






一、下载/安装
yum源里有可直接安装,也可直接官网wget下载请求
安装包放在 /usr/local/src
注意:Logstash需要jdk环境
二、 初步试用
1.启动
启动程序-----------------------> 并在命令行标准输入控制输入输出:
cd /usr/logstash/bin/ # cd 到存放命令的地方
./logstash -e 'input { stdin { type => stdin } } output { stdout { codec => rubydebug } } '
-
./logstash:(启动命令)这是调用Logstash可执行文件的命令。通常Logstash的可执行文件位于Logstash安装目录的bin子目录中。如果Logstash的安装目录已经添加到了系统的PATH环境变量中,那么可以直接使用logstash命令而不需要前面的./。 -
-e:这个选项允许你直接在命令行中指定Logstash的配置。 -
'input { stdin { type => stdin } } output { stdout { codec => rubydebug } }':这是Logstash的配置部分,用单引号括起来以确保整个字符串被当作一个参数传递给Logstash。input { stdin { type => stdin } }:这定义了Logstash的输入部分。它配置Logstash从标准输入(stdin)读取数据,并将这些数据的type字段设置为stdin。这有助于在后续处理中区分来自不同输入源的数据。output { stdout { codec => rubydebug } }:这定义了Logstash的输出部分。它配置Logstash将处理后的数据输出到标准输出(stdout),并使用rubydebug编解码器来格式化输出。rubydebug编解码器将输出格式化为Ruby对象的字符串表示形式,这对于调试和查看数据结构非常有用。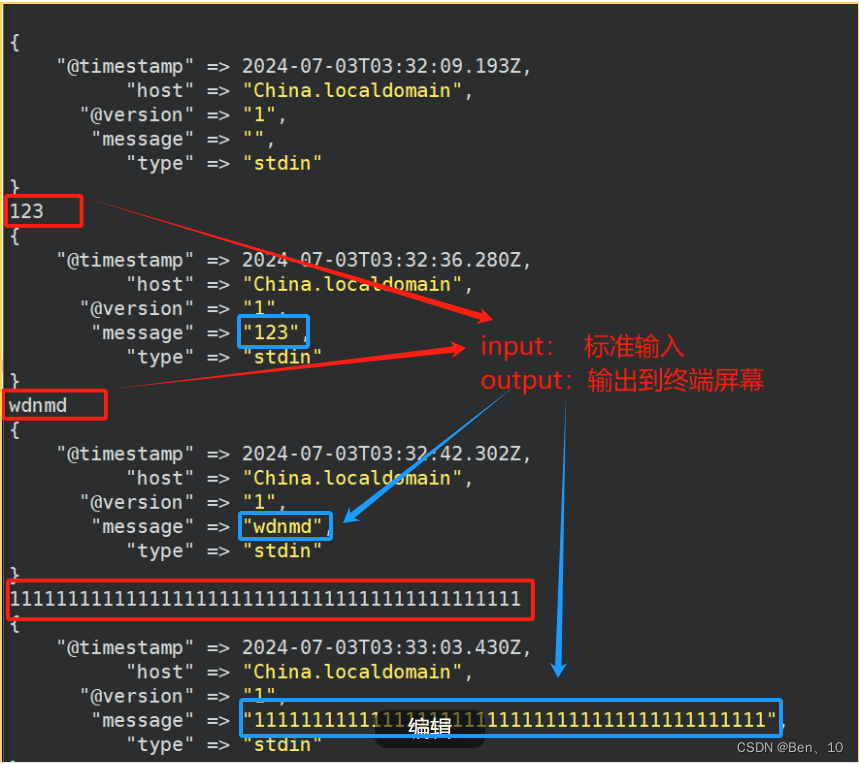
证明可用
- "@timestamp" => 2024-07-03T03:32:42.302Z, #这是事件发生的UTC时间戳,格式遵循ISO 8601标准。
- "host" => "China.localdomain", #表明产生此日志事件的服务器或设备的主 机名是“China.localdomain”。
- "@version" => "1", #这通常表示日志记录的格式或版本。
- "message" => "wdnmd", #这是日志消息的实际内容,但如上所述,这可能不是一 个有意义的日志消息。
- "type" => "stdin" #这表示日志事件是通过标准输入(stdin) 接收的。在一 些日志收集系统,比如Logstash中可以用来指示日志事件的来源。
2.编写配置文件
查看 /usr/local/logstash/config/下的文件有无 first-pipeline.conf 配置文件,没有就创建----------------------------(默认配置文件)
通过配置文件配置输入输出:
/usr/local/logstash/config/first-pipeline.conf
==============================输入部分======================================
input { stdin { } } #输入:标准输入(如键盘输入)
================================输出部分====================================
output { stdout { } } #输出:标准输出(如显示到终端屏幕)
测试并退出:
bin/logstash -f config/first-pipeline.conf --config.test_and_exit作用:测试 Logstash 配置文件 config/first-pipeline.conf 是否有效,而不会实际启动 Logstash 进程来处理数据。这个命令非常有用,因为它允许你在将配置文件部署到生产环境之前,检查配置文件中是否有语法错误或配置问题
bin/logstash:这是 Logstash 的启动脚本路径,通常位于 Logstash 安装目录的bin子目录下。-f config/first-pipeline.conf:-f参数后面跟的是 Logstash 配置文件的路径。在这个例子中,配置文件名为first-pipeline.conf,位于config目录下。这个配置文件定义了 Logstash 如何处理输入数据、过滤器(filters)如何转换数据,以及输出(outputs)如何发送数据。--config.test_and_exit:这个选项告诉 Logstash 只测试配置文件的语法和配置逻辑是否正确,一旦测试完成,Logstash 会退出而不启动处理流程。如果配置文件中有错误,Logstash 会输出错误信息,帮助用户定位问题。
成功: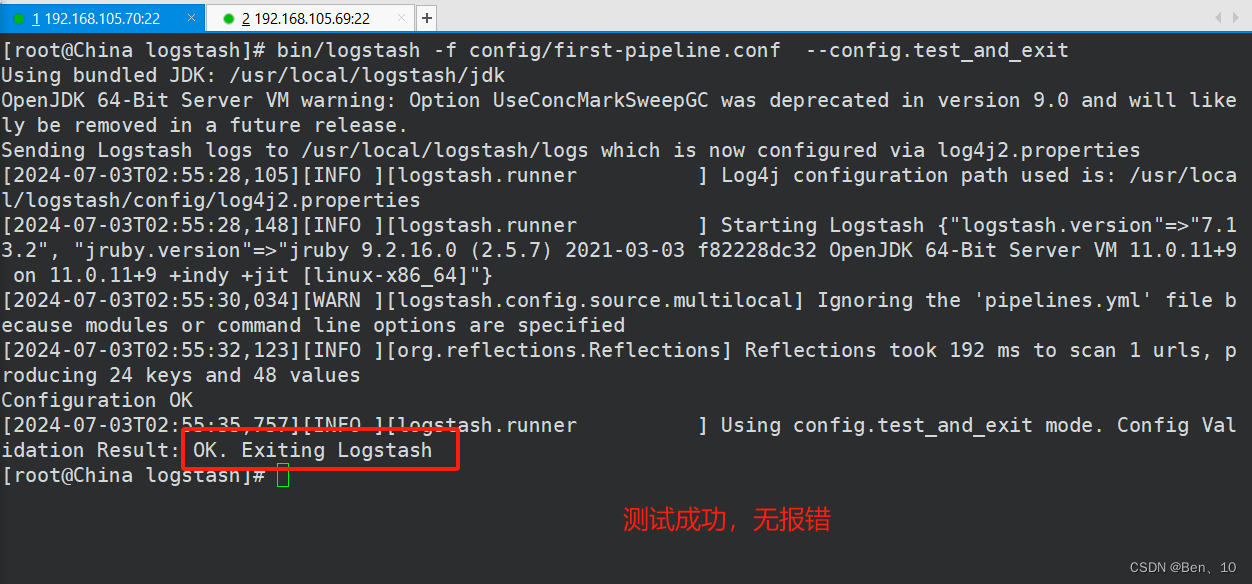
失败: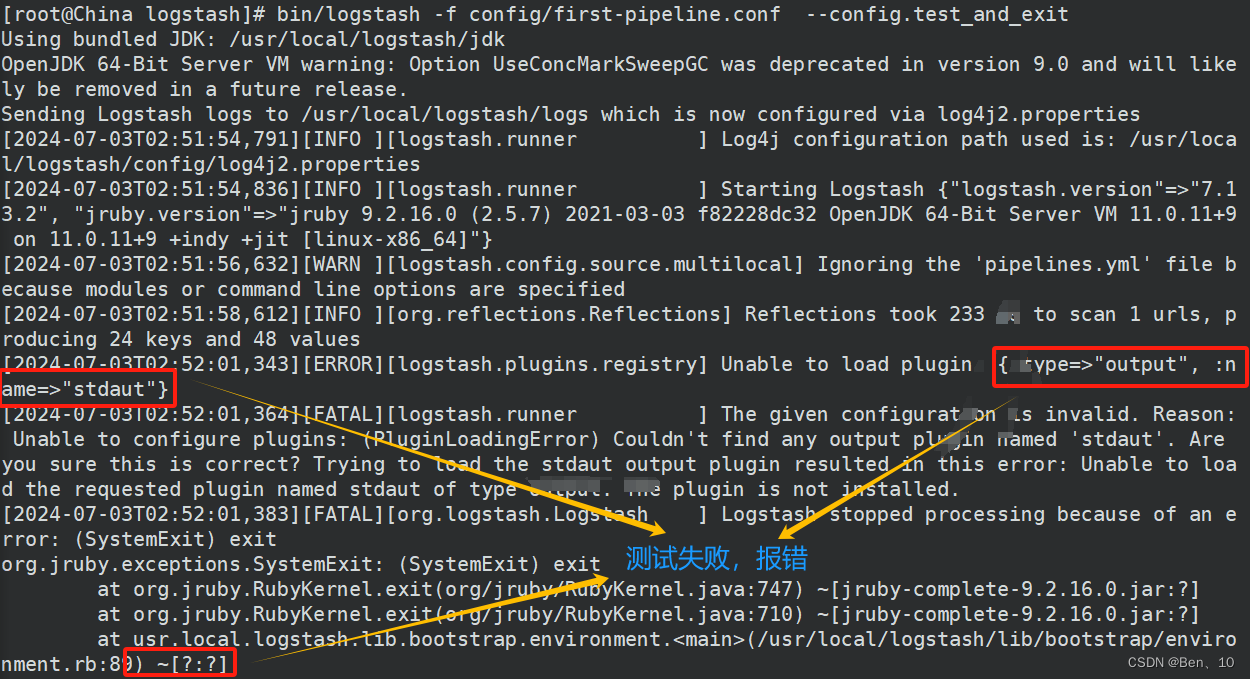
确认配置无误后运行
bin/logstash -f config/first-pipeline.conf
#启动logstash (并指向它的配置文件first-pipeline.conf )三、logstash 配置文件解析
---------------------------------------------- Pipeline配置文件示意图 --------------------------------------------------
1、输入部分:
input {
file {
path => ["/var/log/httpd.log"]
start_position => "beginning"
}
}1.1 input:这个部分定义了 Logstash 应该从哪里接收数据。这里可以使用各种输入插件,如 file、beats、tcp、udp、http 等,来从文件、网络端口、HTTP请求等多种来源读取数据。在这个例子中,Logstash 将从一个或多个文件中读取数据。
-
file:这是一个输入插件,用于从文件系统中读取数据。它特别适用于处理日志文件。
-
path:这个设置指定了要读取的文件的路径。在这个例子中,Logstash 将从
/var/log/httpd.log这个文件中读取数据。注意,这个路径可以是一个数组,意味着你可以指定多个文件路径。 -
start_position :这个设置决定了 Logstash 从文件的哪个位置开始读取数据。
"beginning"表示 Logstash 将从文件的开头开始读取,这对于从头开始分析日志文件或处理新生成的日志文件很有用。另一个选项是"end",它表示 Logstash 将从文件的末尾开始读取,并只处理新写入的数据(这通常用于实时日志处理)
2、过滤部分:
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{IP:client_ip} ..." }
}
}1.2 filter:这个部分用于对输入的数据进行解析、修改或增强。这是 Grok、Mutate 插件等处理插件的主要使用场所。通过定义一系列的过滤器,Logstash可以将数据从原始格式转换为结构化格式,并添加、删除或修改字段。在该例子中,Logstash 将使用 grok 插件来解析从文件中读取的日志数据。
-
grok:这是一个用于解析和解构文本数据的强大插件,它通过定义的模式来匹配和提取日志消息中的字段。
-
match:这个设置指定了 grok 插件应该在哪里查找匹配项,并定义了用于匹配的模式。在这个例子中,
%{TIMESTAMP_ISO8601:timestamp}用于匹配ISO 8601格式的时间戳,并将其提取到名为timestamp的字段中;%{IP:client_ip}用于匹配IP地址,并将其提取到名为client_ip的字段中。...表示可能还有其他字段需要匹配,具体取决于日志数据的格式。
3、输出部分:
-----------------------------示例1:标准输出到终端屏幕------------------------------
output {
stdout {
codec => rubydebug # 使用 rubydebug codec 来以易于阅读的格式输出日志
}
}
----------------------------------示例2:输出到es-------------------------------------
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
1.3 output:这个部分定义了 Logstash 处理完数据后应该将数据发送到哪里。在这个例子中,Logstash 将把处理后的数据发送到标准输出(stdout)。
-
stdout:这是一个输出插件,将数据发送到标准输出(屏幕),用于调试和测试 Logstash 配置。
-
codec:这个设置指定了用于编码输出的编解码器。在这个例子中,
rubydebug编解码器被用于以易于阅读的格式输出日志。这将包括日志的时间戳、日志级别(尽管在这个配置中可能不会显示,因为我们是直接处理原始日志数据)、日志消息以及 grok 插件提取的任何其他字段。
-
elasticsearch :使用elasticsearch插件将数据存储到Elasticsearch中
-
hosts :指定了Elasticsearch集群的节点地址和端口。在这个例子中,Logstash将尝试将数据发送到运行在本机(
localhost)上,监听在9200端口的Elasticsearch实例。9200是Elasticsearch的默认HTTP REST API端口。 -
index:定义了Elasticsearch中用于存储Logstash数据的索引名称。这里使用了Logstash的日期时间字段替换功能(
%{+YYYY.MM.dd}),这意味着索引名称将基于日志事件的时间戳自动生成,格式为logstash-年份.月份.日期。
四、logstash 插件
1.grok 插件 (过滤/排布日志)
Grok的功能概述:
- 模式匹配与提取:Grok是Logstash中的一种模式匹配工具,它基于正则表达式来解析和提取日志文件中的结构化数据。Grok允许用户定义模式,这些模式可以匹配日志中的特定字段,如时间戳、IP地址、用户名等,并将这些字段提取出来,以便后续的处理和分析。
- 数据标准化:通过将非结构化的日志数据转换为结构化的数据,Grok使得日志数据更加易于查询、分析和可视化。
应用场景:
- 日志文件的解析和字段提取。
- 实时监控和日志分析中的数据预处理。
filter {
grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
}
%{COMBINEDAPACHELOG}是一个Grok预定义的模式,它对应于Combined Log Format的日志条目。这个模式包含了多个子模式,用于匹配日志中的各个部分,如时间戳、请求方法、请求URL、HTTP状态码、传输的字节数、用户代理等。这行代码使用了Grok插件来解析Apache的Combined Log Format(组合日志格式)的日志条目。Combined Log Format是Apache HTTP服务器的一种日志格式,它包含了比Common Log Format更多的信息,如用户代理(User-Agent)和引用页(Referer)等
程序运行命令:
bin/logstash -f config/first-pipeline.conf 启动运行后 日志抓取效果:
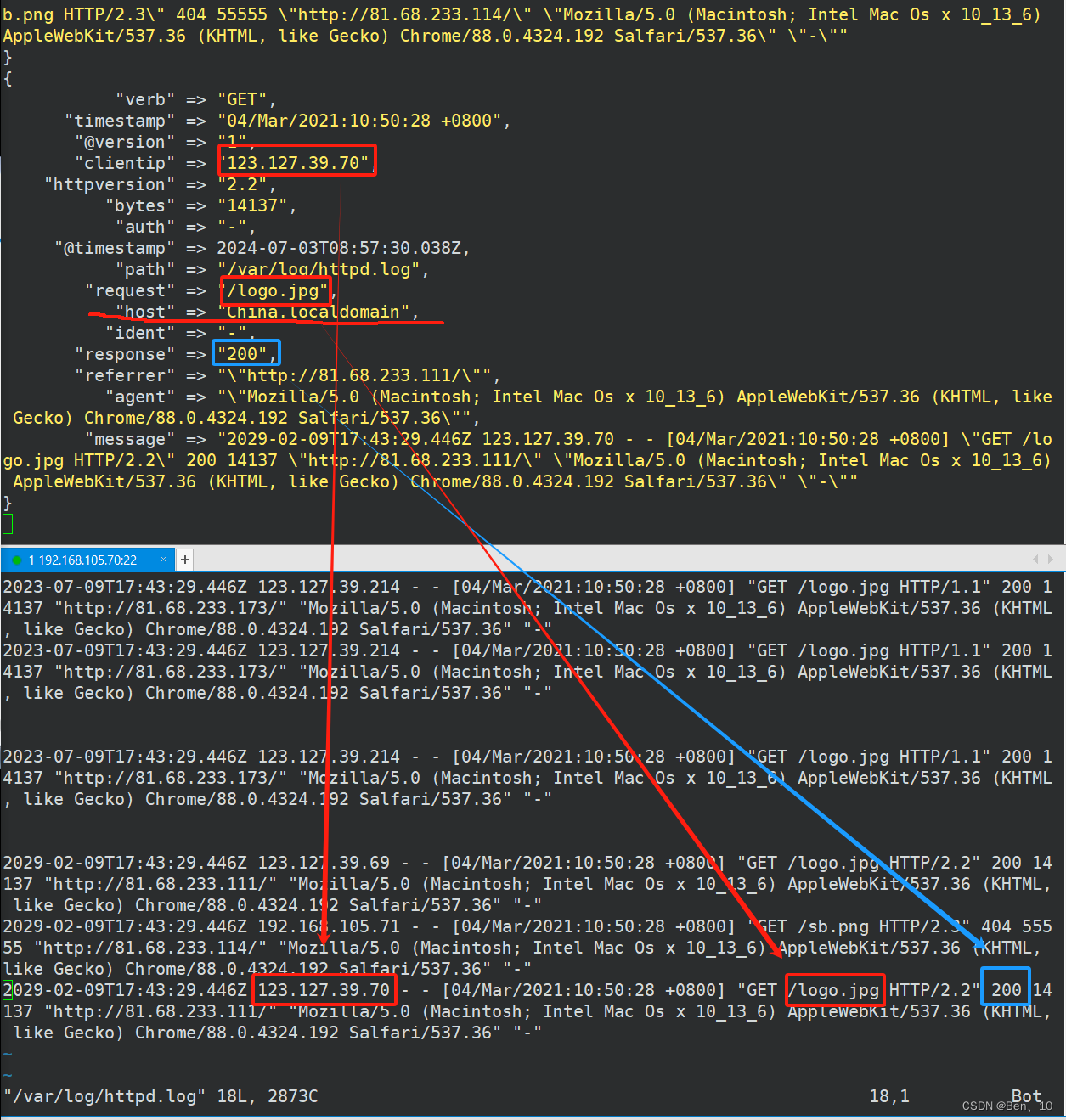
2. Mutate插件
Mutate功能概述:
- 字段修改与转换:Mutate插件是Logstash中的一个常用过滤器,用于对事件中的字段进行修改、重命名、删除和添加等操作。它提供了多种操作选项,如替换字段值、添加新字段、删除字段、重命名字段等。
add_field:添加一个字段。remove_field:删除一个或多个字段。rename:重命名一个字段。replace:替换一个字段的值。gsub:在字段值中进行正则替换操作。convert:将一个字段的值转换成指定的数据类型。uppercase/lowercase:将字段值转换为大写或小写。
- 数据清洗与标准化:通过Mutate插件,可以对日志数据进行清洗和标准化处理,去除不需要的字段,修改字段名称或类型,以满足后续的存储、分析和可视化需求。
应用场景:
- 日志字段的清洗和转换。
- 在事件处理流程中动态修改日志字段。
例:删/改名 选项
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
mutate {rename => {"ident"=>"ID"}} 改选项名"ident" 为 "ID"
mutate {rename =>{"host"=>"Hostname"}} 改选项名"host" 为 "Hostname"
mutate {remove_field => ["message","agent"] } 移除(显示)选项"message"和"agent"
}
3.Geoip过滤器插件 (增强数据编辑/IP溯源)
Geoip功能概述:
GeoIP过滤器插件是一种在Logstash中用于解析IP地址地理位置信息的插件。插件能根据IP地址,从GeoLite2数据库【GeoIP过滤器插件默认与GeoLite2-City数据库捆绑在一起】中查询并添加地理位置信息(如国家名、城市名、经纬度等)到Logstash处理的事件中。这使得在日志分析过程中能够更直观地了解日志来源的地理位置。
filter {
grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
mutate {rename => {"ident"=>"id"}}
mutate {rename =>{"host"=>"hostname"}}
mutate {remove_field => ["agent","message"] }
geoip {source =>"clientip"} # 指定要解析的IP字段
}

4. Beats (配置接收/输入)
Beats功能概述:
Beats插件是一种用于收集和传输日志数据的插件,可以与其他Elastic产品(如Elasticsearch、Kibana)无缝集成,提供全面的日志管理和分析解决方案。能够实时收集和传输日志数据,确保数据的及时性和准确性。支持多种数据源,包括文件、系统日志、网络流量等,可以灵活适配不同的应用场景。Beats插件还支持数据加密和身份验证,确保数据传输的安全性。
案例:用 Fileba t收集日志,传递给 Logstash 展示在终端屏幕上
4.1配置 Lostash 的输入-----------------------------------/usr/local/logstash/config/first-pipeline.conf
input {
# file {
# path => ["/var/log/httpd.log"]
# start_position => "beginning"
# }
beats {
port =>5044 # 输入端口:5044
}
}
4.2配置 Filebeat 的输入和输出------------------------------/usr/local/filebeat/filebeat.yml
--------------------------------Logstash 输入 --------------------------------
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/*.log
#- c:\programdata\elasticsearch\logs\*
-------------------------------- Logstash 输出 -------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
#hosts: ["192.168.105.70:5044"]
# 向那台机器的lostash输出(目标机器IP和端口号)
# filebeat只允许一种输出
---------------------------------- 标准输出 -----------------------------------
#output.console:
# codec.format:
# string: '%{[@timestamp]} %{[message]}'
# pretty: true
4.3确保filebeat收集的目标log文件里有日志生成

4.4运行程序
运行filebeat
/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
运行logstash
/usr/local/logstash/bin/logstash -f /usr/local/logstash/config/first-pipeline.conf
4.5实验成功一览
















 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









