







Get-started demo: https://spring.io/guides/gs/batch-processing/
Get-started with Spring Batch
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<!-- This example uses a memory-based database -->
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>resources文件夹:
(1) schema-all.sql
DROP TABLE people IF EXISTS;
CREATE TABLE people (
person_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);
(2) sample-data.csv
Jill,Doe
Joe,Doe
Justin,Doe
Jane,Doe
John,DoeEntity:
package com.example.batchprocessing;
public class Person {
private String lastName;
private String firstName;
public Person() {
}
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "firstName: " + firstName + ", lastName: " + lastName;
}
}
A common paradigm in batch processing is to ingest data, transform it, and then pipe it out somewhere else. Here, you need to write a simple transformer that converts the names to uppercase.
Processor (a simple transformer):
package com.example.batchprocessing;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.ItemProcessor;
// ItemProcessor in Spring Batch
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
private static final Logger log = LoggerFactory.getLogger(PersonItemProcessor.class);
@Override
public Person process(final Person person) throws Exception {
final String firstName = person.getFirstName().toUpperCase();
final String lastName = person.getLastName().toUpperCase();
final Person transformedPerson = new Person(firstName, lastName);
log.info("Converting (" + person + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}
Now you need to put together the actual batch job. Spring Batch provides many utility classes that reduce the need to write custom code. Instead, you can focus on the business logic.
Java Configuration:
@EableBatchProcessing & define a reader, a processor, and a writer
package com.example.batchprocessing;
import javax.sql.DataSource;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.core.JdbcTemplate;
// tag::setup[]
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
// end::setup[]
// tag::readerwriterprocessor[]
@Bean
public FlatFileItemReader<Person> reader() {
// ItemReader
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
// csv file
.resource(new ClassPathResource("sample-data.csv"))
.delimited()
.names(new String[]{"firstName", "lastName"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
// parses each line item for csv file to turn it into a Person.
setTargetType(Person.class);
}})
.build();
}
@Bean
public PersonItemProcessor processor() {
return new PersonItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
// ItemWriter
return new JdbcBatchItemWriterBuilder<Person>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)")
// JDBC destination
.dataSource(dataSource)
.build();
}
// end::readerwriterprocessor[]
// tag::jobstep[]
@Bean
public Job importUserJob(JobCompletionNotificationListener listener, Step step1) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
// Jobs are built from steps, where each step can involve a reader, a processor, and a writer.
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JdbcBatchItemWriter<Person> writer) {
return stepBuilderFactory.get("step1")
// a generic method. This represents the input and output types of each “chunk” of processing and lines up with ItemReader<Person> and ItemWriter<Person>.
// In the step definition, you define how much data to write at a time.
// In this case, it writes up to ten records at a time.
.<Person, Person> chunk(10)
// Next, you configure the reader, processor, and writer.
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
// end::jobstep[]
}
Listener:
In this job definition, you need an incrementer, because jobs use a database to maintain execution state. The JobCompletionNotificationListener listens for when a job is BatchStatus.COMPLETED and then uses JdbcTemplate to inspect the results.
package com.example.batchprocessing;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if(jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate.query("SELECT first_name, last_name FROM people",
(rs, row) -> new Person(
rs.getString(1),
rs.getString(2))
).forEach(person -> log.info("Found <" + person + "> in the database."));
}
}
}
main方法
package com.example.batchprocessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BatchProcessingApplication {
public static void main(String[] args) throws Exception {
System.exit(SpringApplication.exit(SpringApplication.run(BatchProcessingApplication.class, args)));
}
}
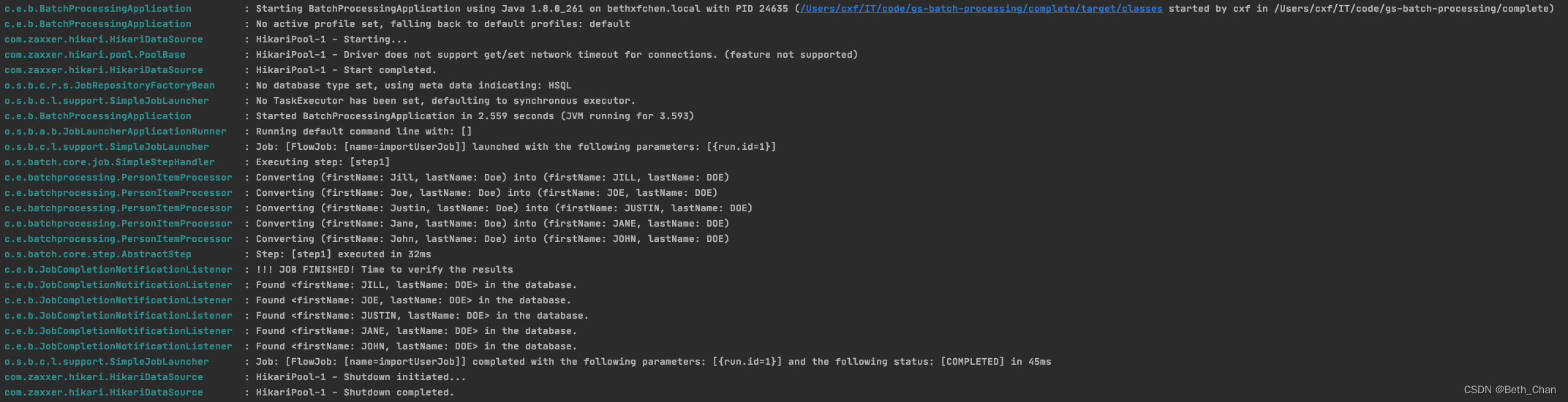
运行结果:

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









