







什么是算符优先分析法
算符优先分析法是一种简单、直观的自下而上分析法
算符优先分析法就是仿照算术表达式的四则运算过程而设计的一种语法分析方法。
这种分析方法首先要规定运算符之间(确切地说终结符之间)的优先关系和结合性质,然后借助这种关系,比较相邻运算符的优先级来确定句型的可归约串并进行归约。
分析步骤为:
1、扩展文法
S’ →#S#
2、求FIRSTVT()和LASTVT()集合
firstvt(S)={ a,^,( }
firstvt(T)={ , } ∪ firstvt(S) = {, ,a,^,( }
lastvt(S)= { a,^,) }
lastvt(T) = { , } ∪ lastvt(S) = { , ,a,^,) }
3、求优先关系
3.1 首先找 等于关系(两个vt之间只隔一个vn)
3.2 低于关系(vt在右,vn在左)
3.3 高于关系(vn在左,vt在右)
4、构造优先关系表
5、算符优先分析过程
一、实验目的
运用算符优先语法分析的基本原理实现对于句子的语法分析
二、实验要求
1、文法及待分析符号串由用户输入
2、数据结构可自行设计
三、实验内容
1、任意输入一个文法,判断它是否为简单优先文法
2、如果是,请构造该文法对应的简单优先分析表
3、输入一个字符串,判断它是否为该文法的一个句子。
四、实验代码
#include <iostream>
#include <fstream>
#include <sstream>
#include <vector>
#include <stack>
#include <iomanip>
#include <cstdlib>
using namespace std;
string V[100][2]; //存储拆分后的文法
int vi = 0; //存储拆分后有多少行
int t = 0;
int s = 0;
int l;
int r;
string FIRSTVT[20][2]; //存储firstvt集
string LASTVT[20][2]; //存储lastvt集
string str; //存储输入文法
string str_a = "#"; // 下堆栈
string str_b; // 剩余输入串
string analysis_table[100][5]; // 文法分析过程
char table[100][100]; // 算符优先关系表
void init_string(string &a) // 删除字符串的第一个元素
{
for (int i = 1; i <= a.length(); ++i)
{
a[i - 1] = a[i];
}
}
bool is_CHAR(char c) // 判断是否为大写字母
{
if (c >= 'A' && c <= 'Z')
{
return true;
}
else
{
return false;
}
}
bool is_in(int i, string x) // 判断从字符串x从最好一个开始算起连续的i个字符是否含有非大写字母
{
bool flag = false;
for (int j = 0; j < i; j++)
{
if (!is_CHAR(x[x.length() - j - 1]))
{
flag = true;
}
}
return flag;
}
void split(string a) // 拆分文法,使其不含有|
{
for (int i = 3; i < a.length(); ++i)
{
V[vi][0] = a[0];
while (a[i] != '|' && i < a.length())
{
V[vi][1] += a[i];
i++;
}
vi++;
}
}
void read_file(string file_path) //按行读取文件
{
fstream f;
f.open(file_path.c_str());
vector<string> words;
string line;
while (getline(f, line))
{
words.push_back(line);
}
cout << "输入文法:" << endl;
for (int i = 0; i < words.size(); i++)
{
cout << words[i] << endl;
split(words[i]);
}
}
int find_index(char a) //寻找字符a在firstvt或者lastvt中的位置
{
for (int i = 0; i < t; ++i)
{
if (FIRSTVT[i][0][0] == a)
{
return i;
}
}
return -1;
}
int find_table_index(char a) //寻找字符a在算符优先关系表中的位置
{
for (int i = 0; i <= s; ++i)
{
if (table[i][0] == a)
{
return i;
}
}
return -1;
}
void get_start() //获取非终结符
{
for (int i = 0; i < vi; ++i)
{
bool flag = true;
for (int j = 0; j < t; ++j)
{
if (FIRSTVT[j][0] == V[i][0])
{
flag = false;
}
}
if (flag)
{
FIRSTVT[t][0] = V[i][0];
LASTVT[t][0] = V[i][0];
t++;
}
}
}
void add_firstvt(string b, int a) //判断字符串b是否在序号为a的firstvt中,没有则加入
{
for (int s = 0; s < b.length(); ++s)
{
bool flag = true;
char c = b[s];
if (c <= 'Z' && c >= 'A')
{
continue;
}
for (int i = 0; i < FIRSTVT[a][1].length(); ++i)
{
if (c == FIRSTVT[a][1][i])
{
flag = false;
}
}
if (flag)
{
FIRSTVT[a][1] += c;
}
}
}
void add_firstvt(char c, int a) //判断字符c是否在序号为a的firstvt中,没有则加入
{
bool flag = true;
for (int i = 0; i < FIRSTVT[a][1].length(); ++i)
{
if (c <= 'Z' && c >= 'A')
{
continue;
}
if (c == FIRSTVT[a][1][i])
{
flag = false;
}
}
if (flag)
{
FIRSTVT[a][1] += c;
}
}
void add_lastvt(string b, int a) //判断字符串b是否在序号为a的lastvt中,没有则加入
{
for (int s = 0; s < b.length(); ++s)
{
bool flag = true;
char c = b[s];
if (c <= 'Z' && c >= 'A')
{
continue;
}
for (int i = 0; i < LASTVT[a][1].length(); ++i)
{
if (c == LASTVT[a][1][i])
{
flag = false;
}
}
if (flag)
{
LASTVT[a][1] += c;
}
}
}
void add_lastvt(char c, int a) //判断字符串c是否在序号为a的lastvt中,没有则加入
{
bool flag = true;
for (int i = 0; i < LASTVT[a][1].length(); ++i)
{
if (c <= 'Z' && c >= 'A')
{
continue;
}
if (c == LASTVT[a][1][i])
{
flag = false;
}
}
if (flag)
{
LASTVT[a][1] += c;
}
}
string get_cur_firstvt(char c, int a) //获取当前字符的firstvt,并放入序号为a的firstvt中
{
string temp;
for (int i = 0; i < vi; ++i)
{
if (c == V[i][0][0])
{
if (!(V[i][1][0] <= 'Z' && V[i][1][0] >= 'A'))
{
add_firstvt(V[i][1][0], a);
}
else
{
if (c != V[i][1][0])
{
temp = get_cur_firstvt(V[i][1][0], find_index(V[i][1][0]));
add_firstvt(temp, a);
}
if (V[i][1].length() > 2)
{
if (!(V[i][1][1] <= 'Z' && V[i][1][1] >= 'A'))
{
add_firstvt(V[i][1][1], a);
}
}
}
}
}
return FIRSTVT[a][1];
}
string get_cur_lastvt(char c, int a) //获取当前字符的lastvt,并放入序号为a的lastvt中
{
string temp;
for (int i = 0; i < vi; ++i)
{
int s = V[i][1].length();
if (c == V[i][0][0])
{
if (!(V[i][1][s - 1] <= 'Z' && V[i][1][s - 1] >= 'A'))
{
add_lastvt(V[i][1][s - 1], a);
}
else
{
if (c != V[i][1][s - 1])
{
temp = get_cur_lastvt(V[i][1][s - 1], find_index(V[i][1][0]));
add_lastvt(temp, a);
}
if (V[i][1].length() > 2)
{
if (!(V[i][1][s - 2] <= 'Z' && V[i][1][s - 2] >= 'A'))
{
add_lastvt(V[i][1][s - 2], a);
}
}
}
}
}
return LASTVT[a][1];
}
void get_firstvt() //获取所有文法的firstvt
{
for (int i = 0; i < t; i++)
{
get_cur_firstvt(FIRSTVT[i][0][0], i);
}
}
void get_lastvt() //获取所有文法的lastvt
{
for (int i = 0; i < t; i++)
{
get_cur_lastvt(LASTVT[i][0][0], i);
}
}
void print_firstvt(string t, string a) //打印非终极符为t的firstvt
{
cout << "FIRSTVT(" << t << ") = {";
for (int i = 0; i < a.length(); ++i)
{
if (i == a.length() - 1)
{
cout << "\"" << a[i] << "\"";
}
else
{
cout << "\"" << a[i] << "\"" << ", ";
}
}
cout << "}" << endl;
}
void print_lastvt(string t, string a) //打印非终结符为t的lastvt
{
cout << "LASTVT(" << t << ") = {";
for (int i = 0; i < a.length(); ++i)
{
if (i == a.length() - 1)
{
cout << "\"" << a[i] << "\"";
}
else
{
cout << "\"" << a[i] << "\"" << ", ";
}
}
cout << "}" << endl;
}
void init_table() //初始化算符优先关系表
{
table[0][0] = '\\';
for (int i = 0; i < vi; ++i)
{
for (int j = 0; j < V[i][1].length(); ++j)
{
bool flag = true;
for (int k = 0; k < s + 1; ++k)
{
if (table[k + 1][0] == V[i][1][j] || (V[i][1][j] <= 'Z' && V[i][1][j] >= 'A'))
{
flag = false;
}
}
if (flag)
{
table[s + 1][0] = V[i][1][j];
table[0][s + 1] = V[i][1][j];
s++;
}
}
}
for (int l = 1; l < s + 1; ++l)
{
for (int i = 1; i < s + 1; ++i)
{
table[l][i] = ' ';
}
}
}
void get_table() //生成算符优先关系表
{
for (int i = 0; i < vi; ++i)
{
for (int j = 0; j < V[i][1].length(); ++j)
{
//ab
if (!(V[i][1][j] <= 'Z' && V[i][1][j] >= 'A') && !(V[i][1][j + 1] <= 'Z' && V[i][1][j + 1] >= 'A') &&
j + 1 < V[i][1].length())
{
table[find_table_index(V[i][1][j])][find_table_index(V[i][1][j + 1])] = '=';
}
//aQb
if ((!(V[i][1][j] <= 'Z' && V[i][1][j] >= 'A')) && (V[i][1][j + 1] <= 'Z' && V[i][1][j + 1] >= 'A') &&
(!(V[i][1][j + 2] <= 'Z' && V[i][1][j + 2] >= 'A')) && j + 2 < V[i][1].length())
{
table[find_table_index(V[i][1][j])][find_table_index(V[i][1][j + 2])] = '=';
}
//aQ
if ((!(V[i][1][j] <= 'Z' && V[i][1][j] >= 'A')) && (V[i][1][j + 1] <= 'Z' && V[i][1][j + 1] >= 'A') &&
j + 1 < V[i][1].length())
{
for (int k = 0; k < FIRSTVT[find_index(V[i][1][j + 1])][1].length(); ++k)
{
table[find_table_index(V[i][1][j])][find_table_index(
FIRSTVT[find_index(V[i][1][j + 1])][1][k])] = '<';
}
}
//Qa
if ((V[i][1][j] <= 'Z' && V[i][1][j] >= 'A') && !(V[i][1][j + 1] <= 'Z' && V[i][1][j + 1] >= 'A') &&
j + 1 < V[i][1].length())
{
for (int k = 0; k < LASTVT[find_index(V[i][1][j])][1].length(); ++k)
{
table[find_table_index(LASTVT[find_index(V[i][1][j])][1][k])][find_table_index(
V[i][1][j + 1])] = '>';
}
}
}
}
}
void print_table() //打印算符优先关系表
{
for (int i = 0; i < s + 1; ++i)
{
for (int j = 0; j < s + 1; ++j)
{
cout << table[i][j] << " ";
}
cout << endl;
}
}
char get_relationship(char a, char b) //获取终结符a,b的优先关系
{
return table[find_table_index(a)][find_table_index(b)];
}
bool is_reduce() //判断是否可以规约
{
for (int i = 0; i < vi; ++i)
{
int count = 0;
int f = str_a.length() - 1;
for (int j = V[i][1].length() - 1; j >= 0 && f >= 0; j--, f--)
{
if (is_in(V[i][1].length(), str_a))
{
if (is_CHAR(str_a[f]) && is_CHAR(V[i][1][j]))
{
count++;
}
else if (str_a[f] == V[i][1][j])
{
count++;
}
}
else
{
continue;
}
}
if (count == V[i][1].length())
{
r = i;
return true;
}
}
return false;
}
void analyze_input_string() // 生成算符优先文法的分析过程
{
analysis_table[0][0] = "步骤";
analysis_table[0][1] = "下堆栈";
analysis_table[0][2] = "优先关系";
analysis_table[0][3] = "剩余输入串";
analysis_table[0][4] = "移进或规约";
str_b = str;
char relationship;
l = 1;
int x;
stringstream ss;
while (true)
{
ss << l;
int index = str_a.length() - 1;
analysis_table[l][0] = ss.str();
analysis_table[l][3] = str_b;
analysis_table[l][1] = str_a;
ss.clear();
ss.str("");
if (is_CHAR(str_a[index]))
{
for (int i = str_a.length() - 1; i >= 0; i--)
{
if (!is_CHAR(str_a[i]))
{
index = i;
break;
}
}
}
relationship = get_relationship(str_a[index], str_b[0]);
analysis_table[l][2] = relationship;
if (relationship == '=')
{
if (str_a[index] == '#' && str_b[0] == '#')
{
analysis_table[l][4] = "完成";
break;
}
else
{
analysis_table[l][4] = "移进";
str_a += str_b[0];
analysis_table[l + 1][1] = str_a;
init_string(str_b);
}
}
else if (relationship == '<')
{
analysis_table[l][4] = "移进";
str_a += str_b[0];
analysis_table[l + 1][1] = str_a;
init_string(str_b);
}
else if (relationship == '>')
{
if (is_reduce())
{
analysis_table[l][4] = "规约";
str_a[str_a.length() - V[r][1].length()] = V[r][0][0];
str_a.erase(str_a.length() - V[r][1].length() + 1, V[r][1].length() - 1);
}
else
{
cout << "输入串非法" << endl;
exit(-1);
}
}
l++;
}
}
void print_analyze_process() //打印算符优先文法的分析过程
{
cout << "算符优先分析过程" << endl;
cout << setw(12) << analysis_table[0][0] << setw(16) << analysis_table[0][1] << setw(16) << analysis_table[0][2]
<< setw(24)
<< analysis_table[0][3] << setw(20)
<< analysis_table[0][4] << endl;
for (int i = 1; i <= l; ++i)
{
cout.width(10);
cout << analysis_table[i][0];
cout.width(12);
cout << analysis_table[i][1];
cout.width(10);
cout << analysis_table[i][2];
cout.width(20);
cout << analysis_table[i][3];
cout << analysis_table[i][4];
cout << endl;
}
}
int main(int argv, char *arg[])
{
cout.setf(std::ios::left);
read_file("D:\\in.txt");
cout << "拆分后文法:" << endl;
for (int i = 0; i < vi; ++i)
{
cout << V[i][0] << "->" << V[i][1] << endl;
}
cout << "非终结符:" << endl;
get_start();
for (int j = 0; j < t; ++j)
{
cout << FIRSTVT[j][0] << endl;
}
cout << "FIRSTVT:" << endl;
get_firstvt();
for (int k = 0; k < t; ++k)
{
print_firstvt(FIRSTVT[k][0], FIRSTVT[k][1]);
}
cout << "LASTVT:" << endl;
get_lastvt();
for (int k = 0; k < t; ++k)
{
print_lastvt(LASTVT[k][0], LASTVT[k][1]);
}
cout << "算符优先关系表" << endl;
init_table();
get_table();
print_table();
cout << "请输入文法并以#结束:" << endl;
cin >> str;
analyze_input_string();
print_analyze_process();
return 0;
}
//E→E+T∣T
//T→T*F∣F
//F→(E)∣i
五、测试结果
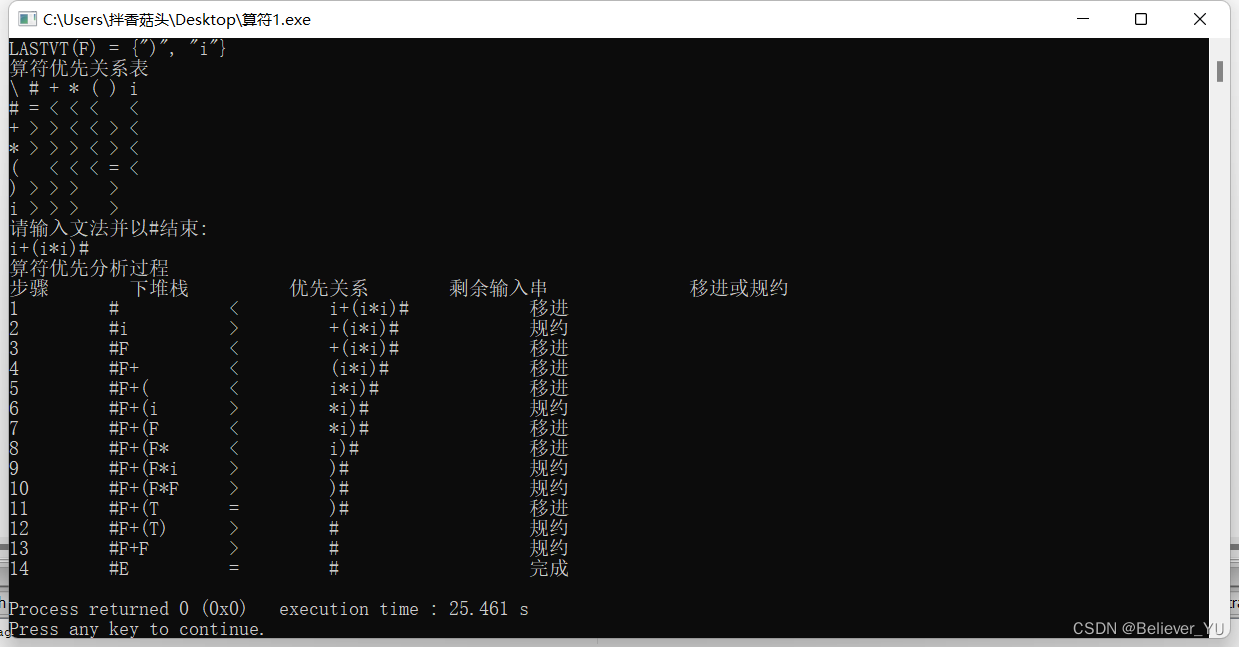
1.从文件中读取文法,然后构造优先表
2.输入待分析串,输出分析过程
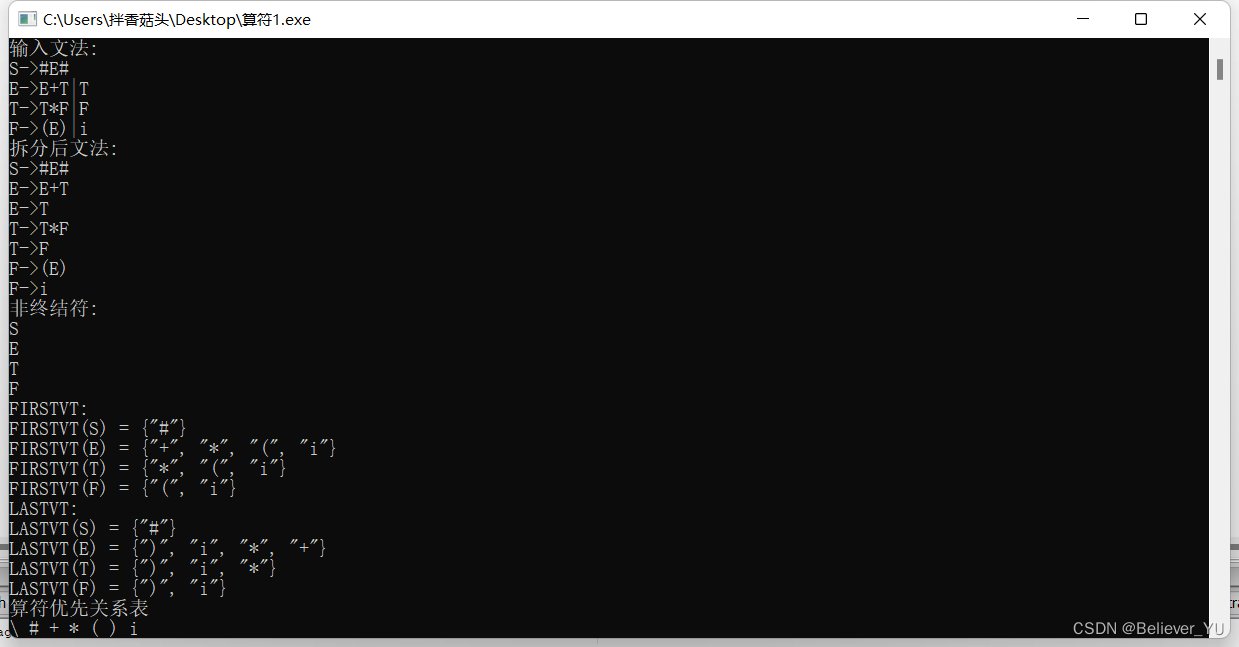
in.txt中文法为:
S->#E#
E->E+T|T
T->T*F|F
F->(E)|i














 1461
1461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









