






1.语音信号
语音信号是一个在时域上波动的一维信号,如下图所示:
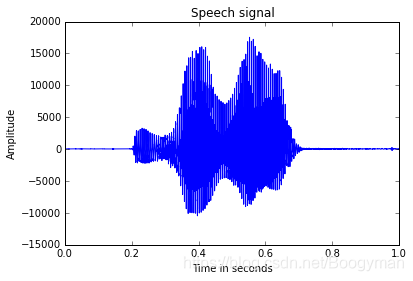
常见的语音信号模型有Autoregressive Model(自回归模型)、Sinusoidal + Residual model(正弦加噪模型)。一种更加被广泛认可的模型认为语音信号等效于一个时变滤波器对一系列脉冲信号的处理造成。脉冲信号主要受说话人的音色影响,时变滤波器主要受说话人发音内容影响(如,清音,浊音等)影响。当然,以及最后的随机噪声影响。
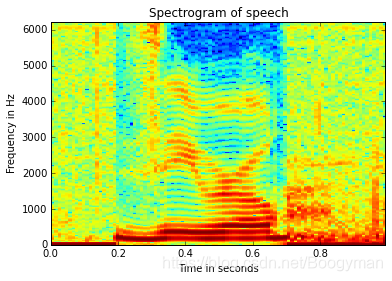
语音信号是准稳态的(quasi-stationary),这意味着语音信号在短时间内具有频率不变性,但对于一段很长的语音信号其频率在不同的时间点可能存在很大的不同。这也是短时傅里叶变换的必要性(Short-Time Fourier Transform)。下图为一个语音信号的语谱图。
2.语音特征
MFCC,教程见(http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/)
LPC, 教程见(https://www.gaussianwaves.com/2014/05/yule-walker-estimation/)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









