







一、流程图
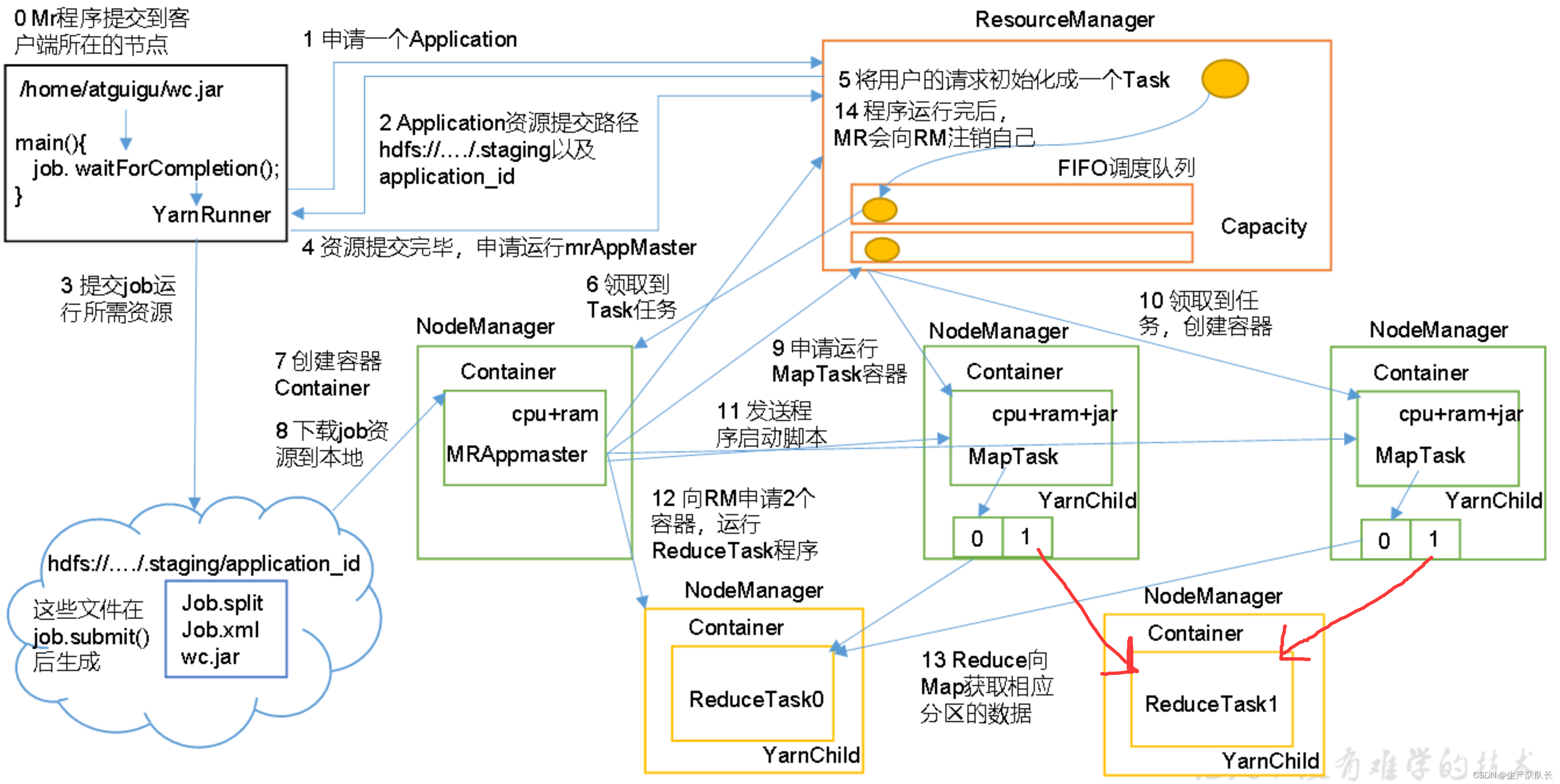
注意:步骤0中,如果是本地运行,则创建的是LocalRunner
二、流程说明
1、首先,我们把自己编写好的MR程序,上传到集群中客户端所在的节点。
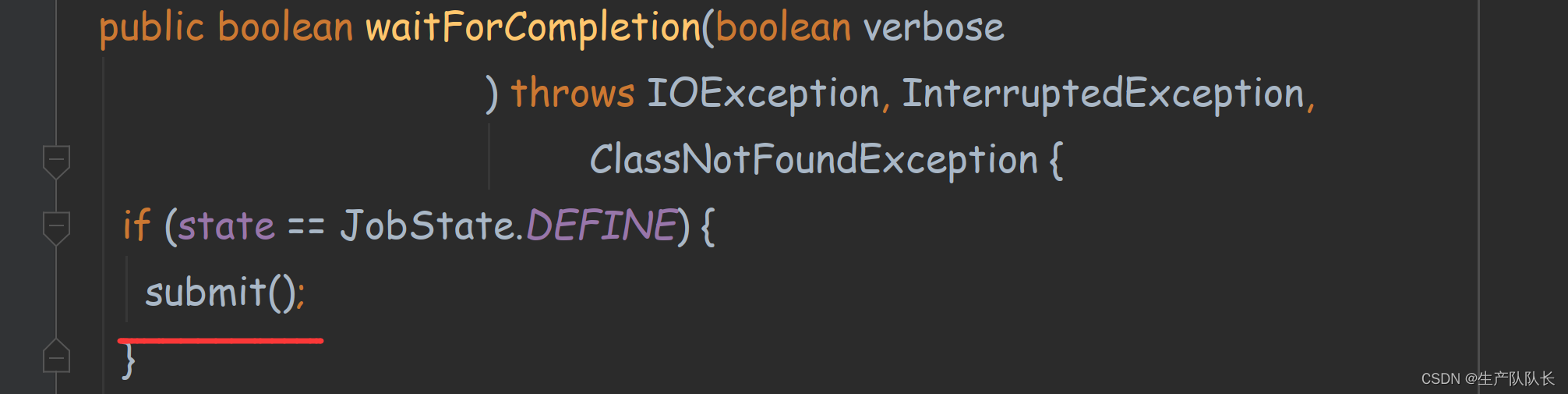
2、使用shell客户端命令,执行jar程序,执行到job.waitForCompletion(true);时,会创建一个YarnRunner对象。
3、YarnRunner会向ResourceManager(RM)申请一个Application。
4、RM将该应用程序的资源路径返回给YarnRunner。
5、于是,程序将运行所需的三样(Job.split、Job.xml、xxx.jar)资源,提交到HDFS上对应路径下。
而这三样资源,在Driver运行到job.submit();时,被创建。
6、程序资源提交完毕后,向RM申请运行mrAppMaster。
7、RM将用户的请求初始化成一个Task。并将该Task放入任务队列中,等待处理。
8、空闲的NodeManager(NM)会来领取Task任务。并创建容器Container,并生成一个MRAppmaster。
然后,将job提交的3个资源下载到本地。在根据Job.split切片信息,申请MapTask容器。
比如,此处是两个切片,则申请2个MapTask容器来运行。
9、于是,RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(注意:这两个容器,可能在同一个NodeManager上,图中只是一种可能的情况)
10、MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
11、MrAppMaster等待所有MapTask运行完毕后,再次向RM申请容器,运行ReduceTask。ReduceTask向MapTask获取相应分区的数据。
12、ReduceTask全部执行完毕后,MrAppMaster反馈给RM,RM进行资源释放。
















 4508
4508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









