






1.对一个大小为256的浮点型数组,做并行归约。并完成:
- 复现
• 相邻配对• 消除线程束分化• 消除bank conflict• 单线程加载全局内存时做一次加法• 循环展开• 单线程加载全局内存时做多次加法• 完全循环展开• shuffle指令优化8种实现方式,其中shuffle指令优化采用
_shfl_xor_sync实现shuffle指令优化; - 利用thrust库实现归约;
- 对每种实现,重复实验2000次,统计平均时间用于最终性能评价。
/*
相邻配对朴素实现
使用方法:chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
__global__ void reduce0(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE]; //共享内存大小等于线程块的大小
int tid = threadIdx.x; //共享内存中的索引,即在线程块中的编号
int i = blockIdx.x * blockDim.x + threadIdx.x; //全局内存中的索引
s_data[tid] = g_in[i];
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做相邻配对归约,线程和数据序号一一对应
for(int s = 1; s < blockDim.x; s *= 2)
{
if(tid % (2 * s) == 0)
{
s_data[tid] += s_data[tid + s];
}
__syncthreads();
}
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / BLOCK_SIZE); //线程块的个数
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < BLOCK_SIZE; j++)
{
seq_result[i] += h_in[i * BLOCK_SIZE + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce0<<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("相邻配对归约朴素实现:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
消除线程束分支
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
__global__ void reduce1(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE];//共享内存大小等于线程块的大小
int tid = threadIdx.x; //共享内存中的索引,即在线程块中的编号
int i = blockIdx.x*blockDim.x + threadIdx.x;//全局内存中的索引
s_data[tid] = g_in[i];
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做相邻配对归约,线程和数据序号间隔对应
for(int s = 1; s < blockDim.x; s *= 2)
{
int index = 2 * s * tid;
if (index < blockDim.x)
{
s_data[index] += s_data[index + s];
}
__syncthreads();
}
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / BLOCK_SIZE); //线程块的个数
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < BLOCK_SIZE; j++)
{
seq_result[i] += h_in[i * BLOCK_SIZE + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce1<<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("消除线程束分支优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
交错配对归约消除bank conflict
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
__global__ void reduce2(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE];//共享内存大小等于线程块的大小
int tid = threadIdx.x; //共享内存中的索引,即在线程块中的编号
int i = blockIdx.x * blockDim.x + threadIdx.x;//全局内存中的索引
s_data[tid] = g_in[i];
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做交错配对归约
for(int s = (blockDim.x >> 1); s > 0; s >>= 1)
{
if (tid < s)
{
s_data[tid] += s_data[tid + s];
}
__syncthreads();
}
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / BLOCK_SIZE); //线程块的个数
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < BLOCK_SIZE; j++)
{
seq_result[i] += h_in[i * BLOCK_SIZE + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce2<<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("交错配对消除bank conflict优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
从全局内存加载时计算
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
__global__ void reduce3(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE]; //共享内存大小等于线程块的大小
int tid = threadIdx.x;
int i = blockDim.x * (blockIdx.x * 2) + tid; //当前线程块对应数据块编号 (blockIdx.x * 2)
s_data[tid] = g_in[i] + g_in[i + blockDim.x];//当前数据块和下一块数据对应位置相加
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做交错配对归约
for(int s = (blockDim.x >> 1); s > 0; s >>= 1)
{
if (tid < s)
{
s_data[tid] += s_data[tid + s];
}
__syncthreads();
}
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / (2 * BLOCK_SIZE)); //线程块的个数要减半
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < (2 * BLOCK_SIZE); j++) //串行结果也要多个数据块合并计算
{
seq_result[i] += h_in[i * (2 * BLOCK_SIZE) + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce3<<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("加载时计算优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
加载时计算
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
//循环展开
__device__ void warpReduce(volatile float* cache, unsigned int tid){
cache[tid]+=cache[tid+32]; //0-31 + 32-63
cache[tid]+=cache[tid+16]; //0-15 + 16-31
cache[tid]+=cache[tid+8];
cache[tid]+=cache[tid+4];
cache[tid]+=cache[tid+2];
cache[tid]+=cache[tid+1];
}
__global__ void reduce4(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE]; //共享内存大小等于线程块的大小
int tid = threadIdx.x;
int i = blockIdx.x * (blockDim.x * 2) + threadIdx.x;;//到下一个数据块的步长是blockIdx.x * (blockDim.x * 2)
s_data[tid] = g_in[i] + g_in[i + blockDim.x];//当前数据块和下一块数据对应位置相加
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做交错配对归约
for(int s = (blockDim.x >> 1); s > 32; s >>= 1) //剩下64个数时跳出循环
{
if (tid < s) {
s_data[tid] += s_data[tid + s];
}
__syncthreads();
}
//剩下的32个线程对64个数做循环展开
if (tid < 32) warpReduce(s_data, tid);
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / (2 * BLOCK_SIZE)); //线程块的个数要减半
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < (2 * BLOCK_SIZE); j++) //串行结果也要多个数据块合并计算
{
seq_result[i] += h_in[i * (2 * BLOCK_SIZE) + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce4<<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("循环展开优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
完全循环展开
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
//完全展开-使用模板
//这里这么多判断是为了防止线程块设置太小,设置太小的,前面的几步操作就可以忽略了
template <int blockSize>
__device__ void warpReduce(volatile float* cache, unsigned int tid){
if(blockSize >= 64) cache[tid] += cache[tid+32];
if(blockSize >= 32) cache[tid] += cache[tid+16];
if(blockSize >= 16) cache[tid] += cache[tid+8];
if(blockSize >= 8) cache[tid] += cache[tid+4];
if(blockSize >= 4) cache[tid] += cache[tid+2];
if(blockSize >= 2) cache[tid] += cache[tid+1];
}
template <int blockSize>
__global__ void reduce5(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[blockSize]; //共享内存大小等于线程块的大小
int tid = threadIdx.x;
int i = blockIdx.x * (blockDim.x * 2) + threadIdx.x;;//到下一个数据块的步长是blockIdx.x * (blockDim.x * 2)
s_data[tid] = g_in[i] + g_in[i + blockDim.x];//当前数据块和下一块数据对应位置相加
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做交错配对归约 暴力展开
if (blockSize >= 1024)
{
if (tid < 512)
{
s_data[tid] += s_data[tid + 512];
}
__syncthreads();
}
if (blockSize >= 512)
{
if (tid < 256)
{
s_data[tid] += s_data[tid + 256];
}
__syncthreads();
}
if (blockSize >= 256)
{
if (tid < 128)
{
s_data[tid] += s_data[tid + 128];
}
__syncthreads();
}
if (blockSize >= 128)
{
if (tid < 64)
{
s_data[tid] += s_data[tid + 64];
}
__syncthreads();
}
//剩下的32个线程对64个数做循环展开
if (tid < 32) warpReduce<blockSize>(s_data, tid);
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main()
{
const int N = 32 * (1 << 20); //输入数据规模:32M
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int block_num = (N / (2 * BLOCK_SIZE)); //线程块的个数要减半
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < (2 * BLOCK_SIZE); j++) //串行结果也要多个数据块合并计算
{
seq_result[i] += h_in[i * (2 * BLOCK_SIZE) + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
reduce5<BLOCK_SIZE><<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("完全循环展开优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
单线程在加载全局内存时做多次加法
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
//完全展开-使用模板
//这里这么多判断是为了防止线程块设置太小,设置太小的,前面的几步操作就可以忽略了
template <int blockSize>
__device__ void warpReduce(volatile float* cache, unsigned int tid){
if(blockSize >= 64) cache[tid] += cache[tid+32];
if(blockSize >= 32) cache[tid] += cache[tid+16];
if(blockSize >= 16) cache[tid] += cache[tid+8];
if(blockSize >= 8) cache[tid] += cache[tid+4];
if(blockSize >= 4) cache[tid] += cache[tid+2];
if(blockSize >= 2) cache[tid] += cache[tid+1];
}
//线程块大小,每个线程对应要处理的数据块个数
template <int blockSize , int NUM_PER_THREAD>
__global__ void reduce6(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[blockSize]; //共享内存大小等于线程块的大小
int tid = threadIdx.x;
int i = blockSize * (blockIdx.x * NUM_PER_THREAD) + tid;//在第一个数据块内,第一个数的全局索引
s_data[tid] = 0;
#pragma unroll
for(int iter=0; iter<NUM_PER_THREAD; iter++)
s_data[tid] += g_in[i + iter * blockSize];
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做交错配对归约
if (blockSize >= 1024)
{
if (tid < 512)
{
s_data[tid] += s_data[tid + 512];
}
__syncthreads();
}
if (blockSize >= 512)
{
if (tid < 256)
{
s_data[tid] += s_data[tid + 256];
}
__syncthreads();
}
if (blockSize >= 256)
{
if (tid < 128)
{
s_data[tid] += s_data[tid + 128];
}
__syncthreads();
}
if (blockSize >= 128)
{
if (tid < 64)
{
s_data[tid] += s_data[tid + 64];
}
__syncthreads();
}
if (tid < 32) warpReduce<blockSize>(s_data, tid);
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
int main(int argc, char **argv)
{
const int N = 32 * (1 << 20); //输入数据规模:32M
const int NUM_PER_THREAD = 8; //每个线程在加载全局内存时计算的数字个数
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int NUM_PER_BLOCK = (NUM_PER_THREAD * BLOCK_SIZE); //根据线程块数量计算每个线程块要处理的数据个数
int block_num = N / NUM_PER_BLOCK;
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < NUM_PER_BLOCK; j++) //串行结果也要多个数据块合并计算
{
seq_result[i] += h_in[i * NUM_PER_BLOCK + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
//必须传递常量进去
reduce6<BLOCK_SIZE , NUM_PER_THREAD><<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("单线程%d次加法优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , NUM_PER_THREAD , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
shuffle洗牌
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE 256
#define WARP_SIZE 32
//在一个warp内进行归约
template <int blockSize>
__device__ float warpReduceSum(float sum)
{
//__shfl_down_sync向前传值
if (blockSize >= 32) sum += __shfl_down_sync(0xffffffff, sum, 16); //束内前16个获取后16个的值
if (blockSize >= 16) sum += __shfl_down_sync(0xffffffff, sum, 8); //0-7获取8-15的值
if (blockSize >= 8) sum += __shfl_down_sync(0xffffffff, sum, 4); //0-3获取4-7的值
if (blockSize >= 4) sum += __shfl_down_sync(0xffffffff, sum, 2); //0-1获取2-3的值
if (blockSize >= 2) sum += __shfl_down_sync(0xffffffff, sum, 1); //0获取1的值
return sum;
}
//线程块大小 每个线程要处理的个数
template <int blockSize, int NUM_PER_THREAD>
__global__ void reduce7(float *g_in,float *g_out)
{
//(1)线程块内各个warp做归约,结果存储到共享内存中
float sum = 0; //用于warp内归约求和
int tid = threadIdx.x;
int i = blockIdx.x * (blockSize * NUM_PER_THREAD) + threadIdx.x;
#pragma unroll
for(int iter=0; iter < NUM_PER_THREAD; iter++)
sum += g_in[i+iter*blockSize]; //一个线程块处理多个数据块
__shared__ float warpLevelSums[WARP_SIZE]; //共享内存用于存储线程块内各个warp归约的结果
const int laneId = threadIdx.x % WARP_SIZE; //线程在warp内的编号[0-31]
const int warpId = threadIdx.x / WARP_SIZE; //块内第几个warp,最大1024个线程,[0-31]
sum = warpReduceSum<blockSize>(sum); //先对线程块内每个warp内部进行归约
if(laneId == 0) warpLevelSums[warpId] = sum; //每个束内0号线程,将归约结果放入共享内存中
__syncthreads();
//(2)结果收集到0号warp各线程的sum,0号warp做归约
sum = (threadIdx.x < (blockSize / WARP_SIZE)) ? warpLevelSums[laneId] : 0; //将归约结果取到warp 0的sum中
if(warpId == 0) sum = warpReduceSum<(blockSize/WARP_SIZE)>(sum); //warp 0做归约
if(tid == 0) g_out[blockIdx.x] = sum;
}
int main(int argc, char **argv)
{
const int N = 32 * (1 << 20); //输入数据规模:32M
const int NUM_PER_THREAD = 8; //每个线程在加载全局内存时计算的数字个数
//主机输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int NUM_PER_BLOCK = (NUM_PER_THREAD * BLOCK_SIZE); //根据线程块数量计算每个线程块要处理的数据个数
int block_num = N / NUM_PER_BLOCK;
float *seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for(int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for(int j = 0; j < NUM_PER_BLOCK; j++) //串行结果也要多个数据块合并计算
{
seq_result[i] += h_in[i * NUM_PER_BLOCK + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
float *d_out;
cudaMalloc((void **)&d_out , block_num * sizeof(float));
float *h_out = (float *)malloc(block_num * sizeof(float)); //每个线程块一个输出
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
//必须传递常量进去
reduce7<BLOCK_SIZE , NUM_PER_THREAD><<<block_num , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out , d_out , block_num * sizeof(float) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , block_num);
float seq_final_res = 0.0 , gpu_final_res = 0.0;
for(int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("shuffle优化:串行归约结果=%.3f=并行归约结果=%.3f \n" , NUM_PER_THREAD , seq_final_res , gpu_final_res);
printf("计算%dM数据:串行计算时间: %f ms\n", N / (1 << 20) , cpu_time);
printf("CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.2f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
CUDA高性能计算库Thrust做归约
*/
#include <stdio.h>
#include <cuda_runtime.h>
#include <thrust/device_vector.h>
#include <thrust/reduce.h>
int main()
{
int n = 32 * (1 << 20);
thrust::device_vector<float> src(n, 1.0);
float sum;
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
sum = thrust::reduce(src.begin(), src.begin() + n);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
printf("使用Thrust库归约结果为: %f \n" , sum);
printf("并行计算时间为: %fms\n", gpu_time);
return 0;
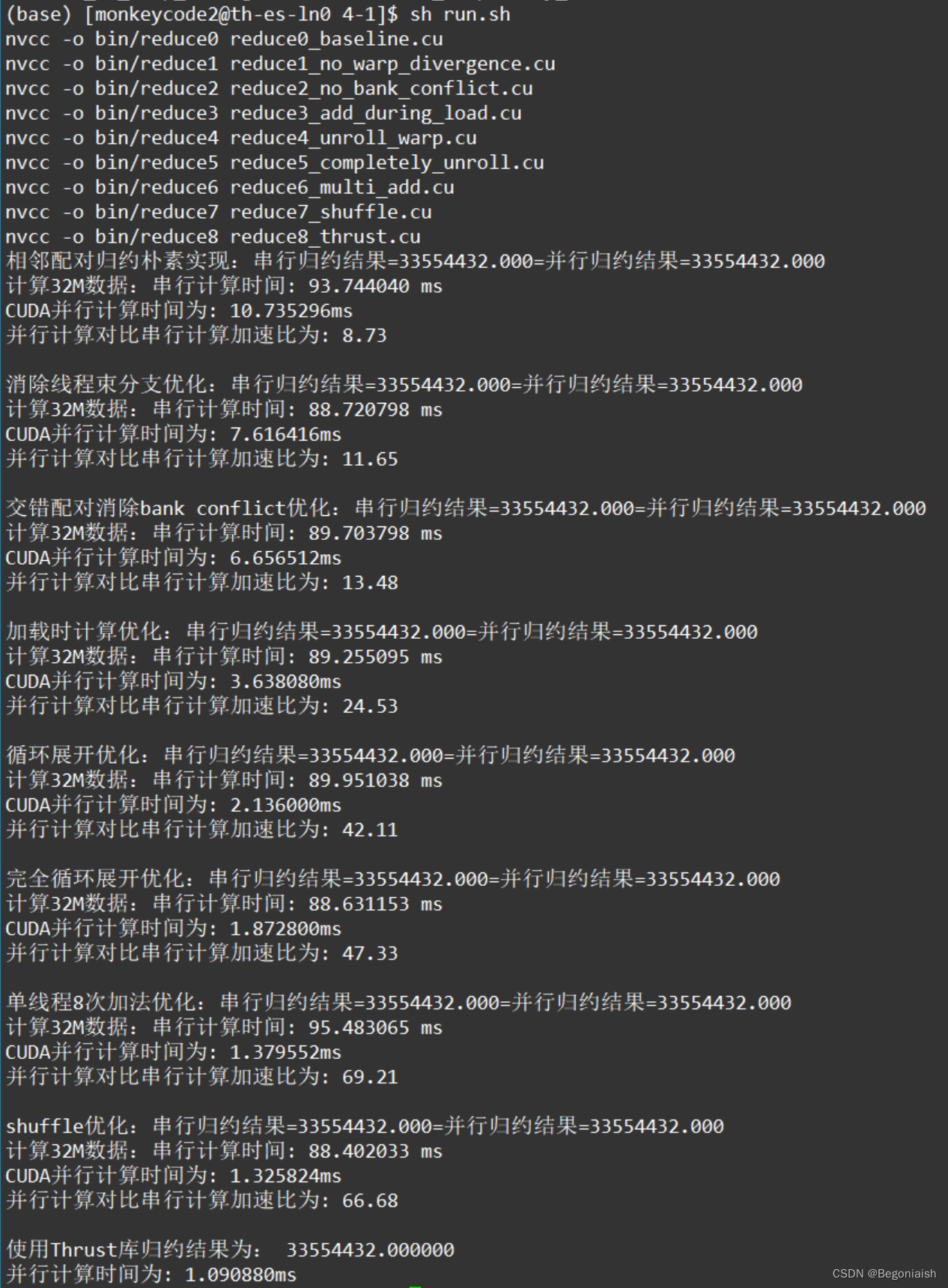
}
2.对大小为64M的一个整型数组,做并行扫描。
(1) 复现
•
线程全局累加
•
单块Hillis Steele扫描(两种)
•
单块Blelloch扫描(两种)
•
scan-then-fan: Hillis Steele扫描(两种)
•
scan-then-fan: Blelloch扫描(两种)
8种实现方式,完成PPT里所提及的思考题;
(2) 利用thrust库实现并行扫描;
(3) 对每种实现,重复实验2000次,统计平均时间用于最终性能评价(对于任意长度的多块扫描,尝试不同的线程块大小)。
/*
最简单实现 线程全局累加
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 10)
#define N (1 << 10) //输入数据规模
__global__ void simple_prefix_sum(int *X , int *Y)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tmp = 0.0;
for(int i = 0; i < idx; i++)
{
tmp += X[i];
}
Y[idx] = tmp;
}
int main()
{
//主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in , N);
//设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in , N * sizeof(int));
cudaMemcpy(d_in , h_in , N * sizeof(int) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int * seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
//开扫描
seq_result[0] = 0;
for(int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i-1] + h_in[i];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
int *d_out;
cudaMalloc((void **)&d_out , N * sizeof(int));
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
simple_prefix_sum<<<ceil(N/BLOCK_SIZE) , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); //每个线程块一个输出
cudaMemcpy(h_out , d_out , N * sizeof(int) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10) , cpu_time);
printf("朴素扫描,CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
Hillis Steele 单块扫描
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 10)
#define N (1 << 10) //单块上,输入数据规模=线程块大小
//Hillis_Steele两次同步
__global__ void Hillis_Steele_scan_kernel(int *X, int *Y)
{
//每个线程取一个元素到共享内存
__shared__ int s_Y[BLOCK_SIZE];
int tid = threadIdx.x;
if (tid < N)
s_Y[tid] = X[tid];
//在共享内存上算前缀和,往前找元素的步长每轮翻倍
for(int s = 1; s <= tid; s <<= 1)
{
__syncthreads();
int tmp = s_Y[tid - s];
__syncthreads();
s_Y[tid] += tmp;
}
//将结果写回全局内存
if (tid < N)
Y[tid] = s_Y[tid];
}
int main()
{
//主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in , N);
//设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in , N * sizeof(int));
cudaMemcpy(d_in , h_in , N * sizeof(int) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int * seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
seq_result[0] = h_in[0];
for(int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i-1] + h_in[i];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
int *d_out;
cudaMalloc((void **)&d_out , N * sizeof(int));
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
Hillis_Steele_scan_kernel<<<1 , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); //每个线程块一个输出
cudaMemcpy(h_out , d_out , N * sizeof(int) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10) , cpu_time);
printf("单块Hillis Steele 扫描(两次同步),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
Hillis Steele double buffer
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 10)
#define N (1 << 10) //单块上,输入数据规模=线程块大小
//Hillis_Steele double buffer
__global__ void Hillis_Steele_double_buffer(int *X, int *Y)
{
//每个线程取一个元素到共享内存中的读缓冲区
__shared__ int s_Y[2 * BLOCK_SIZE]; //共享内存地址翻倍
int tid = threadIdx.x;
int pread = 0 , pwrite = 1; //pwrite表示写缓冲区,pread表示读缓冲区
if(tid < N)
s_Y[pread * N + tid] = X[tid];
__syncthreads();
//在共享内存上算前缀和,往前找元素的步长每轮翻倍
for (int s = 1; s < N; s <<= 1)
{
if (tid >= s) //从读缓冲区读数到写缓冲区,修改的只是写缓冲内容,避免了竞争
s_Y[pwrite * N + tid] = s_Y[pread * N + tid - s] + s_Y[pread * N + tid];
else
s_Y[pwrite * N + tid] = s_Y[pread * N + tid];
__syncthreads();
pread = 1 - pread , pwrite = 1 - pwrite; //读写缓冲交换
}
Y[tid] = s_Y[pread * N + tid];
}
int main()
{
//主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in , N);
//设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in , N * sizeof(int));
cudaMemcpy(d_in , h_in , N * sizeof(int) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int * seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
seq_result[0] = h_in[0];
for(int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i-1] + h_in[i];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
int *d_out;
cudaMalloc((void **)&d_out , N * sizeof(int));
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
Hillis_Steele_double_buffer<<<1 , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); //每个线程块一个输出
cudaMemcpy(h_out , d_out , N * sizeof(int) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10) , cpu_time);
printf("单块Hillis Steele 扫描(double buffer),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
Blelloch算法 - 未消除bank confilct
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 9)
#define N (1 << 10) //单块上,输入数据规模=线程块大小
//Blelloch算法
__global__ void Blelloch_scan_with_bank_conflict(int *X, int *Y)
{
//每个线程取两个元素到共享内存
int tid = threadIdx.x;
__shared__ int s_Y[2 * BLOCK_SIZE];
if((2 * tid) < N) s_Y[2 * tid] = X[2 * tid];
if((2 * tid + 1) < N) s_Y[2 * tid + 1] = X[2 * tid + 1];
//第一阶段 reduce
for(int s = 1; s <= BLOCK_SIZE; s <<= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if(index < (2 * BLOCK_SIZE))
{
s_Y[index] += s_Y[index - s];
}
}
//把最后一个元素清0
if(tid == 0)
{
s_Y[2 * BLOCK_SIZE - 1] = 0.0;
}
//第二阶段 down sweep
for(int s = BLOCK_SIZE; s > 0; s >>= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if(index < (2 * BLOCK_SIZE))
{
int tmp = s_Y[index];
s_Y[index] += s_Y[index - s];
s_Y[index - s] = tmp;
}
}
__syncthreads();
//将结果写回全局内存
if((2 * tid) < N) Y[2 * tid] = s_Y[2 * tid];
if((2 * tid + 1) < N) Y[2 * tid + 1] = s_Y[2 * tid + 1];
}
int main()
{
//主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in , N);
//设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in , N * sizeof(int));
cudaMemcpy(d_in , h_in , N * sizeof(int) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int * seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
//此时算的是开扫描
seq_result[0] = 0;
for(int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i-1] + h_in[i-1];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
int *d_out;
cudaMalloc((void **)&d_out , N * sizeof(int));
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
Blelloch_scan_with_bank_conflict<<<1 , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); //每个线程块一个输出
cudaMemcpy(h_out , d_out , N * sizeof(int) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10) , cpu_time);
printf("单块Blelloch_scan 扫描(bank conflict),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
任意长度扫描 单块使用Blelloch算法 - 未消除bank confilct
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define CONFLICT_FREE_OFFSET(a) ((a) >> 5)
#define BLOCK_SIZE (1 << 9)
#define N (1 << 10) //单块上,输入数据规模=线程块大小
//Blelloch算法
__global__ void Blelloch_scan_bank_conflict_optimization(int *X, int *Y)
{
//每个线程取两个元素到共享内存
int tid = threadIdx.x;
__shared__ int s_Y[2 * BLOCK_SIZE + (2 * BLOCK_SIZE >> 5)]; //每个线程处理两个元素
if((2 * tid) < N) s_Y[2 * tid + CONFLICT_FREE_OFFSET(2 * tid)] = X[2 * tid];
if((2 * tid + 1) < N) s_Y[2 * tid + 1 + CONFLICT_FREE_OFFSET(2 * tid + 1)] = X[2 * tid + 1];
//第一阶段 reduce
for(int s = 1; s <= BLOCK_SIZE; s <<= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1; //没有消除bank conflict之前的索引
if(index < (2 * BLOCK_SIZE))
{
s_Y[index + CONFLICT_FREE_OFFSET(index)] += s_Y[index - s + CONFLICT_FREE_OFFSET(index - s)];
}
}
//把最后一个元素清0
if(tid == 0)
{
s_Y[2 * BLOCK_SIZE - 1 + CONFLICT_FREE_OFFSET(2 * BLOCK_SIZE - 1)] = 0.0;
}
//第二阶段 down sweep
for(int s = BLOCK_SIZE; s > 0; s >>= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if(index < (2 * BLOCK_SIZE))
{
int tmp = s_Y[index + CONFLICT_FREE_OFFSET(index)];
s_Y[index + CONFLICT_FREE_OFFSET(index)] += s_Y[index - s + CONFLICT_FREE_OFFSET(index -s)];
s_Y[index - s + CONFLICT_FREE_OFFSET(index - s)] = tmp;
//printf("%d %d %d-%f %f\n" ,
// s ,index , index - s , s_Y[index] , s_Y[index - s]);
}
}
__syncthreads();
//将结果写回全局内存
if((2 * tid) < N) Y[2 * tid] = s_Y[2 * tid + CONFLICT_FREE_OFFSET(2 * tid)];
if((2 * tid + 1) < N) Y[2 * tid + 1] = s_Y[2 * tid + 1 + CONFLICT_FREE_OFFSET(2 * tid + 1)];
}
int main()
{
//主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in , N);
//设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in , N * sizeof(int));
cudaMemcpy(d_in , h_in , N * sizeof(int) , cudaMemcpyHostToDevice);
//主机串行计算并计时
int * seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
//此时算的是开扫描
seq_result[0] = 0;
for(int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i-1] + h_in[i-1];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
//申请设备输出结果内存及拷贝回主机内存
int *d_out;
cudaMalloc((void **)&d_out , N * sizeof(int));
//并行归约计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
Blelloch_scan_bank_conflict_optimization<<<1 , BLOCK_SIZE>>>(d_in , d_out);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); //每个线程块一个输出
cudaMemcpy(h_out , d_out , N * sizeof(int) , cudaMemcpyDeviceToHost);
checkResult(seq_result , h_out , N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10) , cpu_time);
printf("单块Blelloch_scan 扫描(消除bank conflict),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time , (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
任意长度扫描 单块使用Hillis Steele算法
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 9)
/*
使用Hillis_Steele进行扫描
in_data 输入数据
out_scan_result 每个扫描块的前缀和结果数组(闭扫描)
out_sum_of_each_block 每个扫描块的总和数组(辅助数组)
length 计算数据大小
*/
__global__ void Hillis_Steele_scan_kernel(int *in_data, int *out_scan_result, int *out_sum_of_each_block, int length)
{
// 每个线程取一个元素到共享内存
__shared__ int s_out_data[BLOCK_SIZE];
int tid = threadIdx.x;
int idx = blockIdx.x * blockDim.x + tid;
if (idx < length)
s_out_data[tid] = in_data[idx];
// 在共享内存上算前缀和,往前找元素的步长每轮翻倍
for (int s = 1; s <= tid; s <<= 1)
{
__syncthreads();
int tmp = s_out_data[tid - s];
__syncthreads();
s_out_data[tid] += tmp;
}
// 将结果写回全局内存
if (idx < length)
{
out_scan_result[idx] = s_out_data[tid];
if (tid == (BLOCK_SIZE - 1)) //将每个扫描块扫描结果的最后一个值作为扫描块的总和
out_sum_of_each_block[blockIdx.x] = s_out_data[tid];
}
}
/*
fan 扇出,将扫描后的总和数组扇出到各个扫描块上
in_first_scan_result 第一遍扫描结果,存储每个扫描块的前缀和结果数组,从Hillis_Steele_scan_kernel中得到
in_scan_of_sum 对辅助数组做前缀和的结果数组
out_final 该轮递归的最终前缀和结果数组
length 计算数据大小
*/
__global__ void fan_elements(int *in_first_scan_result, int *in_scan_of_sum,
int *out_final, int length)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < length)
{
int block_index = (int)(idx / BLOCK_SIZE); // 当前数据属于第几个块
if (block_index != 0)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index - 1];
}
else
{
out_final[idx] = in_first_scan_result[idx];
}
}
}
/*
递归函数
d_in 输入的设备指针
d_out 指向扫描输出数组的二级指针
length 计算长度
*/
void scanFunc(int *d_in, int **d_out, int length)
{
//(1)先做一遍扫描
int *d_first_scan_result; //存储第一次扫描后的每个块内前缀和
cudaMalloc((void **)&d_first_scan_result, length * sizeof(int));
int Grid_Size = ceil((double)length / BLOCK_SIZE);
int *d_first_scan_sum_of_each_block; // 辅助数组:存储第一次扫描后每个扫描块内部总和
cudaMalloc((void **)&d_first_scan_sum_of_each_block, Grid_Size * sizeof(int));
Hillis_Steele_scan_kernel<<<Grid_Size, BLOCK_SIZE>>>(d_in, d_first_scan_result, d_first_scan_sum_of_each_block, length);
cudaDeviceSynchronize();
// 如果剩下的只需要一个block
// 那么d_first_scan_result就是最终的前缀和了,如有递归,此时结束
if (Grid_Size == 1)
{
*d_out = d_first_scan_result;
cudaFree(d_first_scan_sum_of_each_block);
return;
}
//(2)对辅助数组再做一遍扫描,再次扫描也是递归的过程
int *d_second_scan_result; // 第二次扫描的结果,就是对辅助数组求前缀和
scanFunc(d_first_scan_sum_of_each_block, &d_second_scan_result, Grid_Size);
//(3)将辅助数组扫描结果加到第一步扫描结果中
int *d_fan_result; // 本轮递归的最终数组
cudaMalloc((void **)&d_fan_result, length * sizeof(int));
fan_elements<<<Grid_Size, BLOCK_SIZE>>>(d_first_scan_result, d_second_scan_result, d_fan_result, length);
cudaDeviceSynchronize();
*d_out = d_fan_result;
cudaFree(d_first_scan_result);
cudaFree(d_first_scan_sum_of_each_block);
cudaFree(d_second_scan_result);
}
int main(int argc, char **argv)
{
int N = (1 << 20);
if (argc == 2)
{
N = (1 << atoi(argv[1]));
}
// 主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in, N);
// 设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in, N * sizeof(int));
cudaMemcpy(d_in, h_in, N * sizeof(int), cudaMemcpyHostToDevice);
// 主机串行计算并计时
int *seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
seq_result[0] = h_in[0];
for (int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i - 1] + h_in[i];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
// 设备输出结果内存
int *d_out;
// 并行归约计算并计时
cudaEvent_t start, stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
scanFunc(d_in, &d_out, N);
// 结束计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); // 每个线程块一个输出
cudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);
checkResult(seq_result, h_out, N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10), cpu_time);
printf("任意长度扫描,单块使用Hillis Steele 扫描(两次同步),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time, (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}/*
任意长度扫描 单块使用Hillis Steele算法 double buffer
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 9)
/*
使用Hillis_Steele进行扫描
in_data 输入数据
out_scan_result 每个扫描块的前缀和结果数组(闭扫描)
out_sum_of_each_block 每个扫描块的总和数组(辅助数组)
length 计算数据大小
*/
__global__ void Hillis_Steele_double_buffer(int *in_data, int *out_scan_result , int *out_sum_of_each_block, int length)
{
//每个线程取一个元素到共享内存中的读缓冲区
__shared__ int s_out_data[2 * BLOCK_SIZE]; //共享内存地址翻倍
int tid = threadIdx.x;
int idx = blockIdx.x * blockDim.x + tid;
int pread = 0 , pwrite = 1; //pwrite表示写缓冲区,pread表示读缓冲区
if (idx < length)
s_out_data[pread * BLOCK_SIZE + tid] = in_data[idx];
__syncthreads();
//在共享内存上算前缀和,往前找元素的步长每轮翻倍
for (int s = 1; s < length; s <<= 1)
{
if (tid >= s) //从读缓冲区读数到写缓冲区,修改的只是写缓冲内容,避免了竞争
s_out_data[pwrite * BLOCK_SIZE + tid] = s_out_data[pread * BLOCK_SIZE + tid - s] + s_out_data[pread * BLOCK_SIZE + tid];
else
s_out_data[pwrite * BLOCK_SIZE + tid] = s_out_data[pread * BLOCK_SIZE + tid];
__syncthreads();
pread = 1 - pread , pwrite = 1 - pwrite; //读写缓冲交换
}
if(idx < length)
{
out_scan_result[idx] = s_out_data[pread * BLOCK_SIZE + tid];
if(tid == (BLOCK_SIZE - 1)) //将每个扫描块扫描结果的最后一个值作为扫描块的总和
out_sum_of_each_block[blockIdx.x] = s_out_data[pread * BLOCK_SIZE + tid];
}
}
/*
fan 扇出,将扫描后的总和数组扇出到各个扫描块上
in_first_scan_result 第一遍扫描结果,存储每个扫描块的前缀和结果数组
in_scan_of_sum 对辅助数组做前缀和的结果数组
out_final 该轮递归的最终前缀和结果数组
length 计算数据大小
*/
__global__ void fan_elements(int *in_first_scan_result, int *in_scan_of_sum,
int *out_final, int length)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < length)
{
int block_index = (int)(idx / BLOCK_SIZE); // 当前数据属于第几个块
if (block_index != 0)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index - 1];
}
else
{
out_final[idx] = in_first_scan_result[idx];
}
}
}
/*
递归函数
d_in 输入的设备指针
d_out 指向扫描输出数组的二级指针
length 计算长度
*/
void scanFunc(int *d_in, int **d_out, int length)
{
//(1)先做一遍扫描
int *d_first_scan_result; //存储第一次扫描后的每个块内前缀和
cudaMalloc((void **)&d_first_scan_result, length * sizeof(int));
int Grid_Size = ceil((double)length / BLOCK_SIZE);
int *d_first_scan_sum_of_each_block; // 辅助数组:存储第一次扫描后每个扫描块内部总和
cudaMalloc((void **)&d_first_scan_sum_of_each_block, Grid_Size * sizeof(int));
Hillis_Steele_double_buffer<<<Grid_Size, BLOCK_SIZE>>>(d_in, d_first_scan_result, d_first_scan_sum_of_each_block, length);
cudaDeviceSynchronize();
// 如果剩下的只需要一个block
// 那么d_first_scan_result就是最终的前缀和了,如有递归,此时结束
if (Grid_Size == 1)
{
*d_out = d_first_scan_result;
cudaFree(d_first_scan_sum_of_each_block);
return;
}
//(2)对辅助数组再做一遍扫描,再次扫描也是递归的过程
int *d_second_scan_result; // 第二次扫描的结果,就是对辅助数组求前缀和
scanFunc(d_first_scan_sum_of_each_block, &d_second_scan_result, Grid_Size);
//(3)将辅助数组扫描结果加到第一步扫描结果中
int *d_fan_result; // 本轮递归的最终数组
cudaMalloc((void **)&d_fan_result, length * sizeof(int));
fan_elements<<<Grid_Size, BLOCK_SIZE>>>(d_first_scan_result, d_second_scan_result, d_fan_result, length);
cudaDeviceSynchronize();
*d_out = d_fan_result;
cudaFree(d_first_scan_result);
cudaFree(d_first_scan_sum_of_each_block);
cudaFree(d_second_scan_result);
}
int main(int argc, char **argv)
{
int N = (1 << 20);
if (argc == 2)
{
N = (1 << atoi(argv[1]));
}
// 主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in, N);
// 设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in, N * sizeof(int));
cudaMemcpy(d_in, h_in, N * sizeof(int), cudaMemcpyHostToDevice);
// 主机串行计算并计时
int *seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
seq_result[0] = h_in[0];
for (int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i - 1] + h_in[i];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
// 设备输出结果内存
int *d_out;
// 并行归约计算并计时
cudaEvent_t start, stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
scanFunc(d_in, &d_out, N);
// 结束计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); // 每个线程块一个输出
cudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);
checkResult(seq_result, h_out, N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10), cpu_time);
printf("任意长度扫描,单块使用Hillis Steele 扫描(double buffer),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time, (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
Blelloch算法 - 未消除bank confilct
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 9)
/*
Blelloch算法 - 未消除bank confilct
in_data 输入数据
out_scan_result 每个扫描块的前缀和结果数组(开扫描)
out_sum_of_each_block 每个扫描块的总和数组(辅助数组)
length 计算数据大小
*/
__global__ void Blelloch_scan_with_bank_conflict(int *in_data, int *out_scan_result, int *out_sum_of_each_block, int length)
{
// 每个线程取两个元素到共享内存,一个线程块负责的扫描块大小等于线程块大小的两倍
int tid = threadIdx.x;
__shared__ int s_out_data[2 * BLOCK_SIZE];
int Block_offset = blockIdx.x * 2 * BLOCK_SIZE; // 块间的偏移量
if ((Block_offset + 2 * tid) < length)
s_out_data[2 * tid] = in_data[Block_offset + 2 * tid];
if ((Block_offset + 2 * tid + 1) < length)
s_out_data[2 * tid + 1] = in_data[Block_offset + 2 * tid + 1];
// 第一阶段 reduce
for (int s = 1; s <= BLOCK_SIZE; s <<= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if (index < (2 * BLOCK_SIZE))
{
s_out_data[index] += s_out_data[index - s];
}
}
// 把最后一个元素清0
if (tid == 0)
{
s_out_data[2 * BLOCK_SIZE - 1] = 0;
}
// 第二阶段 down sweep
for (int s = BLOCK_SIZE; s > 0; s >>= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if (index < (2 * BLOCK_SIZE))
{
int tmp = s_out_data[index];
s_out_data[index] += s_out_data[index - s];
s_out_data[index - s] = tmp;
}
}
__syncthreads();
// 将扫描结果写回全局内存,并计算块内总和
if ((Block_offset + 2 * tid) < length)
{
out_scan_result[Block_offset + 2 * tid] = s_out_data[2 * tid];
// 因为是开扫描,要将每个扫描块扫描结果的最后一个值 + 每个扫描块原始数据的最后一个值才能得到每个扫描块内的总和
if (2 * tid == (2 * BLOCK_SIZE - 1)) // 如果线程块大小是奇数,让最后一个线程去计算块内总和
{
out_sum_of_each_block[blockIdx.x] = s_out_data[2 * tid] + in_data[Block_offset + 2 * tid];
}
}
if ((Block_offset + 2 * tid + 1) < length)
{
out_scan_result[Block_offset + 2 * tid + 1] = s_out_data[2 * tid + 1];
if ((2 * tid + 1) == (2 * BLOCK_SIZE - 1)) // 如果线程块大小是偶数,让最后一个线程去计算块内总和
{
out_sum_of_each_block[blockIdx.x] = s_out_data[2 * tid + 1] + in_data[Block_offset + 2 * tid + 1];
}
}
}
/*
fan 扇出,将扫描后的总和数组扇出到各个扫描块上 同样一个线程块处理两倍线程块大小的扫描块
in_first_scan_result 第一遍扫描结果,存储每个扫描块的前缀和结果数组,从Blelloch_scan_with_bank_conflict中得到
in_scan_of_sum 对辅助数组做前缀和的结果数组
out_final 该轮递归的最终前缀和结果数组
length 计算数据大小
*/
__global__ void fan_elements(int *in_first_scan_result, int *in_scan_of_sum, int *out_final, int length)
{
int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x * 2;
int block_index = (int)(idx / (BLOCK_SIZE * 2)); // 注意一个线程块对应两个扫描块,所以两个为一组,这里算的是当前数据属于第几组
if (idx < length)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index];
}
idx += 1;
block_index = (int)(idx / (BLOCK_SIZE * 2)); // 当前数据属于第几个块
if (idx < length)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index];
}
}
/*
递归函数
d_in 输入的设备指针
d_out 指向扫描输出数组的二级指针
length 计算长度
*/
void scanFunc(int *d_in, int **d_out, int length)
{
//(1)先做一遍扫描
int *d_first_scan_result; // 存储第一次扫描后的每个块内前缀和
cudaMalloc((void **)&d_first_scan_result, length * sizeof(int));
int Grid_Size = ceil((double)length / (BLOCK_SIZE * 2)); // 注意只需要用一半的block
int *d_first_scan_sum_of_each_block; // 辅助数组:存储第一次扫描后每个扫描块内部总和
cudaMalloc((void **)&d_first_scan_sum_of_each_block, Grid_Size * sizeof(int));
Blelloch_scan_with_bank_conflict<<<Grid_Size, BLOCK_SIZE>>>(d_in, d_first_scan_result, d_first_scan_sum_of_each_block, length);
cudaDeviceSynchronize();
// 如果剩下的只需要一个block
// 那么d_first_scan_result就是最终的前缀和了,如有递归,此时结束
if (Grid_Size == 1)
{
*d_out = d_first_scan_result;
cudaFree(d_first_scan_sum_of_each_block);
return;
}
//(2)对辅助数组继续做扫描
int *d_second_scan_result; // 辅助数组的前缀和
scanFunc(d_first_scan_sum_of_each_block, &d_second_scan_result, Grid_Size);
//(3)将做完前缀和的辅助数组加到前缀和数组上
int *d_fan_result; // 本轮递归的最终数组
cudaMalloc((void **)&d_fan_result, length * sizeof(int));
fan_elements<<<Grid_Size, BLOCK_SIZE>>>(d_first_scan_result, d_second_scan_result, d_fan_result, length);
cudaDeviceSynchronize();
*d_out = d_fan_result;
cudaFree(d_first_scan_result);
cudaFree(d_first_scan_sum_of_each_block);
cudaFree(d_second_scan_result);
}
int main(int argc, char **argv)
{
int N = (1 << 20);
if (argc == 2)
{
N = (1 << atoi(argv[1]));
}
// 主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in, N);
// 设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in, N * sizeof(int));
cudaMemcpy(d_in, h_in, N * sizeof(int), cudaMemcpyHostToDevice);
// 主机串行计算并计时
int *seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
// 开扫描
seq_result[0] = 0;
for (int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i - 1] + h_in[i - 1];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
// 设备输出结果内存
int *d_out;
// 并行归约计算并计时
cudaEvent_t start, stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
scanFunc(d_in, &d_out, N);
// 结束计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); // 每个线程块一个输出
cudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);
checkResult(seq_result, h_out, N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10), cpu_time);
printf("任意长度扫描,单块使用Blelloch算法(有bank conflict),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time, (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
Blelloch算法 - 消除bank confilct
chmod +x run.sh && ./run.sh
*/
#include <stdio.h>
#include "common.h"
#define BLOCK_SIZE (1 << 9)
/*
Blelloch算法 - 消除bank confilct
in_data 输入数据
out_scan_result 每个扫描块的前缀和结果数组(开扫描)
out_sum_of_each_block 每个扫描块的总和数组(辅助数组)
length 计算数据大小
*/
__global__ void Blelloch_scan_bank_conflict_optimization(int *in_data, int *out_scan_result, int *out_sum_of_each_block, int length)
{
// 每个线程取两个元素到共享内存,一个线程块负责的扫描块大小等于线程块大小的两倍
int tid = threadIdx.x;
__shared__ int s_out_data[2 * BLOCK_SIZE + (2 * BLOCK_SIZE >> 5)];
int Block_offset = blockIdx.x * 2 * BLOCK_SIZE; // 扫描块间的偏移量,当前扫描块之前的大小
if ((Block_offset + 2 * tid) < length)
s_out_data[2 * tid + CONFLICT_FREE_OFFSET(2 * tid)] = in_data[Block_offset + 2 * tid];
if ((Block_offset + 2 * tid + 1) < length)
s_out_data[2 * tid + 1 + CONFLICT_FREE_OFFSET(2 * tid + 1)] = in_data[Block_offset + 2 * tid + 1];
// 第一阶段 reduce
for (int s = 1; s <= BLOCK_SIZE; s <<= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if (index < (2 * BLOCK_SIZE))
{
s_out_data[index + CONFLICT_FREE_OFFSET(index)] += s_out_data[index - s + CONFLICT_FREE_OFFSET(index - s)];
}
}
// 把最后一个元素清0
if (tid == 0)
{
s_out_data[2 * BLOCK_SIZE - 1 + CONFLICT_FREE_OFFSET(2 * BLOCK_SIZE - 1)] = 0;
}
// 第二阶段 down sweep
for (int s = BLOCK_SIZE; s > 0; s >>= 1)
{
__syncthreads();
int index = 2 * s * (tid + 1) - 1;
if (index < (2 * BLOCK_SIZE))
{
int tmp = s_out_data[index + CONFLICT_FREE_OFFSET(index)];
s_out_data[index + CONFLICT_FREE_OFFSET(index)] += s_out_data[index - s + CONFLICT_FREE_OFFSET(index - s)];
s_out_data[index - s + CONFLICT_FREE_OFFSET(index - s)] = tmp;
}
}
__syncthreads();
// 将扫描结果写回全局内存,并计算块内总和数组
if ((Block_offset + 2 * tid) < length)
{
out_scan_result[Block_offset + 2 * tid] = s_out_data[2 * tid + CONFLICT_FREE_OFFSET(2 * tid)];
// 因为是开扫描,要将每个扫描块扫描结果的最后一个值 + 每个扫描块原始数据的最后一个值才能得到每个扫描块内的总和
if (2 * tid == (2 * BLOCK_SIZE - 1)) // 如果线程块大小是奇数,让最后一个线程去计算块内总和
{
out_sum_of_each_block[blockIdx.x] = s_out_data[2 * tid + CONFLICT_FREE_OFFSET(2 * tid)] + in_data[Block_offset + 2 * tid];
}
}
if ((Block_offset + 2 * tid + 1) < length)
{
out_scan_result[Block_offset + 2 * tid + 1] = s_out_data[2 * tid + 1 + CONFLICT_FREE_OFFSET(2 * tid + 1)];
if ((2 * tid + 1) == (2 * BLOCK_SIZE - 1)) // 如果线程块大小是偶数,让最后一个线程去计算块内总和
{
out_sum_of_each_block[blockIdx.x] = s_out_data[2 * tid + 1 + CONFLICT_FREE_OFFSET(2 * tid + 1)] + in_data[Block_offset + 2 * tid + 1];
}
}
}
/*
fan 扇出,将扫描后的总和数组扇出到各个扫描块上 同样一个线程块处理两倍线程块大小的扫描块
in_first_scan_result 第一遍扫描结果,存储每个扫描块的前缀和结果数组,从Blelloch_scan_with_bank_conflict中得到
in_scan_of_sum 对辅助数组做前缀和的结果数组
out_final 该轮递归的最终前缀和结果数组
length 计算数据大小
*/
__global__ void fan_elements(int *in_first_scan_result, int *in_scan_of_sum, int *out_final, int length)
{
int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x * 2;
int block_index = (int)(idx / (BLOCK_SIZE * 2)); // 注意一个线程块对应两个扫描块,所以两个为一组,这里算的是当前数据属于第几组
if (idx < length)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index];//对应相加
}
idx += 1;
block_index = (int)(idx / (BLOCK_SIZE * 2)); // 当前数据属于第几个块
if (idx < length)
{
out_final[idx] = in_first_scan_result[idx] + in_scan_of_sum[block_index];
}
}
/*
递归函数
d_in 输入的设备指针
d_out 指向扫描输出数组的二级指针
length 计算长度
*/
void scanFunc(int *d_in, int **d_out, int length)
{
//(1)先做一遍扫描
int *d_first_scan_result; // 存储第一次扫描后的每个块内前缀和
cudaMalloc((void **)&d_first_scan_result, length * sizeof(int));
int Grid_Size = ceil((double)length / (BLOCK_SIZE * 2)); // 注意只需要用一半的block
int *d_first_scan_sum_of_each_block; // 辅助数组:存储第一次扫描后每个扫描块内部总和
cudaMalloc((void **)&d_first_scan_sum_of_each_block, Grid_Size * sizeof(int));
Blelloch_scan_bank_conflict_optimization<<<Grid_Size, BLOCK_SIZE>>>(d_in, d_first_scan_result, d_first_scan_sum_of_each_block, length);
cudaDeviceSynchronize();
// 如果剩下的只需要一个block
// 那么d_first_scan_result就是最终的前缀和了,如有递归,此时结束
if (Grid_Size == 1)
{
*d_out = d_first_scan_result;
cudaFree(d_first_scan_sum_of_each_block);
return;
}
//(2)对辅助数组继续做扫描
int *d_second_scan_result; // 辅助数组的前缀和
scanFunc(d_first_scan_sum_of_each_block, &d_second_scan_result, Grid_Size);
//(3)将做完前缀和的辅助数组加到前缀和数组上
int *d_fan_result; // 本轮递归的最终数组
cudaMalloc((void **)&d_fan_result, length * sizeof(int));
fan_elements<<<Grid_Size, BLOCK_SIZE>>>(d_first_scan_result, d_second_scan_result, d_fan_result, length);
cudaDeviceSynchronize();
*d_out = d_fan_result;
cudaFree(d_first_scan_result);
cudaFree(d_first_scan_sum_of_each_block);
cudaFree(d_second_scan_result);
}
int main(int argc, char **argv)
{
int N = (1 << 20);
if (argc == 2)
{
N = (1 << atoi(argv[1]));
}
// 主机输入数据初始化
int *h_in = (int *)malloc(N * sizeof(int));
initialData(h_in, N);
// 设备输入数据初始化
int *d_in;
cudaMalloc((void **)&d_in, N * sizeof(int));
cudaMemcpy(d_in, h_in, N * sizeof(int), cudaMemcpyHostToDevice);
// 主机串行计算并计时
int *seq_result = (int *)malloc(N * sizeof(int));
double cpu_start = cpuSecond();
// 开扫描
seq_result[0] = 0;
for (int i = 1; i < N; i++)
{
seq_result[i] = seq_result[i - 1] + h_in[i - 1];
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
// 设备输出结果内存
int *d_out;
// 并行归约计算并计时
cudaEvent_t start, stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
scanFunc(d_in, &d_out, N);
// 结束计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
int *h_out = (int *)malloc(N * sizeof(int)); // 每个线程块一个输出
cudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);
checkResult(seq_result, h_out, N);
printf("计算%dKB数据,串行计算时间: %f ms\n", N / (1 << 10), cpu_time);
printf("任意长度扫描,单块使用Blelloch算法(消除bank conflict),CUDA并行计算时间为: %fms\n并行计算对比串行计算加速比为: %.4f\n\n",
gpu_time, (cpu_time / gpu_time));
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
/*
CUDA高性能计算库Thrust做scan
*/
#include <stdio.h>
#include <cuda_runtime.h>
#include <thrust/device_vector.h>
#include <thrust/scan.h>
#include "common.h"
int main(int argc,char *argv[])
{
int N = (1 << 20);
if (argc == 2)
{
N = (1 << atoi(argv[1]));
}
//主机输入数据初始化
int *ptr = (int *)malloc(N * sizeof(int));
initialData(ptr , N);
//设备输入数据初始化
int * d_ptr;
cudaMalloc((void**)&d_ptr, sizeof(int) * N);
cudaMemcpy(d_ptr, ptr, sizeof(int) * N, cudaMemcpyHostToDevice);
//并行scan计算并计时
cudaEvent_t start , stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start , 0);
thrust::inclusive_scan(thrust::device_pointer_cast(d_ptr), thrust::device_pointer_cast(d_ptr + 16) , thrust::device_pointer_cast(d_ptr));
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(ptr, d_ptr, sizeof(int) * 16, cudaMemcpyDeviceToHost);
//结束计时
cudaEventRecord(stop , 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start , stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
printf("扫描计算%dKB数据\n使用Thrust库扫描时间为: %fms\n", N / (1<<10) , gpu_time);
return 0;
}(base) [monkeycode2@th-es-ln0 4-2]$ sh run.sh
mkdir: 无法创建目录"bin": 文件已存在
nvcc -o bin/scan0 scan0.cu
nvcc -o bin/scan1 scan1.cu
nvcc -o bin/scan2 scan2.cu
nvcc -o bin/scan3 scan3.cu
nvcc -o bin/scan4 scan4.cu
nvcc -o bin/scan5 scan5.cu
nvcc -o bin/scan6 scan6.cu
nvcc -o bin/scan7 scan7.cu
nvcc -o bin/scan8 scan8.cu
nvcc -o bin/scan9 scan9.cu
==30693== NVPROF is profiling process 30693, command: ./bin/scan0
计算1KB数据,串行计算时间: 0.002146 ms
朴素扫描,CUDA并行计算时间为: 0.249504ms
并行计算对比串行计算加速比为: 0.0086
==30693== Profiling application: ./bin/scan0
==30693== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 95.82% 118.21us 1 118.21us 118.21us 118.21us simple_prefix _sum(int*, int*)
2.15% 2.6560us 1 2.6560us 2.6560us 2.6560us [CUDA memcpy DtoH]
2.02% 2.4960us 1 2.4960us 2.4960us 2.4960us [CUDA memcpy HtoD]
API calls: 98.46% 109.67ms 2 54.836ms 4.0030us 109.67ms cudaMalloc
0.73% 808.92us 2 404.46us 386.92us 422.00us cuDeviceTotal Mem
0.35% 388.74us 192 2.0240us 99ns 85.326us cuDeviceGetAt tribute
0.13% 146.84us 2 73.420us 12.313us 134.53us cudaFree
0.11% 124.82us 1 124.82us 124.82us 124.82us cudaEventSync hronize
0.11% 120.45us 1 120.45us 120.45us 120.45us cudaLaunchKer nel
0.05% 53.960us 2 26.980us 21.045us 32.915us cudaMemcpy
0.04% 39.865us 2 19.932us 18.130us 21.735us cuDeviceGetNa me
0.01% 12.540us 2 6.2700us 3.8680us 8.6720us cudaEventReco rd
0.01% 8.3140us 2 4.1570us 529ns 7.7850us cudaEventCrea te
0.01% 6.8560us 2 3.4280us 1.2760us 5.5800us cuDeviceGetPC IBusId
0.00% 3.2210us 4 805ns 156ns 2.4310us cuDeviceGet
0.00% 2.1570us 1 2.1570us 2.1570us 2.1570us cudaEventElap sedTime
0.00% 1.8070us 2 903ns 447ns 1.3600us cudaEventDest roy
0.00% 1.1020us 3 367ns 126ns 587ns cuDeviceGetCo unt
0.00% 388ns 2 194ns 168ns 220ns cuDeviceGetUu id
==9279== NVPROF is profiling process 9279, command: ./bin/scan1
==9279== Warning: Profiling results might be incorrect with current version of nvcc compil er used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correc t profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1KB数据,串行计算时间: 0.003099 ms
单块Hillis Steele 扫描(两次同步),CUDA并行计算时间为: 0.144928ms
并行计算对比串行计算加速比为: 0.0214
==9279== Profiling application: ./bin/scan1
==9279== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 65.98% 10.176us 1 10.176us 10.176us 10.176us Hillis_Steele _scan_kernel(int*, int*)
17.22% 2.6560us 1 2.6560us 2.6560us 2.6560us [CUDA memcpy DtoH]
16.80% 2.5920us 1 2.5920us 2.5920us 2.5920us [CUDA memcpy HtoD]
API calls: 98.54% 110.70ms 2 55.349ms 3.9600us 110.69ms cudaMalloc
0.73% 814.69us 2 407.35us 391.16us 423.53us cuDeviceTotal Mem
0.36% 408.56us 192 2.1270us 99ns 94.046us cuDeviceGetAt tribute
0.12% 136.13us 2 68.066us 12.169us 123.96us cudaFree
0.11% 122.90us 1 122.90us 122.90us 122.90us cudaLaunchKer nel
0.05% 53.584us 2 26.792us 21.228us 32.356us cudaMemcpy
0.04% 42.339us 2 21.169us 18.667us 23.672us cuDeviceGetNa me
0.02% 17.360us 1 17.360us 17.360us 17.360us cudaEventSync hronize
0.01% 11.400us 2 5.7000us 3.5160us 7.8840us cudaEventReco rd
0.01% 8.5820us 4 2.1450us 154ns 5.9460us cuDeviceGet
0.01% 7.8780us 2 3.9390us 1.4700us 6.4080us cuDeviceGetPC IBusId
0.01% 7.7870us 2 3.8930us 578ns 7.2090us cudaEventCrea te
0.00% 1.9870us 1 1.9870us 1.9870us 1.9870us cudaEventElap sedTime
0.00% 1.8010us 2 900ns 482ns 1.3190us cudaEventDest roy
0.00% 1.1850us 3 395ns 131ns 554ns cuDeviceGetCo unt
0.00% 358ns 2 179ns 141ns 217ns cuDeviceGetUu id
==30731== NVPROF is profiling process 30731, command: ./bin/scan2
==30731== Warning: Profiling results might be incorrect with current version of nvcc compi ler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get corre ct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1KB数据,串行计算时间: 0.002146 ms
单块Hillis Steele 扫描(double buffer),CUDA并行计算时间为: 0.224416ms
并行计算对比串行计算加速比为: 0.0096
==30731== Profiling application: ./bin/scan2
==30731== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 60.93% 8.0320us 1 8.0320us 8.0320us 8.0320us Hillis_Steele _double_buffer(int*, int*)
20.14% 2.6550us 1 2.6550us 2.6550us 2.6550us [CUDA memcpy DtoH]
18.93% 2.4960us 1 2.4960us 2.4960us 2.4960us [CUDA memcpy HtoD]
API calls: 98.32% 108.97ms 2 54.486ms 3.8890us 108.97ms cudaMalloc
0.78% 865.65us 2 432.82us 406.41us 459.24us cuDeviceTotal Mem
0.44% 484.31us 192 2.5220us 102ns 126.63us cuDeviceGetAt tribute
0.19% 208.07us 1 208.07us 208.07us 208.07us cudaLaunchKer nel
0.13% 140.75us 2 70.377us 13.584us 127.17us cudaFree
0.05% 55.568us 2 27.784us 21.892us 33.676us cuDeviceGetNa me
0.05% 54.947us 2 27.473us 21.903us 33.044us cudaMemcpy
0.01% 16.339us 1 16.339us 16.339us 16.339us cudaEventSync hronize
0.01% 12.326us 2 6.1630us 3.8860us 8.4400us cudaEventReco rd
0.01% 7.8340us 2 3.9170us 514ns 7.3200us cudaEventCrea te
0.01% 7.2530us 2 3.6260us 1.3390us 5.9140us cuDeviceGetPC IBusId
0.00% 3.3790us 4 844ns 162ns 2.6420us cuDeviceGet
0.00% 2.2940us 1 2.2940us 2.2940us 2.2940us cudaEventElap sedTime
0.00% 2.1550us 2 1.0770us 525ns 1.6300us cudaEventDest roy
0.00% 1.1540us 3 384ns 112ns 620ns cuDeviceGetCo unt
0.00% 354ns 2 177ns 150ns 204ns cuDeviceGetUu id
==9327== NVPROF is profiling process 9327, command: ./bin/scan3
==9327== Warning: Profiling results might be incorrect with current version of nvcc compil er used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correc t profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1KB数据,串行计算时间: 0.003099 ms
单块Blelloch_scan 扫描(bank conflict),CUDA并行计算时间为: 0.175584ms
并行计算对比串行计算加速比为: 0.0177
==9327== Profiling application: ./bin/scan3
==9327== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 77.34% 17.696us 1 17.696us 17.696us 17.696us Blelloch_scan _with_bank_conflict(int*, int*)
11.61% 2.6560us 1 2.6560us 2.6560us 2.6560us [CUDA memcpy DtoH]
11.05% 2.5280us 1 2.5280us 2.5280us 2.5280us [CUDA memcpy HtoD]
API calls: 98.50% 110.20ms 2 55.100ms 4.0680us 110.20ms cudaMalloc
0.72% 810.06us 2 405.03us 387.27us 422.79us cuDeviceTotal Mem
0.37% 417.53us 192 2.1740us 101ns 104.09us cuDeviceGetAt tribute
0.13% 148.39us 1 148.39us 148.39us 148.39us cudaLaunchKer nel
0.12% 137.83us 2 68.917us 12.472us 125.36us cudaFree
0.05% 57.239us 2 28.619us 21.964us 35.275us cudaMemcpy
0.04% 41.205us 2 20.602us 18.448us 22.757us cuDeviceGetNa me
0.02% 26.403us 1 26.403us 26.403us 26.403us cudaEventSync hronize
0.01% 12.886us 2 6.4430us 3.7630us 9.1230us cudaEventReco rd
0.01% 8.5680us 2 4.2840us 516ns 8.0520us cudaEventCrea te
0.01% 6.8610us 2 3.4300us 1.4160us 5.4450us cuDeviceGetPC IBusId
0.00% 3.3890us 4 847ns 132ns 2.5770us cuDeviceGet
0.00% 2.3610us 1 2.3610us 2.3610us 2.3610us cudaEventElap sedTime
0.00% 1.9050us 2 952ns 508ns 1.3970us cudaEventDest roy
0.00% 1.1950us 3 398ns 117ns 607ns cuDeviceGetCo unt
0.00% 380ns 2 190ns 176ns 204ns cuDeviceGetUu id
==30769== NVPROF is profiling process 30769, command: ./bin/scan4
==30769== Warning: Profiling results might be incorrect with current version of nvcc compi ler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get corre ct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1KB数据,串行计算时间: 0.002861 ms
单块Blelloch_scan 扫描(消除bank conflict),CUDA并行计算时间为: 0.162496ms
并行计算对比串行计算加速比为: 0.0176
==30769== Profiling application: ./bin/scan4
==30769== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 72.00% 13.248us 1 13.248us 13.248us 13.248us Blelloch_scan _bank_conflict_optimization(int*, int*)
14.43% 2.6560us 1 2.6560us 2.6560us 2.6560us [CUDA memcpy DtoH]
13.57% 2.4960us 1 2.4960us 2.4960us 2.4960us [CUDA memcpy HtoD]
API calls: 98.54% 113.63ms 2 56.814ms 3.6510us 113.62ms cudaMalloc
0.70% 811.28us 2 405.64us 387.46us 423.82us cuDeviceTotal Mem
0.37% 423.77us 192 2.2070us 102ns 107.71us cuDeviceGetAt tribute
0.13% 154.19us 2 77.094us 12.668us 141.52us cudaFree
0.12% 141.12us 1 141.12us 141.12us 141.12us cudaLaunchKer nel
0.05% 53.733us 2 26.866us 21.331us 32.402us cudaMemcpy
0.04% 41.074us 2 20.537us 18.665us 22.409us cuDeviceGetNa me
0.02% 21.151us 1 21.151us 21.151us 21.151us cudaEventSync hronize
0.01% 12.097us 2 6.0480us 3.8820us 8.2150us cudaEventReco rd
0.01% 7.6470us 2 3.8230us 549ns 7.0980us cudaEventCrea te
0.01% 6.9180us 2 3.4590us 1.3330us 5.5850us cuDeviceGetPC IBusId
0.00% 3.2500us 4 812ns 158ns 2.5030us cuDeviceGet
0.00% 2.2590us 1 2.2590us 2.2590us 2.2590us cudaEventElap sedTime
0.00% 1.8860us 2 943ns 476ns 1.4100us cudaEventDest roy
0.00% 1.0870us 3 362ns 118ns 627ns cuDeviceGetCo unt
0.00% 329ns 2 164ns 157ns 172ns cuDeviceGetUu id
==9366== NVPROF is profiling process 9366, command: ./bin/scan5
==9366== Warning: Profiling results might be incorrect with current version of nvcc compil er used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correc t profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1024KB数据,串行计算时间: 4.316807 ms
任意长度扫描,单块使用Hillis Steele 扫描(两次同步),CUDA并行计算时间为: 1.828640ms
并行计算对比串行计算加速比为: 2.3607
==9366== Profiling application: ./bin/scan5
==9366== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 59.05% 1.4560ms 1 1.4560ms 1.4560ms 1.4560ms [CUDA memcpy DtoH]
22.75% 561.02us 1 561.02us 561.02us 561.02us [CUDA memcpy HtoD]
14.62% 360.57us 3 120.19us 7.5520us 344.86us Hillis_Steele _scan_kernel(int*, int*, int*, int)
3.58% 88.255us 2 44.127us 4.5760us 83.679us fan_elements( int*, int*, int*, int)
API calls: 94.68% 114.45ms 9 12.717ms 2.0460us 114.06ms cudaMalloc
2.48% 3.0039ms 2 1.5020ms 570.85us 2.4331ms cudaMemcpy
1.18% 1.4292ms 9 158.80us 2.4670us 585.87us cudaFree
0.67% 812.21us 2 406.10us 394.28us 417.93us cuDeviceTotal Mem
0.40% 487.25us 5 97.449us 11.116us 356.90us cudaDeviceSyn chronize
0.33% 404.56us 192 2.1070us 101ns 88.962us cuDeviceGetAt tribute
0.16% 194.67us 5 38.934us 6.1150us 158.83us cudaLaunchKer nel
0.04% 44.934us 2 22.467us 19.291us 25.643us cuDeviceGetNa me
0.01% 13.784us 2 6.8920us 4.3210us 9.4630us cudaEventReco rd
0.01% 11.455us 1 11.455us 11.455us 11.455us cudaEventSync hronize
0.01% 9.3190us 2 4.6590us 540ns 8.7790us cudaEventCrea te
0.01% 8.9030us 2 4.4510us 1.8180us 7.0850us cuDeviceGetPC IBusId
0.00% 3.9100us 1 3.9100us 3.9100us 3.9100us cudaEventElap sedTime
0.00% 3.8410us 4 960ns 151ns 2.9720us cuDeviceGet
0.00% 1.4790us 2 739ns 427ns 1.0520us cudaEventDest roy
0.00% 1.3370us 3 445ns 120ns 695ns cuDeviceGetCo unt
0.00% 620ns 2 310ns 246ns 374ns cuDeviceGetUu id
==30807== NVPROF is profiling process 30807, command: ./bin/scan6
==30807== Warning: Profiling results might be incorrect with current version of nvcc compi ler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get corre ct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1024KB数据,串行计算时间: 4.267931 ms
任意长度扫描,单块使用Hillis Steele 扫描(double buffer),CUDA并行计算时间为: 2.220480ms
并行计算对比串行计算加速比为: 1.9221
==30807== Profiling application: ./bin/scan6
==30807== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 51.45% 1.4770ms 1 1.4770ms 1.4770ms 1.4770ms [CUDA memcpy DtoH]
25.68% 737.28us 3 245.76us 4.0640us 724.06us Hillis_Steele _double_buffer(int*, int*, int*, int)
19.73% 566.40us 1 566.40us 566.40us 566.40us [CUDA memcpy HtoD]
3.13% 89.920us 2 44.960us 4.1920us 85.728us fan_elements( int*, int*, int*, int)
API calls: 94.26% 114.17ms 9 12.685ms 1.9630us 113.77ms cudaMalloc
2.54% 3.0721ms 2 1.5360ms 564.70us 2.5074ms cudaMemcpy
1.18% 1.4324ms 9 159.16us 2.3040us 584.49us cudaFree
0.72% 866.63us 5 173.33us 10.746us 736.09us cudaDeviceSyn chronize
0.70% 853.18us 2 426.59us 417.43us 435.75us cuDeviceTotal Mem
0.36% 433.14us 192 2.2550us 112ns 102.10us cuDeviceGetAt tribute
0.16% 195.86us 5 39.172us 5.7980us 161.70us cudaLaunchKer nel
0.03% 41.542us 2 20.771us 19.221us 22.321us cuDeviceGetNa me
0.01% 13.429us 2 6.7140us 4.1560us 9.2730us cudaEventReco rd
0.01% 11.324us 1 11.324us 11.324us 11.324us cudaEventSync hronize
0.01% 9.6210us 2 4.8100us 556ns 9.0650us cudaEventCrea te
0.01% 8.0160us 2 4.0080us 1.8590us 6.1570us cuDeviceGetPC IBusId
0.00% 3.8390us 1 3.8390us 3.8390us 3.8390us cudaEventElap sedTime
0.00% 3.0640us 4 766ns 155ns 2.3130us cuDeviceGet
0.00% 1.5420us 2 771ns 417ns 1.1250us cudaEventDest roy
0.00% 1.0490us 3 349ns 99ns 524ns cuDeviceGetCo unt
0.00% 372ns 2 186ns 152ns 220ns cuDeviceGetUu id
==9404== NVPROF is profiling process 9404, command: ./bin/scan7
==9404== Warning: Profiling results might be incorrect with current version of nvcc compil er used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correc t profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1024KB数据,串行计算时间: 4.492044 ms
任意长度扫描,单块使用Blelloch算法(有bank conflict),CUDA并行计算时间为: 1.862976ms
并行计算对比串行计算加速比为: 2.4112
==9404== Profiling application: ./bin/scan7
==9404== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 57.24% 1.4467ms 1 1.4467ms 1.4467ms 1.4467ms [CUDA memcpy DtoH]
22.32% 564.22us 1 564.22us 564.22us 564.22us [CUDA memcpy HtoD]
17.30% 437.28us 2 218.64us 17.504us 419.77us Blelloch_scan _with_bank_conflict(int*, int*, int*, int)
3.14% 79.359us 1 79.359us 79.359us 79.359us fan_elements( int*, int*, int*, int)
API calls: 94.40% 110.40ms 6 18.401ms 2.1380us 110.00ms cudaMalloc
2.64% 3.0829ms 2 1.5414ms 565.67us 2.5172ms cudaMemcpy
1.22% 1.4247ms 6 237.46us 5.4390us 582.86us cudaFree
0.69% 809.45us 2 404.73us 387.21us 422.25us cuDeviceTotal Mem
0.45% 523.02us 3 174.34us 22.923us 412.57us cudaDeviceSyn chronize
0.36% 417.04us 192 2.1720us 103ns 102.53us cuDeviceGetAt tribute
0.17% 197.24us 3 65.746us 11.486us 171.98us cudaLaunchKer nel
0.04% 41.734us 2 20.867us 18.146us 23.588us cuDeviceGetNa me
0.01% 13.253us 2 6.6260us 4.2820us 8.9710us cudaEventReco rd
0.01% 10.265us 1 10.265us 10.265us 10.265us cudaEventSync hronize
0.01% 9.5120us 2 4.7560us 549ns 8.9630us cudaEventCrea te
0.01% 7.5100us 2 3.7550us 1.3720us 6.1380us cuDeviceGetPC IBusId
0.00% 3.5180us 1 3.5180us 3.5180us 3.5180us cudaEventElap sedTime
0.00% 3.3290us 4 832ns 147ns 2.4410us cuDeviceGet
0.00% 1.5280us 2 764ns 436ns 1.0920us cudaEventDest roy
0.00% 1.1730us 3 391ns 127ns 561ns cuDeviceGetCo unt
0.00% 357ns 2 178ns 165ns 192ns cuDeviceGetUu id
==30845== NVPROF is profiling process 30845, command: ./bin/scan8
==30845== Warning: Profiling results might be incorrect with current version of nvcc compi ler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get corre ct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
计算1024KB数据,串行计算时间: 4.420996 ms
任意长度扫描,单块使用Blelloch算法(消除bank conflict),CUDA并行计算时间为: 1.758976ms
并行计算对比串行计算加速比为: 2.5134
==30845== Profiling application: ./bin/scan8
==30845== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 60.91% 1.4718ms 1 1.4718ms 1.4718ms 1.4718ms [CUDA memcpy DtoH]
23.52% 568.38us 1 568.38us 568.38us 568.38us [CUDA memcpy HtoD]
12.11% 292.64us 2 146.32us 12.160us 280.48us Blelloch_scan _bank_conflict_optimization(int*, int*, int*, int)
3.46% 83.679us 1 83.679us 83.679us 83.679us fan_elements( int*, int*, int*, int)
API calls: 94.41% 109.62ms 6 18.270ms 2.1510us 109.21ms cudaMalloc
2.66% 3.0882ms 2 1.5441ms 575.24us 2.5130ms cudaMemcpy
1.27% 1.4707ms 6 245.12us 6.1600us 586.07us cudaFree
0.74% 858.62us 2 429.31us 417.33us 441.29us cuDeviceTotal Mem
0.34% 397.79us 3 132.60us 18.133us 287.82us cudaDeviceSyn chronize
0.33% 388.00us 192 2.0200us 97ns 85.082us cuDeviceGetAt tribute
0.16% 190.33us 3 63.443us 10.890us 164.61us cudaLaunchKer nel
0.03% 39.445us 2 19.722us 17.719us 21.726us cuDeviceGetNa me
0.01% 14.184us 2 7.0920us 4.4870us 9.6970us cudaEventReco rd
0.01% 11.868us 1 11.868us 11.868us 11.868us cudaEventSync hronize
0.01% 10.118us 2 5.0590us 644ns 9.4740us cudaEventCrea te
0.01% 6.6870us 2 3.3430us 1.5220us 5.1650us cuDeviceGetPC IBusId
0.00% 3.6030us 1 3.6030us 3.6030us 3.6030us cudaEventElap sedTime
0.00% 2.9410us 4 735ns 147ns 2.1380us cuDeviceGet
0.00% 1.7070us 2 853ns 401ns 1.3060us cudaEventDest roy
0.00% 1.0910us 3 363ns 121ns 625ns cuDeviceGetCo unt
0.00% 334ns 2 167ns 126ns 208ns cuDeviceGetUu id
==9442== NVPROF is profiling process 9442, command: ./bin/scan9
==9442== Warning: Profiling results might be incorrect with current version of nvcc compil er used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correc t profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
扫描计算1024KB数据
使用Thrust库扫描时间为: 0.366080ms
==9442== Profiling application: ./bin/scan9
==9442== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 95.95% 568.89us 1 568.89us 568.89us 568.89us [CUDA memcpy HtoD]
3.04% 18.016us 1 18.016us 18.016us 18.016us void thrust:: cuda_cub::core::_kernel_agent<thrust::cuda_cub::__scan::ScanAgent<thrust::device_ptr<int>, thrust::device_ptr<int>, thrust::plus<int>, int, int, thrust::detail::integral_constant<b ool, bool=1>>, thrust::device_ptr<int>, thrust::device_ptr<int>, thrust::plus<int>, int, t hrust::cuda_cub::cub::ScanTileState<int, bool=1>, thrust::cuda_cub::__scan::DoNothing<int> >(thrust::device_ptr<int>, thrust::device_ptr<int>, int, thrust::plus<int>, int, int)
0.53% 3.1680us 1 3.1680us 3.1680us 3.1680us [CUDA memcpy DtoH]
0.48% 2.8480us 1 2.8480us 2.8480us 2.8480us void thrust:: cuda_cub::core::_kernel_agent<thrust::cuda_cub::__scan::InitAgent<thrust::cuda_cub::cub::S canTileState<int, bool=1>, int>, thrust::cuda_cub::cub::ScanTileState<int, bool=1>, int>(b ool=1, thrust::cuda_cub::cub::ScanTileState<int, bool=1>)
API calls: 97.97% 111.19ms 2 55.597ms 133.39us 111.06ms cudaMalloc
0.74% 836.40us 2 418.20us 387.13us 449.27us cuDeviceTotal Mem
0.53% 604.67us 2 302.33us 39.073us 565.60us cudaMemcpy
0.38% 435.16us 192 2.2660us 103ns 105.35us cuDeviceGetAt tribute
0.14% 158.94us 2 79.471us 9.5860us 149.36us cudaLaunchKer nel
0.12% 131.87us 1 131.87us 131.87us 131.87us cudaFree
0.04% 40.736us 2 20.368us 18.274us 22.462us cuDeviceGetNa me
0.02% 25.733us 1 25.733us 25.733us 25.733us cudaDeviceSyn chronize
0.01% 13.412us 3 4.4700us 930ns 8.2480us cudaEventReco rd
0.01% 12.313us 2 6.1560us 3.1100us 9.2030us cudaFuncGetAt tributes
0.01% 8.7710us 2 4.3850us 601ns 8.1700us cudaEventSync hronize
0.01% 8.1930us 2 4.0960us 599ns 7.5940us cudaEventCrea te
0.01% 7.2520us 2 3.6260us 1.3820us 5.8700us cuDeviceGetPC IBusId
0.00% 4.5700us 4 1.1420us 249ns 3.0200us cudaGetDevice
0.00% 3.4510us 4 862ns 137ns 2.6780us cuDeviceGet
0.00% 2.9240us 4 731ns 220ns 1.6400us cudaDeviceGet Attribute
0.00% 2.5240us 2 1.2620us 513ns 2.0110us cudaEventElap sedTime
0.00% 2.3040us 4 576ns 304ns 1.0850us cudaEventDest roy
0.00% 1.2130us 3 404ns 113ns 632ns cuDeviceGetCo unt
0.00% 811ns 4 202ns 101ns 433ns cudaPeekAtLas tError
0.00% 381ns 2 190ns 161ns 220ns cuDeviceGetUu id
0.00% 199ns 1 199ns 199ns 199ns cudaGetLastEr ror















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









