






目录
1.什么是文件
通常我们所说的文件是指存储在计算机硬盘或其他存储介质上的数据单元,这些数据单元可能包含文本、图像、音频、视频等各种形式的信息。这些文件通常被分为两类:文本文件和二进制文件。
-
文本文件:文本文件是由字符组成的文件,每个字符都可以在对应的字符编码表中找到对应的表示。常见的文本文件格式包括 .txt(纯文本文件)、.csv(逗号分隔值文件)、.html(网页文件)等。这些文件可以使用文本编辑器(如记事本)打开并查看内容,通常不会出现乱码。
-
二进制文件:二进制文件包含的数据并不是以字符的形式存储的,而是以二进制编码的形式表示。这类文件包括图像文件(如 .jpg、.png)、音频文件(如 .mp3、.wav)、视频文件(如 .mp4、.avi)、可执行文件(如 .exe、.dll)等。这些文件通常无法直接用文本编辑器打开查看,并且在打开时可能会显示乱码或无法识别的内容。
1.1 文件的概念
但是在计算机中,“文件”是一个广义的概念概念,不仅可以指存储在计算机硬盘或其他存储介质上的文本文件和二进制文件,还可以指计算机硬盘或其他存储介质上的目录(即日常中所说的文件夹)。但是不特意强调的话,一般说文件还是指文本文件和二进制文件。
计算机中的常用存储设备:
| 设备名 | 读写速度 | 存储容量 | 价格 | 断电是否丢失 |
|---|---|---|---|---|
| CPU(寄存器,缓存) | 最快 | 最小 | 最贵 | 丢失 |
| 内存(RAM) | 其次 | 其次 | 其次 | 丢失 |
| 硬盘 | 最慢 | 最大 | 最便宜 | 不丢失 |
文件是保存在硬盘上的但是因为CPU和硬盘之间的读写速度相差太大,于是就引入了个介于两者之间,比硬盘读写速度快很多的内存。
当我们操作文件的时候,会先将数据读入到内存中,然后CPU直接读取内存中的数据进行操作,就会快很多。修改完的数据再从内存保存到硬盘中。
我们打开文件夹相当于hash表查找是o(1)的复杂度,可以直接找到指定位置的数据,而不需要遍历。
1.2 文件位置的描述
操作系统通过文件系统对于存储设备等硬件进行封装,使用N叉树来组织文件,每个普通文件就是叶子节点,每个目录就是子节点。目录实际上就是一种树形结构。
操作系统用“路径”这个概念来描述文件的位置。比如:
G:\others\aaa.txt
操作系统将不同级的目录用\来进行划分,从根目录,一级一级向下走,直到到达目标文件,中间走过的目录名加上划分,就构成了“路径”。(tips: Windows支持\和/来对目录进行划分,Linux只支持/对目录进行划分)
路径从不同的角度来看,分为两种路径:
-
绝对路径,指从N叉树的根节点到目标文件中间的路径。
-
相对路径,指定一个工作“当前目录”/“工作目录”/“基准目录”,从当前目录出发找到目标文件之间的路径。
2.java对于文件系统/文件内容的操作
java中对于文件(此处仅指存储在硬盘的文件)操作的api分为了两类:
-
针对文件系统的操作,比如文件的创建与删除,文件的重命名,文件目录的创建与删除等等。对文件系统的操作在java.io.File中。(其中io指input(输入)和output(输出),是站在CPU的角度来看的,数据从硬盘到CPU叫输入,从CPU到硬盘叫输出)
-
针对文件内容的操作,读和写文件。
2.1 java操作文件系统
java对于文件系统操作,需要先实例化一个File类对象,可以传入相对路径,也可以传入绝对路径。还能传其他参数例如uri,来进行初始化,感兴趣的可以去研究一下。以下是一些常用方法的使用:
package io;
import java.io.File;
import java.io.IOException;
public class IODemo1 {
public static void main(String[] args) throws IOException {
//传入文件的绝对路径,Windows中以硬盘的盘符为根节点,分割符用反斜杠,因为反斜杠表示转义字符,所以使用的时候
//需要将转义字符转义为反斜杠,表示一个反斜杠就需要连续写两个反斜杠
File f = new File("G:\\java\\J2024_3_30FileIO\\aaa.txt");
//传入文件的绝对路径,分隔符用正斜杠
File f1 = new File("G:/java/J2024_3_30FileIO/aaa.txt");
//传入文件的相对路径
File f2 = new File("./aaa.txt");
//判断文件是否存在
boolean f_exist = f.exists();
System.out.println("f_exist" + " :" + f_exist );
boolean f1_exist = f1.exists();
System.out.println("f1_exist" + " :" + f1_exist );
boolean f2_exist = f2.exists();
System.out.println("f2_exist" + " :" + f2_exist );
System.out.println("f1.getParent()" + " :" + f1.getParent());
System.out.println("f2.getParent()" + " :" + f2.getParent());
//获取文件名
System.out.println("f1.getName()" + " :" + f1.getName());
System.out.println("f2.getName()" + " :" + f2.getName());
//获取打开文件的相对路径
System.out.println("f1.getPath()" + " :" + f1.getPath());
System.out.println("f2.getPath()" + " :" + f2.getPath());
//获取打开文件的绝对路径
System.out.println("f1.getAbsolutePath()" + " :" + f1.getAbsolutePath());
System.out.println("f2.getAbsolutePath()" + " :" + f2.getAbsolutePath());
//获取打开文件的规范路径
System.out.println("f1.getCanonicalPath()" + " :" + f1.getCanonicalPath());
System.out.println("f2.getCanonicalPath()" + " :" + f2.getCanonicalPath());
}
}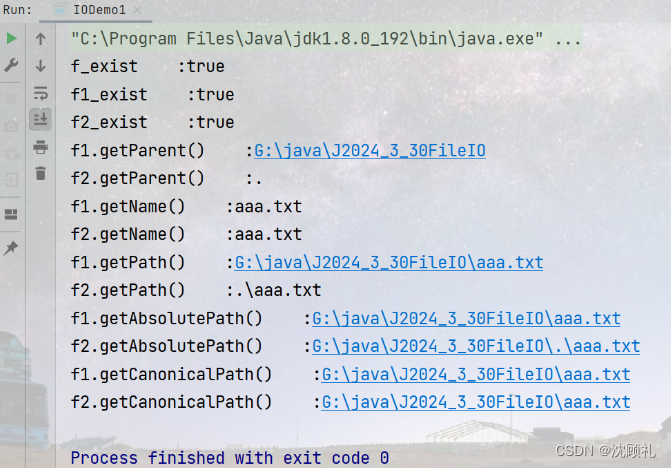
通过上面的代码,很容易知道这些方法是用来干什么的,这里就来把细节部分说一说。
-
getParent(),getPath(),getAbsolutePath(),getCanonicalPath() 等获取文件路径的方法,都是基于你new一个File对象时传入的路径,就算你随便乱写一个根本不存在的路径,这些方法也能输出结果。获取路径的方法并不会自己判断,文件是否真的存在,需要自己写程序的时候,手动判断处理。
-
getPath()获取相对路径,只能正确获取在当前项目文件夹下的文件路径。
-
实例化File类时传入相对路径,“ .\aaa.txt” 中的"."表示当前工作目录下,而“..\aaa.txt”表示在当前工作目录的上一级目录下。
-
当实例化File类时传入的是相对路径时,getAbsolutePath(),getCanonicalPath()就有了区别,getAbsolutePath:返回的是文件所在目录的路径+构造时的参数 ,getCanonicalPath:返回的就是这个文件存储的绝对路径,getCanonicalPath()作为规范,确保无论什么情况下,绝对路径只能有一种形式。
-
初始化时,如果传入的是相对路径。在idea中运行的时候,此时的工作目录就是项目所在的目录;将代码打包成单独的jar包时,此时工作目录就是jar所在的目录。
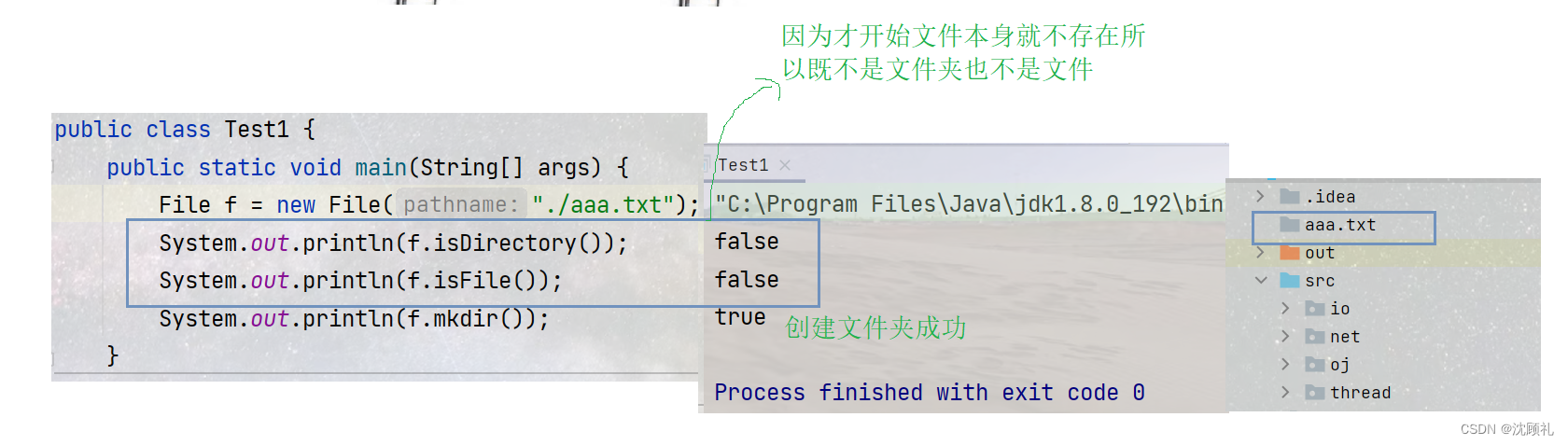
package io;
import java.io.File;
public class Test1 {
public static void main(String[] args) {
File f = new File("./aaa.txt");
System.out.println(f.isDirectory());
System.out.println(f.isFile());
System.out.println(f.mkdir());
}
}
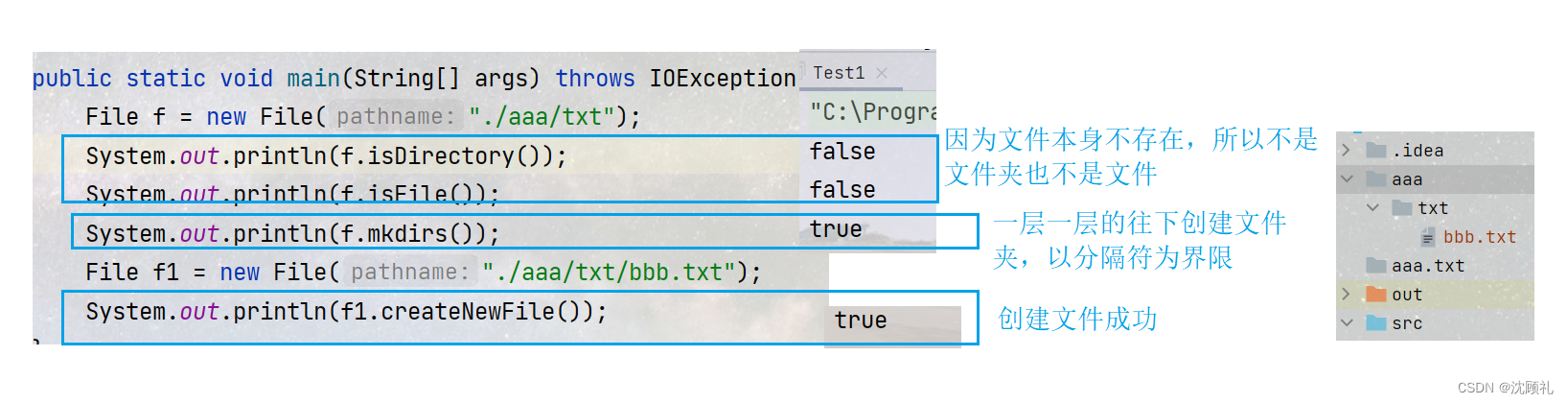
package io;
import java.io.File;
import java.io.IOException;
public class Test1 {
public static void main(String[] args) throws IOException {
File f = new File("./aaa/txt");
System.out.println(f.isDirectory());
System.out.println(f.isFile());
System.out.println(f.mkdirs());
File f1 = new File("./aaa/txt/bbb.txt");
System.out.println(f1.createNewFile());
}
}
public static void main(String[] args) {
File file = new File("./");
String[] files = file.list();
System.out.println(Arrays.toString(files));
}
file.list会得到当前路径下的文件夹的名字,并不会返回当前路径下文件夹的子文件夹名,也不会返回当前路径下的文件名。
public static void main(String[] args) {
File file = new File("./aaa/txt/bbb.txt");
File dest = new File("./aaa/bbb.txt");
boolean b = file.renameTo(dest);
System.out.println(b);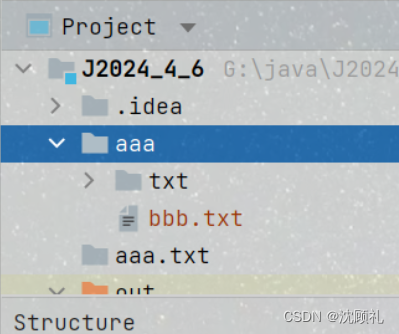
renameTo方法可以用来移动文件。和复制文件不同,如果在同一个硬盘上,移动文件的速度是很快的,时间复杂度是o(1)的,只是简单的重命名。
2.2 一些特殊文件
2.2.1 隐藏文件

有一些文件是看不到的,需要在勾选上“隐藏的项目”才能看,隐藏文件,通常用于存储用户的首个选项或保留一个应用程序的状态。被各种程序隐蔽的创建。
2.2.2 临时文件
临时文件其实也是隐藏文件,需要勾选上“隐藏的项目”才能看到。临时文件会在操作文件正常退出后才会被删除。它会给你实时编辑的内容进行保存,防止你文件还没保存呢,电脑突然断电了。
应用程序会将你正在编辑的内容写入临时文件中,临时文件是保存在硬盘中的,正在编辑的内容是在内存中的,如果你没保存就突然断电了,此时临时文件就不会被删除,后续可以借助这个临时文件来恢复之前未被保存的数据。也有一些应用程序是自动保存的。不担心突然断电的情况,比如飞书,idea等。

2.3 java操作文件内容
操作系统底层对于文件的输入输出是基于“流”进行的,java标准库对于“流”进行了一系列的封装,提供了一组类来针对文件内容进行输入输出,这两种类主要分为两大类:
2.3.1 字节流
以字节为单位进行读写操作,一次最少读写一个字节,代表类有InputStream(输入)和OutputStream(输出)。
读写文件内容主要就是四个步骤,打开文件,读文件,写文件,关闭文件。
InputStream
先介绍一下InputStream:
![]()
InputStream是一个抽象类,实现了Closeable接口。抽象类,代表这个类不能被实例化,但是可以被继承来在这个类的基础上做扩展。实现了Closeable接口,代表可以使用接口中的close方法来释放在内核中占用的相关资源。
public static void main(String[] args) throws IOException {
//打开文件,可以通过绝对路径,也可以通过相对路径
InputStream inputStream = new FileInputStream("./aaa/bbb.txt");
//执行其他的逻辑
inputStream.close();// 关闭文件
}打开文件时,如果文件不存在会抛出FileNotFoundException异常。每打开一个文件就会给这个文件分配一个文件描述符(file descriptor),本质上是一个非负整数,用来标识不同的打开文件。这些文件描述符会记录在文件描述符表中,文件描述符表是有限的,无限打开文件就会把文件描述符表占满,就不能打开其他的文件了。所以不再使用的文件的文件描述符表中删去,close方法就是来实现这个操作的。
但是有的时候,打开文件后执行的操作抛出了异常或者操作里面有return,程序无法执行到close方法,这样还是会占用文件描述符表的资源。我们可以通过try-finally或者try with resources来解决。
使用try-finally:
public static void main(String[] args) throws IOException {
InputStream inputStream = null;
try {
inputStream = new FileInputStream("./aaa/bbb.txt");//打开文件
// 其他逻辑
} finally {
inputStream.close();// 关闭文件
}
}使用try-with-resources:
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("./aaa/bbb.txt")) {
} catch (IOException e) {
e.printStackTrace();
}
}注意这里只有实现了Closeable接口的类才能放到try()里。当出了try的代码块后,try会自动调用inputStream的close方法。
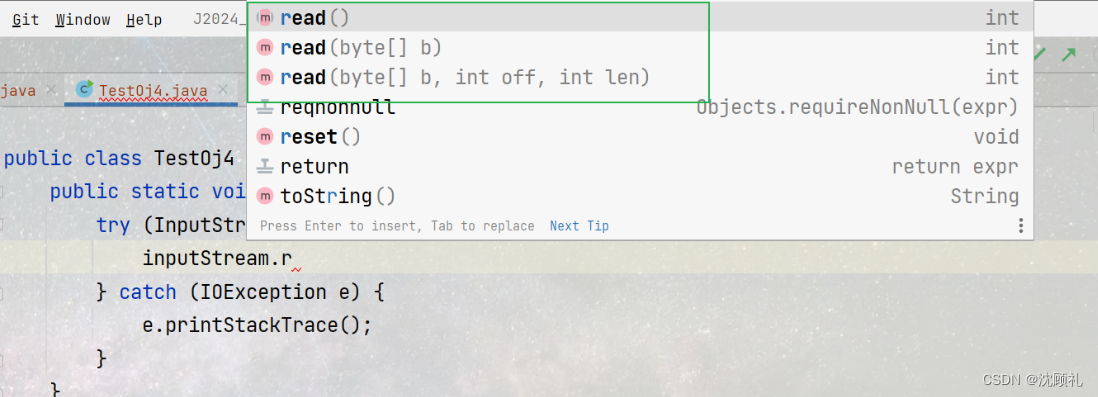
对文件内容进行读操作,是通过inputStream对象的read方法进行的,read方法三个版本。
无参版本的read每次调用读取一个字节,返回值就会表示读取到的这个字节的值,如果读取到文件末尾了(读的时候就没数据了)会返回-1。一个字节实际上能表示的值的范围是0-255,所以虽然返回的是int类型,但实际上返回的值在0-255这个区间里(不算特殊情况)
read(byte[] b) 版本,是要提供一个内容为空的字节数组(就是该数组的数据都是默认的值)给read方法,读到的数据就从从第一个数组元素开始按字节往后面填充。返回的int表示实际读取的字节个数。
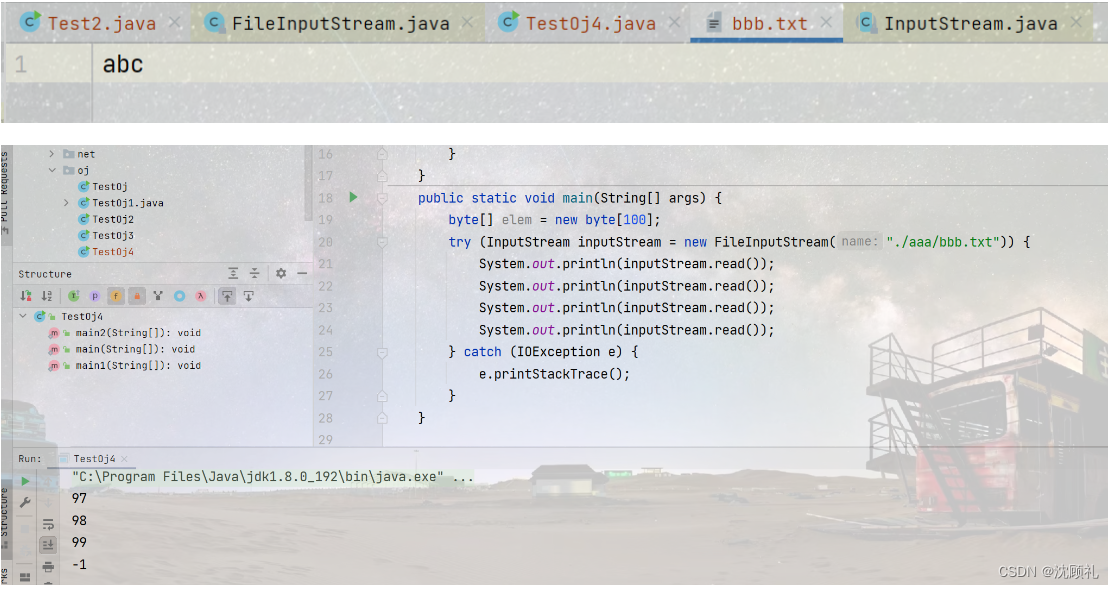
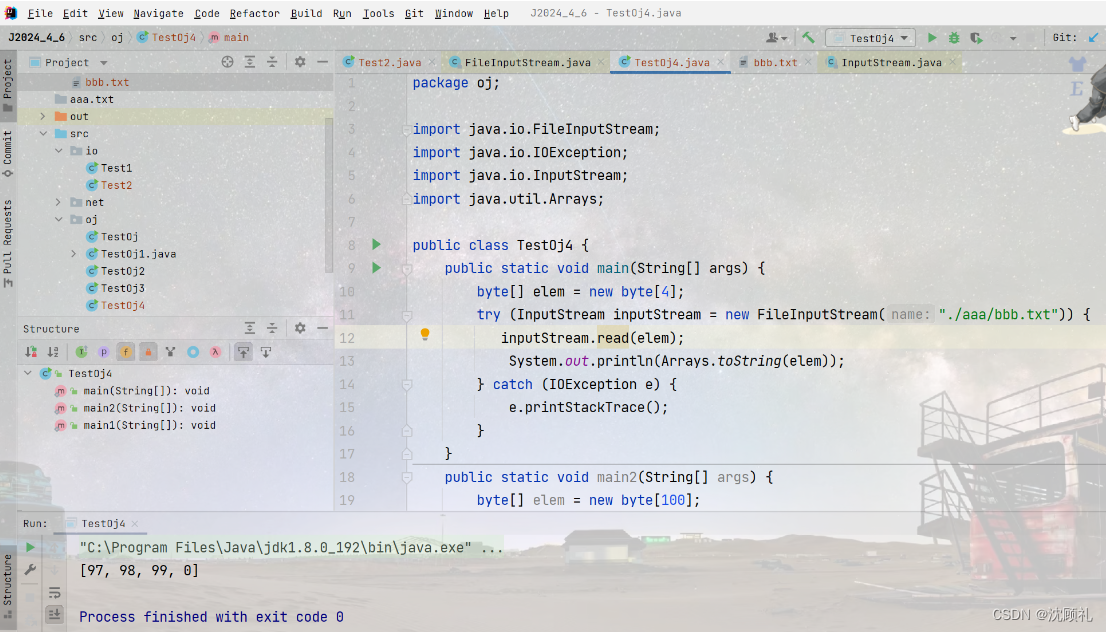
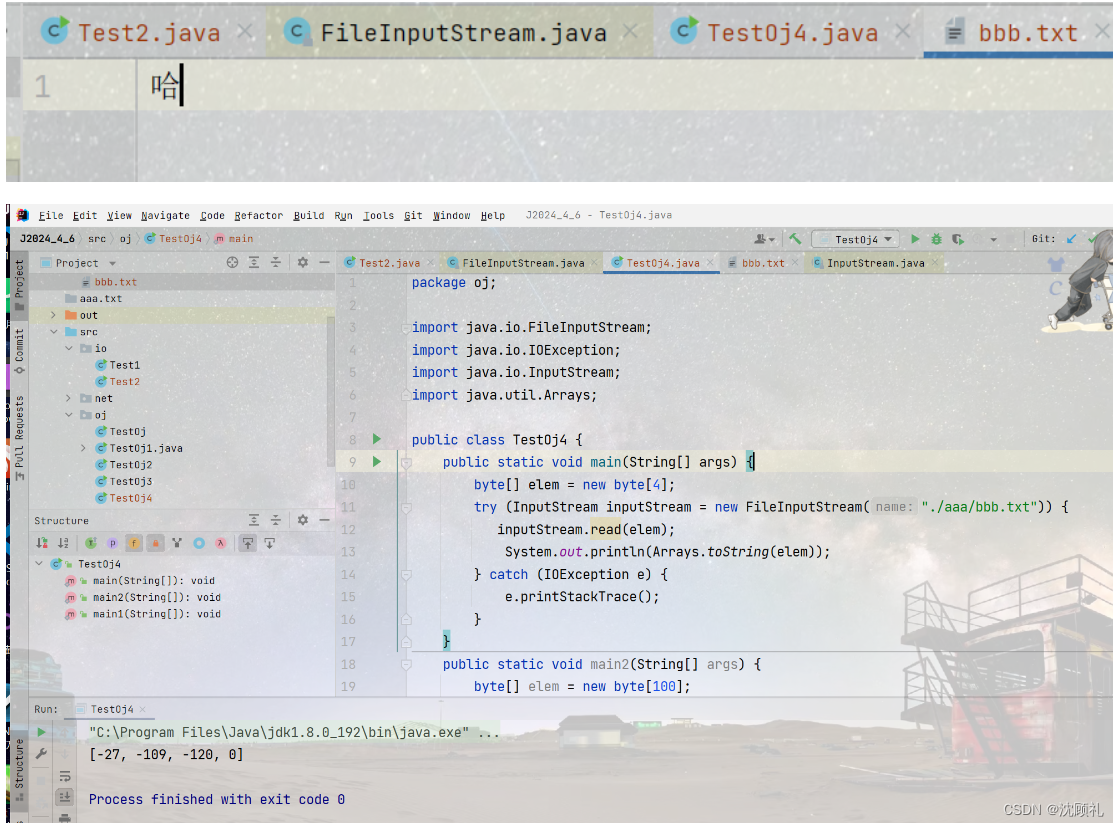
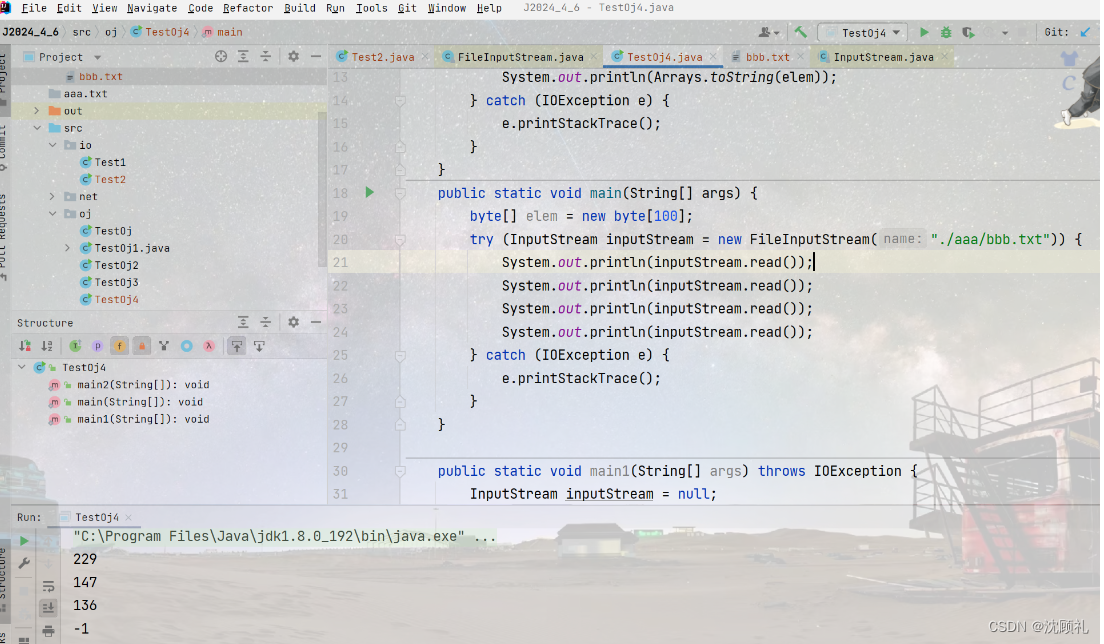
如图,你会发现如果读的是汉字的话,无参read和read到数组的里的数,就会不一样。但其实呢,数据是一样的,但是解读的方式不一样,inputStrem.read()是按照无符号数来解读的,无符号数其实是c语言中的概念,但read方法的底层是c或c++写的,而Arrays.toString(elem)是按照有符号数来进行解读的。无符号数,一个字节能表示的范围是0~255,有符号数一个字节能表示的范围为-128~127。我们可以用System.out.printf("%x ", elem[i]);来指定十六进制格式来打印,这样的话输出的结果都是一样了。
又因为在java里,都是有符号数,用byte接收的话,能表示的值在-128~127内,那么负号的值是无意义的,所以用int来接收。
你会发现无论是汉字还是英文字符读出的都是数字,这个数字其实是它们的编码值,英文字符返回的是ASCII码值,汉字的编码方式往往占多个字节,Unicode中一个汉字占两个字节,utf8中一个汉字占3个字节,读取一个字节返回的值其实就是这个字节中存放的数据值。
read(byte[] b, int off, int len) 版本,同样也需要提供一个字节数组来接收读取的数据, off是offset的缩写,偏移量的意思,就是指你读取的数据从字节数组的哪个位置开始放,len表示你要读取几个字节的数据。返回的int表示实际读取的字节个数。
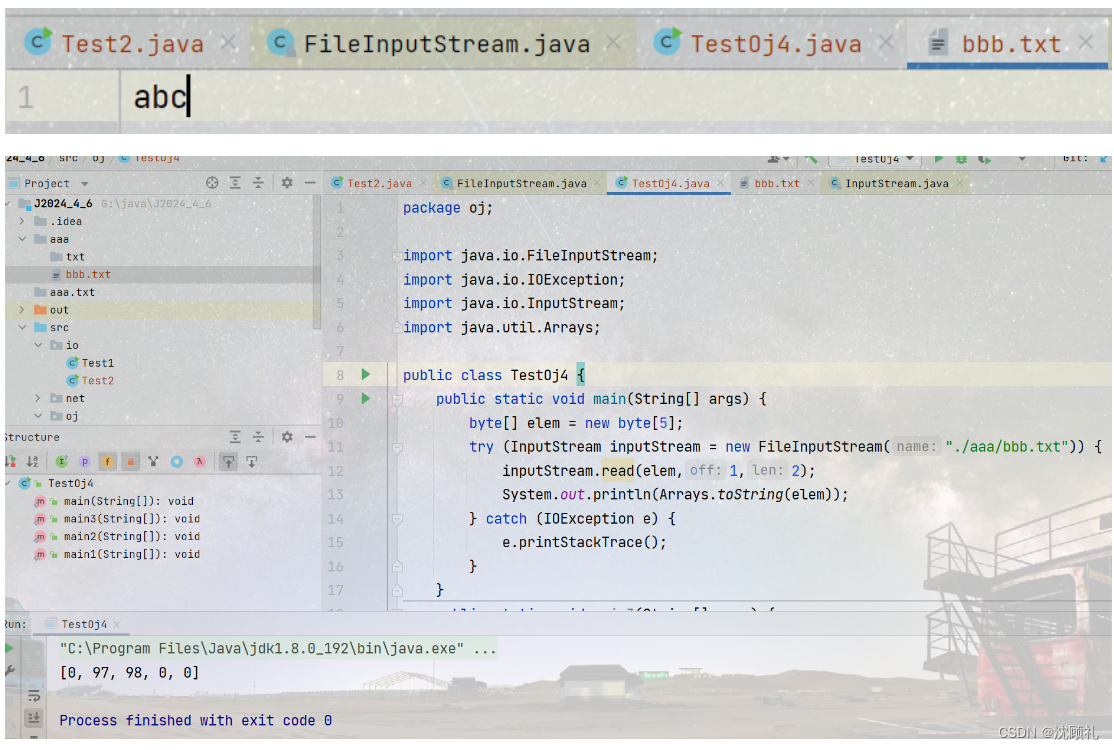
无参版本的read一次读一个字节,有参版本的read一次读多个字节,一般来说用有参版本的read比较好,因为从硬盘中读数据是个比较低效的操作,一次读若干个字节可以减少低效的操作。
读出的数据是数字,虽然有意义但是不便于阅读,毕竟字符编码千千万,谁能都记住呢,我们可以用String的构造方法来把存放读出数据的字符数据放到构造方法里面,new 一个String,就可以看到汉字了。
public static void main(String[] args) throws FileNotFoundException {
byte[] buffer = new byte[10];//buffer是缓冲区的意思,就是把数据暂时存放到这
try (InputStream inputStream = new FileInputStream("./aaa/bbb.txt")) {
int ret = inputStream.read(buffer);//返回实际读到的字节数
String s = new String(buffer, 0, ret);// 把字节数组构造成String
System.out.println(s);
} catch (IOException e) {
e.printStackTrace();
}
}OutputStream
读文件内容需要打开文件和关闭文件,写文件也一样。OutputStream和InputStream是比较类似的,都是抽象类,都实现了Closeable接口,使用上面也都差不多,只有一些区别。
public static void main(String[] args) throws FileNotFoundException {
try (OutputStream outputStream = new FileOutputStream("./aaa/bbb.txt")) {
// 其他逻辑
} catch (IOException e) {
e.printStackTrace();
}
}注意,outputStream打开文件的时候,文件的内容会直接被清空。但是我们可以用追加写的方式打开,这样就不会清空本来就有的数据了。
![]()
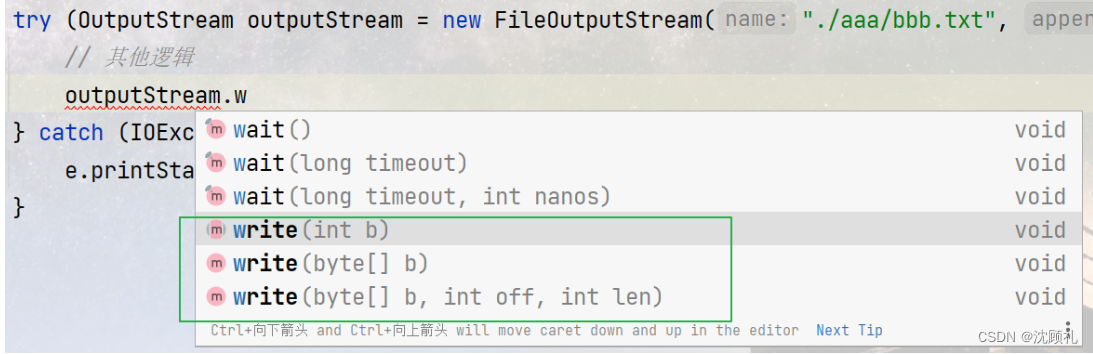
outputStream对文件进行写操作,写操作有三个版本。和inputStream的read三个版本意思差不多。有参write代表每次只写一个字节,write(byte[] b) 就是要提供一个字节数组,这个字节数组里面是要写入的数据所对应的编码值,然后一次若干个字节数据,write(byte[] b, int off , int len) ,off就是offset,从字节数组的哪个位置开始往下写,len就是要写多少个字节。
2.3.2 字符流
以字符为单位进行读写操作,一次最少读一个字符,可以根据字符编码不同来动态的读取数据,比如用gbk编码时,一个汉字占两个字节,用utf8编码时,一个汉字占三个字节。但是英文字符一般是占1个字节的。那么中英文混合读取的情况,如何判断到哪里会是一个字符呢?对于这个不用咋自己判断,java提供的字符流底层就解决了这个问题,可以自己处理字符编码。
代表类有Reader和Writer,这两个的使用方式和InputStream,OutputStream基本差不多。
Reader
同样的,是抽象方法,实现了Closeable接口
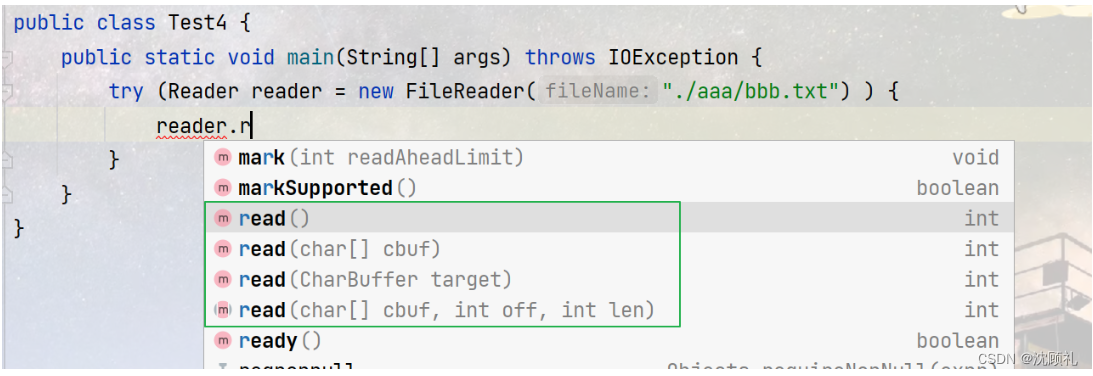
Reader的读文件主要是通过read方法,该方法的使用和InputStream的read是一样的,就不去赘述了。但是这里的read是以字符为单位进行读取的。这里有一个细节,一个char占2个字节,但是utf8中,一个汉字是占3个字节,在java中会把utf8编码的字符,在按照字符读取的时候转换成Unicode编码(Unicode编码中一个汉字占2个字节),每个char中存储的都是Unicode编码字符的值。Unicode编码还可以构造回utf8的String。
Writer
同样的,是抽象方法,实现了Closeable接口
Writer的写文件主要通过write方法,使用和OutputStream差不多。其中Writer的write增加了一种版本的方法,write(String str),是使用字符串来进行写入,一次写一个字符串。write(String str, int off, int len)就是把这个字符串只去其中一部分进行。















 1067
1067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









