







一、概述
1、压缩的优缺点
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
2、压缩的原则
(1)运算密集型的Job,少用压缩
(2)IO密集型的Job,多用压缩
二、MR支持的压缩编码
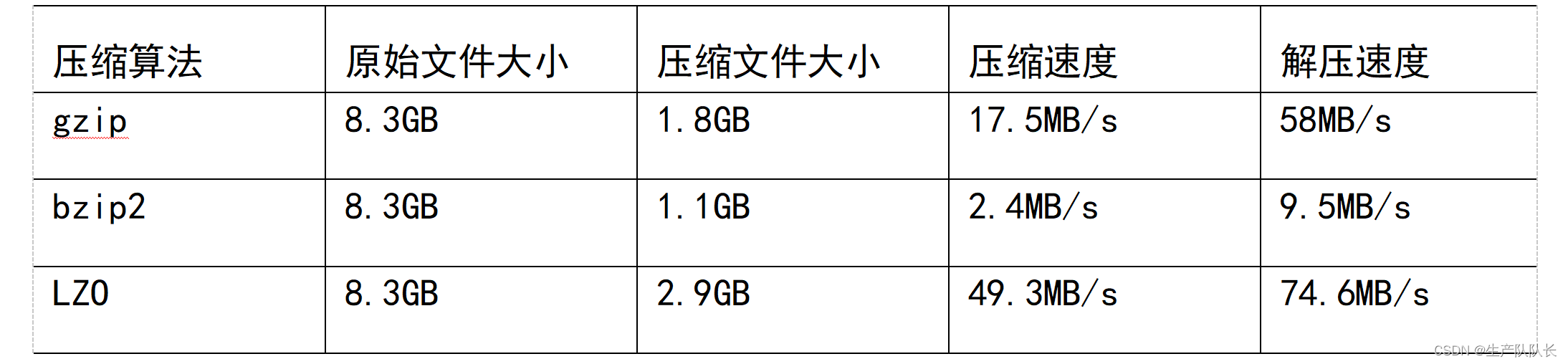
1、压缩算法对比

补充Snappy :
Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
2、性能比较
三、选择的原则
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
MR程序中,有三处可以使用压缩

四、相关配置
1、查看集群支持的压缩方式
hadoop checknative
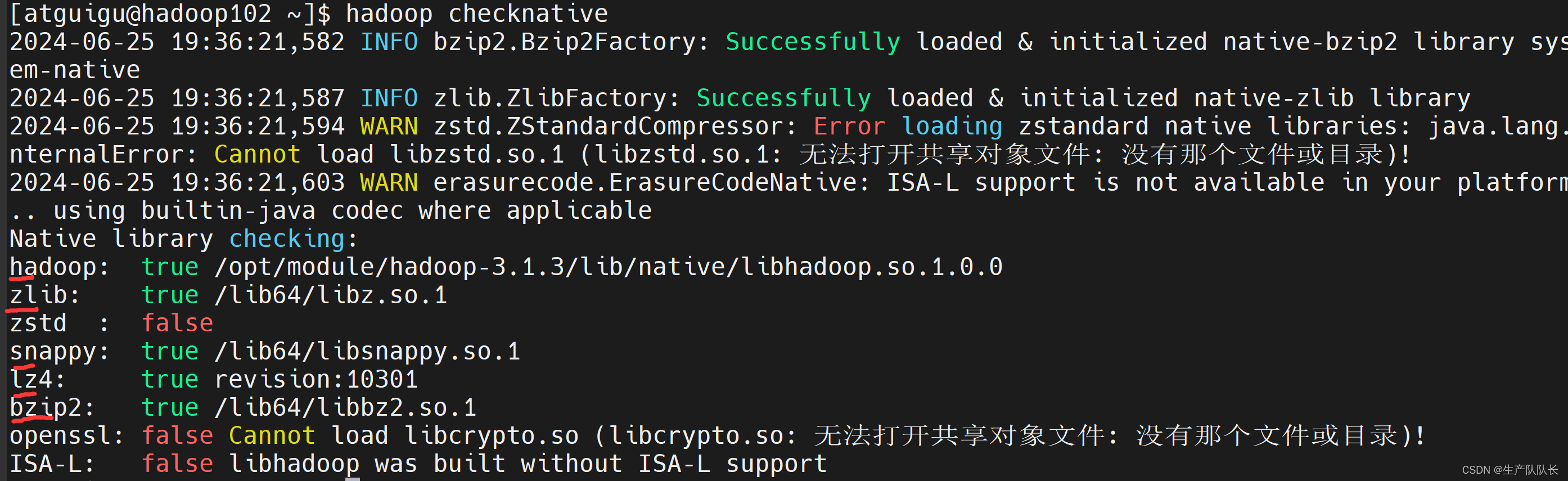
其中,Snappy需要再集群中才能使用,本地无法测试。
2、查看配置
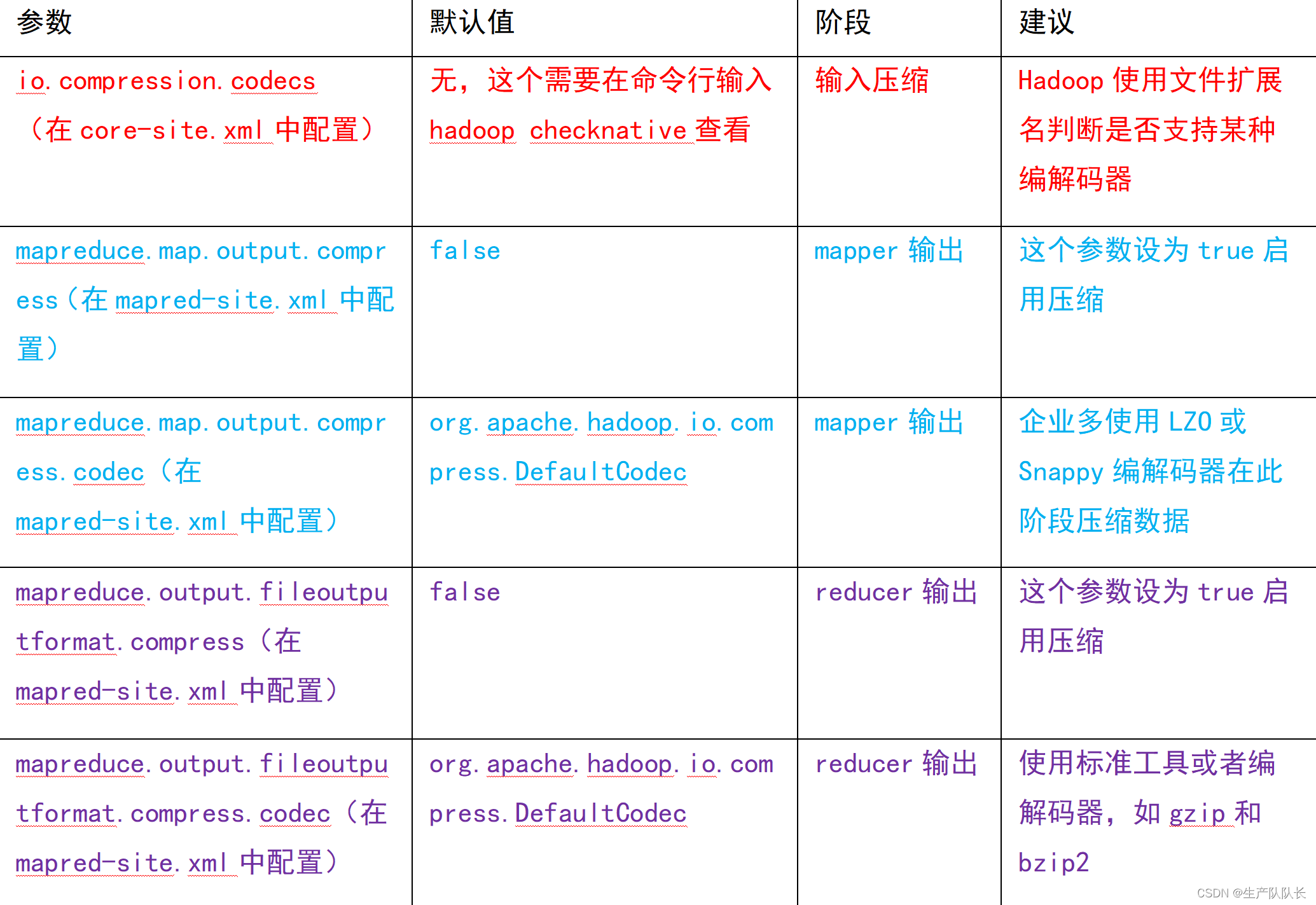
core-default.xml
io.compression.codecs
mapred-default.xml
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
mapreduce.output.fileoutputformat.compress
mapreduce.output.fileoutputformat.compress.codec
五、代码实现
WordCountDriver
关键配置
package com.atguigu.mapreduce.yasuo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
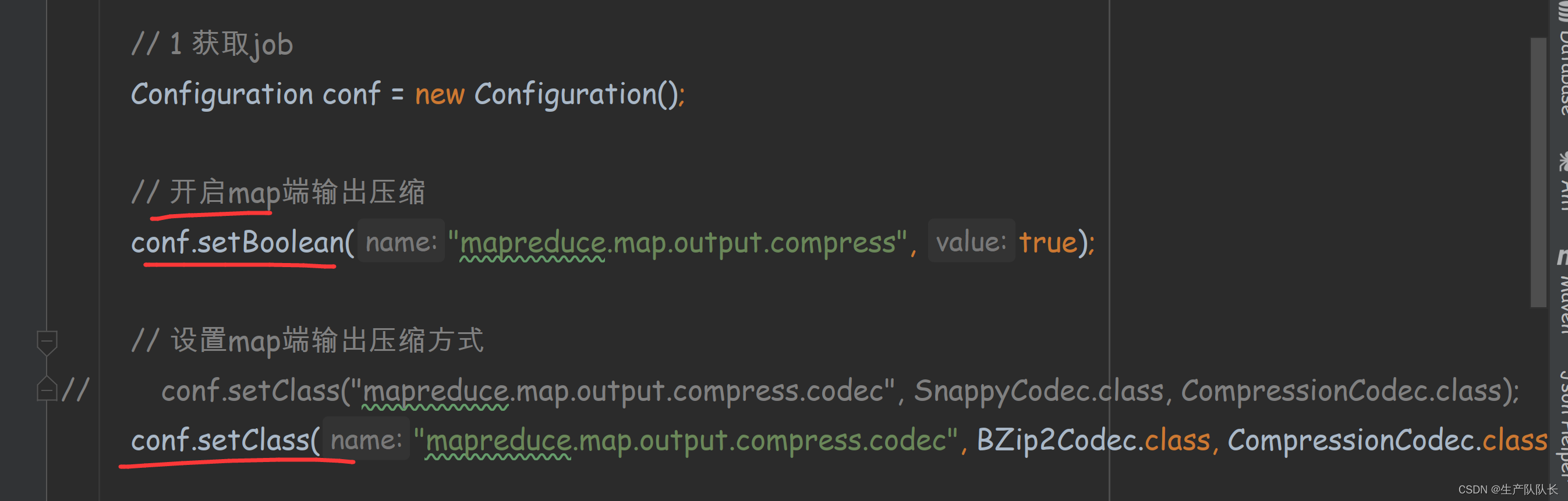
// 1 获取job
Configuration conf = new Configuration();
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec", SnappyCodec.class, CompressionCodec.class);
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
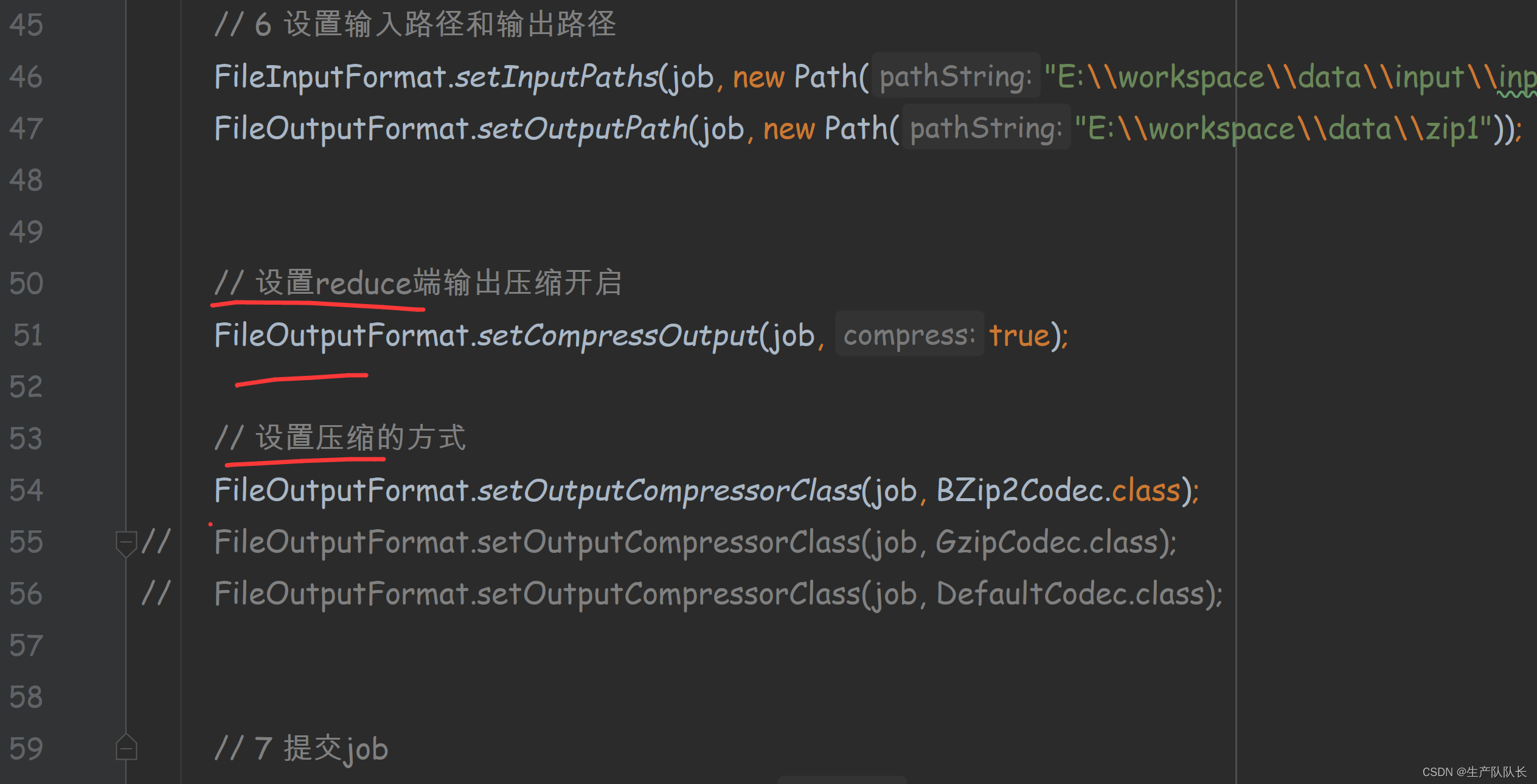
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output888"));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
// FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
WordCountMapper
package com.atguigu.mapreduce.yasuo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key的类型:LongWritable
* VALUEIN,map阶段输入value类型:Text
* KEYOUT,map阶段输出的Key类型:Text
* VALUEOUT,map阶段输出的value类型:IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
// atguigu atguigu
String line = value.toString();
// 2 切割
// atguigu
// atguigu
String[] words = line.split(" ");
// 3 循环写出
for (String word : words) {
// 封装outk
outK.set(word);
// 写出
context.write(outK, outV);
}
}
}
WordCountReducer
package com.atguigu.mapreduce.yasuo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN, reduce阶段输入的key的类型:Text
* VALUEIN,reduce阶段输入value类型:IntWritable
* KEYOUT,reduce阶段输出的Key类型:Text
* VALUEOUT,reduce阶段输出的value类型:IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// atguigu, (1,1)
// 累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
// 写出
context.write(key,outV);
}
}
测试
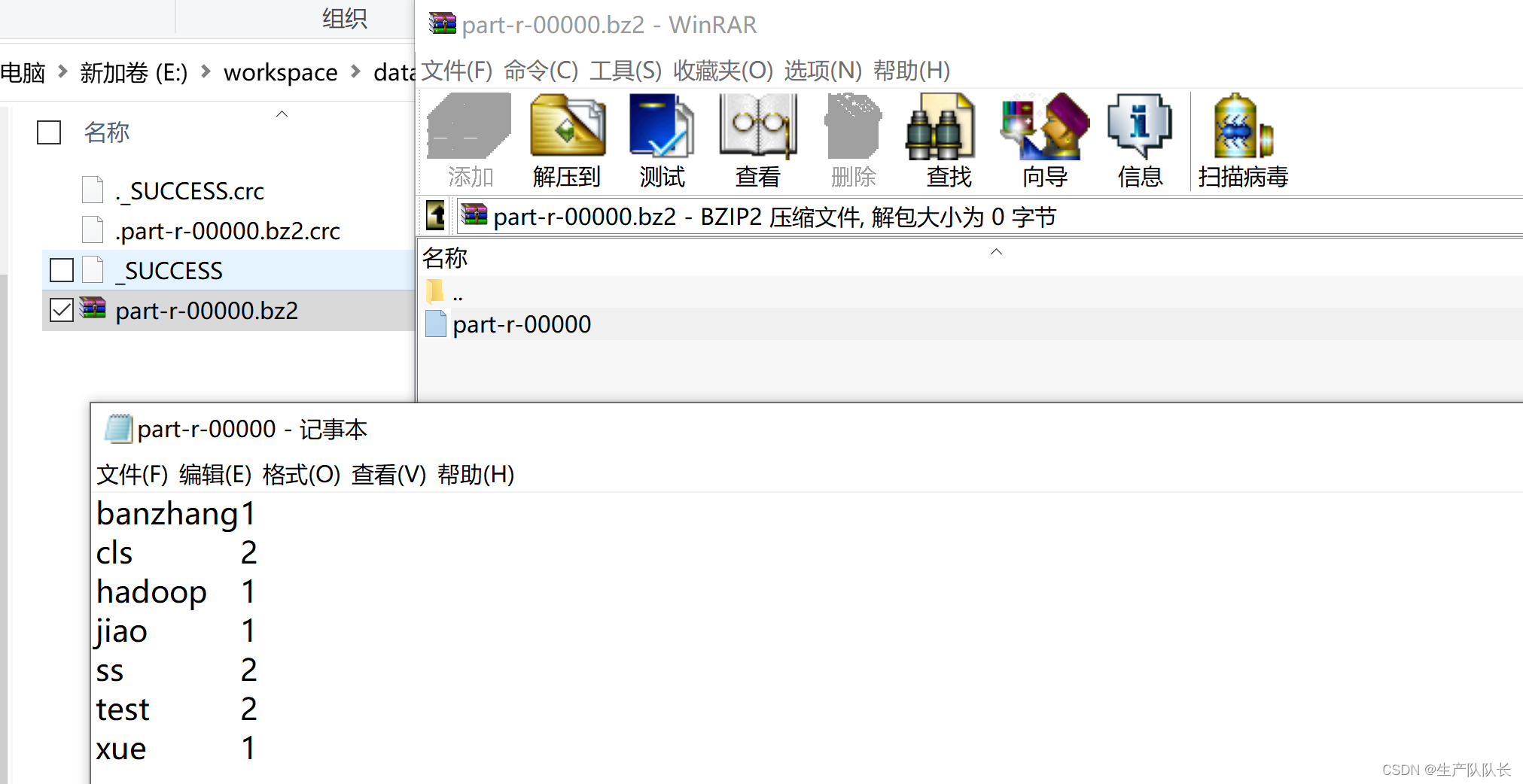
Reduce端输出时的压缩方式
1、BZip2Codec方式
2、GzipCodec方式
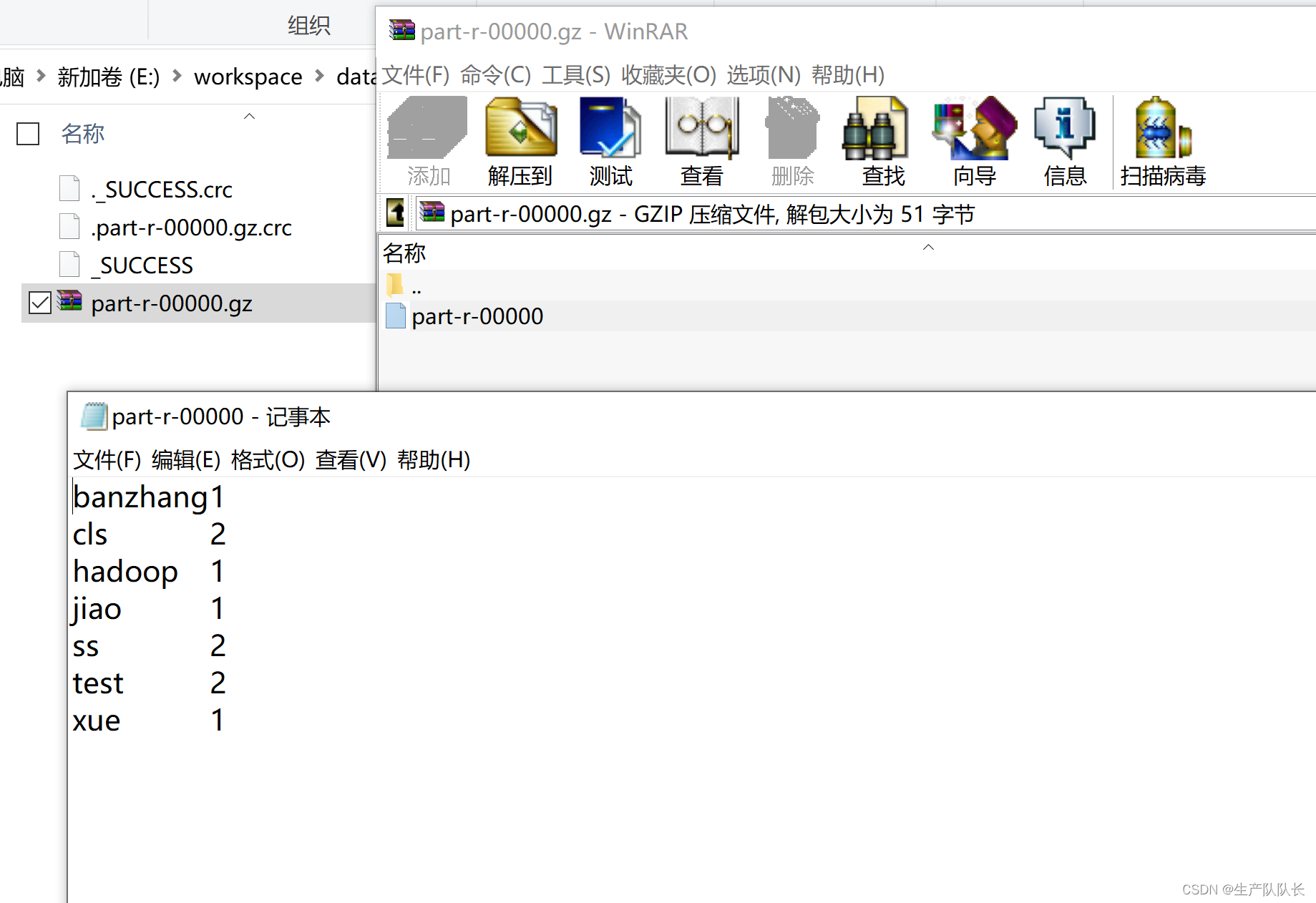
3、DefaultCodec方式
















 1645
1645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









