






安装SSH服务端
进入Ubuntu虚拟机,在桌面打开终端机并输入如下命令。
sudo apt-get install openssh-server之后根据提示进行SSH安装。安装完成后,输入如下指令以查验安装是否成功。
ssh localhost若出现如下界面,则表明安装成功。(首次启动时需要根据提示进行操作,请全部同意即可)

随后在终端机内返回用户根目录。指令:“cd ~”。并按顺序输入如下命令:
注意:输入指令时务必严格控制空格数量为一个。在输入完第二个指令后,请根据提示不断按回车即可。
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys完成上述操作后,重新输入“ssh localhost”指令,若不需要输入密码则表明配置成功。
JAVA环境安装及配置
2.1安装JAVA
首先,将JAVA安装文件拷入Download文件夹。

之后,启动终端机,之后输入如下命令并进入 /usr/lib目录。同时创建JVM文件夹。
cd /usr/lib
sudo mkdir jvm随后,重新将终端机返回Download目录,并将java文件解压至刚刚创建的文件夹。指令如下
cd ~/Downloads
sudo tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/lib/jvm2.2 配置环境变量
完成第一步后,返回主界面,并输入如下指令,以对环境变量文件开始修改。
cd ~
vim ~/.bashrc在该文件开头处添加如下四行
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH随后保存文件,并输入如下内容
cd ~
source ~/.bashrc之后在终端机中任意目录位置输入“java -version”,若出现如下界面则表明java安装成功。

3.安装hadoop
同样,将hadoop安装文件拷到Downloads文件夹。
之后打开终端机,并输入如下指令。
cd ~/Downloads
sudo tar -zxvf hadoop-3.2.3.tar.gz -C /usr/local/
cd /usr/local
sudo mv hadoop-3.2.3 hadoop
sudo chown -R hadoop ./hadoop上述指令分别为:进入Downloads目录、解压hadoop安装文件至/usr/local目录、进入/usr/local目录、给hadoop文件夹重命名为hadoop、给予hadoop管理员权限。
由于hadoop解压即用的性质,当安装完成后,进入hadoop安装目录,并输入如下指令即可查验hadoop安装是否成功。
cd /usr/lib/hadoop
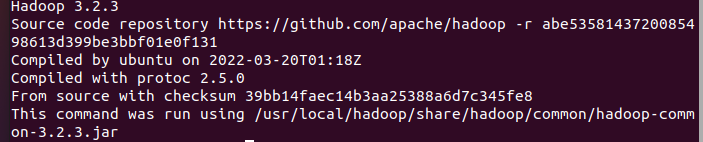
./bin/hadoop version第二条指令为进入hadoop安装目录,第二条为查看hadoop的版本。
若出现如下界面则表示安装成功。
4. 配置hadoop伪分布式模式
为保障后续作业的正常进行,需要修改hadoop的分布式模式为本地伪分布式。
输入如下指令
cd /usr/local/hadoop/etc/hadoop
vim core-site.xml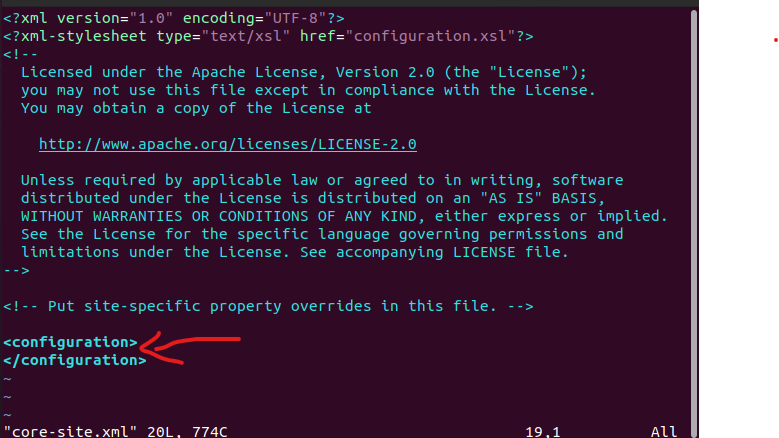
在上图所示的位置,即<configuration></configuration>之间,插入如下代码(注意,configuration部分已经存在,请不要复制进入)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>保存文件后,按上述方式,使用“vim hdfs-site.xml”指令,在同样的位置,为该文件添加如下代码
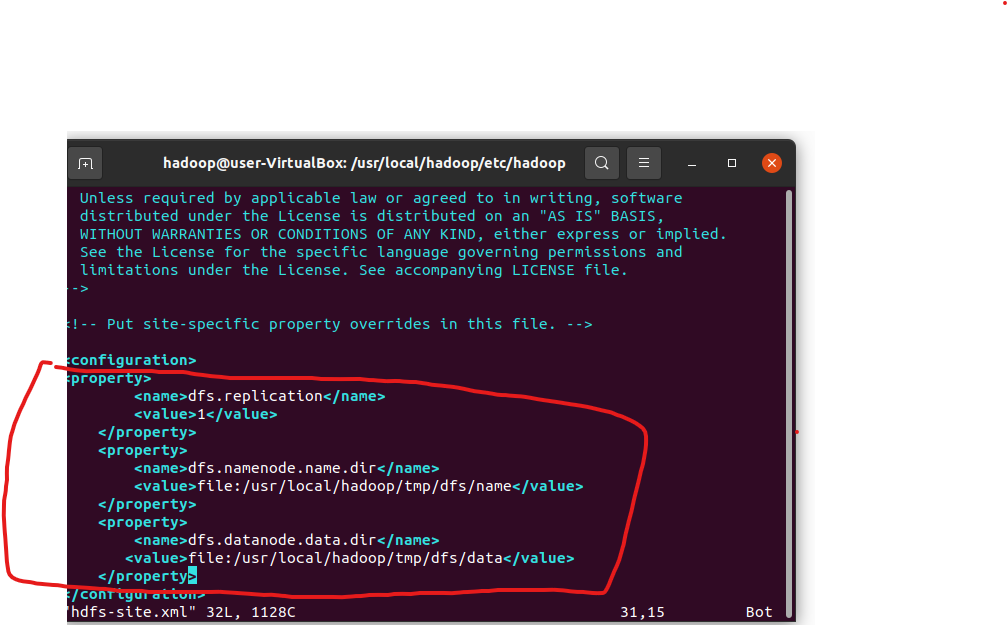
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>随后,返回hadoop文件目录,并输入如下指令,知名namenode初始化
cd /usr/local/hadoop
./bin/hdfs namenode -format待其初始化完成后,请进入hadoop安装目录,并输入如下指令以启动hadoop
cd /usr/local/hadoop
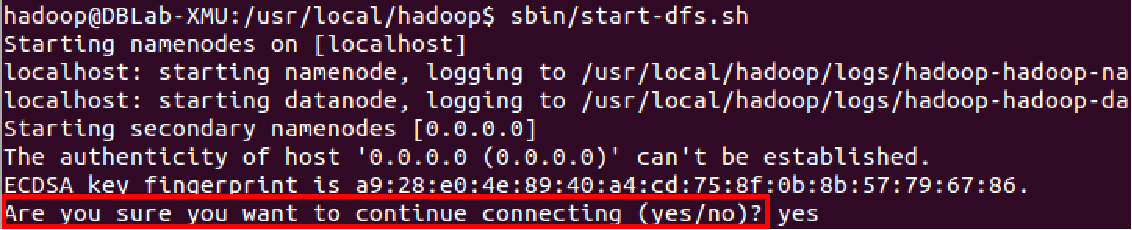
./bin/start-dfs.sh若出现ssh相关提示,请直接输入yes,如下图所示。
之后,在终端机中输入jps以查看服务情况,若出现一下四个则表明启动成功

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









