







 本文详细介绍了监督学习中的线性回归、逻辑回归、支持向量机(SVM)、循环神经网络(RNN)和卷积神经网络(CNN),以及无监督学习的基本概念。讨论了各种算法的优缺点、应用场景和解决的问题,如线性回归的可解释性和非线性数据拟合的挑战,逻辑回归在二分类问题中的应用,RNN和LSTM在序列数据处理中的作用,CNN在图像处理中的优势,以及KNN和SVM的分类原理。此外,还涵盖了数据预处理、梯度下降、模型评估指标以及防止过拟合的方法。
本文详细介绍了监督学习中的线性回归、逻辑回归、支持向量机(SVM)、循环神经网络(RNN)和卷积神经网络(CNN),以及无监督学习的基本概念。讨论了各种算法的优缺点、应用场景和解决的问题,如线性回归的可解释性和非线性数据拟合的挑战,逻辑回归在二分类问题中的应用,RNN和LSTM在序列数据处理中的作用,CNN在图像处理中的优势,以及KNN和SVM的分类原理。此外,还涵盖了数据预处理、梯度下降、模型评估指标以及防止过拟合的方法。
常见的监督学习:线性回归、决策树、朴素贝叶斯分类、最小二乘法、逻辑回归、支持向量机、集成方法
常见的无监督学习:聚类算法、主成分分析、奇异值分解、独立成分分析。
常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。
常见的降维方法包括TF-IDF、主题模型LDA、主成分分析PCA等等
常用的回归技术:线性回归、多项式回归、逐步回归、岭回归、套索回归、ElasticNet回归(是套索回归和岭回归技术的混合体)
线性回归
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
优点:结果具有很好的可解释性(w直观表达了各属性在预测中的重要性),计算熵不复杂。
缺点:对非线性数据拟合不好
适用数据类型:数值型和标称型数据
单变量线性回归
模型:
ho(x) = θo + θ1x
代价函数:
误差平方和
E=h-y
1.0/2me.T.dot(e)
梯度下降求参数:
△theta=1.0/2mx.T.dot(e)
正规方程求参数:
△theta=(x.T.dot(x))ˉ¹.dot(x.T.dot(y))
多变量线性回归
模型:
hθ(X)=θo+θ1X1+θ2X2+θ3X3 +θ4X4
代价函数: 误差平方和
E=h-y
1.0/2me.T.dot(e)
批量梯度下降:
△theta=1.0/2mx.T.dot(e)
数据预处理:
标准缩放:
meanx=np.mean(x,axis=0)
Sigma=np.std(x,axis=0,ddof=1)
Sigma:方差 ddof为自由度
(x-meanx)/sigma
归一缩放:
(x-minx)/(maxx-minx)
准确率计算:
U=Sum((y-h)**2)
V=sum((y-y.mean())**2)
1-u/v
优点:
多变量线性回归适用于所有数据,可以使用曲线来拟合数据
也可以使用正规方程,详见:1.单变量线性回归
通过特征缩放降低特征间数值都处在一个相近的范围,减小误差
多项式可以转回多变量线性回归问题进行求解
逻辑回归
逻辑回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。逻辑回归从本质来说属于二分类问题。
模型:
Z=x.dot(theta)
H=sigmoid(z)
代价函数:
交叉熵代价:
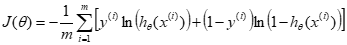
该代价函数是一个凸函数,所以没有局部最优值,只是接近
随机梯度下降:
△theta=1.0/2mx.T.dot(e)
代价对theta求偏导
数据预处理:
标准缩放:
meanx=np.mean(x,axis=0)
Sigma=np.std(x,axis=0,ddof=1)
Sigma:方差 ddof为自由度
(x-meanx)/sigma
归一缩放:
(x-minx)/(maxx-minx)
RNN:
RNN的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。
RNN有一个缺陷:随着时间距离的增大,RNN会丧失联系距它很远信息的能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









