







 本文介绍了Spark SQL中数据源的基本操作,包括默认数据源Parquet的读取和写入,以及如何通过Scala程序手动指定数据源如CSV、JSON。通过format()和option()方法,可以灵活地读取和保存不同格式的文件,并调整读取参数,如处理CSV文件的表头。
本文介绍了Spark SQL中数据源的基本操作,包括默认数据源Parquet的读取和写入,以及如何通过Scala程序手动指定数据源如CSV、JSON。通过format()和option()方法,可以灵活地读取和保存不同格式的文件,并调整读取参数,如处理CSV文件的表头。
一、基本操作
Spark SQL提供了两个常用的加载数据和写入数据的方法:load()方法和save()方法。load()方法可以加载外部数据源为一个DataFrame,save()方法可以将一个DataFrame写入指定的数据源。
二、默认数据源
(一)默认数据源Parquet
默认情况下,load()方法和save()方法只支持Parquet格式的文件,Parquet文件是以二进制方式存储数据的,因此不可以直接读取,文件中包括该文件的实际数据和Schema信息,也可以在配置文件中通过参数spark.sql.sources.default对默认文件格式进行更改。Spark SQL可以很容易地读取Parquet文件并将其数据转为DataFrame数据集。
(二)案例演示读取Parquet文件
执行命令: cd $SPARK_HOME/examples/src/main/resources,查看Spark的样例数据文件users.parquet
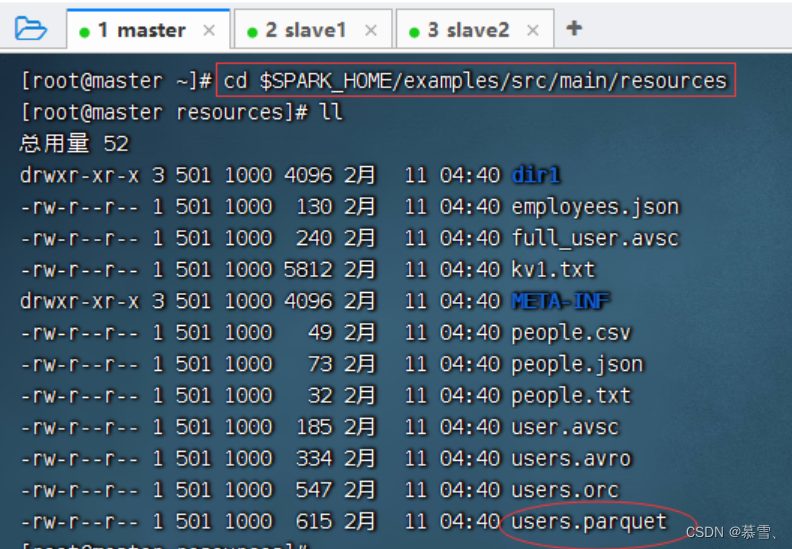
-
用
cat命令显示users.parquet文件内容,只会显示乱码 -
将数据文件
users.parquet上传到HDFS的/datasource/input目录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









