






一、什么是Spark
Spark 是一个快速、通用且可扩展的大数据处理框架,最初由加州大学伯克利分校的AMPLab于2009年开发,并于2010年开源。它在2013年成为Apache软件基金会的顶级项目,是大数据领域的重要工具之一。
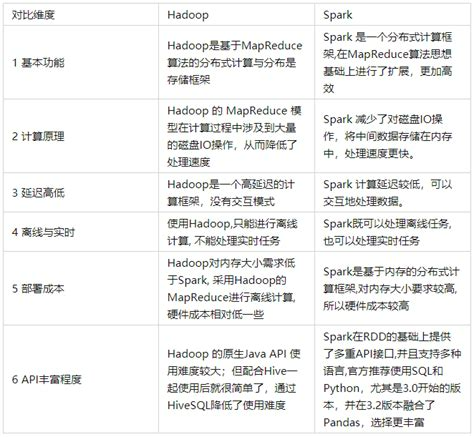
Spark 的优势在于其速度和灵活性。相比传统的Hadoop MapReduce模型,Spark通过内存计算减少了I/O开销,使得迭代式算法(如机器学习和图计算)的性能提升显著。此外,Spark支持批处理、流处理、交互式查询和实时分析等多种计算模式,使其能够满足多样化的数据处理需求
Spark 是一个功能强大且广泛应用的大数据处理框架,适用于需要高效处理大规模数据集的场景,如金融风控、用户画像、广告推荐等领域
二、Hadoop概述
Hadoop 简介
Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会维护,旨在处理海量数据(TB/PB级别)的存储和计算问题。它的核心设计思想是 分布式存储(HDFS) 和 分布式计算(MapReduce) ,能够在普通硬件集群上高效运行。
1. Hadoop 的核心组件
Hadoop 主要由以下几个关键组件构成:
(1) HDFS(Hadoop Distributed File System)
- 分布式文件存储系统,用于存储大规模数据。
- 特点:
- 高容错性:数据自动复制多份(默认3副本),防止硬件故障导致数据丢失。
- 高吞吐量:适合批量处理大数据,而非低延迟的实时查询。
- 可扩展性:支持 PB 级数据存储,可动态增加节点。
(2) MapReduce
- 分布式计算模型,用于并行处理大规模数据集。
- 工作原理:
- Map 阶段:将输入数据拆分成键值对(key-value pairs)。
- Shuffle & Sort 阶段:对中间结果进行排序和分组。
- Reduce 阶段:汇总计算结果并输出。
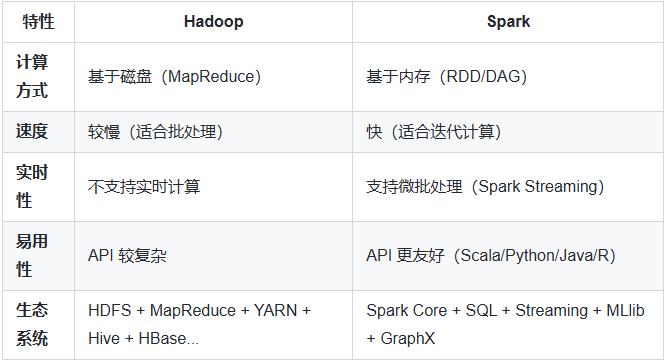
- 缺点:由于依赖磁盘 I/O,速度较慢(相比 Spark)。
(3) YARN(Yet Another Resource Negotiator)
- 资源管理和任务调度系统,负责集群资源分配和作业管理。
- 作用:
- 管理 CPU、内存等资源。
- 支持多种计算框架(如 MapReduce、Spark、Flink)。
2.Hadoop vs Spark
Hadoop 是早期大数据处理的基石,尤其擅长海量数据存储和批处理计算。但随着 Spark、Flink 等更快的计算框架出现,Hadoop MapReduce 的使用逐渐减少,但 HDFS、YARN、Hive、HBase 等组件仍然广泛使用。
如果你的业务需要:
✔️ 低成本存储海量数据 → HDFS
✔️ 批处理分析(如日志分析) → MapReduce/Hive
✔️ 构建数据仓库 → Hive
✔️ 实时数据库查询 → HBase
但如果是需要低延迟计算或机器学习,建议结合 Spark/Flink 使用。
三、为什么我们需要Spark
处理速度
Hadoop:Hadoop MapReduce 基于磁盘进行数据处理,数据在 Map 和 Reduce 阶段会频繁地写入磁盘和读取磁盘,这使得数据处理速度相对较慢,尤其是在处理迭代式算法和交互式查询时,性能会受到较大影响。
Spark:Spark 基于内存进行计算,能将数据缓存在内存中,避免了频繁的磁盘 I/O。这使得 Spark 在处理大规模数据的迭代计算、交互式查询等场景时,速度比 Hadoop 快很多倍。例如,在机器学习和图计算等需要多次迭代的算法中,Spark 可以显著减少计算时间。
编程模型
Hadoop:Hadoop 的 MapReduce 编程模型相对较为底层和复杂,开发人员需要编写大量的代码来实现数据处理逻辑,尤其是在处理复杂的数据转换和多阶段计算时,代码量会非常庞大,开发和维护成本较高。
Spark:Spark 提供了更加简洁、高层的编程模型,如 RDD(弹性分布式数据集)、DataFrame 和 Dataset 等。这些抽象使得开发人员可以用更简洁的代码来实现复杂的数据处理任务,同时 Spark 还支持多种编程语言,如 Scala、Java、Python 等,方便不同背景的开发人员使用。
实时性处理
Hadoop:Hadoop 主要用于批处理任务,难以满足实时性要求较高的数据处理场景,如实时监控、实时推荐等。
Spark:Spark Streaming 提供了强大的实时数据处理能力,它可以将实时数据流分割成小的批次进行处理,实现准实时的数据分析。此外,Spark 还支持 Structured Streaming,提供了更高级的、基于 SQL 的实时流处理模型,使得实时数据处理更加容易和高效。
HadoopMR框架,从数据源获取数据,经过分析计算之后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
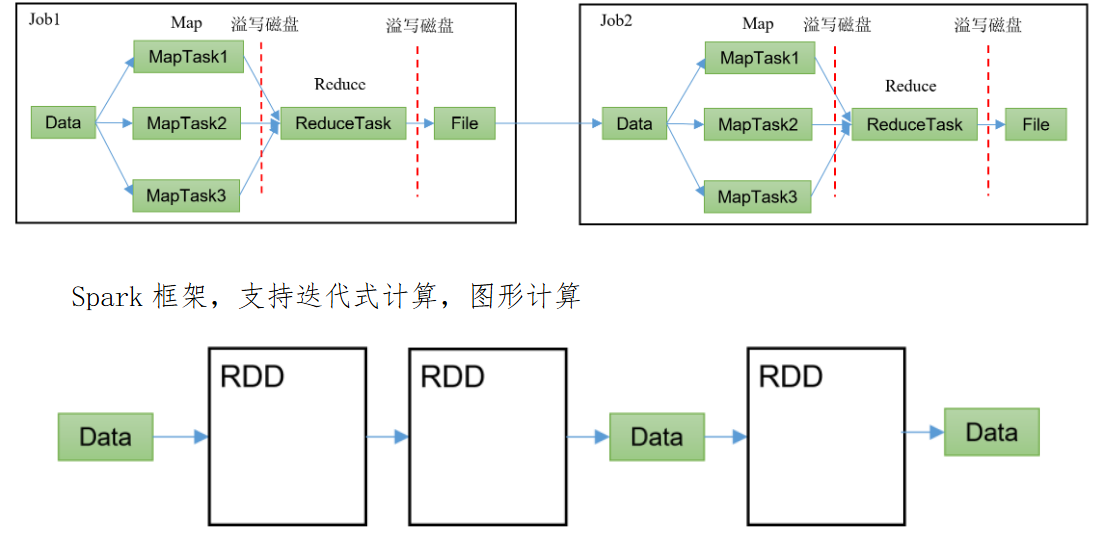
四、Spark的内置模块
它的内置模块非常丰富,提供不同的服务。
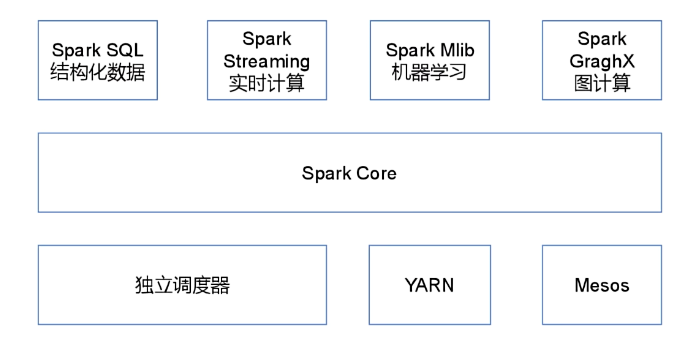
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或 者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









