







✨✨ 欢迎大家来到贝蒂大讲堂✨✨🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:数据结构与算法
贝蒂的主页:Betty’s blog

1. 并查集的引入
1.1 并查集的概念
并查集是一种树型数据结构,主要用于处理不相交集合的合并及查询问题,在实际应用中常常以森林形式呈现。 在众多应用问题里,常常需要将n个不同元素划分成若干不相交的集合。初始状态下,每个元素各自构成一个单元素集合。随后,依据特定规律对归于同一组元素的集合进行合并操作。在此过程中,频繁涉及查询某一元素所属集合的运算。能够很好地描述这类问题的抽象数据结构即并查集。
1.2 并查集的特点
并查集的底层结构一般以数组表示,其一般具有以下三个特点:
- 数组的下标对应集合中元素的编号。
- 数组中元素如果为负数,代表这个下标是一颗树的根节点,数字的绝对值代表该集合中元素个数。
- 数组中原始如果为非负数,代表该元素父节点在数组中的下标。
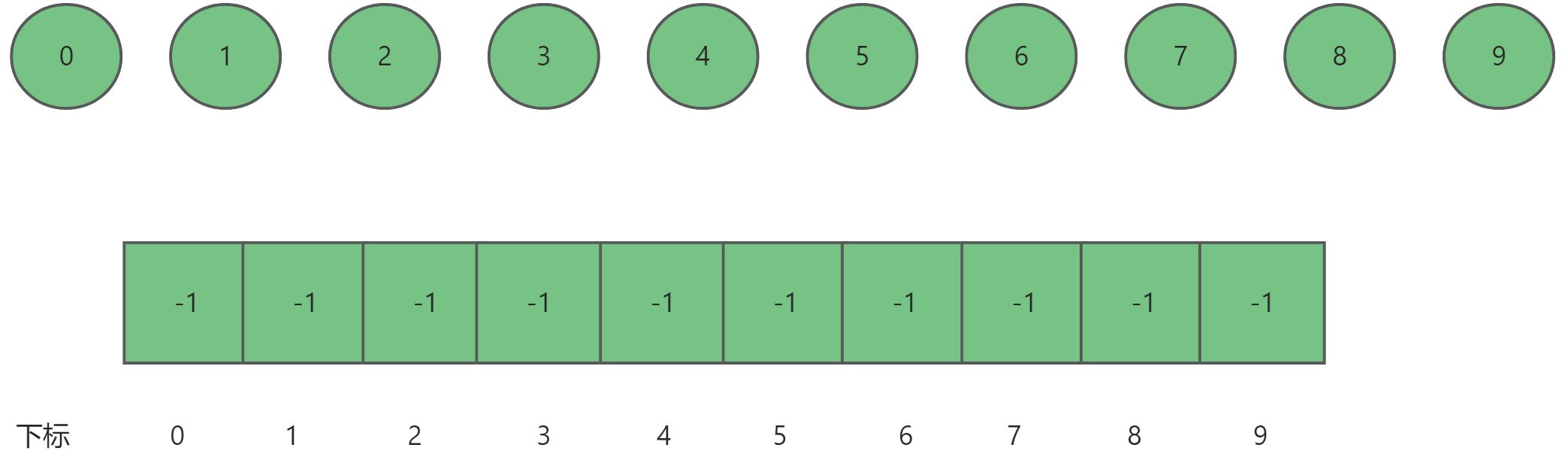
比如说现在有个一个集合,其中分别有十个元素分别为{0,1,2,3,4,5,6,7,8,9}。现在它们之间毫无任何关系,所以每一个元素都可以单独看成一颗树。如果用数组表示,每个元素对应一个下标,每一个下标对应的值都为-1。
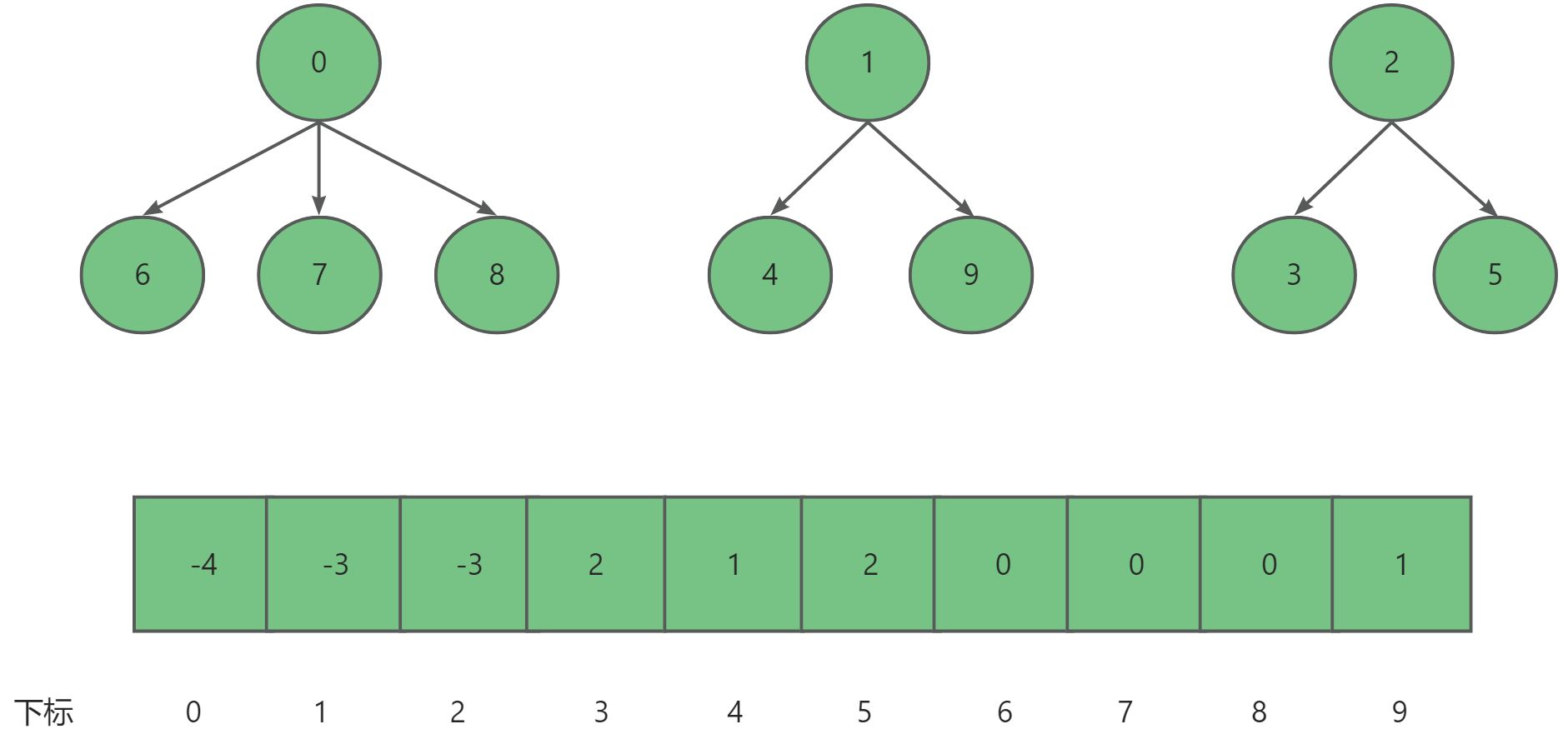
如果对该集合建立关系,比如说分为三个集合:{0,6,7,8},{1,4,9},{2,3,5}。这时我们就可以抽象为对应的三颗子树,对应数组也可更新。
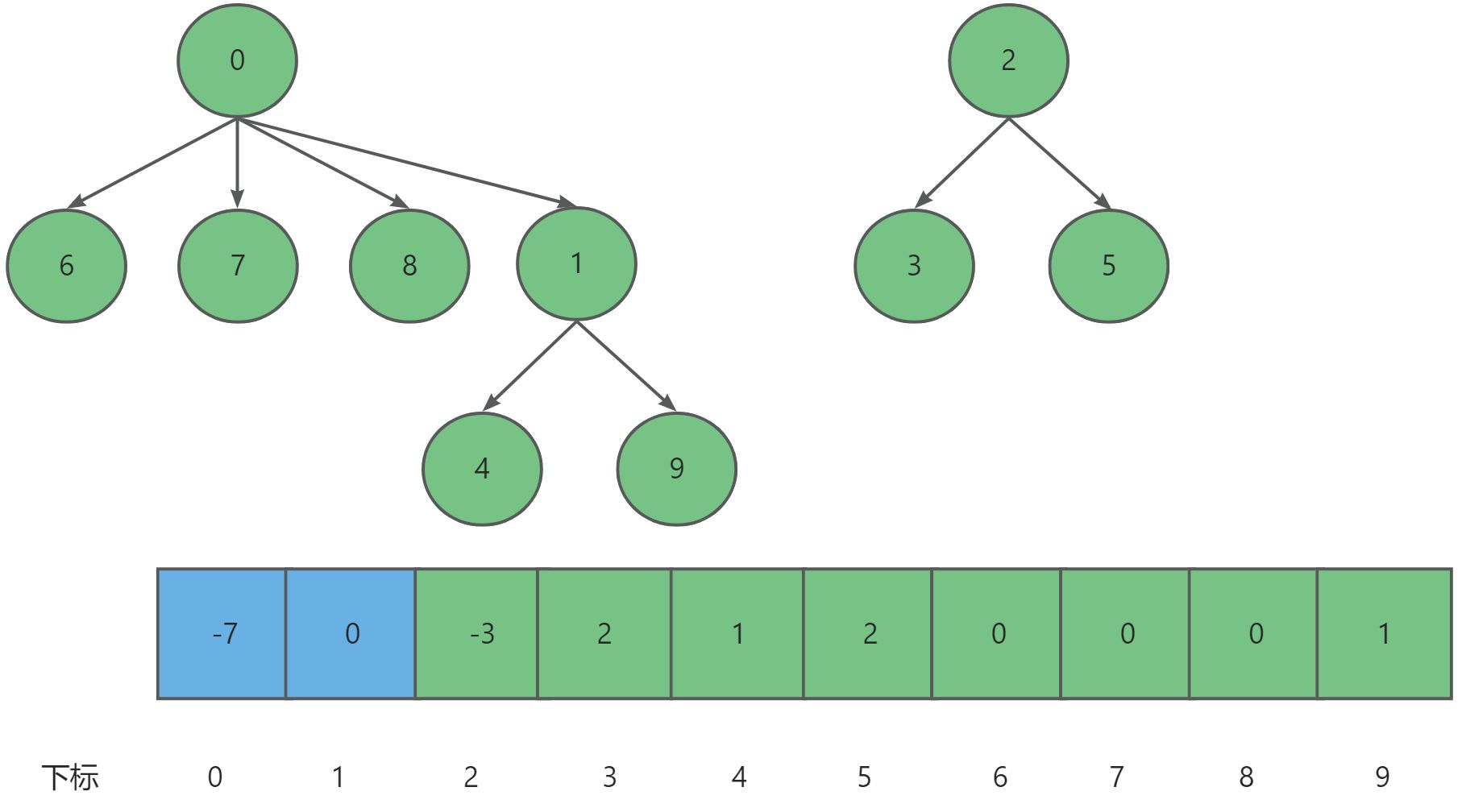
如果我们再让元素0与元素1建立联系,如果这个集合就可合并为一颗子树,对应数组的值也需更新。
2. 并查集的功能
并查集具有常见的以下几个功能:
- 初始化并查集。
- 查找元素对应的根节点。
- 判断两个元素是否在同一个集合。
- 合并两个元素所在的集合。
- 获取并查集中集合的个数。
3. 并查集的功能实现
3.1 并查集的结构
并查集的结构实现非常简单,直接以数组作为底层结构即可。
//并查集
class UnionFindSet
{
public:
//构造函数
UnionFindSet(int n);
//查找根节点
int findRoot(const int x);
//判断两个元素是否在同一个集合
bool inSameSet(const int x1, const int x2);
//合并两个元素所在的集合
bool unionSet(const int x1, const int x2);
//获取并查集中集合的个数
int getNum();
private:
vector<int> _ufs; //数组实现
};
3.2 并查集的初始化
通过上面图示我们知道并查集初始化时每一个数据都是一个根节点,所以全部初始化为-1即可。
UnionFindSet(size_t n)
:_ufs(n, -1)
{}
又因为并查集的成员变量都是自定义类型,所以不需要显示写对应的析构函数。
3.3 查找根节点
查找根节点只需要找到对应值为负数的下标即可。
int findRoot(int x)
{
int root = x;
//如果root大于0则不为根
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
return root;
}
当然我们也可以采用递归的方式实现。
//递归实现
int findRoot(int x)
{
return _ufs[x] < 0 ? x : findRoot(_ufs[x]);
}
3.4 合并两个集合
合并两个集合需要先找到对应的更节点,然后我们默认将小集合合并到大集合上,然后更新大集合的元素个数,以及小集合的根节点。
//合并两个集合
bool unionSet(const int x1, const int x2)
{
int root1 = findRoot(x1);
int root2 = findRoot(x2);
if (root1 == root2)
{
return false;
}
//将小集合拼接到大集合上
//让root1代表大集合,root2代表小集合
if (_ufs[root1] > _ufs[root2])
{
swap(root1, root2);
}
//大集合的元素个数增加
_ufs[root1] += _ufs[root2];
//小集合的父节点改为大集合
_ufs[root2] = root1;
return true;
}
3.5 判断两个元素是否在同一个集合
我们只需找到两元素的根节点判断是否相同即可。
//判断两个元素是否在同一个集合
bool inSameSet(const int x1, const int x2)
{
int root1 = findRoot(x1);
int root2 = findRoot(x2);
return root1 == root2;
}
3.6 获取并查集的集合个数
获取集合个数即判断有几个根节点。
//获取集合的个数
int getNum()
{
int count = 0;
//遍历数组如果小于0则为根
for (auto& e : _ufs)
{
if (e < 0)
{
++count;
}
}
return count;
}
4. 并查集的优化
4.1 路径压缩
在我们不断将两个集合合并的过程中,可能会出现某种极端的情况,使查找对应的根节点的效率接近线性,大大降低我们的查找效率。为了避免发生这种情况,我们可以采用一种路径压缩的形式。

路径压缩简单来说就是把节点都与根节点直接相连,减少查找效率。
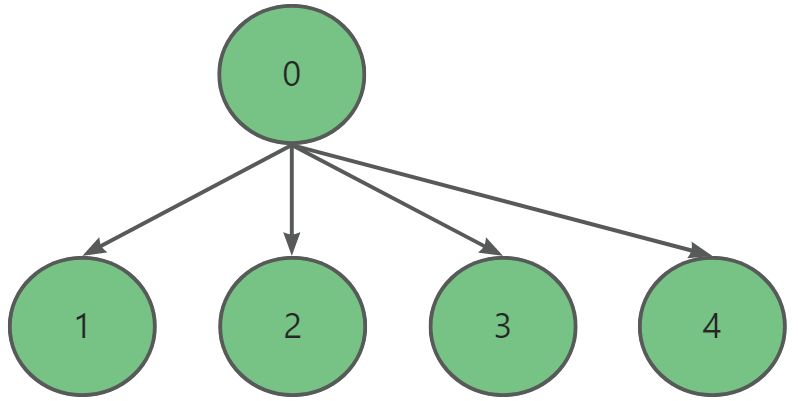
路径压缩一般我们都在查找中顺便实现。
int findRoot(int x)
{
int root = x;
//如果root大于0则不为根
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//路径压缩
while (_ufs[x] >= 0)
{
//记录父节点
int parent = _ufs[x];
//指向根节点
_ufs[x] = root;
x = parent;
}
return root;
}
当然我们也可以采用递归实现。
//递归查找
int findRoot(int x)
{
int root = x;
if (_ufs[x] >= 0)
{
root = findRoot(_ufs[x]); //找到根结点
_ufs[x] = root; //进行路径压缩
}
return root; //返回根结点
}
4.2 泛型编程
我们可以利用模版实现一个针对不同类型的并查集,而为了方便不同类型映射方便,我们还需要增加一个成员变量来映射元素与下标之间的联系。
template<class T>
class UnionFindSet
{
public:
private:
vector<int> _ufs;//并查集的底层为数组
unordered_map<T, int> _indexMap;//建立元素与下标直接的练习
};
然后我们可以先初始化时映射数据与下标的关系,查找时可以直接通过数据找到下标。
UnionFindSet(const vector<T>& v)
:_ufs(v.size(), -1)
{
//每一个元素都映射一个下标
for (int i = 0; i < v.size(); i++)
{
_indexMap[v[i]] = i;
}
}
//查找根节点
int findRoot(const T& x)
{
//找到对应下标
int root = _indexMap[x];
//如果root大于0则不为根
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//路径压缩
int index = _indexMap[x];
while (_ufs[index] >= 0)
{
//记录父节点
int parent = _ufs[index];
//指向根节点
_ufs[index] = root;
index = parent;
}
return root;
}
5. 复杂度分析
以下是对上述并查集代码中各个操作的时间复杂度与空间复杂度分析:
二、时间复杂度分析
- 并查集的初始化:
整体时间复杂度为 O ( n ) O(n) O(n)。
- 初始化
_ufs为大小v.size()的向量,时间复杂度为 O ( n ) O(n) O(n)。- 通过遍历
v建立_indexMap,时间复杂度为 O ( n ) O(n) O(n),其中 n n n 是输入向量v的大小。
- 并查集的查找根节点操作:
整体时间复杂度接近 O ( 1 ) O(1) O(1)。
- 第一次查找对应下标的时间复杂度为 O ( 1 ) O(1) O(1),因为
unordered_map的查找操作平均时间复杂度为 O ( 1 ) O(1) O(1)。- 路径压缩过程中,最坏情况下需要遍历整个集合,时间复杂度为 O ( l o g n ) O(log n) O(logn),其中 n n n 是集合的大小,但由于路径压缩的效果,后续查找操作会更快,实际平均时间复杂度接近 O ( 1 ) O(1) O(1)。
- 并查集合并两个集合操作:
整体时间复杂度接近 O ( 1 ) O(1) O(1)。
- 查找两个元素的根节点,时间复杂度接近 O ( 1 ) O(1) O(1)(因为调用了
findRoot)。- 合并操作时间复杂度为 O ( 1 ) O(1) O(1)。
- 判断两个元素是否在同一个集合操作:
整体时间复杂度接近 O ( 1 ) O(1) O(1)。
- 查找两个元素的根节点,时间复杂度接近 O ( 1 ) O(1) O(1)(因为调用了
findRoot)。- 比较两个根节点是否相同,时间复杂度为 O ( 1 ) O(1) O(1)。
- 获取并查集的集合个数操作:
整体时间复杂度为
O
(
n
)
O(n)
O(n),但通常情况下 n 较大时这个操作执行次数较少。
- 遍历
_ufs向量,时间复杂度为 O ( n ) O(n) O(n),其中 n n n 是输入向量v的大小。
二、空间复杂度分析
- 并查集整体的空间复杂度取决于两个数据结构:
vector<int> _ufs:存储每个元素的父节点信息或集合大小(负数表示根节点且绝对值为集合大小)。其空间复杂度为 O ( n ) O(n) O(n),其中 n n n 是输入向量v的大小。unordered_map<T, int> _indexMap:建立元素与下标之间的映射。其空间复杂度取决于输入元素的数量,最坏情况下为 O ( n ) O(n) O(n),其中 n n n 是输入向量v的大小。
所以,整体空间复杂度为
O
(
n
)
O(n)
O(n),其中
n
n
n 是输入向量 v 的大小。
综上所述,并查集的大部分操作时间复杂度接近 O ( 1 ) O(1) O(1),空间复杂度为 O ( n ) O(n) O(n)。
6. 源码
template<class T>
class UnionFindSet
{
public:
UnionFindSet(const vector<T>& v)
:_ufs(v.size(), -1)
{
//每一个元素都映射一个下标
for (int i = 0; i < v.size(); i++)
{
_indexMap[v[i]] = i;
}
}
//查找根节点
int findRoot(const T& x)
{
//找到对应下标
int root = _indexMap[x];
//如果root大于0则不为根
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//路径压缩
int index = _indexMap[x];
while (_ufs[index] >= 0)
{
//记录父节点
int parent = _ufs[index];
//指向根节点
_ufs[index] = root;
index = parent;
}
return root;
}
//合并两个合集
bool unionSet(const T& x1, const T& x2)
{
int root1 = findRoot(x1);
int root2 = findRoot(x2);
if (root1 == root2)
{
return false;
}
//将小集合拼接到大集合上
//让root1代表大集合,root2代表小集合
if (_ufs[root1] > _ufs[root2])
{
swap(root1, root2);
}
//大集合的元素个数增加
_ufs[root1] += _ufs[root2];
//小集合的父节点改为大集合
_ufs[root2] = root1;
return true;
}
//判断两个元素是否在同一个集合
bool inSameSet(const int x1, const int x2)
{
int root1 = findRoot(x1);
int root2 = findRoot(x2);
return root1 == root2;
}
//获取并查集的个数
int getNum()
{
int count = 0;
//遍历数组如果小于0则为根
for (auto& e : _ufs)
{
if (e < 0)
{
++count;
}
}
return count;
}
private:
vector<int> _ufs;//并查集的底层为数组
unordered_map<T, int> _indexMap;//建立元素与下标直接的练习
};
















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











