







声明:经验之谈,如果不对,请用尿滋醒我!
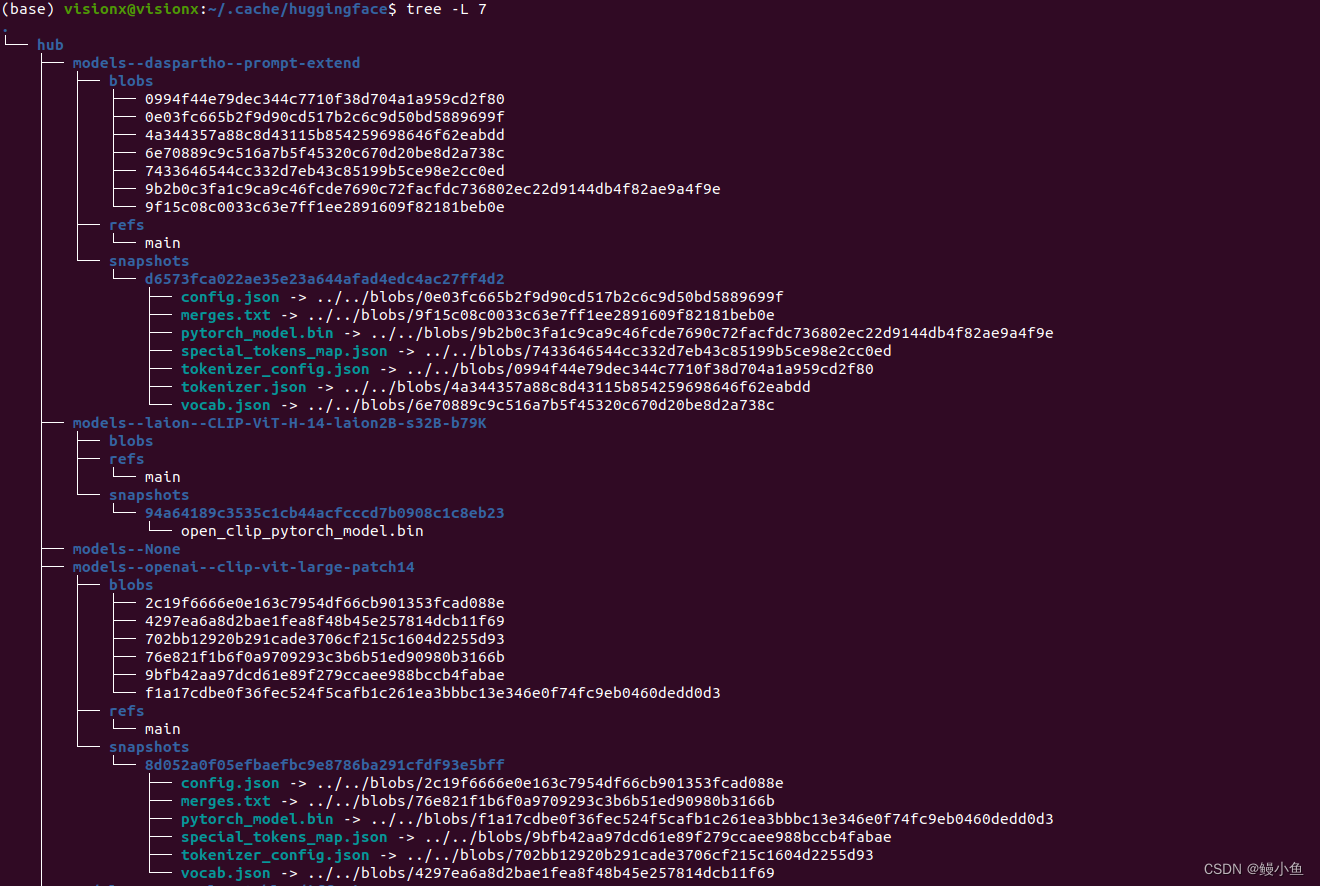
直接上图

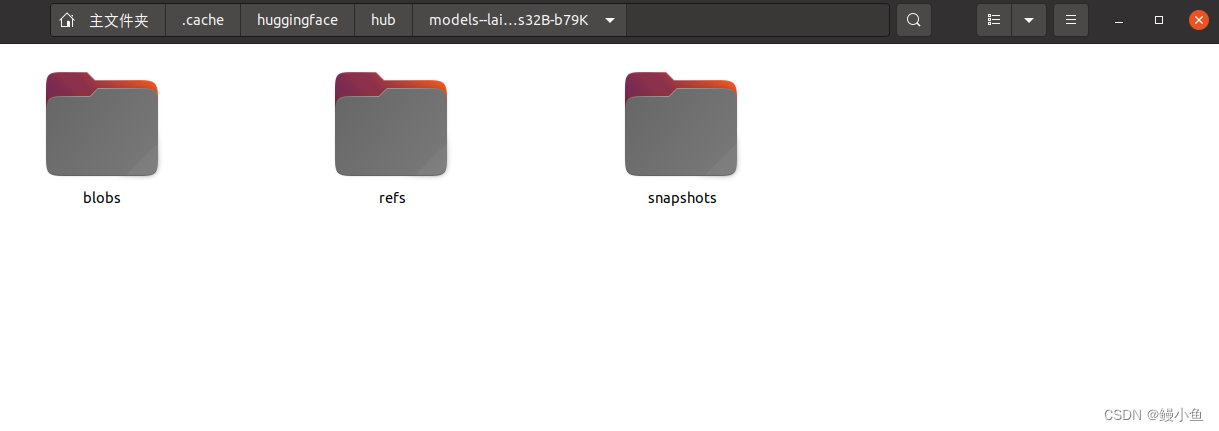
再来一下目录的展示

分析和解读
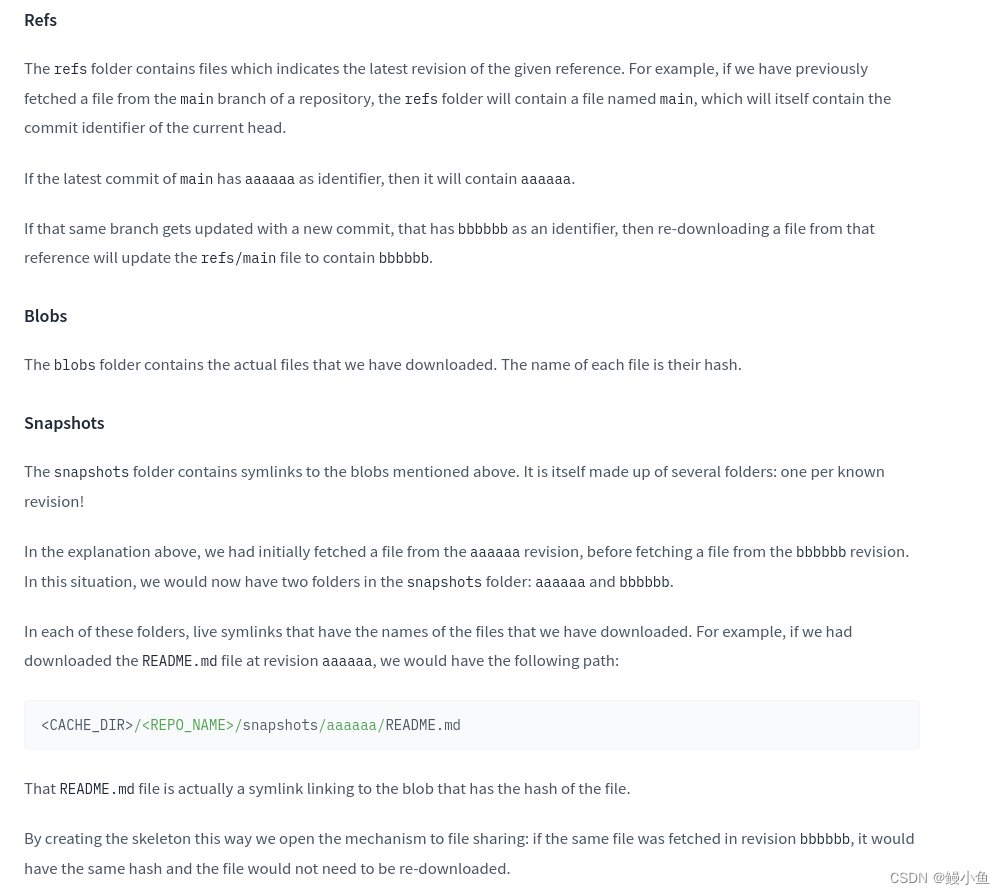
在这里可以看出模型目录下包括三部分blobs、refs和snapshots,其中前两者一般会包含和模型相关的信息,
--blobs:校验码文件名及其参数配置
--refs:main就是存储的就是模型的校验码
snapshots:模型文件以及相关的配置信息
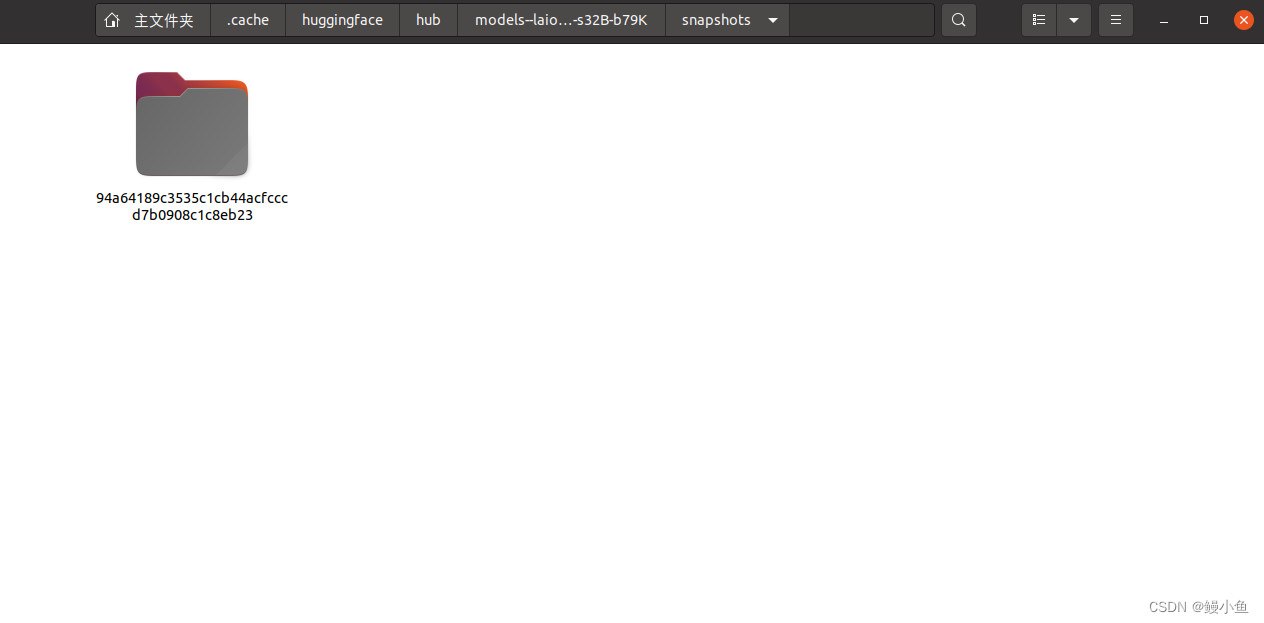
比如在这里的refs/main就是存储的就是模型的校验码94a64189c3535c1cb44acfcccd7b0908c1c8eb23,有的时候也会看到blob——id=94a64189c3535c1cb44acfcccd7b0908c1c8eb23,比如下图
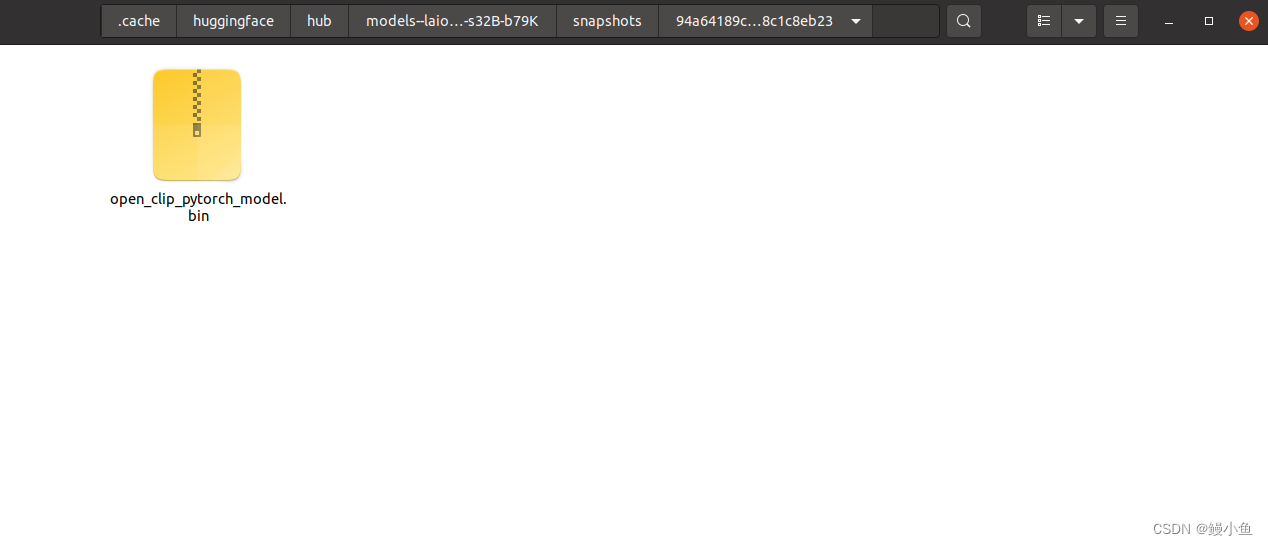
而snapshots/94a64189c3535c1cb44acfcccd7b0908c1c8eb23目录下存储的便是模型文件以及相关的配置信息,当然这个例子只有模型权重文件
这是一种正常的情况,也是默认的情况,可以看下其他模型加载时候的树状目录 ,会发现其他例子的snapshots就有会模型文件以及相关的配置信息
官方文档
机翻大图,高清直出

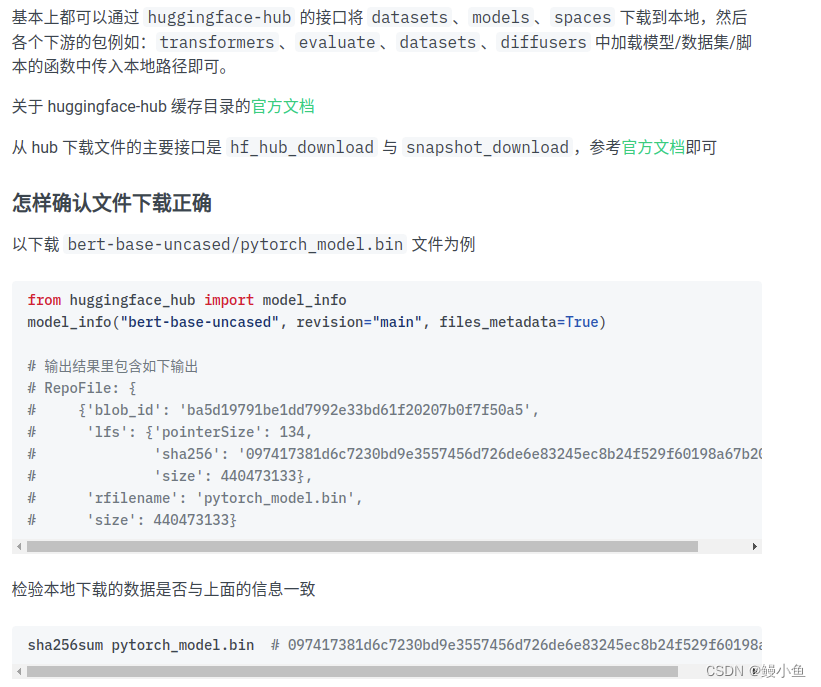
huggingface的使用及缓存机制
官方文档
 https://huggingface.co/docs/huggingface_hub/main/en/package_reference/environment_variables
https://huggingface.co/docs/huggingface_hub/main/en/package_reference/environment_variables缓存机制

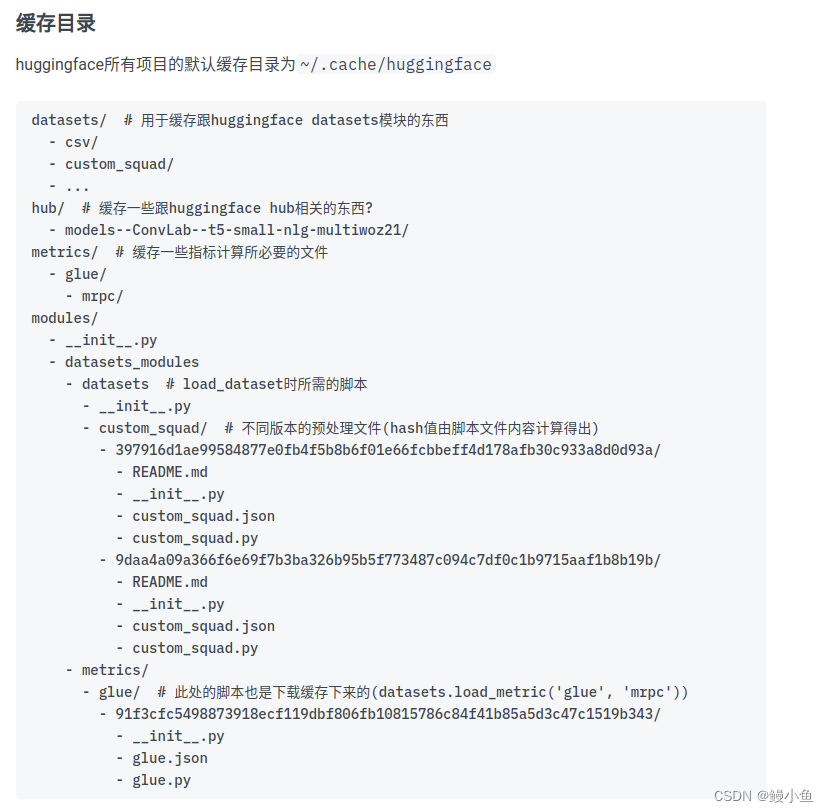





huggingface默认文件目录及修改
huggingface-hub包的默认缓存目录为HUGGINGFACE_HUB_CACHE=~/.cache/huggingface/hub,其本质是对git的一层封装。
transformers包的默认缓存目录为TRANSFORMERS_CACHE=~/.cache/huggingface/hub(与huggingface-hub一致,并且本质上是直接复用了huggingface-hub的缓存方式,即blobs、refs、snapshots的方式)
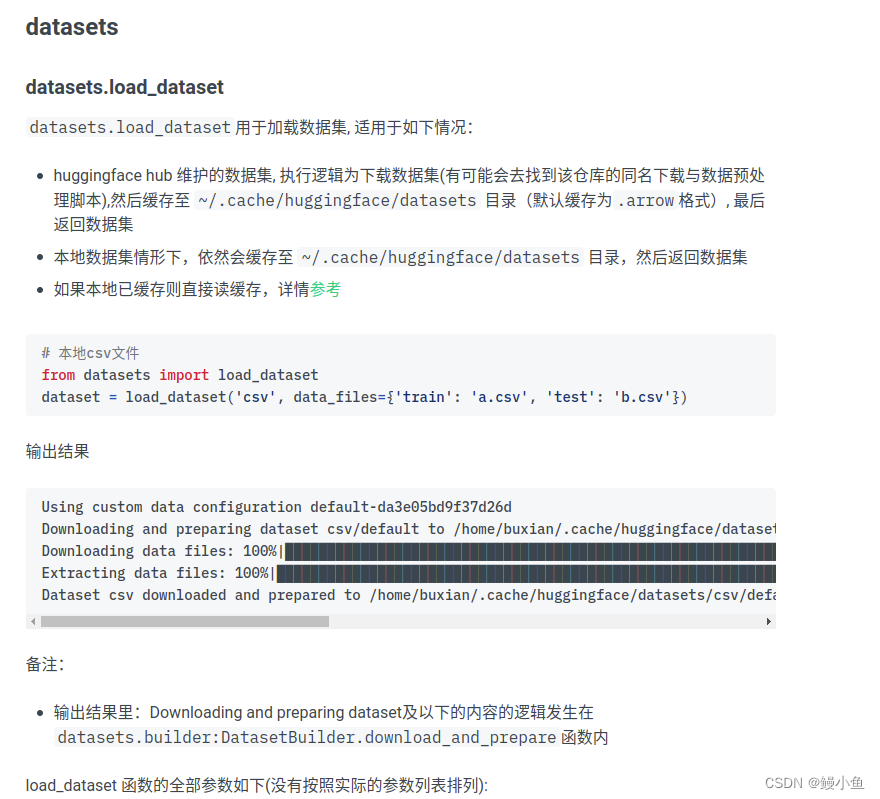
datasets包的默认缓存目录为:HF_DATASETS_CACHE=~/.cache/huggingface/datasets(与huggingface-hub不一致,其本质上是建立了自己的一套缓存数据集的方式,即采用arrow格式对数据进行缓存,从而加速数据的加载速度,提升训练效率),另外,使用datasets.load_dataset时会将需要的脚本缓存至~/.cache/huggingface/modules/datasets_modules目录
evaluate包设定了如下一些默认缓存路径:
HF_METRICS_CACHE=~/.cache/huggingface/metrics
HF_EVALUATE_CACHE=~/.cache/huggingface/evaluate
HF_MODULES_CACHE=~/.cache/huggingface/modules/evaluate_modules
diffusers包的默认缓存目录为:DIFFUSERS_CACHE=~/.cache/huggingface/diffusers,而需要的脚本缓存目录设定在~/.cache/huggingface/modules/diffusers_modules目录


export HF_DATASETS_CACHE="另一个缓存路径"from datasets import load_dataset
dataset = load_dataset('LOADING_SCRIPT', cache_dir="PATH/TO/MY/CACHE/DIR")再次声明,上述内容来自网络,请根据个人情况使用
完结撒花
人一旦身不由己,所有美丽的东西都势必烟消云散。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









