






Python数据容器
1. 列表基础语法和操作

"""
列表的基础语法和定义:
列表:列表中的每一个数据称之为元素,列表中存储的元素类型可以不同
- 变量名 = [x1,x2,x3,...]
- 空列表 :
变量名 = []
变量名 = list()
嵌套列表的定义 -- > list = [[1,2,3],[2,3,4]]
列表的下表:与 Java数组下表一致,从0开始
"""
# 定义一个列表
study_list = ["永夜","123",123,True,["henFan","很难受"]]
print(study_list[0])
print(study_list[1])
print(study_list[2])
print(study_list[3])
print(study_list[4])
print("倒着取对应下标=======================================")
print(study_list[-1])
print(study_list[-2])
print(study_list[-3])
print(study_list[-4])
print(study_list[-5])
# 取出嵌套元素
my_List = [[123,"fuck"],[456,True,"你很棒"]]
print(my_List[0])
print(my_List[1])
"""
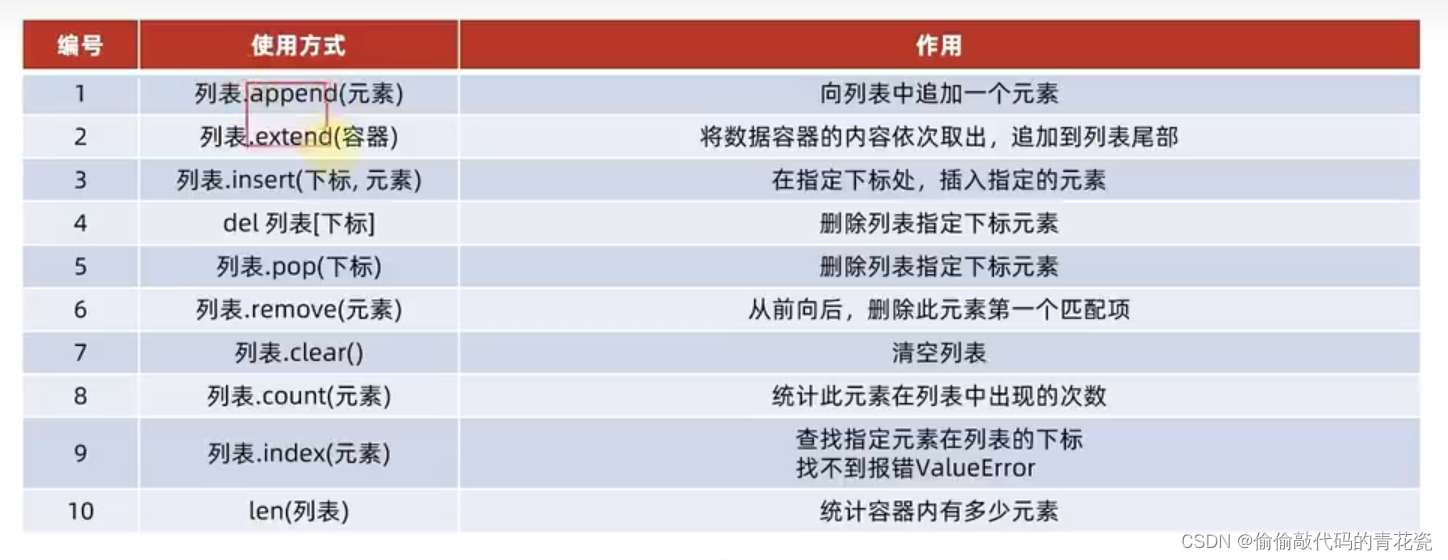
列表提供的方法:
- 查询下标:列表.index(元素)
- 元素插入:列表.insert(下标,元素) 在指定的下标位置,插入指定的元素
- 元素的追加:列表.append(元素) 尾插
- 批量追加:列表.extend(元素) 尾插
- 删除单个元素:del 列表(下标) -- > 指定下标进行删除
:列表.pop(下标) -- > 取出下标元素,可以接收
pop 和 del 的区别:del只删除元素,而 pop不仅能够删掉元素
还能将删掉的元素作为返回值去得到
列表.remove(元素) -- >删除某元素在列表中的第一个匹配项
- 清空列表:列表.clear()
- 统计元素在列表中的数量: 列表.count(元素)
- 统计列表中元素的数量: len(列表)
"""
# 查询下标:
num_index = my_List.index([123,"fuck"])
print(num_index)
# 元素插入:
my_List.insert(0,"周佳琪")
print(my_List)
print(f"插入元素后,列表变为:{my_List}")
# 元素追加:
my_List.append([1,2,3,"小鸡娃子"])
print(f"在列表后面追加了一段元素:{my_List}")
# 批量追加
my_List2 = [2,3,4]
my_List.extend(my_List2)
print(f"批量追加后的结果为: {my_List}")
print("======================列表的删除======================")
# 列表的删除操作
# del 列表(下标)
del_list = [1,2,3,4,5,6,"小王","大王","王炸"]
del del_list[2]
print(f"删除下标后的列表:{del_list}")
# 列表.pop(下标)
res = del_list.pop(5)
print(f"下标为5的元素为:{res},{del_list}")
# 列表.remove(元素) -- > 删除元素在列表中的第一个匹配项
num_list = [1,2,3,2,3]
num_list.remove(2)
print(num_list)
num_list.clear()
print(f"列表被情况le : {num_list}")
# 统计元素在列表中的个数 列表.count()
num_list = [1,2,3,2,3]
res = num_list.count(2)
print(f"2在num_list中的个数为:{res}")
# 统计列表中元素的数量: len(列表)
print(f"列表中有 {len(num_list)}个")
练习题

student_list = [21,25,21,23,22,20]
print(student_list)
# 追加元素
student_list.append(31)
print(f"追加31后的列表:{student_list}")
# 追加新列表
new_list = [29,33,30]
student_list.extend(new_list)
print(student_list)
# 取出最后一个元素
last_num = student_list.pop(-1)
print(f"最后有个元素是: {last_num}")
index_num = student_list.index(31)
print(f"31的下标为:{index_num}")
print(f"列表的长度为:{len(student_list)}")
2. 列表的循环



"""
列表的遍历:
- while循环
- for循环
"""
"""
while循环:
循环控制变量通关下标索引来控制,默认是0
每一次循环将下标索引变量+1
循环条件:下标索引 < 列表的元素数量
"""
def while_list():
index = 0
num_list = [1,2,3,4,5,10,2]
new_list = []
while index < len(num_list):
element = num_list[index]
print(f"循环取出的列表元素为:{element}")
new_list.append(element)
index = index + 1
print(f"新的列表为:{new_list}")
while_list()
"""
for循环:
"""
def for_list():
num_list = ["阿峰","不靠谱","扑该",666,False]
for element in num_list:
print(f"for循环列表的结果:{element}")
for_list()
练习题

num_list = [1,2,3,4,5,6,7,8,9,10]
def getDouble(num_List):
new_list = []
for i in num_List:
if i % 2 == 0:
new_list.append(i)
else:
print(f"{i}不是偶数")
print(f"新的列表存放的偶数为:{new_list}")
getDouble(num_list)
def while_getDouble(numList):
new_list = []
index = 0
while index < len(numList):
element = numList[index]
index = index+1
if element % 2 == 0:
new_list.append(element)
else:
print(f"{element}不是偶数")
print(f"偶数为:{new_list}")
while_getDouble(num_list)
3. 元组 tuple
元组定义:

元组的操作

因为
tuple不可改变,所以无法想 List 一样进行 增删操作
注意 元组的元素无法进行修改,元素内List的内容可以进行修改
如下:
tup_list = (1,2,["yinyue","xiaojiwazi"])
# 修改 1,2 的内容会报错
# tup_list[0] = 2
# print(tu_list)
# 修改 嵌套在元组里面列表的内容不会报错 (元素内List的内容可以进行修改)
tup_list[2][0] = "音乐"
tup_list[2][1] = "小鸡娃子"
print(f"tupList修改后:{tup_list}")
"""
元组
- 定义
- 操作
"""
"""
元组的定义
"""
# 定义元组
t1 = (1,"aFeng","牛马",True)
# 空元组
t2 = ()
t3 = tuple()
print(f"t1的类型是:{type(t1)},值是{t1}")
print(f"t2的类型是:{type(t2)},值是{t2}")
print(f"t3的类型是:{type(t3)},值是{t3}")
# 定义单个元组
t4 = ("hello") # 定义单个元组如果不加 , 那么默认为字符串
t4_1 = ("hello",)
print(f"t4的类型是:{type(t4)},值是{t4}")
print(f"t4_1的类型是:{type(t4_1)},值是{t4_1}")
"""
元组的操作
"""
# index查找,查找嵌套元组
t5 = ((1,2,3),(4,5,6))
# 我需要取出元素6
num_t5 = t5[1][2] # [1]代表最外层,[][2]代表最里层
print(f"从嵌套元组中取出的数据是:{num_t5}")
t6 = ("啊峰","是个策划","是个不靠谱的","扑该",666)
# index
num_t6 = t6[4]
num_res = t6.inedex(666) # 根据输入数据,查找对应下标
print(num_t6)
t_num = ("a","a","a","b",123,321)
# count 统计元素个数
# 统计a的个数
num_res = t_num.count("a")
print(num_res)
# len 统计元组元素数量
res_len = len(t_num)
print(res_len)
4. 元组的循环
tu_list = (1,2,3,4,5)
def tu_while(tu_list):
index = 0
while index < len(tu_list):
print(f"{tu_list[index]}")
index = index + 1
tu_while(tu_list)
def tu_for(tu_list):
for i in tu_list:
print(f"{i}")
tu_for(tu_list)
练习题

tup_ = ("周杰伦",11,["footBall","music"])
# 查询年龄所对应下标
age_index = tup_.index(11)
print(f"年龄对应的下标为:{age_index}")
# 查询学生名称
student_name = tup_[0]
print(f"学生的名称:{student_name}")
# 删除学生爱好中的 footBall
rm_num = tup_[2].pop(0)
print(f"删除的元素为:{rm_num}")
print(f"删除后元组为:{tup_}")
# 增加爱好: coding 到爱好 list 中
increase_num = tup_[2].append("conding")
print(f"增加的元素是:{increase_num}")
print(f"增加后的元组为:{tup_}")
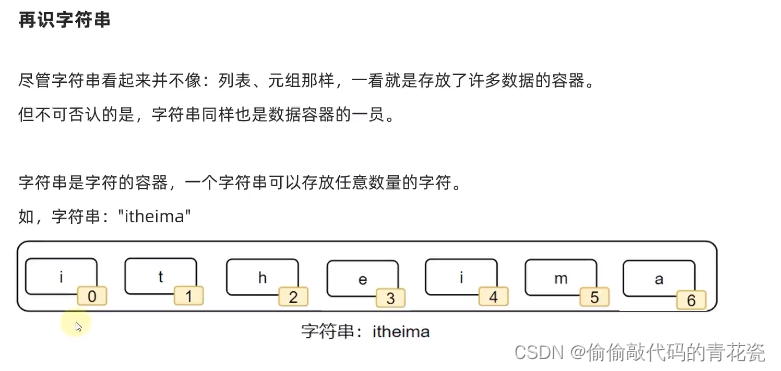
5. 字符串

"""
字符串操作
"""
str_num = "s1周佳琪isBig美女"
st_num1 = str_num[0]
st_num2 = str_num[-1]
print(st_num1)
print(len(str_num))
print(st_num2)
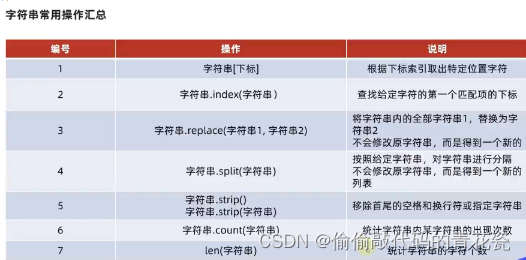
# index 方法 根据元素查找对应下标
my_str = "python全栈开发工程师"
value = my_str.index("栈")
print(value)
# replace 方法 替换 字符串.replace(“字符串1”,"字符串2")
new_my_str = my_str.replace("python","Java")
print(new_my_str)
# split 方法 按照 给定字符串进行分割 不会修改原有字符串,返回一个列表
str_value = "hello world 我要 成为 不一样 的人"
new_str_value = str_value.split(" ")
print(new_str_value)
# strip() 去掉首位 空格/换行服/
# strip("xx") 去掉指定字符串
str_value1 = " hello 小卡拉米 "
new_str = str_value1.strip()
print(f"移除首位空格后:{new_str}")
str_value2 = "12abc21"
print(str_value2.strip("12")) # abc
# 传入虽然是12,但是是按照 1 和 2 ,所以都会被移除
# count("x") 统计x的个数
str_1 = "1231132"
print(str_1.count("1"))
# len()
print(len(str_1))
test_str = "itheima itcast boxuegu"
# 统计有多少个it
res_ = test_str.count("it")
print(res_)
# 空格替换成 |
new_str = test_str.replace(" ","|")
print(new_str)
# 按照|进行分割
new_str_list = new_str.split("|")
print(new_str_list) [xx,xxx,xxx]
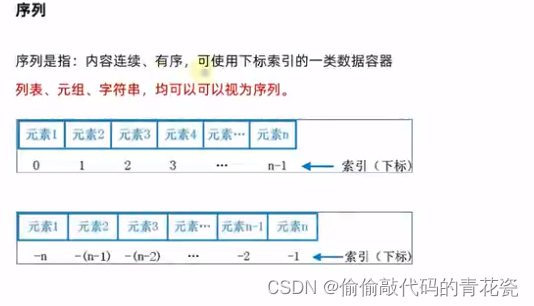
6. 切片

"""
切片操作: 列表/容器[start,end,step]
列表
容器
"""
# 对 list 进行切片,从1开始,4阶数,步长为1
my_list = [0,1,2,3,4,5,6]
result1 = my_list[1:4] # step 默认为1
print(f"my_list从1-4的结果为:{result1}") # 切片左闭右开
# 对 tuple 进行切片,从头开始,到结束,步长为1
my_tuple = (0,1,2,3,4,5,6)
result2 = my_tuple[:] # 起始到结束,步长为1
print(f"起始到结束步长为1的结果为:{result2}")
# 对str进行切片,从头开始,到结束,步长为2
my_str = "0123456"
result3 = my_str[::2]
print(f"开始到结束步长为2的结果为:{result3}")
# 对 str 进行切片,从头开始,到结束,步长为-1
my_str = "01234567"
result4 = my_str[::-1] # 等同于 将序列反转
print(f"反转后的结果为:{result4}")
# 对列表进行切片,从3开始,1结束,步长为-1
my_list = [0,1,2,3,4,5,6]
result5 = my_list[3:1:-1]
print(f"倒着来的结果为:{result5}")
# 对元组进行切片,从头到结束,步长为-2
my_tuple = (0,1,2,3,4,5,6,7)
result6 = my_tuple[::-2]
print(f"结果为:{result6}")
练习
"""
有字符串 "玩过薪悦,员序程峰啊来,狗莎大"
"""
# 得到阿峰程序员
# 具体操作如下
str_List = "玩过薪悦,员序程峰啊来,狗莎大"
# 将 字符串 倒叙
new_str = str_List[::-1]
print(f"倒叙后的字符串为:{new_str}")
# 取出 阿峰
print(new_str[5:7])
总结

7. set 集合
set 去重 且 无序(不支持下标索引)


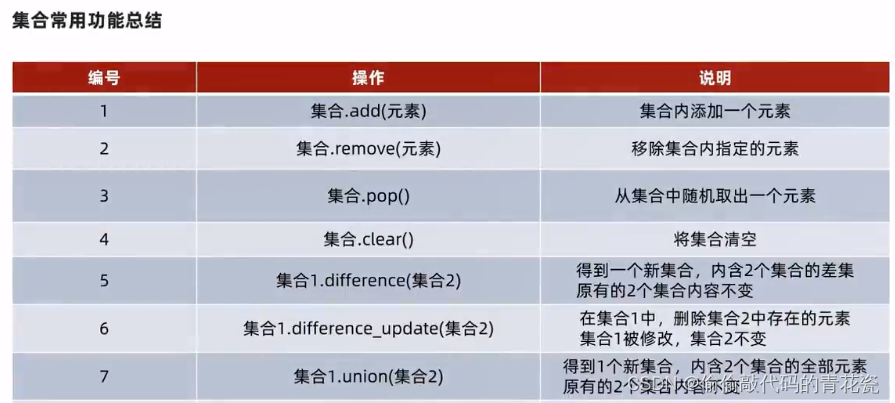
# 定义集合 -- 去重 且 无序 (不支持下标索引)
my_set = {"周佳琪","zjq","周佳琪is小坏蛋","小坏蛋zjq","zjq","周佳琪","不给女人花钱"}
my_set_empty = set()
print(f"my_set的内容是:{my_set},类型是:{type(my_set)}")
print(f"my_set_empty的内容是:{my_set_empty},类型是:{type(my_set_empty)}")
# 添加元素
my_set.add("周佳琪")
print(f"my_set添加元素后结果是: {my_set}")
# 移除元素 -- > 注意区分,remove 移除第一个匹配项
my_set.remove("zjq")
print(f"my_set移除zjq后:{my_set}")
# 集合.pop() 从集合中随机取一个 -- > 和其他容器不同,因为set无下标索引,因此是随机取出的
new_my_set = {"诗悦","西游","bigLoverForEver"}
element = new_my_set.pop()
print(f"随机取出的元素为:{element}")
print(new_my_set)
# 清空集合 集合.clear()
new_my_set.clear()
print(f"清空后的集合为: {new_my_set}")
"""
取两个集合的差集
语法: 集合1.difference(集合2) ---> 取出集合1和集合2的差集(集合1有集合2没有的)
结果: 得到一个辛几何,集合1和集合2不变
"""
set1 = {1,2,3}
set2 = {1,5,6}
new_set = set1.difference(set2)
print(f"set1和set2的差集为:{new_set}")
"""
消除差集
语法:集合1.difference_update(集合2)
对比集合1和集合2,在集合1内,删除和集合2相同的元素
结果:集合1被修改,集合2不变
"""
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2)
print(f"消除差集和set1改变为:{set1}")
print(f"set2为:{set2},没有发生改变")
"""
合并两个集合
语法: 集合1.union(集合2)
结果: 得到新集合
"""
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(f"合并后的结果为:{set3}")
print(f"set1为:{set1}")
print(f"set2为:{set2}")
"""
统计集合元素数量 len()
"""
set = {1,2,3,4,5,6}
count = len(set)
print(count)
"""
集合的遍历
集合不支持下标索引,所以不支持 while 循环
但是能够支持 for 循环
"""
for element in set:
print(f"集合元素有: {element}")
# 练习 对下列信息进行去重
my_list = ["攀枝花吴彦祖徐海涛","西北野玫瑰周佳琪","广州扑该李庚峰","zjq","zjq",
"xht","xht","啊峰","阿峰"]
# 1. 定义一个空集合
my_set = set()
# 2. 通过for循环遍历列表 -- 在for选好中将列表元素添加到集合
for i in my_list:
my_set.add(i)
print(my_set)
8. 字典 dict
字典的定义和set集合一样都是用的{},但是存储的元素不一样
字典的 key 和 value 可以为任意类型,注意: key 不能为 字典

# 1、定义字典
my_dict = {"大于":80,"小于":90,"最后":85}
# 2、定义空字典
my_dict1 = {}
my_dict2 = dict()
print(f"字典my_dict的内容是:{my_dict},类型是{type(my_dict)}")
print(f"字典my_dict1的内容是:{my_dict1},类型是{type(my_dict1)}")
print(f"字典my_dict2的内容是:{my_dict2},类型是{type(my_dict2)}")
# 3、定义重复 key 的字典 -- > 字典不允许 key 的重复
my_dict1 = {"王力宏":99,"王力宏":88,"林俊杰":70}
print(f"重复key的字典内容是:{my_dict1}") # 输出结果 "王力宏":88,"林俊杰":70
# 4、从字典中基于 key 获取 value
my_dict = {"大于":80,"小于":90,"最后":85}
score = my_dict["大于"]
print(f"score为:{score}")
字典的嵌套
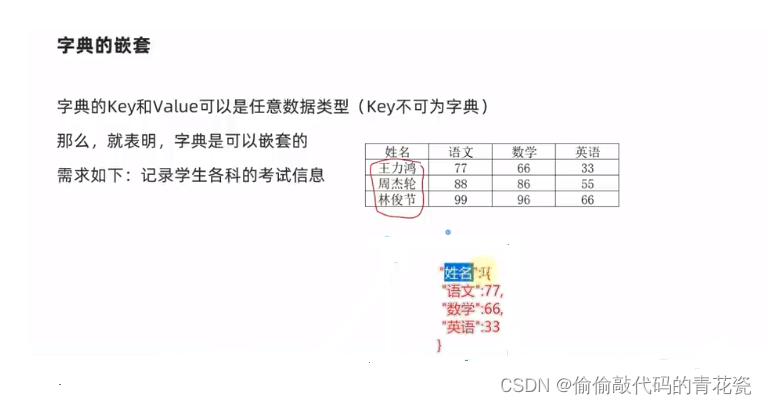
# 5、 定义嵌套字典 -- 字典的 key 可以为 任意的 类型
stu_score_dict = {
"王力宏": {
"语文":88,
"数学":90,
"英语":70
},
"周佳琪":{
"语文":89,
"数学":99,
"英语":80
},
"李庚峰":{
"语文":0,
"数学":9,
"英语":0
}
}
print(f"学生的考试信息是:{stu_score_dict}")
# 6、 从嵌套字典中获取数据
# 周佳琪语文信息
score_info = stu_score_dict["周佳琪"]["语文"]
print(score_info)
总结

字典常用操作
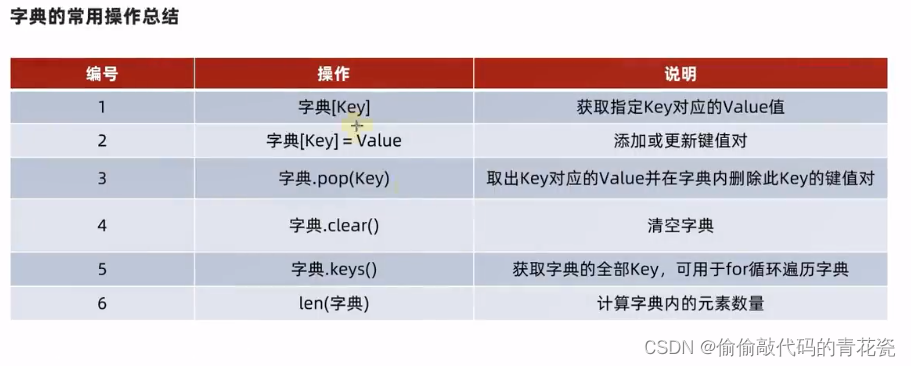
"""
字典的常见操作:
新增
删除
清空
获取全部的 key
遍历字典
统计字典内的元素个数
"""
my_dict = {"周杰伦":99,
"林俊杰":88,
"张学友":77}
# 新增元素
my_dict["周佳琪"] = 99
print(f"字典经过元素增加之后的结果为:{my_dict}")
# 更新元素
my_dict["周佳琪"] = "更新后的元素是70"
print(f"my_dict更新后的元素为:{my_dict}")
# 删除元素 pop()
score = my_dict.pop("周佳琪")
print(f"字典中删除一个元素后为:{my_dict},周佳琪的分数为{score}")
# 清空元素 clear
my_dict.clear()
print(my_dict)
# 获取全部的 key
my_dict = {"周杰伦":99,
"林俊杰":88,
"张学友":77}
keys = my_dict.keys()
print(f"全部的keys为:{keys}")
# 遍历字典
# 方法1:通关获取全部的 key 进行遍历
for key in keys:
print(f"遍历的结果为:{my_dict[key]}")
# 方法2:直接对字典进行for循环,每一次循环都是直接得到key
my_dict = {"周佳琪":80,
"阿峰":90,
"叶小儿":60}
for key in my_dict:
print(f"my_dict的key是:{key}")
print(f"my_dict的value是:{my_dict[key]}")
# 计算字典元素数量 len()
res = len(my_dict)
print(res)
练习
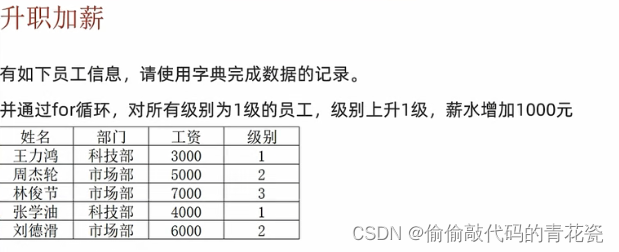
# 练习
# 定义字典
info_dict = {
"王力宏":{
"部门":"科技部",
"工资":3000,
"级别":1
},
"周杰伦":{
"部门":"市场部",
"工资":5000,
"级别":2
},
"林俊杰":{
"部门":"市场部",
"工资":7000,
"级别":3
},
"张学友":{
"部门":"科技部",
"工资":4000,
"级别":1
},
"刘德华":{
"部门":"市场部",
"工资":6000,
"级别":2
}
}
print(f"员工信息如下:{info_dict}")
# 通过 for 循环,对所有级别为 1 级的员工,级别上升1,薪资增加1000
for key in info_dict:
if info_dict[key]["级别"] == 1:
# 升职加薪操作
# 获取value
employee_info_dict = info_dict[key]
# 修改value
employee_info_dict["级别"] == 2 # 级别+1
employee_info_dict["工资"] == employee_info_dict["工资"] + 1000
# 将value的信息更新回 info_dict
info_dict[key] = employee_info_dict
print(f"更新后的信息为:{info_dict}")
9. 对比总结以及通用操作
对比总结

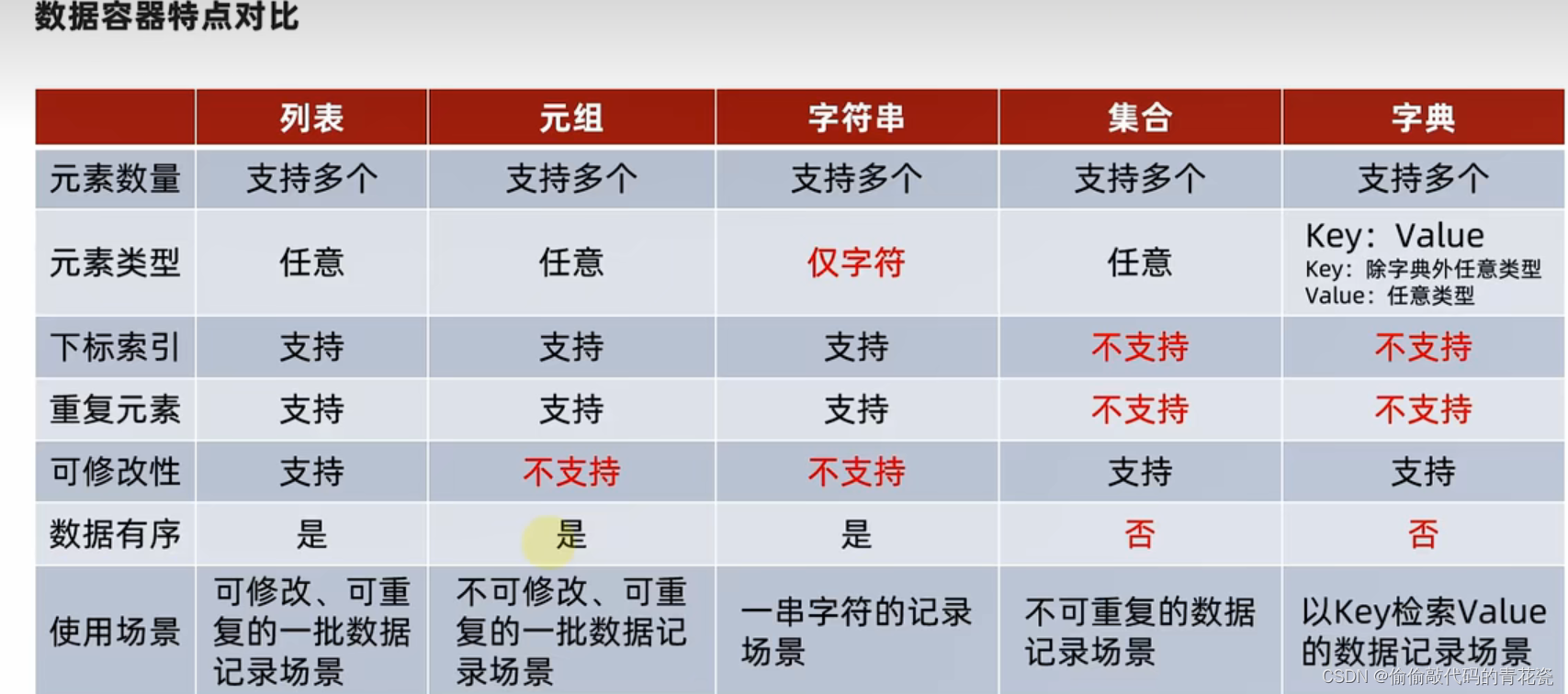

通用操作



sorted(列表,reverse=True)返回列表
"""
演示数据容器的通用功能
"""
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
my_str = "abcdefg"
my_set = {1,2,3,4,5}
my_dict = {
"key1":1,
"key2":2,
"key3":3,
"key4":4,
"key5":5
}
# len 元素个数
print(f"列表元素的个数有: {len(my_list)}")
print(f"元组元素的个数有: {len(my_tuple)}")
print(f"字符串元素的个数有: {len(my_str)}")
print(f"集合元素的个数有: {len(my_set)}")
print(f"字典元素的个数有: {len(my_dict)}")
# max 最大元素
print(f"列表最大元素是有: {max(my_list)}")
print(f"元组最大元素是有: {max(my_tuple)}")
print(f"字符串最大元素是有: {max(my_str)}")
print(f"集合元最大元素是有: {max(my_set)}")
print(f"字典最大元素是: {max(my_dict)}")
# min 最小元素
print(f"列表最小元素是有: {min(my_list)}")
print(f"元组最小元素是有: {min(my_tuple)}")
print(f"字符串最小元素是有: {min(my_str)}")
print(f"集合元最小元素是有: {min(my_set)}")
print(f"字典最小元素是: {min(my_dict)}")
# 类型转换 : 容器列表
print(f"列表转列表的结果是:{list(my_list)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表的结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")
# 类型转换: 容器转元组
print(f"列表转元组的结果是:{tuple(my_list)}")
print(f"字符串转元组的结果是:{tuple(my_str)}")
# 类型转换: 容器转字符串
print(f"列表转字符串的结果是:{str(my_list)}") # "[1,2,3,4,5]"
print(f"元组转字符串的结果是:{str(my_tuple)}") # "(1,2,3,4,5)"
# 类型转换: 容器转集合
print(f"列表转集合的结果是:{set(my_list)}")
print(f"元组转集合的结果是:{set(my_tuple)}")
# 通用排序 将给定容器进行排序
# sorted(容器,revers=True) -- > 排序后返回 列表
st_list = [2,3,13,2,0,9,20,8]
print(f"列表的排序结果:{sorted(st_list)}")
# 反向排序
print(sorted(st_list,reverse=True))
















 4122
4122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











