









基础
首先我们要知道两种排序方法
Q:为什么不用快排呢? A:在集合很大的时候可以用快排,但数据小的话。。。nlogn就显得很大了
基数排序
基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数
还是看一波栗子吧
第一步
假设LSD原来有一串数值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根据个位数的数值,在走访数值时将它们分配至编号0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
第二步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接着再进行一次分配,这次是根据十位数来分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
第三步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
这时候整个数列已经排序完毕;如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。
LSD的基数排序适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好。MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
计数排序
它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。
假设输入的线性表L的长度为n,L=L1,L2,..,Ln;线性表的元素属于有限偏序集S,|S|=k且k=O(n),S={S1,S2,..Sk};则计数排序可以描述如下:
1、扫描整个集合S,对每一个Si∈S,找到在线性表L中小于等于Si的元素的个数T(Si);
2、扫描整个线性表L,对L中的每一个元素Li,将Li放在输出线性表的第T(Li)个位置上,并将T(Li)减1。
其实这个计数排序看代码更好啦
#include <iostream>
using namespace std;
const int MAXN = 100000;
const int k = 1000; // range
int a[MAXN], c[MAXN], ranked[MAXN];
int main() {
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> a[i];
++c[a[i]];
}
for (int i = 1; i < k; ++i)
c[i] += c[i-1];
for (int i = n-1; i >= 0; --i)
ranked[--c[a[i]]] = a[i];//如果是i表达的是原数标号,a[i]就是排序后的正确序列
for (int i = 0; i < n; ++i)
cout << ranked[i] << endl;
return 0;
}概念
子串:字符串 S 的子串 r[i..j] ,i ≤ j ,表示 r 串中从 i 到 j 这一段,就是顺次排列r[i],r[i+1],…,r[j]形成的字符串。
后缀:后缀是指从某个位置 i 开始到整个串末尾结束的一个特殊子串。字符串 r 的从 第 i 个字 符 开 始 的 后 缀 表 示 为 Suffix(i) ,也就是Suffix(i)=r[i..len(r)] 。
字符串的大小比较:关于字符串的大小比较,是指通常所说的 “ 字典顺序 ” 比较, 也就是对于两个字符串 u 、 v ,令 i 从 1 开始顺次比较 u[i] 和 v[i] ,如果u[i]=v[i] 则令 i 加 1 ,否则若 u[i] < v[i] 则认为 u < v , u[i]>v[i] 则认为 u>v(也就是 v < u ),比较结束。如果 i>len(u) 或者 i>len(v) 仍比较不出结果,那么 若 len(u) < len(v) 则 认 为 u < v , 若 len(u)=len(v) 则 认 为 u=v , 若len(u)>len(v) 则 u>v 。
从字符串的大小比较的定义来看, S 的两个开头位置不同的后缀 u 和 v 进行比较的结果不可能是相等,因为 u=v 的必要条件 len(u)=len(v) 在这里不可能满足。
后缀数组: 后缀数组 sa 是一个一维数组,它保存 1..n 的某个排列 sa[1] ,sa[2] , …… , sa[n] ,并且保证 Suffix(sa[i]) < Suffix(sa[i+1]) , 1≤i < n 。也就是将 S 的 n 个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入 SA 中。 【排第几的是谁】
名次数组: 名次数组 Rank[i] 保存的是 Suffix(i) 在所有后缀中从小到大排列的 “ 名次 ”【你排第几】
height 数组:定义 height[i]=suffix(sa[i-1]) 和 suffix(sa[i]) 的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀。那么对于 j 和 k ,不妨设rank[j] < rank[k], 则有以下性质:suffix(j) 和 suffix(k) 的最长公共前缀为 height[rank[j]+1],height[rank[j]+2], height[rank[j]+3], … ,height[rank[k]] 中的最小值。
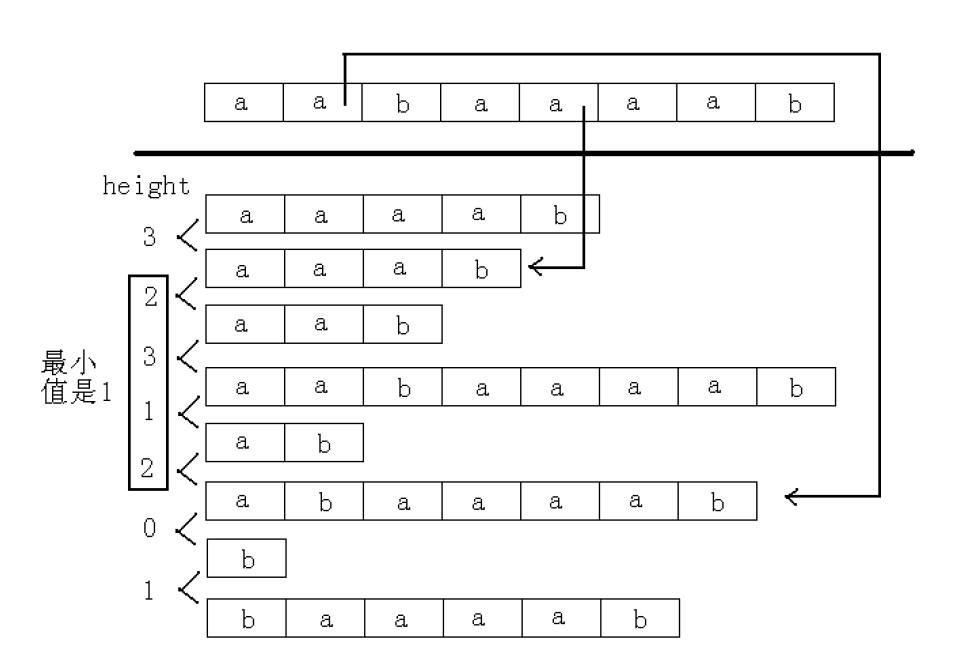
O(NlogN)求sa
这里的构造方法用的是基数排序+倍增构造
倍增构造的思路就是:想要求出
2k
的序列,而我们已知了
2k−1
的序列,那么就利用这个进行基数排序
算法流程
- 对长度为1的串进行排序。如果初始的字符集很小可以采用计数排序,字符集很大的话可以改成快速排序。
- 进行倍增。每一次先对第二关键字进行排序,然后再对第一关键字进行排序。第二关键字的排序可以通过上一次算出的sa求出,第一关键字排序采用计数排序。
- 对于求出的sa值求rank值。这里的rank可以不进行保留,而是根据字符串是否相等判断。

const int m=300;
void build_sa() {
for (int i=0; i<m; i++) c[i]=0;
for (int i=0; i<n; i++) c[x[i]=s[i]]++;
for (int i=1; i<m; i++) c[i]+=c[i-1];
for (int i=n-1; i>=0; i--) sa[--c[x[i]]]=i;
//计数排序
for (int k=1;k<=n;k<<=1){
int p=0;
for (int i=n-k;i<n;i++) y[p++]=i;
for (int i=0;i<n;i++) if (sa[i]>=k) y[p++]=sa[i]-k;
for (int i=0;i<m;i++) c[i]=0;
for (int i=0;i<n;i++) ++c[x[y[i]]];
for (int i=1;i<m;i++) c[i]+=c[i-1];
for (int i=n-1;i>=0;i--) sa[--c[x[y[i]]]]=y[i];
swap(x,y);
p=1; x[sa[0]]=0;
for (int i=1;i<n;i++) x[sa[i]]=y[sa[i-1]]==y[sa[i]]&&
((sa[i-1]+k>=n?-1:y[sa[i-1]+k])==(sa[i]+k>=n?-1:y[sa[i]+k]))?p-1:p++;
if (p>n) break;
m=p;
}
}
O(N)求rank/height
定义h[i]=height[rank[i]] ,也就是 suffix(i) 和在它前一名的后缀的最长公共前缀。
h 数组有以下性质:h[i] ≥ h[i-1]-1(显然?!)
我们知道 Suffix(i-1) 去掉开头的一个字符就变成了 Suffix(i) ,同样Suffix(k) 去掉开头的一个字符就变成了 Suffix(k+1) ,如果 suffix(k) 是排在 suffix(i-1) 前一名的后缀,那么suffix(k+1) 肯定排在 suffix(i) 前面,并且它们都是由前面那两个后缀去掉一个字符得来的,所以它们之间去掉之后至少的公共前缀都不会变。
void build_lcp()
{
for (int i=0;i<n;i++) rank[sa[i]]=i;
height[0]=0;
int k=0;
for (int i=0;i<n;i++)
{
if (!rank[i]) continue;
if (k) --k;
int j=sa[rank[i]-1];
while (i+k<n && j+k<n && s[i+k]==s[j+k]) ++k;
height[rank[i]]=k;
}
}小结
可以发现,后缀数组的题目关键字就一个:
子串
无非就两个关键性质:
①子串一定是某一个后缀的前缀
②最长公共前缀是height的区间最小值
而求解这一类基本问题也就几个方法:
①二分
②height分组
③st表
④单调栈
后缀数组好bt啊,感觉功能上还是后缀自动机多一些,还有很多题没有做,这里码题待做吧
bzoj 3230
bzoj 3238
bzoj 4516
bzoj 2119
bzoj 3277
bzoj 4199















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









