






第1关:构建哈夫曼树
任务描述
本关任务:构建哈夫曼树,从键盘读入字符个数n及这n个字符出现的频率即权值,构造带权路径最短的最优二叉树(哈夫曼树)。
相关知识
哈夫曼树的定义
设二叉树具有n个带权值的叶子结点{w1,w2,...,wn},从根结点到每个叶子结点都有一个路径长度。
从根结点到各个叶子结点的路径长度与相应结点权值的乘积的和称为该二叉树的带权路径长度,记作: WPL=i=1∑nwi×li 其中,wi为第i个叶子结点的权值,li为第i个叶子结点的路径长度。 例如:
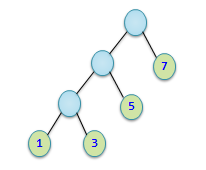
以上二叉树的带权路径长度值: WPL=1×3+3×3+5×2+7×1=29
给定一组具有确定权值的叶子结点,可以构造出许多形状的二叉树,把其中具有最小带权路径长度的二叉树称为哈夫曼树。
例如,用4个整数1、3、5、7作为4个叶子结点的权值,可以构造出不同的二叉树,它们的带权路径长度可能不相同,如下:
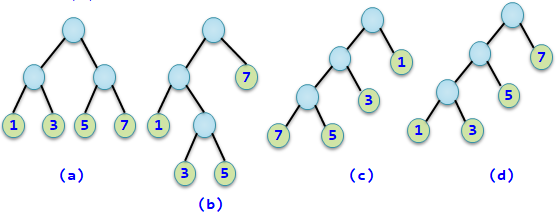
它们的带权路径长度分别为: (a)WPL=1×2+3×2+5×2+7×2=32 (b)WPL=1×2+3×3+5×3+7×1=33 (c)WPL=7×3+5×3+3×2+1×1=43 (d)WPL=1×3+3×3+5×2+7×1=29
其中图(d)所示的二叉树就是一棵哈夫曼树。
根据哈夫曼树的定义,一棵二叉树要使其WPL值最小,必须使权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点。
哈夫曼树的构造算法
(1)由给定的n个权值{w1,w2,...,wn}构造n棵只有一个叶子结点的二叉树,从而得到一个二叉树的集合F={T1,T2,...,Tn};
(2)在F中选取根结点的权值最小和次小的两棵二叉树Ti、Tj进行合并,即增加一个根结点,将Ti、Tj分别作为它的左、右子树,该根结点的权值为其左、右子树根结点权值之和;
(3)重复步骤(2),当F中只剩下一棵二叉树时,这棵二叉树便是所要建立的哈夫曼树。
哈夫曼树的存储结构
根据哈夫曼树的构造算法,哈夫曼树除叶结点外,其余结点的度均为2。
对于具有n个权值构造的哈夫曼树,根据二叉树的性质3,哈夫曼树的结点总数为m=2n-1,即哈夫曼树所需存储空间是由叶结点的个数确定的。
为了便于对多棵二叉树进行组织和便于查找各二叉树的根结点,采用静态链表作为二叉树的存储结构。其存储结构描述如下:
typedef struct{int weight;int parent,lchild,rchild;}HTNode,*HuffmanTree;
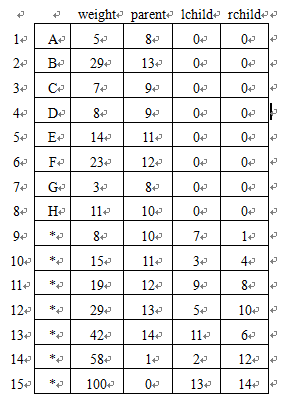
例:设有8个字符{A,B,C,D,E,F,G,H},其概率为{0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11},设其权值用整数表示为 {5,29,7,8,14,23,3,11},其哈夫曼树逻辑示意图如下所示:
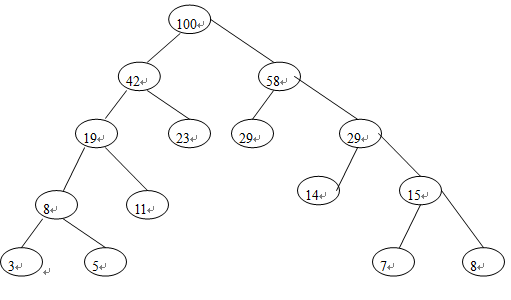
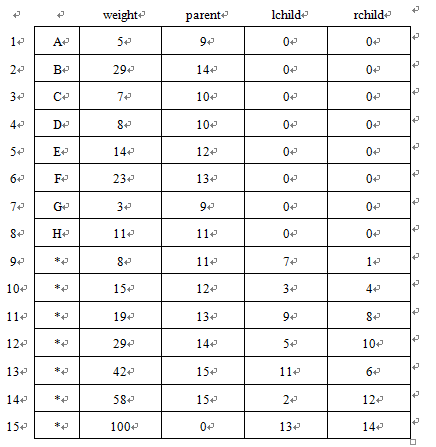
此哈夫曼树在计算机中示意图如下所示:
编程要求
根据提示,在右侧编辑器补充代码,输出哈夫曼树的值。
测试说明
平台会对你编写的代码进行测试:
输入说明 第一行字符的个数n; 第二行输入这n个字符的权值,即n个整数。
测试输入: 8 5 29 7 8 14 23 3 11
输出说明 第一行输出提示信息; 第二行开始输出插入哈夫曼树元素的值,每个项数据元素的数据项用
\t隔开。
预期输出:

代码如下
# include <stdio.h>
# include <iostream>
# include <string.h>
using namespace std;
typedef struct //define structure HuffmanTree
{ int weight;
int parent,lchild,rchild;
}HTNode,*HuffmanTree;
typedef char ** HuffmanCode;
void Select(HuffmanTree HT,int i,int &s1,int &s2) ;//选出HT树到i为止,权值最小且parent为0的2个节点
void HuffmanTreeing(HuffmanTree &HT,int *w,int n);//构建哈夫曼树函数
void output(HuffmanTree HT,int m);//输出哈夫曼树
int main()
{
HuffmanTree HT;
HuffmanCode HC;
int n,i;
int *w;
scanf("%d",&n);
w=(int *)malloc(n*sizeof(int));
for(i=0;i<n;i++)
{
scanf("%d",&w[i]);
}
HuffmanTreeing( HT , w ,n );
cout<<"哈夫曼树:"<<endl;
output(HT,2*n-1);
return 0;
}
void Select(HuffmanTree HT,int i,int &s1,int &s2)
{ //选出HT树到i为止,权值最小且parent为0的2个节点
//s1 is the least of HT[].weight
//s2 is the second least of HT[].weight
/********** Begin **********/
int j;
s1 = 0;
s2 = 0;
for (j = 1; j <= i; ++j)
{
if (HT[j].parent == 0)
{
if (s1 == 0 || HT[j].weight < HT[s1].weight)
{
s2 = s1;
s1 = j;
}
else if (s2 == 0 || HT[j].weight < HT[s2].weight)
{
s2 = j;
}
}
}
/********** End **********/
}
void HuffmanTreeing(HuffmanTree &HT,int *w,int n) //构建哈夫曼树函数
{ // w存放n个字符的权值(均>0),构造赫夫曼树HT
/********** Begin **********/
int m=2*n-1;
HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));
for(int i=1;i<=m;i++)
{
HT[i].weight=0;
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
for(int i=1;i<=n;i++)
{
HT[i].weight=w[i-1];
}
for (int i = n + 1; i <= m; i++)
{
int s1, s2;
Select(HT, i - 1, s1, s2);
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
/********** End **********/
}
void output(HuffmanTree HT,int m)
{ //输出哈夫曼树
for(int i=1;i<=m;++i)
{
cout<<"HT["<<i<<"] ="<<HT[i].weight<<"\t"<<HT[i]. parent<<"\t";
cout<<"\t" <<HT[i]. lchild <<"\t" <<HT[i]. rchild<<endl;
}
}第2关:根据哈夫曼树构建哈夫曼编码
任务描述
本关任务:根据构建好的哈夫曼树,创建一张哈夫曼编码表,输出每个字符的哈夫曼编码。
相关知识
哈夫曼树的存储结构描述如下:
typedef struct{int weight;int parent,lchild,rchild;}HTNode,*HuffmanTree;
例:设有8个字符{A,B,C,D,E,F,G,H},其概率为{0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11},设其权值用整数表示为 {5,29,7,8,14,23,3,11},其哈夫曼树逻辑示意图如下所示:
此哈夫曼树在计算机中示意图如下所示:
哈夫曼编码是基于哈夫曼树构造的编码。
哈夫曼编码的两个特殊性质:
-
哈夫曼编码是前缀编码 前缀编码就是在一个编码方案中,任何一个编码都不是其他任何编码的前缀(最左子串),那么这个编码就是前缀编码。
-
哈夫曼编码是最优前缀编码 即对于包括n个字符的数据文件,分别以它们的出现次数为权值来构造哈夫曼树,则利用该树对应的哈夫曼编码对文件进行编码,能使该文件压缩后对应的二进制文件的长度最短。
哈夫曼编码的实质就是使用频率越高的字符采用的编码越短。
在构造完哈夫曼树之后,通过这棵哈夫曼树来求得哈夫曼编码。
哈夫曼编码的算法实现:
1、先定义一个指向用来存储哈夫曼编码数组的指针,定义如下: typedef char ** HuffmanCode;
2、根据叶子结点个数定义一个存储哈夫曼编码的动态指针数组:
HuffmanCode HC;HC=(HuffmanCode)malloc((n+1)*sizeof(char*));// 分配n个字符编码的头指针向量([0]不用)
3、逐个生成每个叶子结点的编码,实现的思路如下:
在哈夫曼树中,先找到叶子节点,然后向上回溯,每一次回溯都查看是双亲节点的左孩子还是右孩子,如果是左孩子,那么编码就是’0’,反之,如果是右孩子,那么编码就是‘1’。
将得到的‘1’或者‘0’存储到临时的数组中,直到回溯到根节点为止即结束。
在上述的过程中,为什么将得到的编码存储到临时的数组中?
由于是从根节点向上回溯的,所以得到的哈夫曼编码是倒序的,先将编码存储到临时的数组中,待回溯到根节点的时候,再根据编码长度申请一个动态数组编程将编码正序的保存中即可。
注意几个点:
-
通过哈夫曼树构建哈夫曼编码的时候是从叶子节点往回回溯直到根节点得到的。
-
哈夫曼编码是变长编码,因此我们使用一个指针数组来存放每个字符编码串的首地址。
编程要求
根据提示,在右侧编辑器补充代码,输出每个字符的哈夫曼编码。
测试说明
平台会对你编写的代码进行测试:
测试输入: 8 5 29 7 8 14 23 3 11
预期输出:

代码如下
# include <stdio.h>
# include <iostream>
# include <string.h>
using namespace std;
typedef struct //define structure HuffmanTree
{ int weight;
int parent,lchild,rchild;
}HTNode,*HuffmanTree;
typedef char ** HuffmanCode;
void Select(HuffmanTree HT,int i,int &s1,int &s2) ;//选出HT树到i为止,权值最小且parent为0的2个节点
void HuffmanTreeing(HuffmanTree &HT,int *w,int n);//构建哈夫曼树函数
void HuffmanCoding(HuffmanTree HT,HuffmanCode &HC,int n); //建立哈夫曼树编码
void output(HuffmanTree HT,int m);//输出哈夫曼树
int main()
{
HuffmanTree HT;
HuffmanCode HC;
int n,i;
int *w;
scanf("%d",&n);
w=(int *)malloc(n*sizeof(int));
for(i=0;i<n;i++)
{
scanf("%d",&w[i]);
}
HuffmanTreeing( HT , w ,n );
HuffmanCoding( HT, HC ,n );
cout<<"哈夫曼编码:"<<endl;
for(i=1;i<=n;i++)
{
printf("HT[%d] node's Huffman code is: %s\n",i,HC[i]);
}
return 0;
}
void Select(HuffmanTree HT,int i,int &s1,int &s2)
{ //选出HT树到i为止,权值最小且parent为0的2个节点
//s1 is the least of HT[].weight
//s2 is the second least of HT[].weight
int j,k=1;
while(HT[k].parent!=0)
k++;
s1=k;
for(j=1; j<=i ;++j)
if(HT[j].parent==0 && HT[j].weight < HT[s1].weight )
s1=j;
k=1;
while( HT[k].parent!=0|| k==s1 )
k++;
s2=k;
for(j=1;j<=i;++j)
if( HT[j].parent==0 && HT[j].weight<HT[s2].weight && j!=s1)
s2=j;
}
void HuffmanTreeing(HuffmanTree &HT,int *w,int n) //构建哈夫曼树函数
{ // w存放n个字符的权值(均>0),构造赫夫曼树HT
int m,i,s1,s2,start,c,f;
HuffmanTree p;
if(n<=1)
return;
m= 2*n-1 ;
HT=(HuffmanTree) malloc( (m+1)*sizeof( HTNode ) );
for(p=HT+1,i=1;i<=n;++i,++p) //initial HT[1...n]
{
p->weight= w[i-1] ;
p->parent=0;
p->lchild=0;
p->rchild=0;
}
for( ;i<=m;++i,++p) //initial HT[n+1...2*n1]
{
p->weight= 0;
p->parent=0;
p->lchild=0;
p->rchild=0;
}
for(i=n+1;i<=m;++i)
{
Select(HT,i-1,s1,s2); // 在HT[1~i-1]中选择parent为0且weight最小的两个结点,其序号分别为s1和s2
HT[s1].parent= i ;
HT[s2].parent= i ;
HT[i].lchild= s1 ;
HT[i].rchild= s2 ;
HT[i].weight= HT[s1].weight+HT[s2].weight ;
}
}
void HuffmanCoding(HuffmanTree HT,HuffmanCode &HC,int n) //建立哈夫曼树编码
{ // 根据赫夫曼树HT,求出n个字符的赫夫曼编码HC
/********** Begin **********/
HC = (HuffmanCode)malloc((n + 1) * sizeof(char *)); // 分配n个字符编码的头指针向量
char *cd = (char *)malloc(n * sizeof(char)); // 分配求编码的工作空间
cd[n - 1] = '\0'; // 编码结束符
for (int i = 1; i <= n; i++)
{
int start = n - 1;
int c = i;
int f = HT[i].parent;
while (f != 0)
{
--start;
if (HT[f].lchild == c)
{
cd[start] = '0';
}
else
{
cd[start] = '1';
}
c = f;
f = HT[f].parent;
}
HC[i] = (char *)malloc((n - start) * sizeof(char)); // 为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); // 复制生成的赫夫曼编码
}
free(cd); // 释放工作空间
/********** End **********/
}
void output(HuffmanTree HT,int m)
{ //输出哈夫曼树
for(int i=1;i<=m;++i)
{
cout<<"HT["<<i<<"] ="<<HT[i].weight<<"\t"<<HT[i]. parent<<"\t";
cout<<"\t" <<HT[i]. lchild <<"\t" <<HT[i]. rchild<<endl;
}
}













 1957
1957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









