






BUAA-2023-SE-PP
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 课程社区 |
| 这个作业的要求在哪里 | 作业要求 |
| 我在这个课程的目标是 | 积累软工经验,进行软工方法论实践,提高工程能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 进行软工方法实践 |
1 项目地址
教学班级:周四班
项目地址:https://github.com/CoolColoury/BUAA-2023-SE-PP/
2 PSP表格——预估
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | |
| · Estimate | · 估计这个任务需要多少时间 | 15 | |
| Development | 开发 | 1570 | |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | |
| · Design Spec | · 生成设计文档 | 20 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | |
| · Design | · 具体设计 | 100 | |
| · Coding | · 具体编码 | 1000 | |
| · Code Review | · 代码复审 | 120 | |
| · Test | · 测试 (自我测试,修改代码,提交修改) | 300 | |
| Reporting | 报告 | 250 | |
| · Test Report | · 测试报告 | 30 | |
| · Size Measurement | · 计算工作量 | 20 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 200 | |
| 合计 | 2035 |
3 接口设计思想使用
3.1 Information Hiding
信息隐藏是结构化程序设计与面向对象设计的基础之一。当信息被隐藏后,每个类都代表了某种对其他类保密的设计或构建决策。隐藏起来的秘密可能是某个易变的区域,或者某种文件格式,或某种数据类型的实现方式,或某个需要隔离的区域,在这个区域中发生的错误不会给程序其余部分带来太大损失。
——《代码大全》
在我们的编程中,我们以所有的类应该对其自己负责的思想来进行设计,类对外只暴露必要接口,例如我们的图类 WordGraph 只提供接口查询理解边,而不返回底层储存图信息的数据结构。这样当我们在优化底层容器是只需要讲注意力集中在 WordGraph 类中。
3.2 Interface Design
按接口设计方法上,我们首先讲整个程序划分成计算模块、输入模块、输出模块、错误处理模块,模块和模块间指通过接口进行交流。而在具体的模块中,我们在具体代码编写前也为所有的类设计了对外接口。而对于与GUI对接的三个接口我们则是通过类Adaper模式进行封装。
按接口编程我最大的体验是在设计单元测试上非常方便,在实现模块间的解藕上很有启发性。
3.3 Loose Coupling
松散耦合目标是让一个模块不依赖或者很少依赖其他模块,更容易被其他模块调用。
在设计中我们完成了计算模块、输入模块、输出模块、错误处理模块的解耦合,计算模块内部也通过策略模式实现了新增算法和原有算法的解耦合。但我们做的稍微不好的一点是在输入模块和计算模块间过度依赖 WordGraph 类传递信息。
4 计算模块接口的设计与实现过程
首先我们我们对单词的预处理、对参数类型采用不同建图策略等操作都封装到了 WordGraph 类中实现。
wordgraph类对外(public)有以下方法:
// 构造方法
WordGraph(const std::vector<std::string>& words, Config& config);
// 获取总边数(单词数)
int get_edge_num() const { return edge_num; }
// 返回一个节点的邻接边
const std::vector<Edge>& get_edges(int node) const;
// 返回两个节点间的边(仅在enable_loop下会进行使用)
const std::vector<Edge>& get_edges(int from, int to) const;
// 返回节点拓扑序
const std::vector<int>& get_topo_list() const;
// 获得单词链数量
long long get_chains_num();
以及以下私有(private)方法:
// 含单词环
bool contain_circle();
// 构建拓扑序列
bool make_topo_list();
// 解析参数建图
void parseConfig(Config& config);
// 简化图(在非enable_loop下会进行使用)
void simplify_dag(char type);
其中,构造方法会将所有单词小写并去重(题目要求)。封装在 WordGraph 类中的好处是我们可以在解决单词链问题时只关注图抽象层次的内容(例如某个节点的邻接边,),而不用关注图底层实现(实际上底层是用map实现的)。
而图的处理上,采用了策略模式来实现不同方法的解藕,由 Solver 类进行调用
Solver 类声明为:
class Solver
{
private:
Strategy* m_strategy;
WordGraph m_word_graph;
Config m_config;
public:
Solver(WordGraph& word_graph, Config& config);
void solve(std::vector<std::string>& output);
~Solver();
};
Strategy 抽象类声明为:
class Strategy
{
public:
virtual void solve(WordGraph& word_graph, Config& config, std::vector<std::string>& ans) = 0;
virtual ~Strategy() = 0;
};
实际调用链上是 Solver 在构造函数中创建对应 Strategy 方法的实现,在 Solver::solve 中调用 Strategy::solve。使用策略模式的好处是我们可以在实现和验证某个算法正确性的同时而不干涉其他算法。
我们策略迭代大概经历了下面几个过程:
-
深度优先搜索有环/无环图。这个算法大概30-40行就写好了,初期选择这个方法主要是为了保证正确性(避免过早考虑优化)。实现过于简单也不展开了。
-
将不允许环的图改为拓扑排序实现。
-
拓扑排序可以判断图中是否有单词环,即自环不能超过两次,且去掉自环的可以构造拓扑序列
-
由于单词链需要两个以上单词并且图中允许一个自环,所以递归式为:
d p i = m a x j 拓扑序在 i 后 ( d p j + w i j , t a i l j + w i j ) t a i l i = m a x ( t a i l i , w i j ) , i ≠ j dp_i = max_{j 拓扑序在 i 后}(dp_j+w_{ij},~tail_j+w_{ij})\\ tail_i = max(tail_i, w_{ij}),~i\ne j dpi=maxj拓扑序在i后(dpj+wij, tailj+wij)taili=max(taili,wij), i=j
其中, t a i l i tail_i taili 表示以 i i i 开头最长的单个单词,如果 i i i 有自环还需要在遍历结束后
d p i = m a x ( d p j + w i i , t a i l i + w i i ) t a i l i = m a x ( t a i l i , w i i ) , i ≠ j dp_i = max(dp_j+w_{ii},~tail_i+w_{ii})\\ tail_i = max(tail_i, w_{ii}),~i\ne j dpi=max(dpj+wii, taili+wii)taili=max(taili,wii), i=j
实现细节上由于要记录也有不少细节,实际这个算法写了约100行。
-
在计算单词链总数也采用了拓扑排序,如果超过20000可以不需要记录就直接抛出异常。否则暴力搜索。
-
-
优化有环时的DFS:由于有环下是NP问题,我们使用了剪枝和并发来加速搜索,这将在性能改进部分展开描述。
对于官方提供的三个接口函数,我们直接采用了 Adapter 的思想调用我们自己的计算模块。
int gen_chains_all(const char* words[], int len, char* result[]);
int gen_chain_word(const char* words[], int len, char* result[], char head, char tail, char reject, bool enable_loop);
int gen_chain_char(const char* words[], int len, char* result[], char head, char tail, char reject, bool enable_loop);
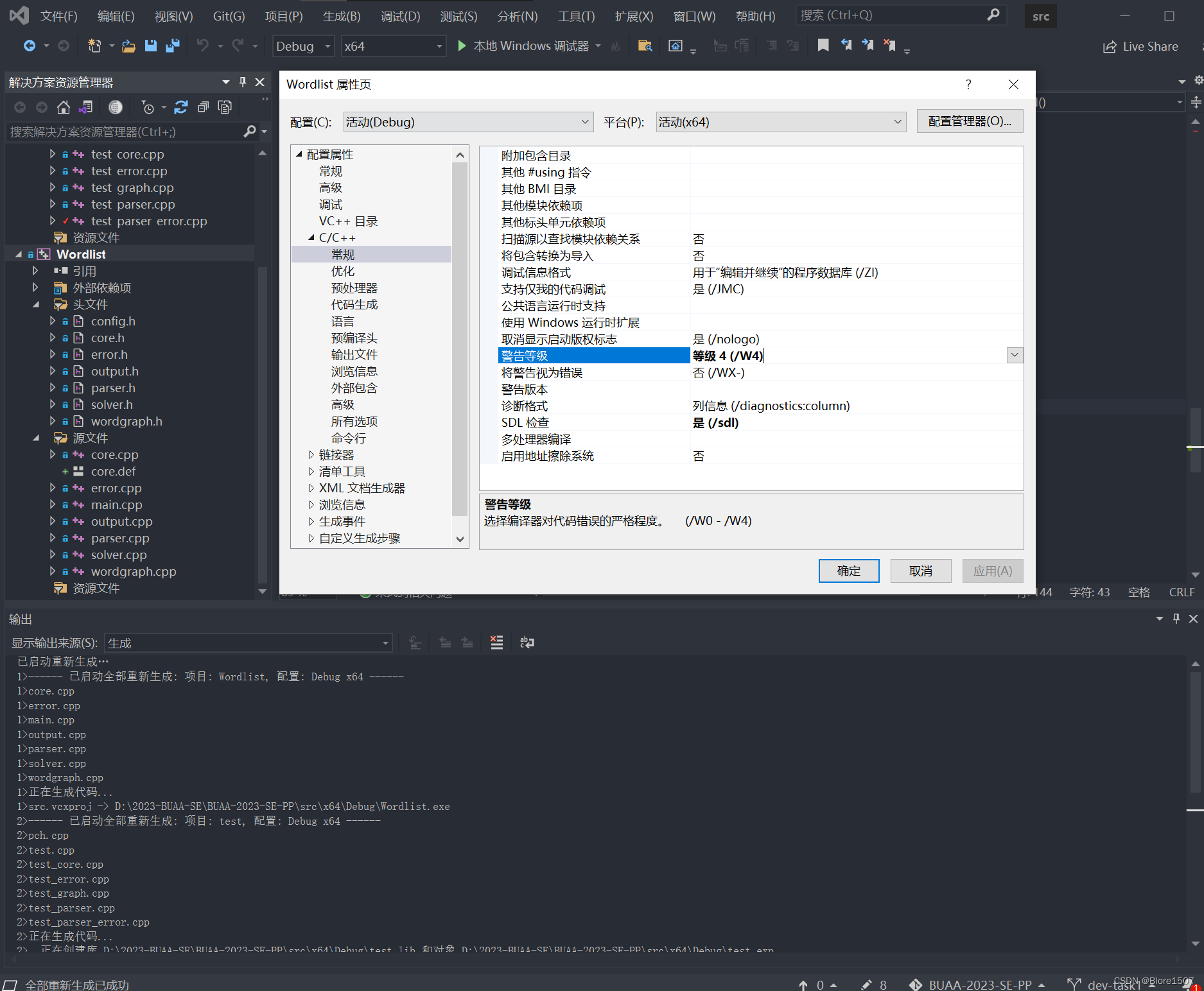
5 编译通过无警告截图
我们开启了W4警告等级,并消除了全部警告。以下是我们的无警告截图。
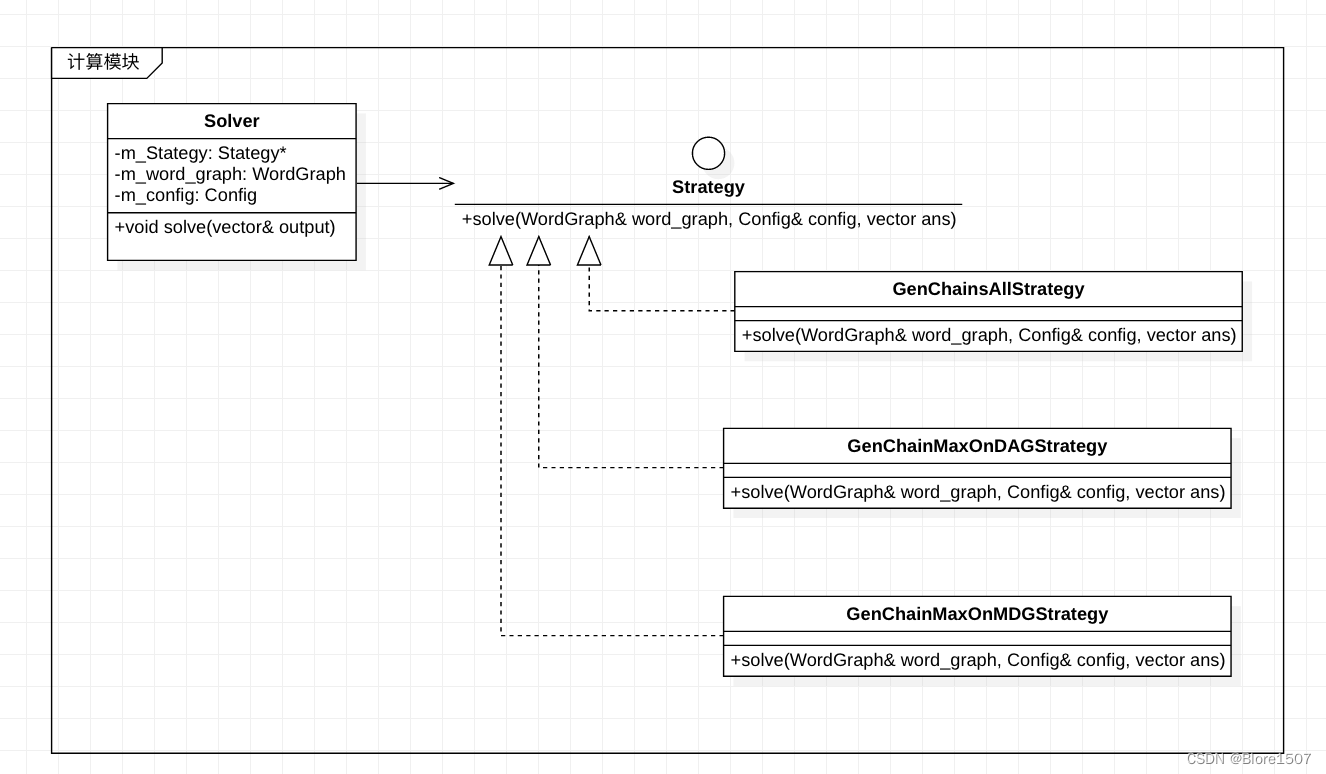
6 UML
计算模块UML如图,其中WordGraph和Config是我们自己的数据类
7 计算模块接口部分的性能改进
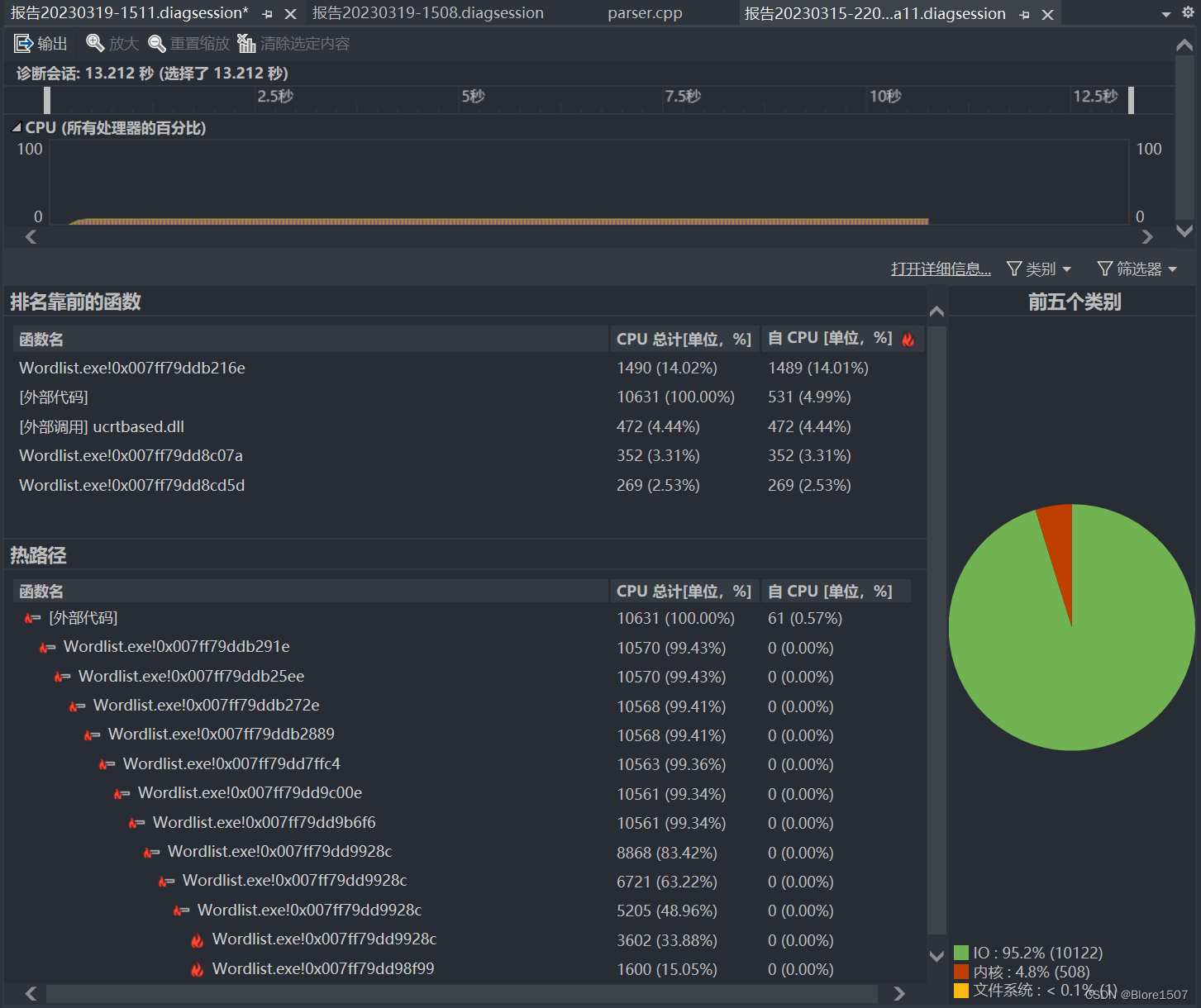
分析过程
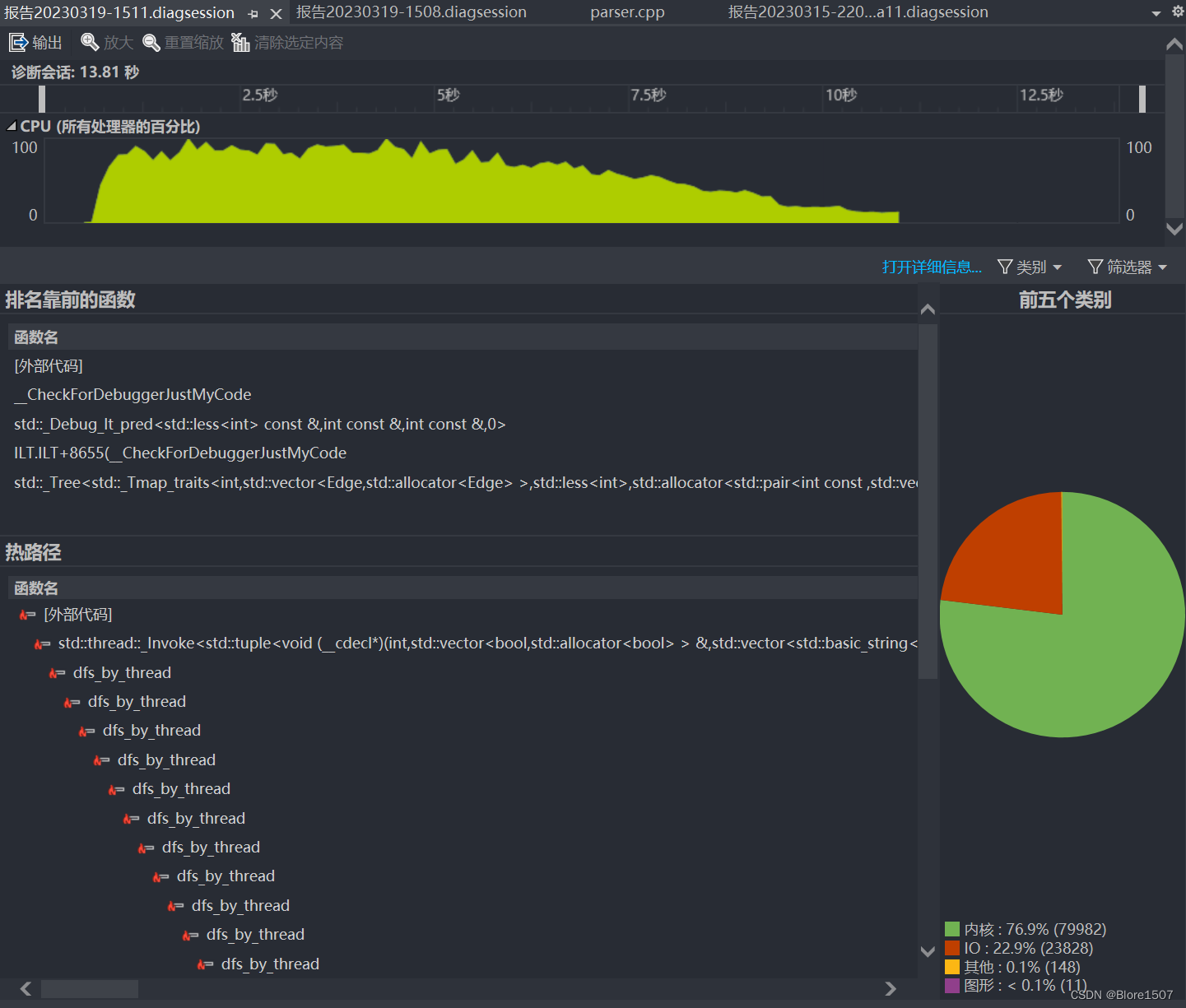
我们找到了一个60个单词成环情况下的性能点。
3.15日,我们进行了第一版代码的性能测试,测试信息如下(由于Visual Studio的问题,函数名没能正常显示)。可以得到如下问题:
CPU占用率很低。热力图集中在成环dfs函数上。
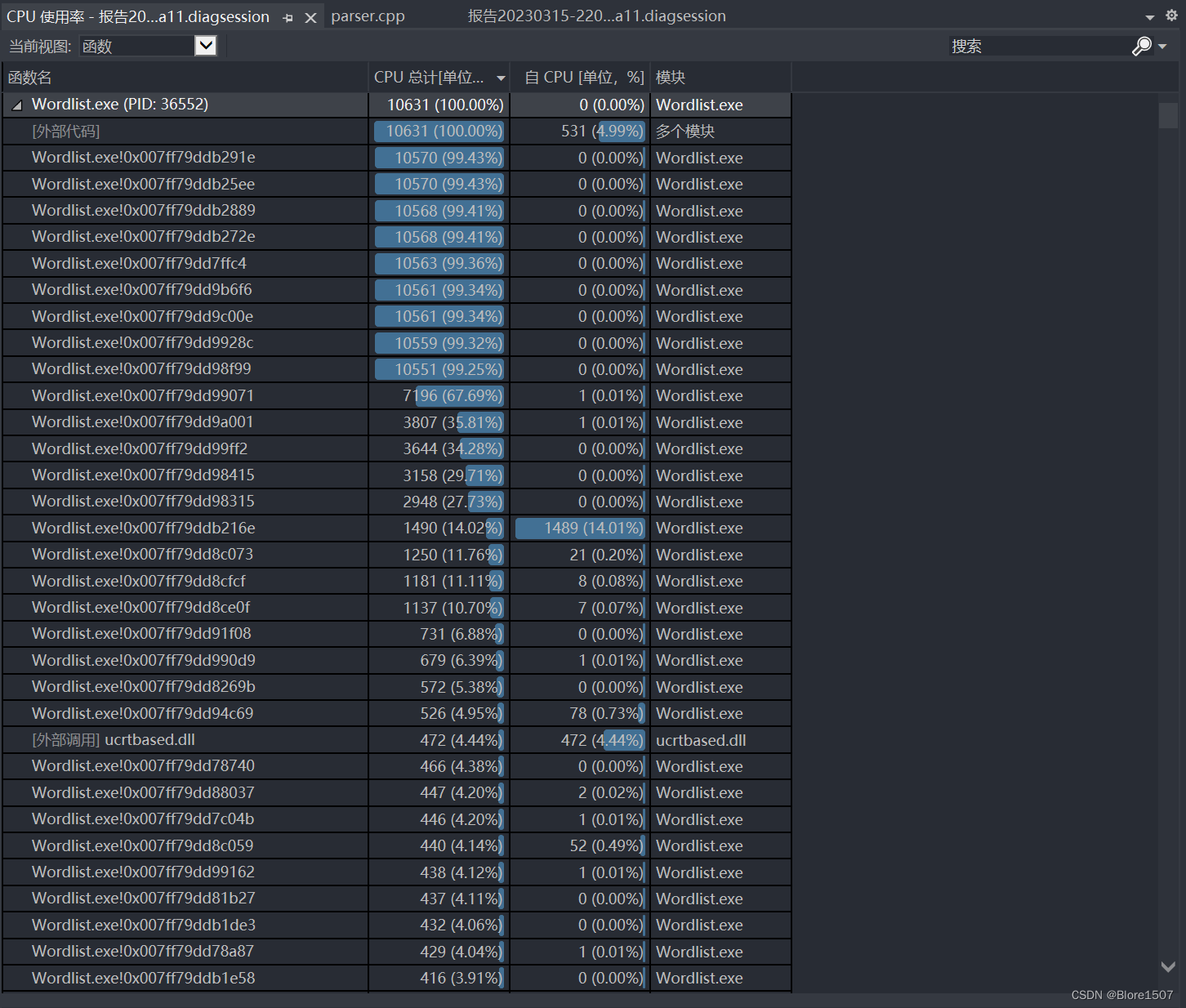
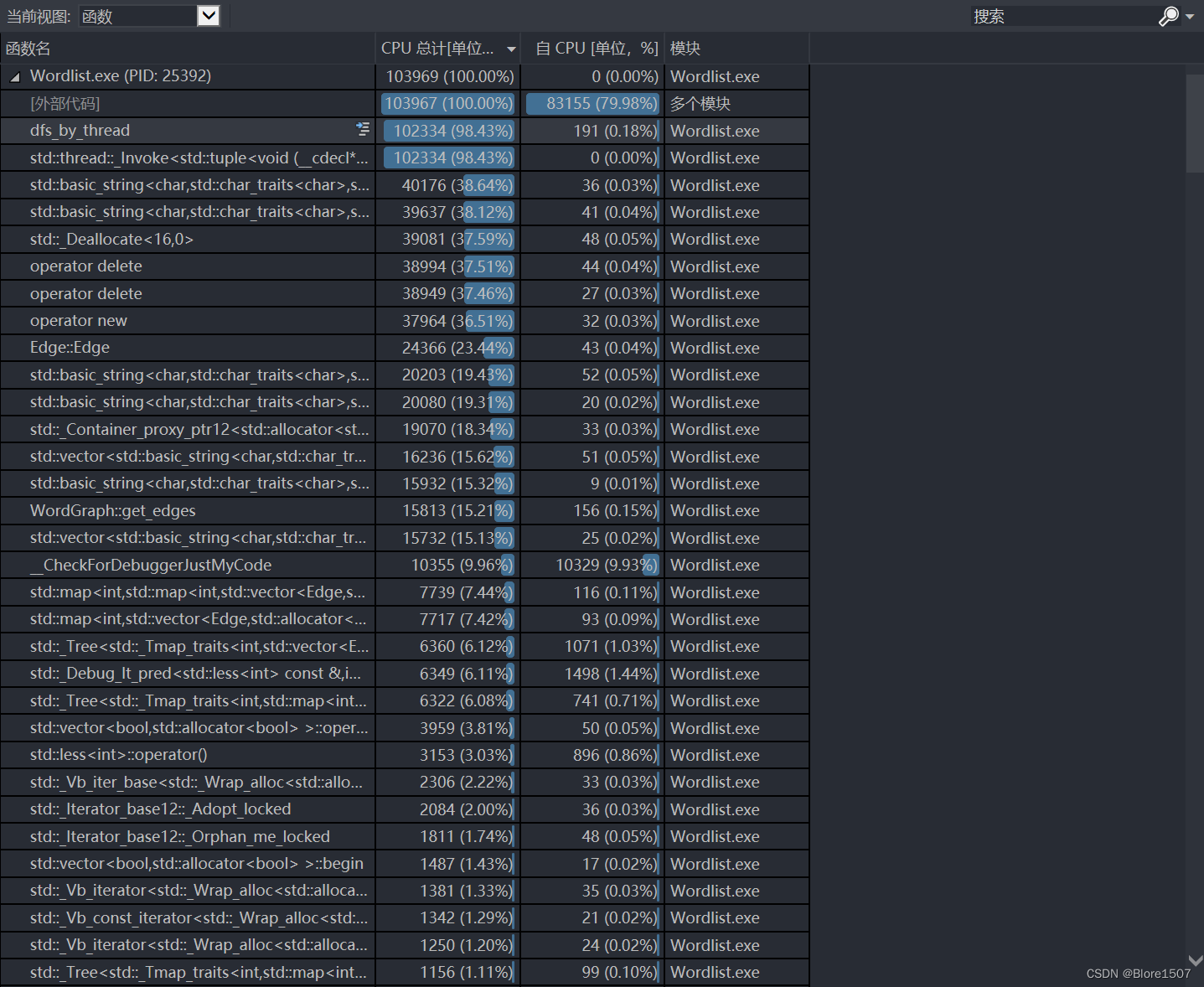
3.19日,进行优化过后对同一个测试点的性能测试,测试信息如下图所示。
改进过程
由于无环图下时间复杂度已经是线性,且根据性能分析主要的时间开销在IO上,所以主要的优化还是针对有环NP问题的优化。主要采用了以下方式:
-
剪枝:
-
自环直接处理
-
每次选择邻边时选择权重最大的一条
-
-
多线程并发。使用了
<thread>库,对遍历的每个开始节点都构建一个线程,在所有线程结束后找最优解。void GenChainMaxOnMDGThreadStrategy::solve(WordGraph& word_graph, Config& config, std::vector<std::string>& ans) { /* 初始化 */ for (int i = 0; i < num_node; i++) { /* 一些守护条件 */ using std::ref; if (!word_graph.get_edges(i).empty()) { threads[i] = std::thread(dfs_by_thread, i, ref(vis[i]), ref(edges[i]), ref(word_graph), ref(config), ref(c_ans[i]), 0, ref(c_ans_len[i])); } } for (int i = 0; i < num_node; i++) { if (!word_graph.get_edges(i).empty()) { threads[i].join(); } } /* 找到最优解 */ } -
用release发布生成版本(之前一直用的Debug版本,结果一直很慢)
性能总结 (命令行测试某个随机生成的60个单词成环数据)
| DEBUG版 | ∆ | RELEASE版 | ∆ | DEBUG和RELEASE版 | |
|---|---|---|---|---|---|
| 朴素DFS | 6709ms | - | 359ms | - | 1868.8% |
| 剪枝优化 | 6620ms | 101.3% | 388ms | 92.5% | 1706.2% |
| 剪枝优化+多线程 | 4320ms | 153.2% | 127ms | 305.5% | 3401.6% |
由于是随机生成的数据,剪枝优化效果并不好,但是依旧保留了剪枝优化。
8 契约相关
Design by Contract,Code Contract 是一种设计软件的方法,要求软件设计者为软件组件定义正式的,精确的并且可验证的接口。这样,可以保证软件组件之间的协作和正确性,避免出现错误和异常。Design by Contract,Code Contract 的优点是可以提高软件的质量、可靠性和可维护性。缺点是可能增加开发的复杂度和成本,以及需要更多的测试和验证。
在我们的编写代码中我们并没有用到契约式编程,而是用到了测试驱动开发(TDD),在设计好接口后先编写单元测试后进行具体代码编写。两者的共同点都是在写功能代码之前就明确需求和规范。我们没有用到契约式编程的理由很简单:我们在迭代上更加频繁,所以使用了测试驱动开发这一更追求软件功能的符合性和可维护性的方法。
9 计算模块部分单元测试展示
主要是对题目样例以及一些小样例进行测试,同时尽可能提高代码覆盖率。
9.1 手工样例测试
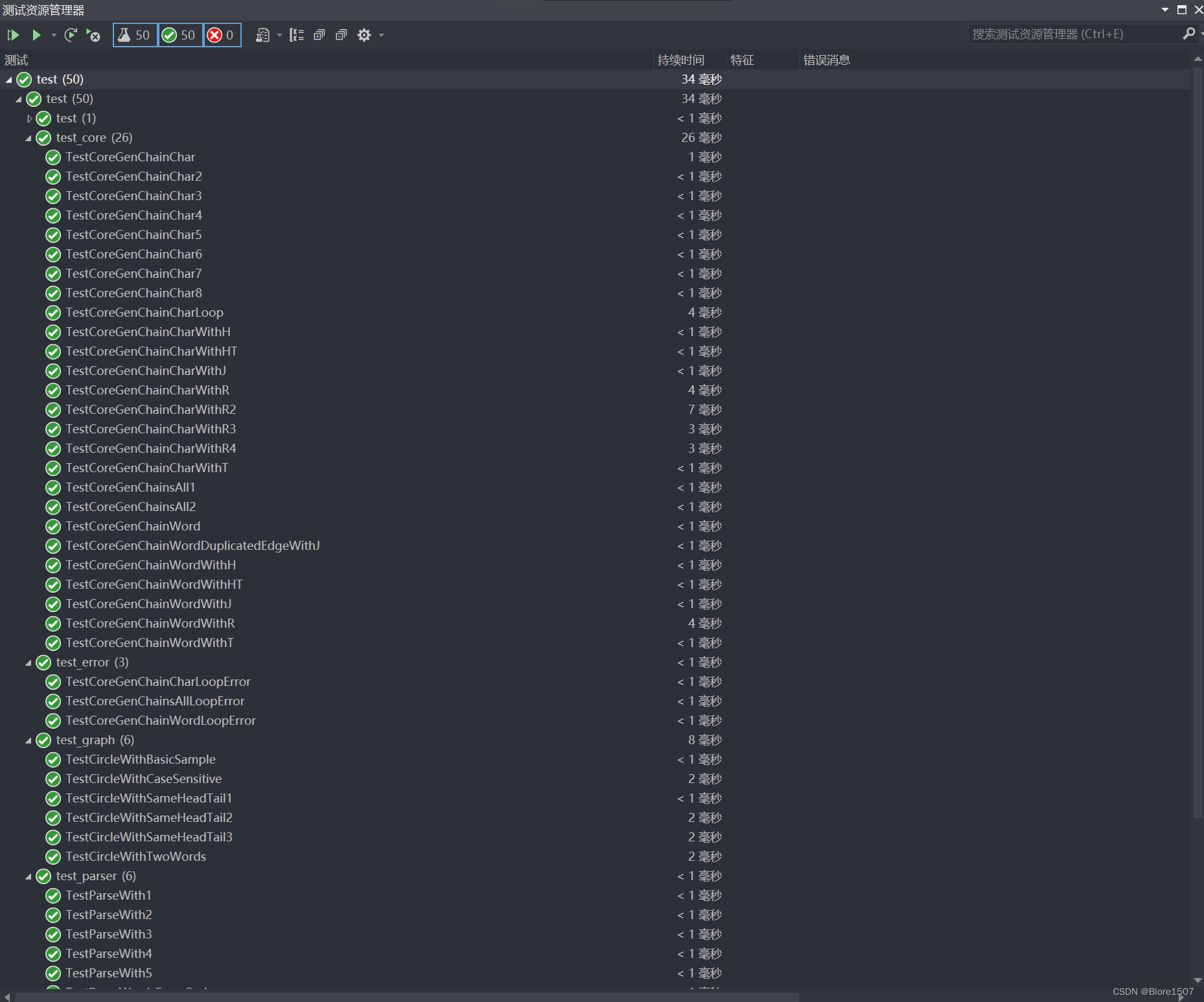
自己构造的简单样例,主要进行各个重要模块的覆盖率和正确性测试。构造了50个左右的单元测试用例。
如图所示:
所测出的代码覆盖率如下(注:我们单元测试覆盖了大部分的代码,由于main.cpp和output.cpp文件没有进行单元测试,因此也没有它们的覆盖率信息):
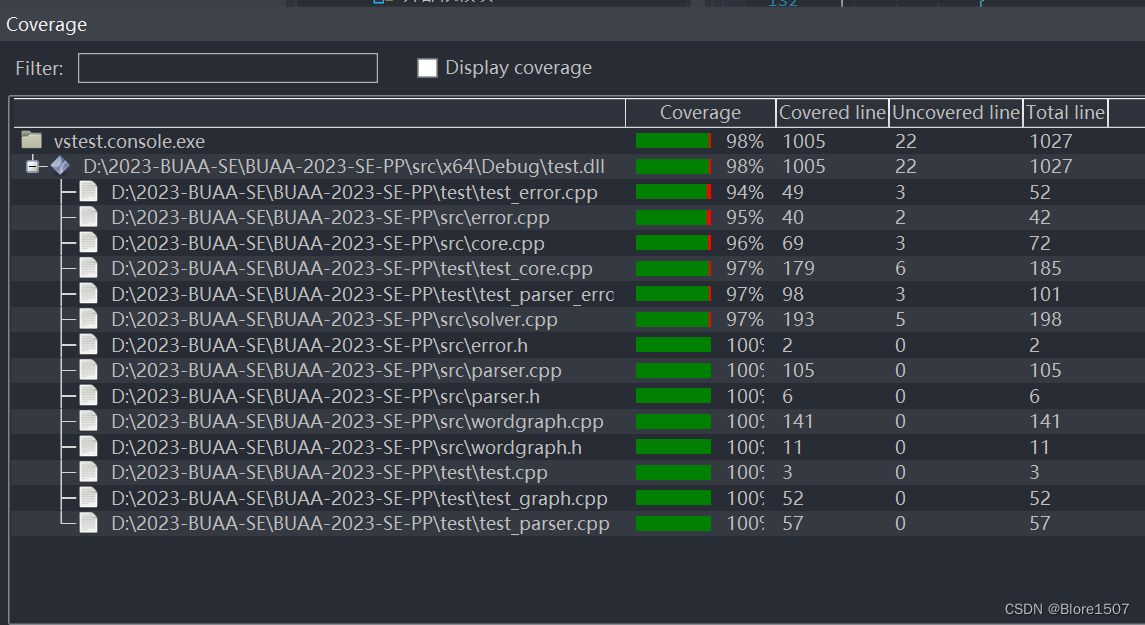
对于部分还未满100%覆盖率的文件。有以下几个原因:1. 防御性编程,有少数几处进行了此操作。在极限边界条件下会出现,单元测试不好进行。2. 部分异常抛出函数会进行抛出异常退出,从而导致之后的一行右大括号}没有覆盖到。
各个单元测试分别如下:
-
test_core: 测试core模块的三个重要函数的功能。这里以
gen_chain_word测试为例。首先定义一个
test_gen_chain_word方法。为测试gen_chain_word的接口,并和手动构造的数据的答案进行比对判断。void test_gen_chain_word(const char* words[], int len, const char* ans[], int ans_len, char head, char tail, char n_head, bool enable_loop) { char** result = (char**)malloc(10000); int out_len = gen_chain_word(words, len, result, head, tail, n_head, enable_loop); Assert::IsTrue(check_valid(result, out_len, head, tail, n_head, enable_loop)); Assert::AreEqual(ans_len, out_len); free(result); }通过手动构造可以得到如下的部分测试样例:
// '-w' TEST_METHOD(TestCoreGenChainWord) { const char* words[] = { "algebra", "apple", "zoo", "elephant", "under", "fox", "dog", "moon", "leaf", "trick", "pseudopseudohypoparathyroidism" }; const char* ans[] = { "algebra", "apple", "elephant", "trick" }; test_gen_chain_word(words, 11, ans, 4, 0, 0, 0, false); } // '-h' TEST_METHOD(TestCoreGenChainWordWithH) { const char* words[] = { "algebra", "apple", "zoo", "elephant", "under", "fox", "dog", "moon", "leaf", "trick", "pseudopseudohypoparathyroidism" }; const char* ans[] = { "elephant", "trick" }; test_gen_chain_word(words, 11, ans, 2, 'e', 0, 0, false); } // ... -
test_error:运行时异常处理的单元测试。测试样例部分如下:
// 有环 TEST_METHOD(TestCoreGenChainCharLoopError) { const char* words[] = { "element", "te", "eee", "ttt", "talk" }; const char* ans[] = { 0 }; try { test_gen_chain_char(words, 5, ans, 0, 0, 0, 'e', false); } catch (const std::exception&) { char* error = get_error_message(); Assert::AreEqual(strcmp(get_error_message(), "Ring Check Exception: there is a loop in words"), 0); } } // 无环 TEST_METHOD(TestCoreGenChainWordLoopError) { const char* words[] = { "element", "te", "eee", "ttt", "talk" }; const char* ans[] = { 0 }; try { test_gen_chain_word(words, 5, ans, 0, 0, 0, 'e', false); } catch (const std::exception&) { char* error = get_error_message(); Assert::AreEqual(strcmp(get_error_message(), "Ring Check Exception: there is a loop in words"), 0); } } -
test_graph:数据结构(图)的核心函数的单元测试模块。测试样例部分如下:
// 含环测试 TEST_METHOD(TestCircleWithTwoWords) { std::vector<std::string> words = { "ab", "ba" }; Config c; c.enable_loop = true; c.type = 'n'; WordGraph g(words, c); Assert::AreEqual(g.contain_circle(), true); } // 自环测试 TEST_METHOD(TestCircleWithSameHeadTail1) { Config c; c.type = 'n'; std::vector<std::string> words = { "aa" }; WordGraph g(words, c); Assert::AreEqual(g.contain_circle(), false); } -
test_parser:Parser模块的单元测试。首先定义config检测函数:
void test_config(Config& config, char head, char tail, char n_head, char type, bool enable_loop) { Assert::AreEqual(config.head == head, true); Assert::AreEqual(config.tail == tail, true); Assert::AreEqual(config.n_head == n_head, true); Assert::AreEqual(config.type == type, true); Assert::AreEqual(config.enable_loop, enable_loop); }测试样例部分如下:
// -n TEST_METHOD(TestParseWith1) { Parser parser; int argc = 2; char* argv[] = { "-n", "stdin.txt" }; parser.parse(argc, argv); test_config(parser.get_config(), 0, 0, 0, 'n', false); } // -c -j TEST_METHOD(TestParseWith2) { Parser parser; int argc = 4; char* argv[] = { "-c", "stdin.txt", "-j", "h"}; parser.parse(argc, argv); test_config(parser.get_config(), 0, 0, 'h', 'c', false); } -
test_parser_error:Parser异常单元测试// 缺少参数异常 TEST_METHOD(TestMissingArgument) { Parser parser; int argc = 0; char* argv[] = { "" }; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Missing Argument: no valid argument"), 0); } } // ...详见 Part 10
9.2 对拍测试
数据生成器
用python进行数据生成:
首先是用xml实现每个数据点配置文件,方便不同数据点进行定制化并保证数据点的可复现性。其中,seed是每次生成的种子数,word-num是总单词数,max-word-length是单词最长长度,special是生成环相关配置
<?xml version="1.0" ?>
<root>
<config id="1">
<seed>597873</seed>
<word-num>10000</word-num>
<max-word-length>100</max-word-length>
<special>nr</special>
</config>
</root>
生成图算法上,无环图利用了拓扑序进行生成,有环图则随机生成。无环图中强制加入了自环来提高数据强度
num_node = 26 # 设置图中节点数量
def get_no_loop_edges(edge_num): # 生成DAG,存入以c命名的文件内
node = list(range(num_node)) # 将格式转换成list,便于下一步随机重排
random.shuffle(node) # 随机重排
edges = []
for i in range(edge_num):
p1 = random.randint(0, num_node - 2) # 选择第一个节点
p2 = random.randint(p1 + 1, num_node - 1) # 选择第二个节点,这个节点的拓扑序必须大于第一个节点
edges.append((node[p1], node[p2]))
return edges
def get_random_edges(edge_num):
edges = []
for i in range(edge_num):
p1 = random.randint(0, num_node - 1) # 选择第一个节点
p2 = random.randint(0, num_node - 1) # 选择第二个节点
edges.append((p1, p2))
return edges
def get_one_word(config, head, tail):
word = shuffle_upper_or_lower(head)
length = random.randint(int(config['max-word-length']) * 2 // 3, int(config['max-word-length']))
for _ in range(length - 2):
word += shuffle_upper_or_lower(random.randint(0, 25))
word += shuffle_upper_or_lower(tail)
return word
def get_one_test_point(config):
random.seed(int(config['seed']))
result = ''
if config['special'] == 'nr':
edges = get_no_loop_edges(int(config['word-num']))
for edge in edges:
result += get_one_word(config, edge[0], edge[1]) + '\n'
# 添加自环
for i in range(26):
result += get_one_word(config, i, i) + '\n'
elif config['special'] == 'r':
edges = get_random_edges(int(config['word-num']))
for edge in edges:
result += get_one_word(config, edge[0], edge[1]) + get_splitter()
else:
raise ValueError('Unknown Special {}'.format(config['special']))
return result
正确性判断
由于结果顺序可能不同,所以只加入了合法性判断(和单元测试实现相同),之后比较长度进行对拍
def check_format(input_list, o_type=None, head=None, tail=None, n_head=None, enable_loop=False):
if len(input_list) == 0:
return 0
if head is not None and input_list[0][0] != head:
raise ValueError('错误的首字母')
if tail is not None and input_list[-1][-1] != tail:
raise ValueError('错误的尾字母')
pre_tail = input_list[0][0]
length = 0
self_loop_count = [0 for _ in range(26)]
vis = [0 for _ in range(26)]
for i in input_list:
if pre_tail != i[0]:
raise ValueError('首尾不相连')
if n_head is not None and i[0] != n_head:
raise ValueError('不允许的首字母')
pre_tail = i[-1]
if o_type == 'w':
length += len(i)
elif o_type == 'c':
length += 1
if i[0] == i[-1]:
self_loop_count[get_id_from_alpha(i[-1])] += 1
else:
vis[get_id_from_alpha(i[-1])] += 1
if not enable_loop:
for i in vis:
if i >= 2:
raise ValueError('环')
for i in self_loop_count:
if i >= 2:
raise ValueError('两个自环')
return length
def compare_file(file1, file2):
input1 = []
with open(file1, "r") as f1:
input1 = f1.read().splitlines()
input2 = []
with open(file2, "r") as f2:
input2 = f2.read().splitlines()
input2 = input2[1:]
len1 = check_format(input1, 'c')
len2 = check_format(input2, 'c')
if len1 != len2:
raise ValueError('不相等')
自动化
直接用 os 模块调用 Wordlist.exe,用 time 模块记录时间,用 func-timeout 进行超时判断(300s)
10 计算模块部分异常处理说明
我们总共定义了两种异常大类,利用了std的logic_error和自己定义的继承于std的exception。大致分别区分解析处理异常和运行时异常。
10.1 解析处理异常
-
Conflicted Arguemnt:参数冲突// -r -r 冲突 TEST_METHOD(TestConflictedArgumentWithR) { Parser parser; int argc = 2; char* argv[] = { "-r", "-r" }; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Conflicted Argument: -r"), 0); } } // -n -r 冲突 TEST_METHOD(TestConflictedArgumentWithNR) { Parser parser; int argc = 3; char* argv[] = { "-n", ".txt", "-r"}; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Conflicted Argument: -n"), 0); } } -
Missing Argument:缺失参数// 没有参数 TEST_METHOD(TestMissingArgument) { Parser parser; int argc = 0; char* argv[] = { "" }; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Missing Argument: no valid argument"), 0); } } -
Invalid Argument:不合法参数// -h 后的参数不合法 TEST_METHOD(TestInvalidArgument) { Parser parser; int argc = 2; char* argv[] = { "-h", "aa"}; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Invalid Argument: please give a single alpha instead of aa"), 0); } } -
Invalid File:文件不合法// .png文件不合法 TEST_METHOD(TestInvalidFile) { Parser parser; int argc = 2; char* argv[] = { "-w", "ss.png" }; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Invalid File: you need end with .txt"), 0); } } -
Unexpected Argument:无法识别参数// -l 是无法识别的参数 TEST_METHOD(TestUnexpectedArgument) { Parser parser; int argc = 1; char* argv[] = { "-l" }; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Unexpected Argument: -l"), 0); } }
10.2 运行时异常
-
Missing File:缺少文件或读取不了文件异常// 当前目录下没有.txt文件,或者没有权限读取.txt文件 TEST_METHOD(TestMissingFile) { Parser parser; int argc = 2; char* argv[] = { "-w", ".txt"}; try { parser.parse(argc, argv); } catch (const std::exception& e) { Assert::AreEqual(strcmp(e.what(), "Missing File: input file cannot open"), 0); } } -
Ring Check Exception:成环异常// 成环且没有-r参数 TEST_METHOD(TestCoreGenChainCharLoopError) { const char* words[] = { "element", "te", "eee", "ttt", "talk" }; const char* ans[] = { 0 }; try { test_gen_chain_char(words, 5, ans, 0, 0, 0, 'e', false); } catch (const std::exception&) { char* error = get_error_message(); Assert::AreEqual(strcmp(get_error_message(), "Ring Check Exception: there is a loop in words"), 0); } } -
Too Much Result:结果超20000条异常// 结果太长,超2w条 TEST_METHOD(TestTooMuchResult) { const char* words[] = { "ab", "abb", "abbb", "bc", "bcc", "bccc", "cd", "cdd", "cddd", "de", "dee", "deee", "ef", "eff", "efff", "fg", "fgg", "fggg", "gh", "ghh", "ghhh", "hi", "hii", "hiii", "ij", "ijj", "ijjj", "jk", "jkk", "jkkk" }; const char* ans[] = { 0 }; try { test_gen_chains_all(words, 30, ans, 0); } catch (const std::exception&) { char* error = get_error_message(); Assert::AreEqual(strcmp(get_error_message(), "Too Much Result: 132813"), 0); } }
11 界面模块的详细设计过程
11.1 GUI所用技术
我们构建GUI版本应用所使用的编程语言为Python,使用的包如下:
PyQt5-Qt5 5.15.4PyQt5-sip 12.11.0PyQt5-stubs 5.15.6.0
打包所用的插件为pyinstaller。
11.2 设计风格
我们使用的是qdarkstyle作为GUI的主题。
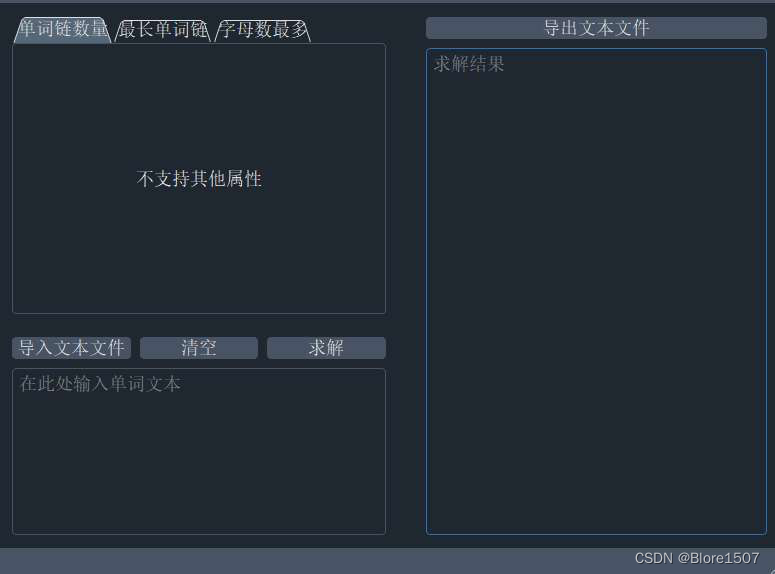
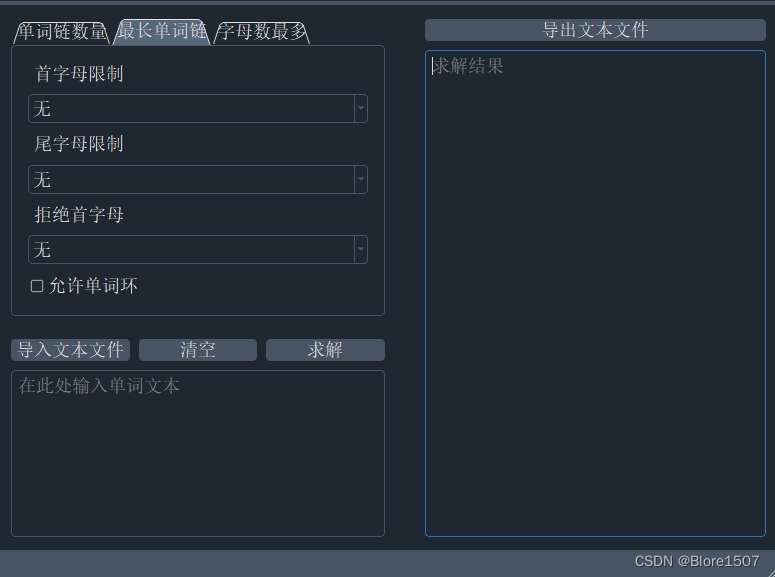
-
控制板块:左上方为控制板块。其提供三种模式的对应。
- 单词链数量:“-n”
- 最长单词链:“-w”
- 字母数最多:“-c”
其中,-n不支持其他参数,-w和-c支持其他4种参数限制,提供给用户的输入全部为选择,因此不会有控制模块的异常读入。
-
输入板块:左下方为输入板块。并提供了三个按钮,分别对应了三个功能。
-
输出板块:右方为输出板块。并提供了导出文件的按钮。
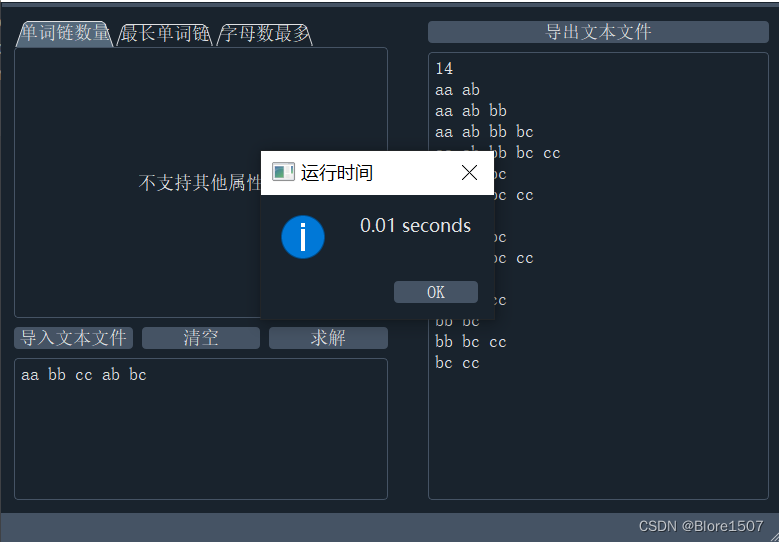
-
运行时间窗口:每次正确求解后都会弹出运行时间窗口。
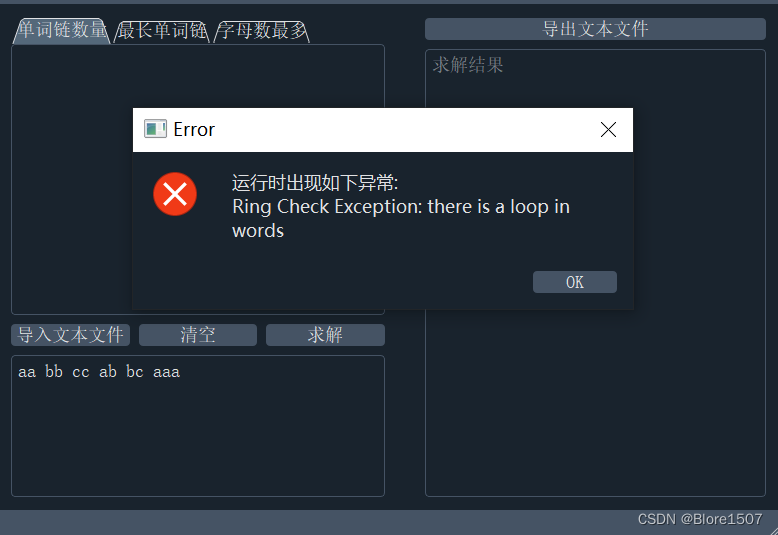
- 运行异常窗口:每次求解时出现异常都会弹出异常窗口,并得到相关异常信息。
11.3 代码设计
-
UI部分。我们采用QtDesigner的图形化设计界面得到ui的部分代码。生成如下:
# Form implementation generated from reading ui file 'main.ui' # # Created by: PyQt5 UI code generator 5.15.4 # # WARNING: Any manual changes made to this file will be lost when pyuic5 is # run again. Do not edit this file unless you know what you are doing. from PyQt5 import QtCore, QtGui, QtWidgets class Ui_MainWindow(object): def setupUi(self, MainWindow): MainWindow.setObjectName("MainWindow") MainWindow.resize(781, 540) MainWindow.setMinimumSize(QtCore.QSize(781, 540)) MainWindow.setMaximumSize(QtCore.QSize(915, 672)) self.centralwidget = QtWidgets.QWidget(MainWindow) self.centralwidget.setObjectName("centralwidget") self.gridLayout = QtWidgets.QGridLayout(self.centralwidget) self.gridLayout.setObjectName("gridLayout") # ... # ...控制模块采用
QTabWidget搭建,输入输出模块采用QPushButton和QTextEdit组建搭建。整体布局采用栅格布局,同时辅以部分区域的QVBoxLayout和QHBoxLayout,并采用Spacer支持拉伸。 -
读入dll库:采用python自带的ctypes库进行处理。
from ctypes import cdll, c_char_p, c_int, c_char, c_bool try: core_dll = cdll.LoadLibrary(".\\dll\\core.dll") except Exception as e: msgBox = QMessageBox() msgBox.setIcon(QMessageBox.Critical) msgBox.setText(f'运行时出现如下异常: {e}') msgBox.setWindowTitle('Error') msgBox.exec_() -
单词读入函数:支持从输入框中读入文本,并解析成单词形式。(注:这一部分只提取出单词,没有进行预处理。对于单词的处理在core模块中完成。)
def read_words(input_text): result = [] word = "" for c in input_text: if c.isalpha(): word += c elif word != "": result.append(word) word = "" if word != "": result.append(word) return result -
核心界面类
MainWindow:class MainWindow(QMainWindow, Ui_MainWindow): def __init__(self, parent=None): super(MainWindow, self).__init__(parent) self.setupUi(self) self.import_txt_button.clicked.connect(self.import_txt) self.clear_button.clicked.connect(self.clear) self.solve_button.clicked.connect(self.solve) self.export_txt_button.clicked.connect(self.export_txt)以上是构造函数。继承自
QMainWindow和Ui_MainWindow。通过调用setupUi方法设置相关ui。各个按钮与事件函数进行链接
connect。-
import_txt函数的目的是从文件管理器中导入txt数据,export_txt为导出txt文件。def import_txt(self): file_dialog = QFileDialog() file_name, _ = file_dialog.getOpenFileName(None, "Select File", "", "Text Files(*.txt)") if file_name: with open(file_name, 'r') as file: self.input_text.setText(file.read()) return def export_txt(self): file_dialog = QFileDialog() file_name, _ = file_dialog.getSaveFileName(None, "Save File", "", "Text Files(*.txt)") if file_name: with open(file_name, "w") as file: file.write(self.output_text.toPlainText()) return -
clear函数的目的是同时清空输入和输出。def clear(self): self.input_text.clear() self.output_text.clear() return -
solve函数为核心函数。def solve(self): # 预处理+转换成cpp的type success = True start_time = time.time() index = self.tabWidget.currentIndex() words = read_words(self.input_text.toPlainText()) len_w = len(words) c_words = (c_char_p * len_w)() for i in range(len_w): c_words[i] = words[i].encode('utf-8') c_len = c_int(len(words)) result = (c_char_p * 20000)() # -n处理 if index == 0: ans = 0 try: ans = core_dll.gen_chains_all(c_words, c_len, result) except Exception as e: # ... # 弹出异常框 results = [result[i].decode('utf-8') for i in range(ans)] # ... # 设置输出 # -w处理 else if index == 1: h = self.w_h_box.currentText() # ... # 预处理 try: ans = core_dll.gen_chain_word(c_words, c_len, result, c_h, c_t, c_n_h, c_r) except Exception as e: # ... # 弹出异常框 results = [result[i].decode('utf-8') for i in range(ans)] # ... # 设置输出 # -c处理 elif index == 2: h = self.c_h_box.currentText() # ... # 预处理 try: ans = core_dll.gen_chain_char(c_words, c_len, result, c_h, c_t, c_n_h, c_r) except Exception as e: # ... # 弹出异常框 results = [result[i].decode('utf-8') for i in range(ans)] # ... # 设置输出 # 记录时间并弹出窗口 run_time = time.time() - start_time if success: QMessageBox.information(None, "运行时间", f"{run_time:.2f} seconds") return
-
-
主程序:
if __name__ == "__main__": app = QApplication(sys.argv) app.setStyleSheet(qdarkstyle.load_stylesheet_pyqt5()) app.setStyleSheet(qdarkstyle.load_stylesheet(qt_api='pyqt5')) w = MainWindow() w.setWindowTitle('单词链统计') w.show() sys.exit(app.exec())
12 界面模块与计算模块的对接
12.1 前后端对接
通过采用python自带的ctypes库导入dll库,并直接使用dll库的函数。
导入dll库的代码为:
from ctypes import cdll, c_char_p, c_int, c_char, c_bool
try:
core_dll = cdll.LoadLibrary(".\\dll\\core.dll")
except Exception as e:
msgBox = QMessageBox()
msgBox.setIcon(QMessageBox.Critical)
msgBox.setText(f'运行时出现如下异常: {e}')
msgBox.setWindowTitle('Error')
msgBox.exec_()
函数直接调用即可。
如:ans = core_dll.gen_chains_all(c_words, c_len, result)
我们通过visual studio 2019导出dll。相关的导出模块定义如下:
LIBRARY Wordlist
EXPORTS
gen_chains_all
gen_chain_word
gen_chain_char
get_error_message
对应的接口函数:
int gen_chains_all(const char* words[], int len, char* result[]);
int gen_chain_word(const char* words[], int len, char* result[], char head, char tail, char n_head, bool enable_loop);
int gen_chain_char(const char* words[], int len, char* result[], char head, char tail, char n_head, bool enable_loop);
char* get_error_message();
12.2 松耦合实践:模块对调与对接
第一组对接
我们与20373737和20373965小组进行了core.dll的交换。
他们的GUI运行我们dll的截图如下:
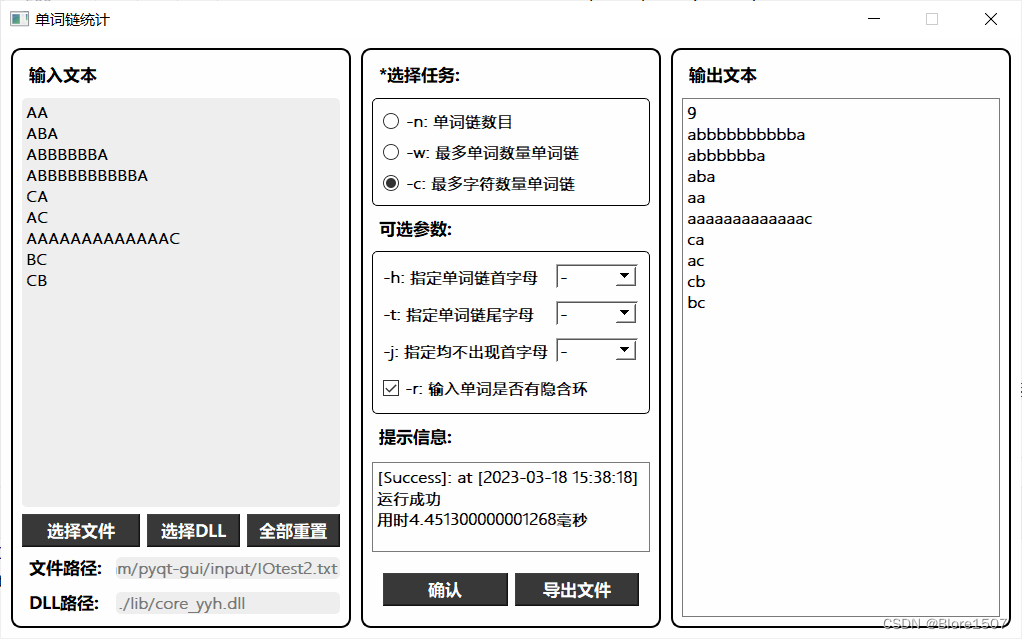
- 问题:参数类型不匹配
- 由于我们都使用了课程组提供的接口函数,因此整体上没有问题。
- 出现问题的是对于没有-h参数时的处理。我们的程序当没有—h时传入参数必须为0,而他们的GUI模块当无-h参数时传入的是’-'。
- 问题:异常处理手段不一致
- 我们是throw异常
- 他们是将异常写入results,在GUI中进行判断
第二组对接
同时,我们也与20373673和20373363小组进行了core.dll的交换。
他们的GUI运行我们的dll的截图如下:
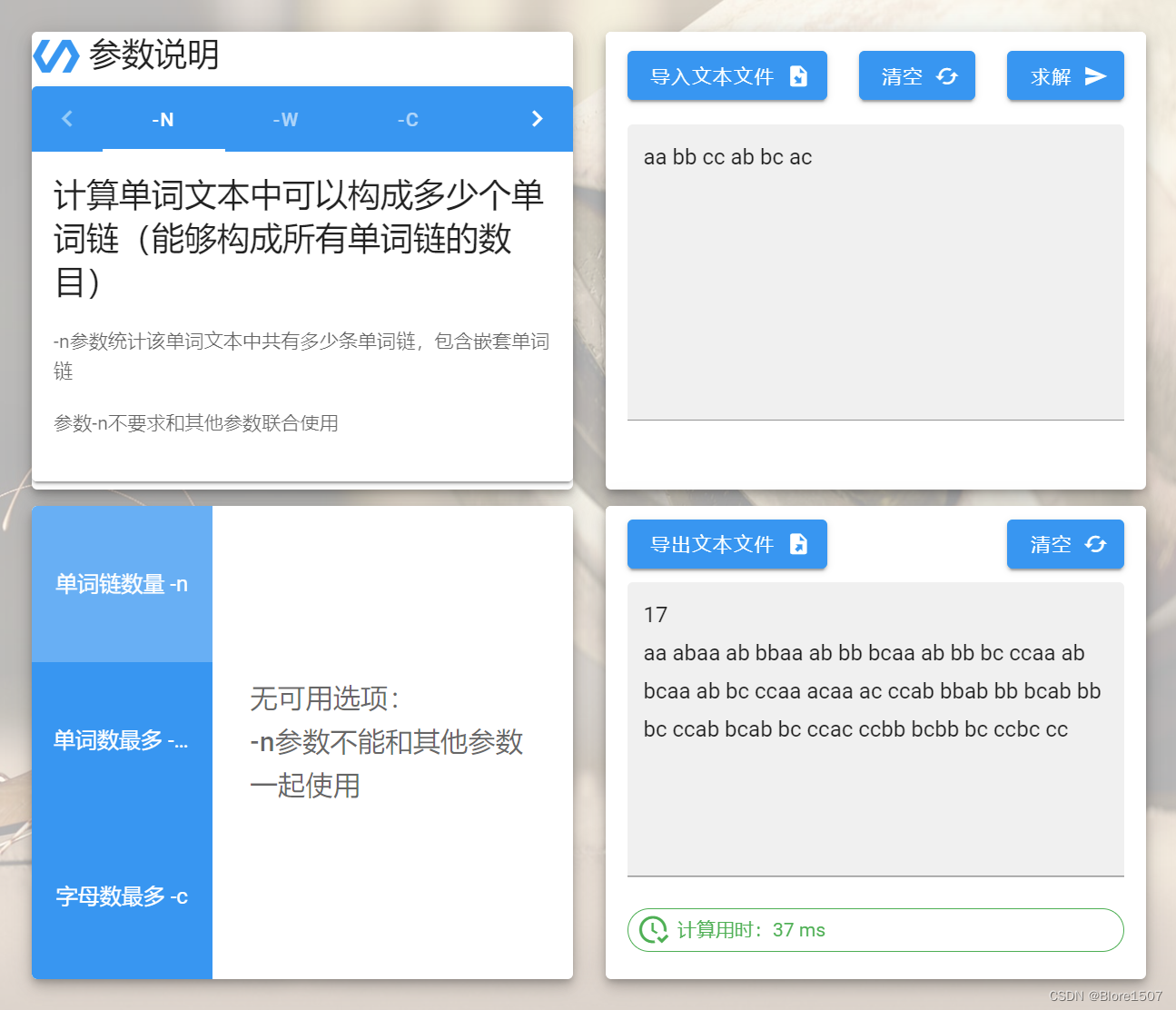
-
问题:接口不一致导致的问题
他们采用将三种策略统一成的单个接口,与我们的接口不同,因此不太好对接。
const char* vuetifyAPI(const char* input, int type, char head, char tail, char reject, bool weighted)
13 描述结对的过程
CoolColoury和我一般在新主楼H10 Wings进行协作,那里的抹茶拿铁很好喝(赞)。在3.7敲定了开发计划后,实际时间上分配如表。整体上采用了TDD开发,主要是为了松耦合和模块正确性保证(不过我们两人时间都不是很充裕,所以有几天的进度非常有限)
在第一周我们的开发是非常顺利的,在第一周周末就完成了几乎包含GUI代码的编写以及部分单元测试。但是第二周性能优化的学习以及构建单元测试+集成测试耗费大量了精力(测试真的是一个需要耐心的活)。编写测试代码的时间可能是编写功能代码的时间两倍之多,相比之下可能我们投入到性能优化上的精力很少。
| 时间 | 工作 |
|---|---|
| 3.7 | 接口规约 + 10个测试点 + 环境配置 |
| 3.8 | 单元测试 + 初步代码 |
| 3.9 | 初步代码 + 压力测试 (初步完成需求1)+ debug |
| 3.10 | GUI |
| 3.11 | 性能优化 + 单元测试 |
| 3.12 | 性能优化 |
| 3.13 | 进一步设计文档+部分测试+异常 |
| 3.14 | 性能测试+性能优化,完成多线程编写 |
| 3.15 | BUG修复 |
| 3.16 | 完成异常部分单元测试,覆盖率达到97%+ |
| 3.17 | 对接+重构小部分代码 |
| 3.18 | 对拍测试+博客共同部分 |
| 3.19 | 博客单人部分+测试 |
结对第一天:

第一周结束出去干饭:

结对最后一天:

14 结对编程的优点和缺点
优点:(1)保证代码质量。在代码编写时就完成代码复审,极大减少了出错后修正错误的代价,出错后修正缺陷的时间大大减少(2)可以保持相对积极的心态,遇到问题时和伙伴一起解决相对自己独立解决心态上能更加平和(3)略微提高编码效率,在伙伴的push下进行编码,防止懈怠。
缺点:在两人一人熟悉一人不熟悉的问题上效率不如分开编写,在一个短期项目中去让不熟悉的人去学习时间开销太大。(例如在我们的编码中实际上GUI部分完全是CoolColoury开发的,我则更多的精力投入到研究性能优化和测试上)
Blore
优点:对相关算法比较熟悉,做过测试相关工作
缺点:不熟悉工程开发,不熟悉GUI
CoolColoury
优点:熟悉GUI开发,工程构建能力强,性格随和,和我有共同爱好(最重要的一点)
缺点:对一些算法不是很熟
15 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 25 |
| Development | 开发 | 1570 | 1860 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 20 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 100 | 120 |
| · Coding | · 具体编码 | 1000 | 700 |
| · Code Review | · 代码复审 | 120 | 200 |
| · Test | · 测试 (自我测试,修改代码,提交修改) | 300 | 600 |
| Reporting | 报告 | 250 | 420 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 200 | 300 |
| 合计 | 2035 | 2305 |















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









