







这篇博客主要是讲解从煎蛋网抓取妹子图。也算是对之前所学的爬虫的隐藏和代理的一个综合训练。
我们要想抓取一个网页的指定内容,我们首先需要踩点,所谓的踩点就是发现网页之间存在的联系、规律等等,以便实现我们的高效抓取。
首先我们对煎蛋网进行踩点.我们要实现的功能是抓取煎蛋网上10页中的所有图片,因此我们首先要找到页的地址,在去找到页中图片的地址。
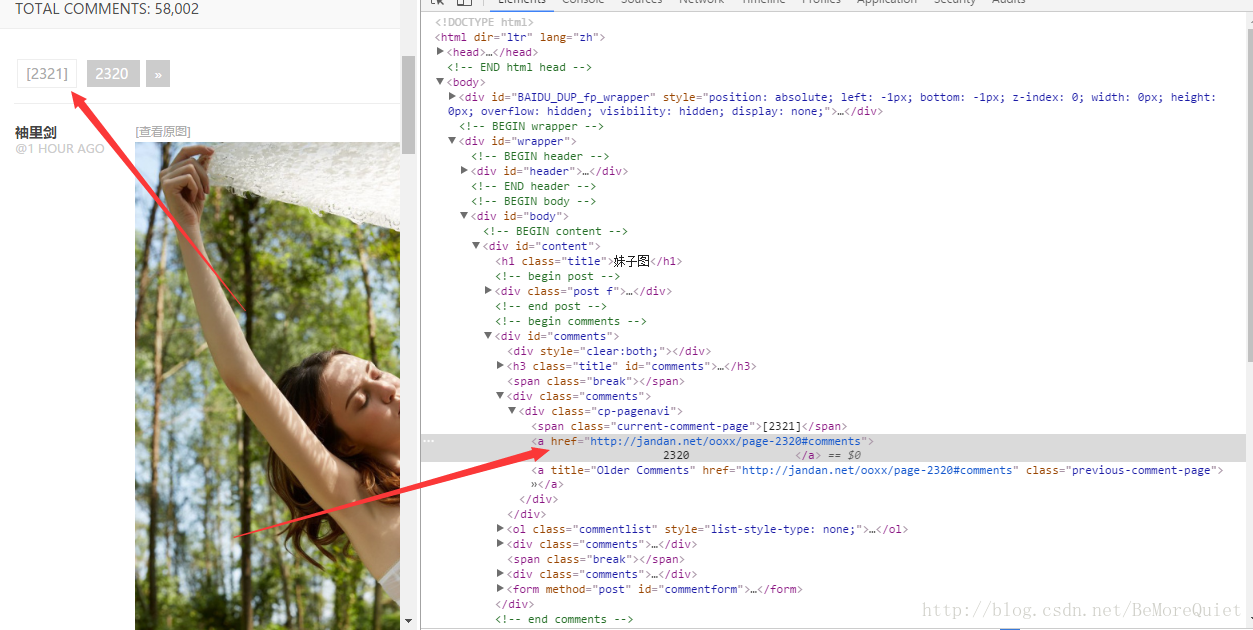
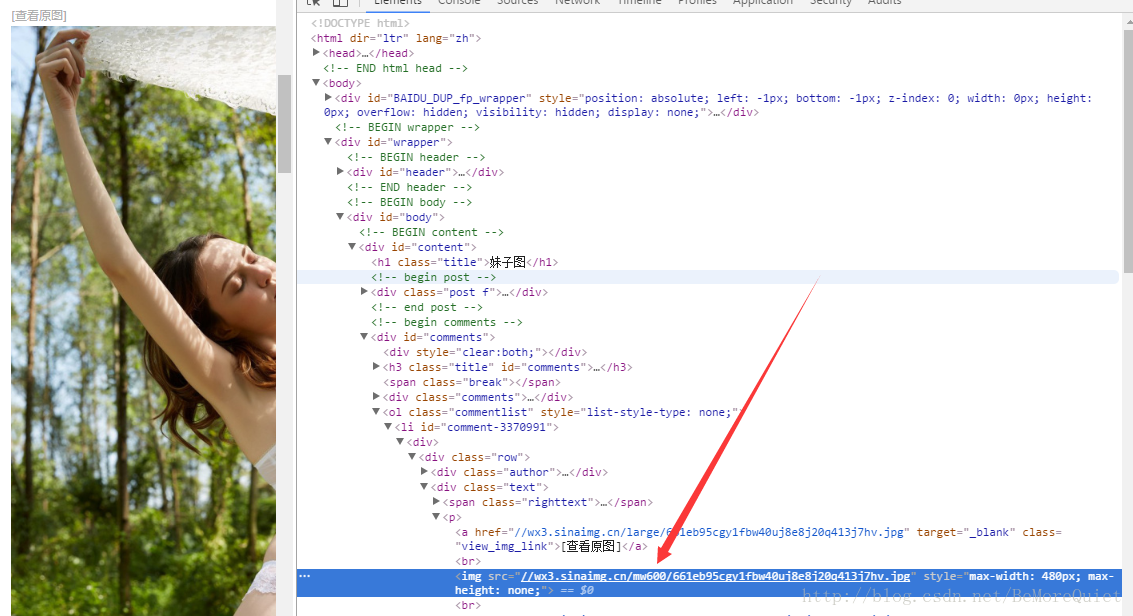
我们通过对煎蛋网页面中页和图片进行检查,很容易便发现了页的地址与图片的地址,并且通过切换不同的页,找到了页与页之间的规律。


不同页之间只是页码号不同,其余均相同。踩好点之后我们便开始代码的编写。我们进行模块化编程,使用函数进行编写。
import urllib.request
import os
#用于获得煎蛋网页面的函数
def url_open(url):
req=urllib.request.Request(url)
#添加header信息
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')
response=urllib.request.urlopen(req)
html=response.read()
return html
#用于从煎蛋网的网页中获得页面的地址的函数
def get_page(url):
#将网页解码为Python能够处理的Unicode编码
html=url_open(url).decode('utf-8')
a=html.find('current-comment-page')+23
b=html.find(']',a)
print(html[a:b])
return html[a:b]
#用于从煎蛋网的页面中找到图片地址的函数
def find_imgs(url):
html=url_open(url).decode('utf-8')
img_addrs=[]
#find函数若找不到要找到的字符串则会返回-1
a=html.find('img src=')
while a!=-1:
#给定.jpg的寻找范围,注意不要太大
b=html.find('.jpg',a,a+100)
#如果顺利找到.jpg,说明找到了完整的图片的地址,则进行保存
if b!=-1:
#对图片进行保存时要格外注意,因为现在使用了泛解析,有的地址不会
#明确给出http的协议名,有的地址有会给出http,
#这对于我们的抓取带来了一定的麻烦,因此我们要分两种情况进行讨论
#这样才不会出现地址错误的异常
if 'http' not in html[a+9:b+4]:
img_addrs.append('http:'+html[a+9:b+4])
else:
img_addrs.append(html[a+9:b+4])
else:
#如果找不到.jpg,则应将b+9,因为下一次循环是从这一次结束开始的
#如果不进行这个操作,则b=-1,则无法进行下一次寻找,之所以加9
#是因为img src="正好是9个字节
b=a+9
#继续进行下一次寻找,只有一个参数,表示从这个点开始下一次寻找
a=html.find('img src=',b)
return img_addrs
#用于保存图片的函数
def save_imgs(folder,img_addrs):
for each in img_addrs:
#[-1]表示从右边数第一个参数
filename=each.split('/')[-1]
f=open(filename,'wb')
img=url_open(each)
f.write(img)
def download_mm(folder='OOXX',pages=10):
#在当前的文件夹(python.exe所在的文件)下创建新的文件夹
os.mkdir(folder)
#将目录切换到该文件夹
os.chdir(folder)
url="http://jandan.net/ooxx/"
#这里的地址是一层套着一层
#页面的地址在网页中抓取
#而页面中的图片在在页面的地址下抓取
#注意层层递进的关系
page_num=int(get_page(url))
for i in range(pages):
#使用循环获取10页的内容
page_num-=i
#获取每一页的地址
page_url=url+'page-'+str(page_num)+'#comments'
#在每一页中找到图片
img_addrs=find_imgs(page_url)
#保存图片
save_imgs(folder,img_addrs)
if __name__=='__main__':
download_mm()
上述代码中已经有了很详细的解释,我被这个程序卡了一天多的bug,主要原因在于在获得图片的地址时对于http协议头部的处理,一开始都加,结果是有的地址出现了双http,而如果不加上http,则缺少http又不能访问,所以在爬取的时候一定要仔细认真。
最后将抓取的资源放上:
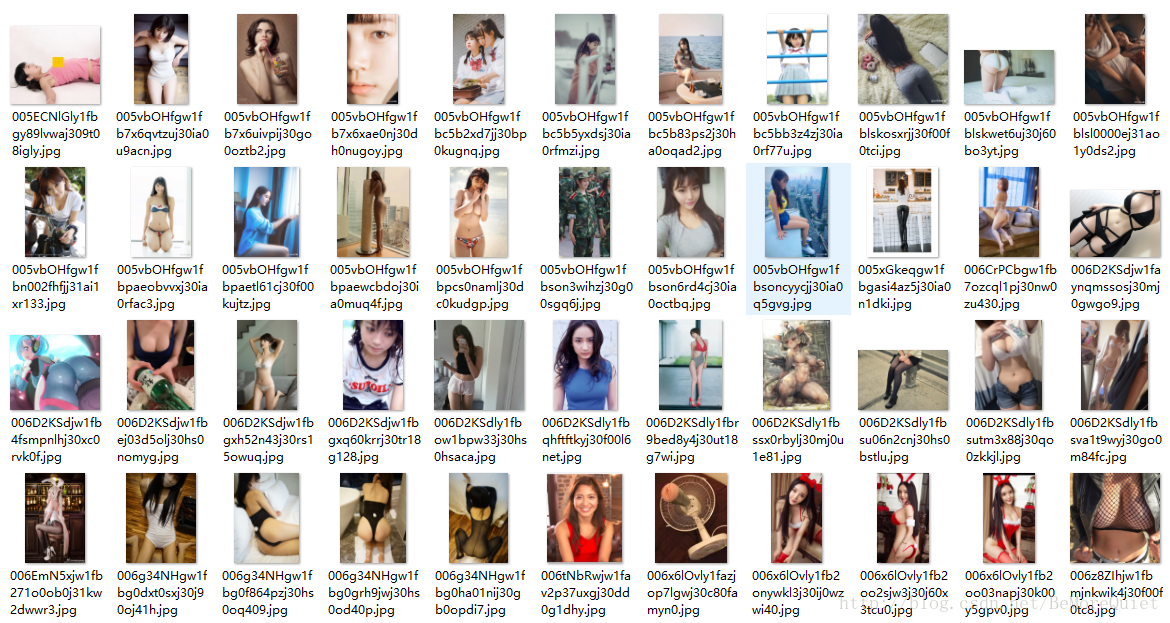
这也是第一个正式的爬虫,还是有点小激动,接下来还是继续加油!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









