







首先参照官网对于过拟合和欠拟合的解释(英文版):
过拟合(overfitting)。这个术语是指一个模型与训练样本太过匹配了,以至于用于验证和检测组时无法产生出好的结果。出现过拟合的表现是一个模型在训练集能达到 100% 或 99% 的准确度,而在测试数据上却只有50%。
这里面有一句话很重要:
Always keep this in mind: deep learning models tend to be good at fitting to the training data, but the real challenge is generalization, not fitting.
永远记住这一点:深度学习模式往往适合训练数据,但真正的挑战是泛化,而不是拟合。
一般来说:损失函数的值应该是逐渐减小的。
当对于训练集的accuracy > 测试集的accuracy时,可能是过拟合了,
当然,有这样一种理解:参照官网的教程:
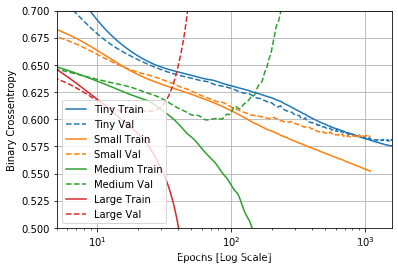
随着训练次数的增多,大的数据训练模型比小的数据训练模型更容易过拟合,就是说,如果模型选择的是小型的,就可以稍微偏大一点设置训练的次数epochs,但是如果,模型是偏大一点的模型,那训练的次数就要降下来。
具体多大的模型划分大小,要参考我上面给的官方链接文档。















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









