







-
论文:https://arxiv.org/abs/2311.17911
代码:https://github.com/shikiw/OPERA
在多模态大模型中,幻觉问题一直是一个备受关注的难题。大多数多模态大模型(Multi-Modal Large Language Models)经常对输入的图像和提示给出错误的回答,尤其在生成较长文本回答时,很容易说出与图像不符的事物,或者错误地判断图像上物体的颜色、数量和位置等。
这里以著名的多模态大模型LLaVA-1.5举个栗子:
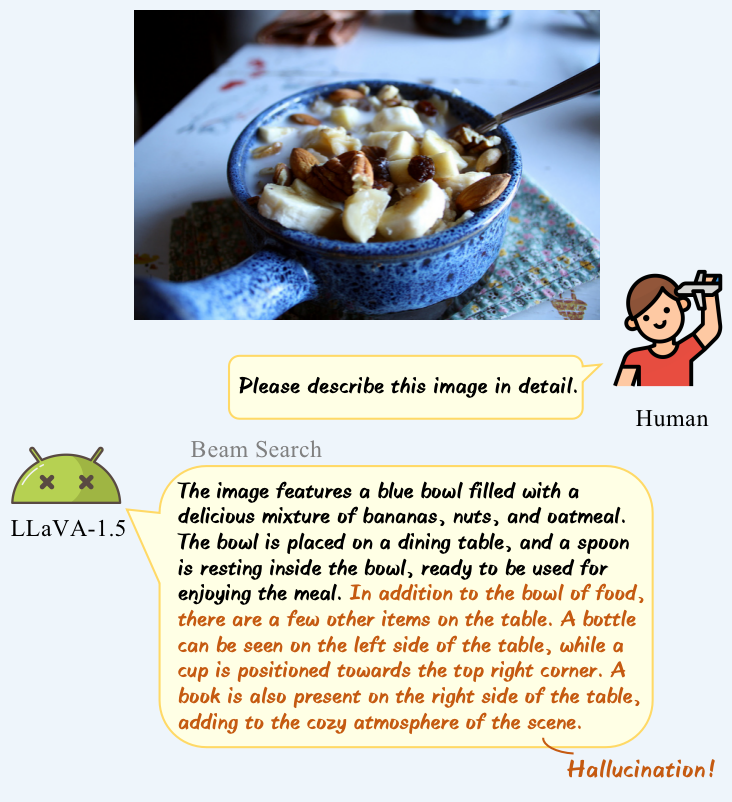
为了缓解多模态大模型的幻觉问题,最近有许多不同的方法陆续被提出。其中一些方法涉及构建额外的训练数据并加入到训练阶段,另一些方法则依赖于外部知识或强大的模型进行辅助,这些方法通常伴随着大量的额外开销。那么是否存在一种方法,可以在不需要额外知识和训练的情况下轻松缓解多模态大模型的幻觉问题呢?
为此,中科大和上海AI Lab的研究者们近日提出了一种名为OPERA的解码方法,该方法基于注意力惩罚与回退策略,成功地在不借助外部知识并不引入额外训练的情况下缓解了多模态大模型的幻觉问题。
研究者们发现了一个引人注目的现象,即在多模态大模型生成幻觉内容时,其自注意力权重往往表现出一种“过度信赖”的趋势。具体而言,当我们对多模态大模型的最后一层自注意力权重进行可视化时,在模型生成幻觉句子之前,很容易观察到一个明显的“柱状”特征。以多模态大模型InstructBLIP为例:
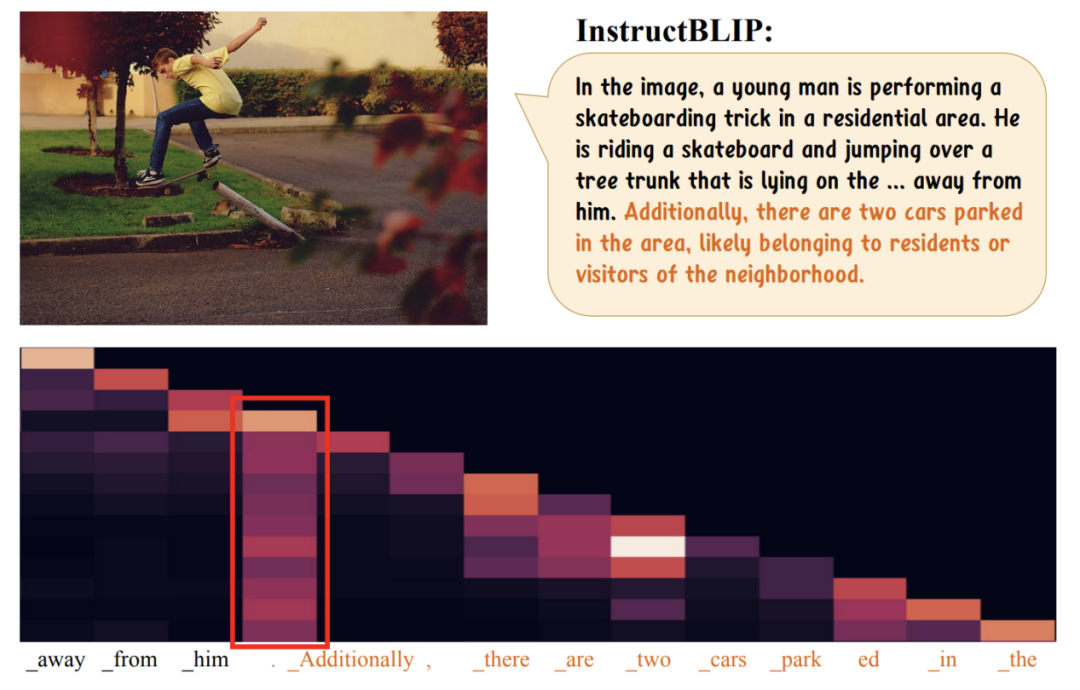
可以清晰地观察到,在幻觉句子出现之前,存在一个token,其对后续所有token都具有较高的注意力权值。通常情况下,这种现象并不合乎常理,因为从输出的回答来看,这个词并不一定包含丰富的信息。研究者们分析认为,这种现象可能是多模态大模型在生成较长语句时展现的一种“自动总结”本能。类似于人类的行为,当输出内容逐渐增加时,为了降低负担并提高效率,模型可能会进行阶段性的总结,后续的所有回答都可能基于这些总结进行生成。
然而,这种阶段性总结也可能导致之前某些具体信息的丢失,因为后续的token可能由于“过度信赖”这些总结而忽略了先前的信息,从而产生幻觉内容。研究者们将这一现象描述为“partial over-trust”,并发现大型模型的这种阶段性总结可能是导致幻觉问题的一大“元凶”!同时,研究者们进行了数值统计,在不同模型中都观察到了这一现象与幻觉之间的相关性。
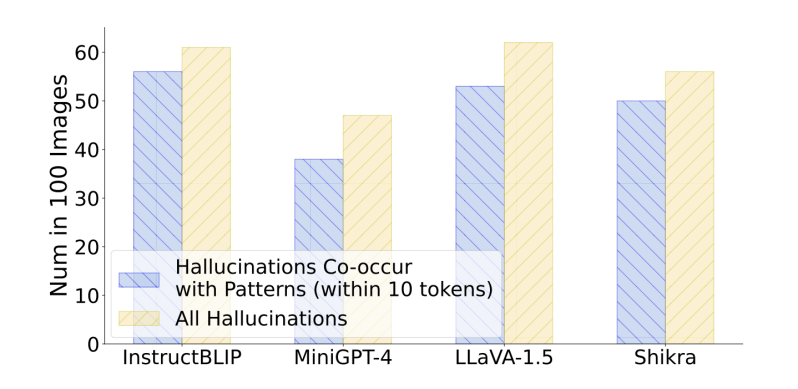
研究者们通过随机采样100张图像,并向不同的多模态大模型提出问题。他们发现在所有出现幻觉回答的情况下,有80%~90%的回答都呈现出了“过度信赖”现象,进一步证实了这一现象与幻觉之间的伴生关系。
方法
为了缓解“过度信赖”现象,研究者们试图通过改变解码策略来减轻幻觉问题的发生。在经典的Beam Search解码方法基础上,他们首先引入了一个额外的惩罚项,对解码过程中每个token的输出概率进行调整,以惩罚出现“过度信赖”的注意力特征。具体而言,他们在自注意力权重图上划分一个局部窗口,对这些权重进行数值放大,同时通过列乘法生成一个得分向量,最终选择其中的最大得分作为惩罚得分。这个惩罚得分的增加表示生成句子中“过度信赖”的特征越为明显,幻觉的可能性越大。最后,这个惩罚得分会影响每个序列的Beam得分,从而使得得分较低的序列最终被淘汰。
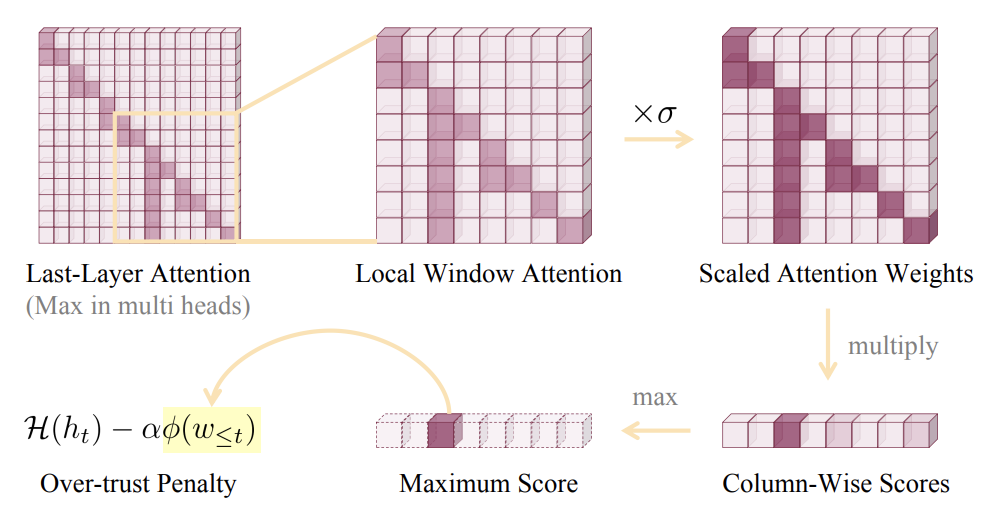
由于“过度信赖”特征存在“滞后性”,即只有在解码过程中输出了若干token后才能观察到这种特征。为了应对这种滞后带来的限制,研究者们提出了“回退-再分配”的策略。具体而言,他们计算了最近几个token的得分向量的最大值下标,并检查该下标连续出现的次数是否超过一定阈值。如果超过阈值,就会将当前序列的解码过程回退到该下标所在token的位置,并重新选择词表中概率次高的词(排除之前已选择的词)。
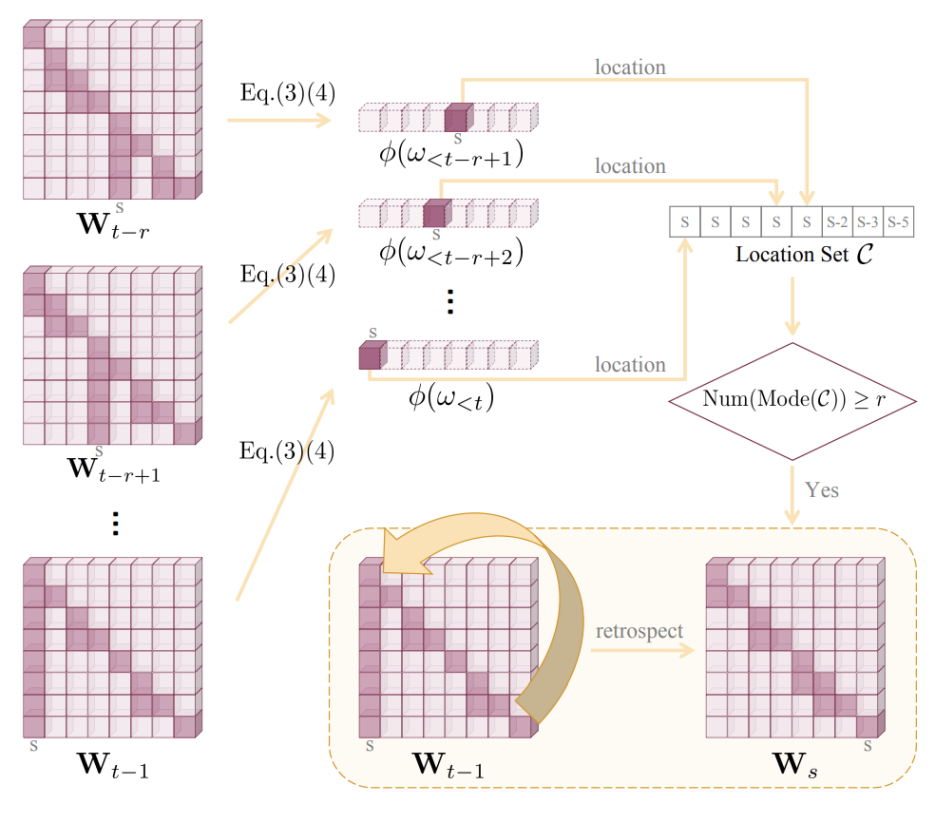
研究者们结合所提出的“过度信赖”惩罚与“回退-再分配”策略,提出了一个新的多模态大模型解码方法OPERA,极大地缓解了模型的的幻觉现象,尤其是在生成较长回答的时候的幻觉问题。
实验
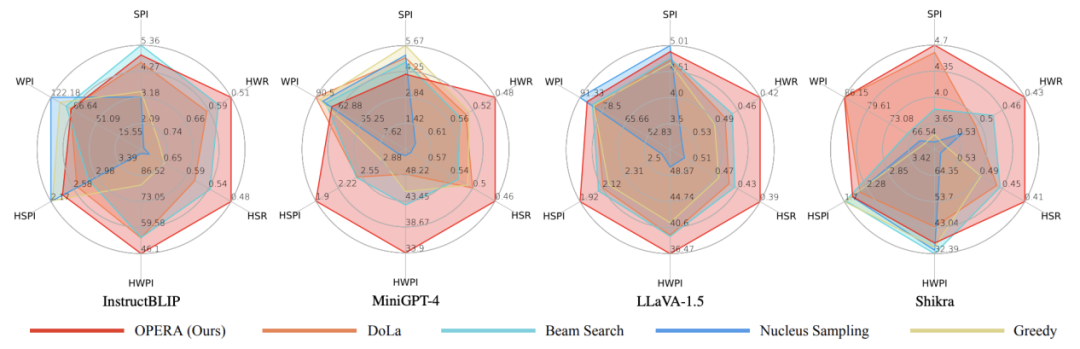
研究者们对InstructBLIP、MiniGPT-4、LLaVA-1.5以及Shikra等多种多模态大模型进行了测试,并在不同维度上进行了统计验证。相对于先前的解码方法,他们提出的OPERA解码方法在缓解幻觉方面展现出卓越的性能。
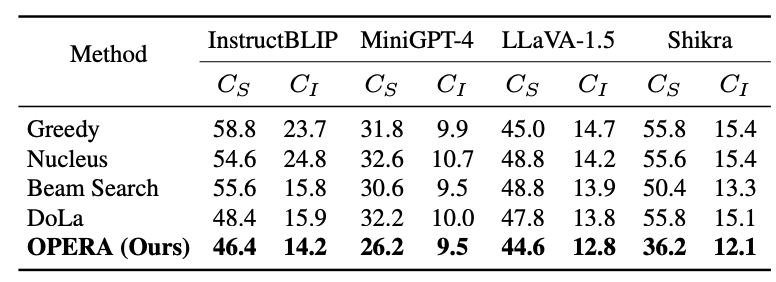
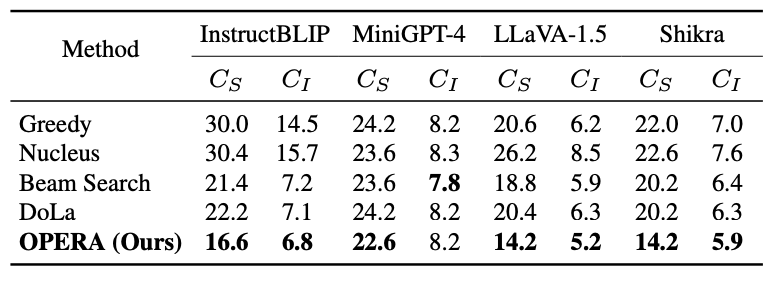
除此之外,研究者们还让GPT-4和GPT-4V给不同解码方法生成的文本进行打分,在生成内容的准确程度与具体程度上,OPERA同样也展现出优越的性能。
同时,研究者们还给出了OPERA的一些具体表现的实例:



总的来说,作为一种通过改进解码策略来减轻多模态大模型幻觉的方法,OPERA具有易于在不同模型和架构上部署的特点,同时也激发了更多研究者从机制层面研究和解决多模态大模型的幻觉问题。















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








