







输入数据


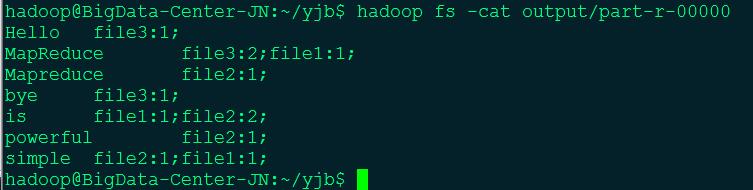
输出数据
代码
package com.test.ReversedIndex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class ReversedIndex {
public static class ReversedIndexMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//FileSplit fs = new FileSplit();
StringTokenizer st = new StringTokenizer(value.toString());
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
while (st.hasMoreTokens()){
String word = st.nextToken();
String outputKey = word + ":" + fileName;
context.write(new Text(outputKey), new Text("1"));
}
}
}
public static class ReversedIndexCombiner extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Text value:values){
sum += Integer.parseInt(value.toString());
}
int index = key.toString().indexOf(":");
String word = key.toString().substring(0, index);
String fileName = key.toString().substring(index+1);
context.write(new Text(word), new Text(fileName + ":" +Integer.toString(sum)));
}
}
public static class ReversedIndexReducer extends Reducer<Text, Text, Text,Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String newValue = "";
for (Text value:values){
newValue += (value.toString() + ";");
}
context.write(key, new Text(newValue));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "ReversedIndex");
job.setJarByClass(ReversedIndex.class);
job.setMapperClass(ReversedIndexMapper.class);
job.setCombinerClass(ReversedIndexCombiner.class);
job.setReducerClass(ReversedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0:1);
}
}
说明
本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大(具体值与默认HDFS块大小及相关配置有关),要保证每个文件对应一个split。否则,由于Reduce过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。可以通过重写InputFormat类将每个文件为一个split,避免上述情况。或者执行两次MapReduce,第一次MapReduce用于统计词频,第二次MapReduce用于生成倒排索引。除此之外,还可以利用复合键值对等实现包含更多信息的倒排索引。
参考来源
参考自 http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html















 2996
2996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









