







本文主要分析redis服务器的工作的实现原理,事件,以及redis与memcache处理高并发请求的对比。
1. Redis的工作流程
首先从宏观上来看一下redis如何处理一个请求,以set key value为例,分为以下4步:
(1) client向server发送命令请求set key value

client会将
set key value转换成协议:
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
(2) 当client与server的socket可用时(IO多路复用技术,稍后介绍),server将协议内容保存到redisClient的输入缓冲区;然后分析命令,保存到argc和argv中。
(3) 命令执行器
根据argv[0]在command table中查找set命令,执行预备操作(判断参数、身份验证等)后,调用命令执行;
(4) 当client socket变为可写状态时,服务器执行命令回复处理器(函数),将保存在client输出缓冲区的"OK"回复给client。
2. Redis的事件
Redis服务器是一个事件驱动程序,event是server对socket操作的一种抽象,每次的accept、read、write等都会产生一个event,服务器需要处理如下两类事件:
- file event(文件事件)
- time event(时间事件)
- file event handler采用IO multiplexing来监听多个socket,并根据socket的任务来关联不同的handler(functoin);
- 每一个accept、read、write、close都会产生一个event,socket被封装在event中;
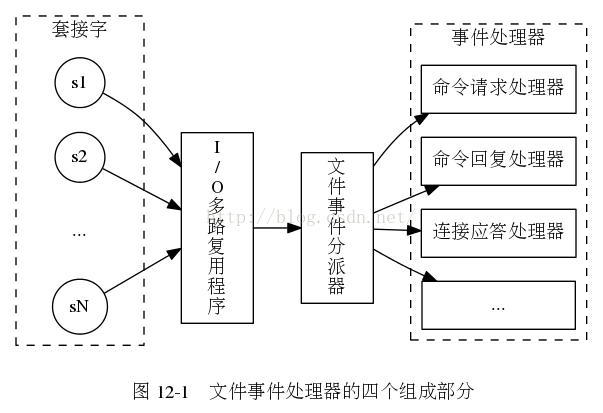
如图,IO多路复用程序负责监听多个socket,每当一个socket可用时,IO多路复用程序便会产生一个file event,并将产生事件的socket放入一个队列,如下图:

当一个socket产生的event被处理完毕后,IO多路复用程序才会向文件事件分派器传送下一个socket。
由以上,file event handler以单线程方式运行,但通过IO多路复用技术来监听socket,既实现了高性能的网络通信模型,又可以很好地与redis server中其它同样以单线程运行的模块对接,从而保证了redis实现的简单性。
我们来看IO多路复用程序是如何实现的:
Redis的IO multiplexing的实现都是通过包装常见的select、epoll(Liunx)、kqueue(BSD)、evport(Solaris)的IO多路复用函数库实现的,具体在文件ae_select.c, ae_epoll.c, ae_kqueue.c中实现;
Redis源码中用#include macro定义了相应的规则,使系统自动选择性能最高的IO多路复用函数库作为其底层实现。
3. Redis与Memcached的比较
从实验中可以看出,redis的速度非常快;作为单线程的redis为什么快?先给出以下三点原因:
- 绝大部分操作时基于内存的(非常快);
- 采用单线程,避免了高并发时线程之间的上下文交换和竞争条件;
- 采用异步非阻塞IO,它的性能远高于同步阻塞IO。
另外,redis采用了epoll+自己实现的简单event框架,绝不在io上浪费一点时间。由于网络IO是瓶颈,redis在这一点上作了很好地处理。
有的人分析了CAS(compare & set或者compare & swap)问题,CAS是memcached中一种比较方便的防止竞争修改资源的一种方法。虽然开销非常小,但不排除高并发情况下对memcached的性能有微小影响。
CAS是cpu指令支持的一种原子操作,GCC、windows、C++中各有对CAS不同的实现,类似的原子操作还有:
fetch and add(原子+1),test and set(写值到内存并返回旧值)等等。
下面的网址有如何用CAS来实现无锁队列(lock free queues):
http://coolshell.cn/articles/8239.html















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









