







KXEN的软件公司是Getronics,公司的Slogan是The world is your workplace connect with Getronics。不过最近上他们的网站发现Slogan变成了The Data Mining Automation Company。从很多人引用的KDnuggets调查结果来看,KXEN从05年(May 2005 Poll)的名不经传到现在(May 08 Poll)紧跟Clementine和SAS这些专业挖掘软件其后。
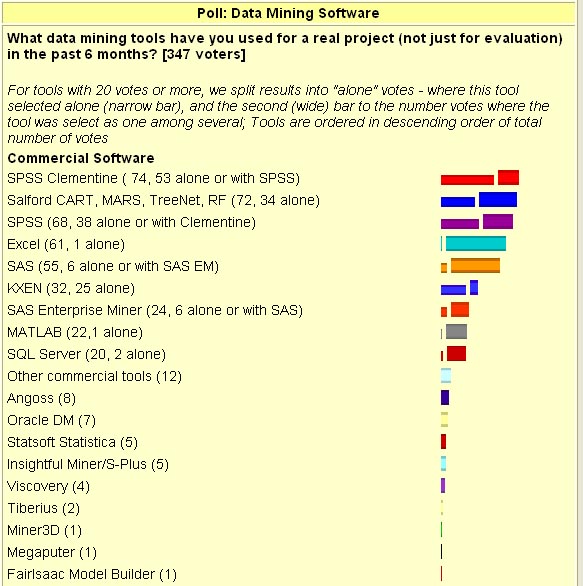
目前KXEN最新版本应该是V5,不过从V4版本起已经需要软件狗才能使用,所以我体验的最新版本也就是06年发布的V3.3。从这个Evaluation Licensetype来看Model具备了用于Classification/Regression的K2R,用于Clustering的K2S,用于Time Series Analysis的KTS和用于Association Rules的KAR。数据挖掘的主要应用也就是这几个方面,只不过KXEN可提供的算法少一些,基本每种挖掘应用就固化了一种算法。下面会详细介绍KXEN这几个以K开头的组件。
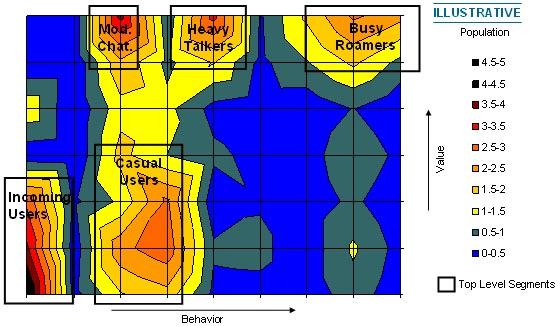
我接触KXEN是在04年Accenture的MR项目,里面对家庭客户做VB(价值-行为)战略分群使用的就是这个软件,分别用V变量和B变量分群然后再交叉形成类似下面的曲面图。MR项目选择KXEN的原因我想有两个,一个是Accenture和KXEN是战略合作关系,Accenture的KX(知识库)里面专门有一个KXEN的内部网站,会提供一些基于KXEN的商业挖掘应用案例,在北京曾听过KXEN HongKong Branch的一位engineer和德腾(KXEN国内代理) 公司刘文 先生的授课。另外一个原因我想就是KXEN的价钱比较便宜。
KXEN的全称是Knowledge Extract Engine,意即“知识提取引擎”,知识提取听起来很悬乎,其实是一个不折不扣的商业挖掘软件。

之所以强调它是“商业”挖掘软件,是因为从它的定位来看,它是为了在企业应用中能够非常方便地将数据挖掘作为一部分,以突出它与一些专业挖掘软件如SAS的差异。正如他标榜的“大多数分析工具在创建统计模型时需要丰富的经验,而KXEN是为每个人使用的数据挖掘——在创建和部署模型时不需要高深的,技术性的知识。简单的点击使您能够在日常的商业决策中整合先进的分析。数据准备和知识发现过程自动化,使您能够节省时间,更好的进行决策。”从我的使用体验来看,KXEN在做分类、客户分群、关联规则和时间序列等建模时都不需要你选择算法,它已经为每种应用都固化了它认为最好的算法(下面会介绍),而且软件的大部分操作都不需要参数调整(使用专家法,也没有多少参数可以让你调节),而且都是step by step的方式,每种算法的方法论或者说专家经验都已经融入到每个step流程中去,你只需要每次按步骤操作点next(就类似Excel绘图一样)就可以得到图表化的结果输出(KXEN的商业模型解释的确做得很出色,可以看到Clementine的新版本也吸取了不少亮点),即使不会调节建模参数KXEN也能做到自动化最优模型搜索。KXEN有句很经典的广告:“上帝的归上帝,撒旦的归撒旦。数学的归KXEN,商业的归用户。”
这种定位其实也受到业内专家的一些争议,数据挖掘本来就是一种技术含量很高的工作,KXEN的出现让对统计和挖掘原理一窍不通的人也可以轻松的得到挖掘结果,实际上对决策支持是一种很危险的趋势。举个例子,在金融行业进行信用风险评级时,一个小数点位数对于经营决策都有很大影响,幸亏进行信用评级所必需的精确几率只有Logistic回归算法能实现,而KXEN的K2R暂时并不具备。
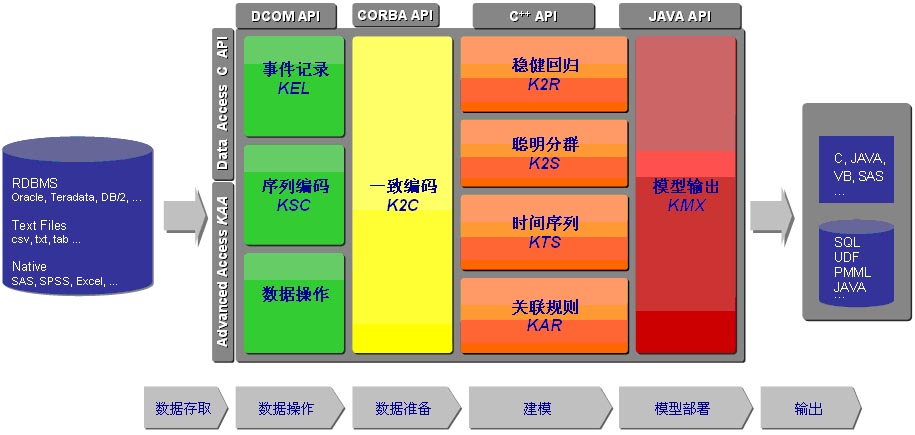
首先它提供了一个KXEN分析框架,KXEN Aanlytic Framework,名字的含义表明它是一种框架,这个含义是指它为你搭好了一个分析应用的框架,剩下的你需要知道该在什么地方放些什么内容了。当然,通常一个框架似乎并不适合我们遇到的需求,因为人们试图去逃避学习曲线或是持着自以为是的态度。之所以有这个框架,是说你可以基于KXEN完成一个完整的挖掘项目,可以将更多精力集中在为数据得到挖掘结果做决策上。它包含了诸如数据源访问,Corba、DCOM和C++的API接口,以及若干分析组件。说白了,如果听过CRISP-DM流程的朋友们,这个所谓的框架就是用来实现CRISP-DM一头的数据准备和处理,还有一尾的模型发布。但从我的使用体验而言,KXEN的数据处理能力和模型发布能力远不如 Clementine,最佳的搭配其实还是Clementine+KXEN,KXEN的强项是在建模速度和评估简单上,我一般的使用经验也是先用Clementine准备好宽表,然后直接让KXEN建模。
在这个框架中,KXEN提供了若干组件,这是KXEN最有特色的东西了,光看都以K打头的模型命名方法已经能嗅到浓浓的“商业”气息,我尝试详细介绍一下。
*K 2C (Kxen.ConsistentCoder):这是KXEN实现自动化预处理的组件,一般在分类预测建模时会自动调用,因此在软件操作界面上没有刻意呈现。这个组件是顾名思义就是用来连续变量离散化的,跟Clementine里面的Binning比较类似。这个数据预处理工作以前会花费不少功夫,因为不同的算法适用不同数据类型。其实以前的分类预测算法,像最开始的决策树算法都不具备支持连续型自变量,但现在新的决策树算法像CART算法已经具备对连续型自变量具有自己的分段功能。还有类似信用评级建模自变量也必须是分类变量。K 2C 的一致编码从原理上说其实在变量预处理阶段已经是用到了类似K2R预测建模时的支持向量机算法寻找非线性的最佳组合区间。
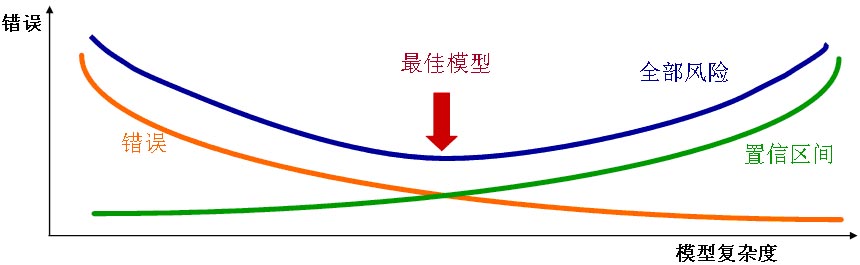
*K2R(Kxen.RobustRegression):K2R做回归分类预测的组件,无可否认Classification分类预测是挖掘里面最常用的一个主题,因为数据挖掘的精髓就是在于它相比传统统计具有惊人的预测力,而分类预测无疑是最能体现这一精髓的。KXEN的技术文档只提到“This polynomial regression is a proprietary algorithm developed by KXEN using Vapnik's SRM (Structured Risk Minimization) principle to calculate the parameters.”众所周知,俄国数学家Vapnik是支持向量机(Support Vector Machine)的发明者,而支持向量机最基础的思想之一就是结构化风险最小化原则SRM,事实上Vapnik就是KXEN科学技术委员会的Leader。KXEN采用结构风险最小化的岭回归(新版本有了专门的KSVM组件)作为分类预测建模的算法也算是业内首吃螃蟹者,连Clementine也是07年才开始引进SVM算法。如果说决策树算法是在多维空间中切矩形,神经网络RBFN是在多维空间中切圆,那么支持向量机就是在多维空间中切各种不规则的图形,从算法原理上来说SVM更符合现实事物的一般性,但不知道为什么从Clementine的二项分类器预测建模精确度比较来看,SVM总是落后于决策树和神经网算法。有点绕远了,因为K2R是KXEN最有激动人心的组件,我再多说一点。大家可能会有疑问,为什么要叫Robust Regression(稳健回归)呢?我想是跟KXEN提供了两个独有的指标有关系,一个是KI (KXEN Indicator) 衡量输入变量预测目标变量的能力,另外一个是KR(KXEN Robustness)衡量模型在新数据集(非训练集)上的性能。想一下,由于预测建模容易出现过度训练,在用Clementine进行预测模型评估时,都是分别比较左右两个Training集和Testing集所画出来的Gain Chart看看有没有区别(是否稳健),而KXEN只需要看指标值就可以了。这也是KXEN一直倡导的结构化风险最小化,用KI来衡量模型的拟合度(也即下面的红线),用KR来衡量模型的可靠性(也即下面的绿线)。分类预测模型的评估和优调很有学问,我也是在摸索中学习,因为涉及到很多计算公式和截图我稍后会尽量专门撰文陈述。另外我印象中,最早具有变量筛选功能的也是K2R,Clementine在12版本也基本具备。
*K2S (Kxen.SmartSegmenter):所谓的聪明分群其实就是Kmeans算法。但它的独到之处是支持有监督(目标)聚类,所谓有监督(目标)聚类其实就是用目标变量标准化各个维度(变量),给予一种距离的衡量方式,这时可以提供KI/KR指标。举个例子,如果是想用聚类来做流失分群管理,可以用是否流失为目标变量。如果想做有监督的聚类就非KXEN莫属了,至少我还没有在其他软件上发现能做有监督聚类的,稍后我会专门撰文写为什么要做有监督的聚类,其实是跟在做聚类时最好不要有分类变量有关系,涉及到分类变量该如何连续化的问题,如果聚类变量都是连续型的有无监督都无关系。在我印象中,KXEN也是第一个提出结合运用分群和分类预测模型的厂商。
*KTS(Kxen.TimeSeries):KTS是做时间序列分析的组件。可以时间序列分析的算法并不多,跟K2R一样KXEN的所有算法都是基于SRM结构化风险最小原则的,优势是模型稳定性比较好。时间序列分析不是KXEN的强项,而且电信业用得不多。
*KAR(Kxen.AssociationRules):KAR是做关联规则分析的组件,就是俗称的购物篮分析。KAR用的是APriori算法。对每条规则除了提供支持度和置信度两个通用指标以外,还提供了KI值:前因中能够解释的结果的信息值,说白了KXEN就是倡导利用这些指标对每条规则进行排序选择的而不像其他DM Tools往往应用所有的规则。KAR出来的关联结果虽然已经是1个客户多条记录每条记录1个推荐产品,便于生成某个产品的目标客户名单(不像Clementine出来的结果是1个客户1条记录把多个推荐产品打平的),但还是没有经过进一步的“商用化”处理,例如没有把对同一客户相同的推荐产品进行归并。
*KSVM(Kxen.SVMClassification):专门的支持向量机分类预测算法模型,它适合用来对哪些观察量很少而变量很多的数据进行分析。不过这个组件我还不知道该怎么调用出来。应该也是在Classification/Regression这类模型入口进去再选择算法。
还有一些其他的次要组件。例如提供两种交易数据的集中方式,KEL(Kxen.EventLog)和KSC(Kxen.SequenceCoder),其实就是常说的ETL过程从交易级数据汇总成客户级数据,KEL是针对时间归并,KSC是针对同一客户的不同交易进行归并。因为对于挖掘,通常的输入是围绕一种对象建立很多变量,例如对用户,除了用户的基本信息,还有用户的通话次数、投诉次数等。而通话、投诉这些被KXEN看作是事件Event,这些信息通常位于不同的表里面,KEL能够自动作计算这次次数、汇总值或均值什么的形成宽表。至于KMX,很明显,这是将KXEN的模型导出成SQL、C甚至是SAS的代码。 KXEN还有一些其他的组件,例如SAS插件或Clementine插件,都是提供接口把KXEN组件生成的数据作为临时文本文件。而IOLAP则是用于找出哪些OLAP分析的维度组合是有意义的,这倒是有点意思。
可以看到,这些模块很有布局性。KEL和KSC是用来转换数据用的,输出数据通过K 2C 进行数据的预处理,到4个模型组件,K2R、K2S、KTS、KAR去建模,模型通过KMX输出为可移植的代码,一切看起来很美的样子。
虽然KXEN一直在往挖掘商用的方向发展,而不是专业的方向发展。但其商用的努力到目前为止仍停留在软件操作的傻瓜化和人性化。事实上,我认为数据挖掘要实现商用(或者说营销自动化MA),必须把挖掘技术黑匣子化,最好让人根本感觉不到数据挖掘的存在,做成生产系统上的插件,把挖掘模型可以作为客户关系系统评分指标(用于流失与挽留),或者产品推荐系统(用于目标客户预测)等的核心原理。这也是我目前一直关注的数据挖掘发布。















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









