







文章目录
引言
- 继ICASSP2023年举办跨语言AD检测,InterSpeech今年有举办了关于跨语言检测AD的比赛,虽然没有比赛结果,但是还需要学习一下数据集以及BaseLine,给我的研究做一些支撑。
- 文章链接
- 关于痴呆检测比赛,基本上ICASPP和interSpeech两个结构都是轮流举办的,每年都有一届,我去年忘记参加了,好可惜!不然论文应该发的更早吧,那个时候还在家里过年!
正文
1、Abstract
-
为了探索通过连贯语音检测患者认知功能的可行性,我们提出了一个新基准数据集和预测任务。
- 数据集构成
- 该数据集包括普通话和英语使用者的语音样本及其临床信息,涵盖不同认知障碍程度的个体以及认知正常的个体。
- 通过倾向评分分析精心匹配了样本的年龄和性别,确保模型训练中的平衡性和代表性。
- 任务说明
- 预测任务包括轻度认知障碍的诊断和认知测试分数的预测。
- 数据集构成
-
该框架旨在鼓励开发跨语言通用的语音认知评估方法。
- 我们通过基准模型进行示例展示,模型采用语言无关的特征进行诊断和认知测试分数预测,结果显示诊断任务的平均召回率为59.2%,分数预测任务的均方根误差为2.89。
2、Introduction
1、语音检测有效性
-
痴呆问题包括记忆丧失、语音和语言障碍,以及推理困难,一般来说这些症状在老年人身上很常见。,除此之外,这些症状是综合性痴呆的前兆。因为痴呆患病率很高,并且治疗成本十分高昂,所以对于痴呆检测和抑制的相关研究十分重要。
- 关键点
- 开一个能够有效检测认知检测痴呆的低成本以及可扩展性的方法十分必要,无论是最轻微的症状还是最复杂的症状都能够检测出来。
- 关键点
-
语音信号能够直观反映患者的认知功能,是一种很容易收集的行为信号,因此可以作为一个认知能力的数字生物标记,这为语音技术的应用提供了独特的机会。
2、主要研究内容
- 我们旨在通过评估语言作为认知行为标记,在全球健康背景下研究其在认知健康指标建模中的应用,重点关注中文和英文这两大语言。
- 本文聚焦于通过图片描述任务中的连贯语音样本(也就是图片描述任务中的音频文件),预测老年中文和英文使用者的认知测试分数,并诊断轻度认知障碍(MCI)。
- 主要使用音频数据集和语音数据,进行AD检测,主要是分类和MMSE的回归任务
- 我们的目标是探索独立于语言或基于可比特征的方法。
- 为此,我们创建并向研究界分享了研究参与者在完成图片描述任务时的录音,以及相应的临床和神经心理测试数据。
3、数据集说明
- 该数据集已被用于语音处理和机器学习任务的基准,旨在通过分析连贯语音数据检测认知能力下降。
- 它成为了2024年Interspeech大会TAUKADIAL挑战赛的基础资源(http://luzs.gitlab.io/taukadial/)。
- 我们希望这一新资源能够激发语音、生物标记、信号处理、机器学习和生物医学研究领域的研究,使研究人员能够在这一新的标准化数据集上测试现有方法或开发新的方法,并为未来的研究和结果复现提供支持。
2、Background背景
-
目前研究具有以下几个问题
-
数据集不平衡
- 之前有很多做AD检测研究的,小部分是做轻度痴呆检测。之前大部分的研究所使用的数据集没有进行类别平衡,这使得通过准确度指标是一个无效的检测方式。
- 之前有很多研究在不平衡的数据集上能够取得不错的效果,但是一旦更换为平衡的数据集,效果一般!(作者自己证明了一下,这里就不提了)
-
任务设置不合理,很少去预测MMSE等医学检测结果
- MMSE(简短精神状态检查)等临床测试通常在研究中作为数据描述符,很少被用于预测任务。
- 目前大部分的研究都是使用MMSE作为分类的依据,将之和基于音频特征的分类结果进行比较,很少有研究去预测MMSE或者其他的检测指标。但是目前研究热点是有一些转变的,已经开始预测MMSE等医学检测指标的数值了。
-
没有研究尝试解决过跨语言模型
- 跨语言进行AD检测,这个问题十分的稀缺并且本质上不同于以往任何问题(异制化)
- 类似的跨语言检测模型研究
- 之前有一个研究叫做AZTIAHO做过跨语言的AD检测,该方法仅仅使用临时的音频特征,准确率在的93.79%到60%,但是这个数据集本身就很小,而且仅仅是极度不平衡的(虽然有很多不同的语言构成)
- 还有一个跨语言检测模型是基于英语和瑞士语的,最终在英语的准确度是63%,在瑞士语的准确度是72%。
- 另一项研究[17]在法语(57个样本)和英语(550个样本)中进行阿尔茨海默病(AD)与正常对照(NC)分类,获得了75%(F1 = 0.77)的准确率。
- 最近的一个信号处理挑战(ICASSP2023的比赛)解决了跨语言通用化的语音预测模型问题,使用希腊语和英语数据,在英语上训练模型并在希腊语上测试。
- 最好的系统在 AD 与 NC 分类中的准确率为69%到87%,MMSE 分数预测的均方根误差(RMSE)在4.79到3.72之间。
-
总结
- 据我们所知,我们的研究弥补了目前在跨语言语音分析、痴呆检测以及认知分数预测等多个领域的文献空白。
3、Data数据
- 在很多神经心理学科室的很多测试任务中,保存音频数据是很常见的。我们的数据集是患者在医学机构进行认知测试时,完成图片描述任务时,进行的数据采集。
英语对象的数据集采集过程
英语数据集的采集对象
- 英语参与者通过在美国社区的纸质和在线广告招募,广告目标人群为60至90岁且有记忆问题的成年人。符合条件的参与者年龄至少为60岁,能够说和理解英语,具备足够的听力和视力以参与远程健康会话,稳定服用或未服用增强认知功能的药物,并且自我报告没有重大精神障碍或其他可能导致认知能力下降的医疗疾病(如创伤性脑损伤)。参与者被分类为认知正常(NC)或轻度认知障碍(MCI)。
轻度认知障碍判定标准
- 为了被归类为轻度认知障碍(MCI),神经心理学家确定参与者符合以下美国国立老龄化研究所-阿尔茨海默病协会(NIA-AA)的标准[19]:
- (a) 自我报告认知能力下降,
- (b) 记忆受损(在客观测量中得分大于或等于 -1.5 个标准差),
- © 保持功能独立(在临床痴呆评定量表[20]中获得小于或等于 0.5 的总分,该分数通过与亲人访谈得出)
- (d) 未痴呆
数据采集过程
- 在提供知情同意后,参与者通过视频会议完成了大约90分钟的评估环节。在此过程中,参与者与评估员一起完成了话语协议和认知语言库测验[21]。与本项目相关的话语协议任务包括:
- “Cookie Theft” 图片描述任务[22],提示语为“请告诉我你看到这张图片中的一切”;
- “Cat Rescue ”图片[23],提示语为“请讲述一个有开始、中间和结尾的故事”;
- Norman Rockwell 的版画“go and come”[24],使用与营救猫咪任务相同的提示语。
- 认知语言电池测验包括蒙特利尔认知评估(MoCA)[25],其分数根据公认的做法映射到本数据集中使用的简短精神状态检查(MMSE)[26]。评估员使用标准化的脚本和材料来执行话语协议,并按照高质量音频录制指南录制整个过程。研究数据的收集使用了Research Electronic Data Capture (REDCap) 工具进行管理[27]。
中文数据采集过程
- 在用于收集中文数据的研究中,纳入标准为年龄在60至90岁之间的参与者,受教育年限不少于六年,且没有神经系统或精神疾病史。
- 神经科医生根据NIA-AA标准对轻度认知障碍(MCI)参与者进行评估。评估基于他们的临床痴呆评定量表(CDR)得分,全球评分为0.5,并且在招募前两年内进行的脑部磁共振成像(MRI)显示出与阿尔茨海默病相关区域的萎缩。
- 研究使用图片描述任务来引发连贯语音,采用数字录音机记录参与者的回答。参与者描述了一组展现台湾文化的三幅图片,任务指令为报告他们在每幅图片中观察到的所有内容。
- 评估人员避免提供反馈,但如果参与者的回答不够充分,会鼓励其详细说明。该研究获得了台北天主教耕莘医院伦理审查委员会的批准(CTH110-3-8-041),所有参与者均签署了书面知情同意书。
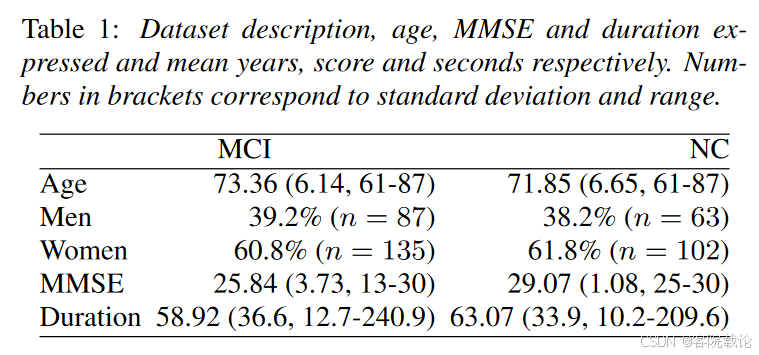
整体数据分布
- 为了避免模型中的偏差,整个数据集(包括英语和中文)在年龄和性别上进行了平衡。
- 通过逻辑回归估算样本的AD概率,并选择匹配的样本,确保了协变量之间的标准化均值差异较低,表明数据集具备良好的平衡性,适合用于训练模型。
数据集的构成
- 训练集和测试集分别包含中文和英文语音样本,每个参与者有三段图片描述。
- 总体上,数据集中共有507个样本,总时长528分钟,训练集和测试集的比例为3:1。该数据集已开放给研究界,通过 DementiaBank 获取。
具体数据集分布见下图
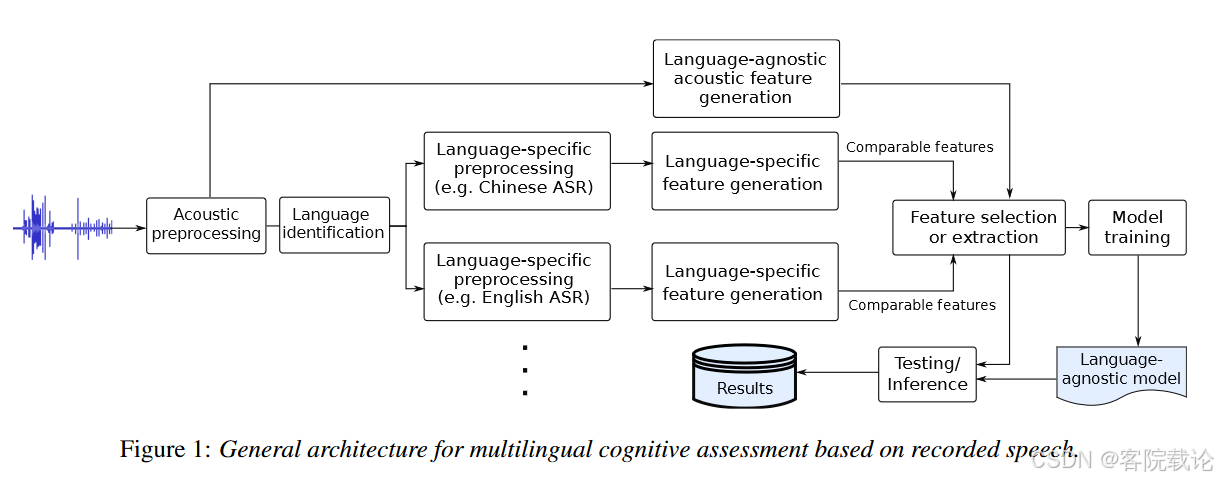
5、Modeling Approach建模方法
- 由于我们的目标是探索能够跨语言通用的模型,我们致力于为每项任务创建一个包含从两种语言中提取特征的单一预测模型。因此,图1展示了我们的分类和回归系统的总体架构,其中从两种语言中提取的可比特征被结合到一个单一的预测模型中。
5.1 Feature Extraction特征提取
- 特征提取过程旨在识别能够很好地跨两种语言泛化的语音特征。对于声学特征,我们测试了两种不同的方法:
- 一种是传统的特征工程方法,使用一个在情感识别和其他计算副语言任务中被认为有效的特征集*(eGeMAPs);
- 另一种是自监督特征学习方法。
eGeMAPS
- eGeMAPs 特征集包括 F0 半音、响度、频谱通量、MFCC(梅尔频率倒谱系数)、抖动、闪烁、F1、F2、F3、α 比率、Hammarberg 指数以及斜率 V0 特征,并对这些特征应用了多种统计函数。每个音频录音总共提取88个特征[29]。
自监督特征
- 对于自监督特征提取,我们使用了预训练模型 wav2vec,在没有进行微调的情况下,直接从原始音频中提取特征。
后续处理特征
- 为了平衡所有音频录音的时长,我们对音频录音进行了零填充,以便进行特征提取。特征是从特征提取层中提取的。然后我们应用了一个dropout层,接着是一个特征聚合层,再加上另一个dropout层。为了进行降维,我们使用了 MaxPool1d 层(大小为42000,步幅为10000)。最终结果作为多层感知器(MLP)模型的输入特征,每个音频录音提取到512个特征。
语义特征的提取
- 最后,我们提取了可以跨语言比较的语言特征。首先使用自动语音识别(ASR)对录音进行转录,并进行了词性标注。接着计算了以下特征:词元数量、词类数量、词类与词元比率、密度(动词、形容词、副词、介词和连词占词元总数的比例)、动词比率和代词比率。为了考虑图片和描述的差异,词元数量和词类数量进行了z-score标准化。
- 这里可以做很多优化!
5.2 Classification regression分类回归问题
-
多层感知器(MLP)模型在不同的特征组合上进行了训练,使用了Adam优化器和ReLU激活函数。MLP模型用于分类和回归任务。
-
具体参数设置
- 我们设置了α = 10⁻⁴,隐藏层的大小为55、160、160和55,学习率固定为0.001,最大迭代次数为10,000。
- 在这两种任务中,使用了20折交叉验证。
- 模型开发是在Intel Core i9-9980HK CPU @ 2.40GHz、16 GB内存以及8 GB GPU内存(Nvidia GeForce RTX 2080 max-q设计)上进行的。
-
用于数据集平衡、特征提取、模型训练、交叉验证和测试的软件可以在https://gitlab.com/luzs/taukadial获取。
6、Results结果
- 在分类(诊断)任务中,我们的模型在融合了wav2vec和eGeMAPs特征后,在测试数据上的未加权平均召回率(UAR)达到了59.18%。完整的结果显示在表2中。
- 置信区间是通过1000次自举法获得的。该任务的基线结果是测试数据上59.18%的UAR(σ = 0.587, ρ = 0.597, π = 0.617)。两种语言(英语和中文)的结果非常相似(英语:UAR= 60.00%,σ = 0.40, ρ = 0.80;中文:UAR= 60.04%,σ = 0.39, ρ = 0.81)。总体准确率为0.592,F1得分为0.602。图2展示了每个特征集对分类性能的影响,表3展示了两种语言中表现最好的方法的结果。


8、Conclusion
- 本文提出了一个新的基准数据集,用于通过对连续语音的自动分析进行认知评估模型的开发和测试。特别是,本文定义了轻度认知障碍(MCI)诊断和MMSE评分预测的学习任务。
- 提出了一种用于跨语言认知评估的一般处理架构,该架构结合了语言无关的声学特征和英语与中文中可比较的语言特征,整合到一个预测模型中。
- 基线模型展示了这些预测任务以及特征提取的方法。数据和元数据已经向研究社区开放。随着医学界对语音生物标记作为早期检测和监测认知问题的一种便捷且成本效益高的方法的兴趣不断增加,我们预计这一新资源将促进跨语言认知功能建模这一尚未充分探索领域的进一步研究。
总结
- 这个比赛很有意义,因为目前AD检测的主要问题就是数据集过少,大部分数据集都是英语数据集,但是实际上很多患者分布在非英语的国家,所以需要解决多语种数据小的问题。这个比赛刚好是解决了英语检测样本和中文检测样本的问题,不过Baseline做的实在不够高明,对于语义信息的提取还是需要再进一步改良的。
- 这篇文章主要是对这个数据集了解的更加深刻,方便以后自己做科研!加油!趁现在,抓紧把论文写完!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









