






话不多说,直接上代码:
-
相关代码
配置文件application.yml中关于路径的配置


public void exportExperimentalData(ExportExperimentalDataReqVo reqVo, Long userId, HttpServletResponse response, HttpServletRequest request) {
List<String> experimentalIds = reqVo.getExperimentalIds();
List<ExperimentalDataIndex> list = new ArrayList<>();
for (String experimentalId : experimentalIds) {
ExperimentalDataIndex experimentalDataIndex = searchService.searchExperimentalById(experimentalId, EsIndexEnum.EXPERIMENTAL_DATA_INDEX.getIndexName());
list.add(experimentalDataIndex);
// 新增用户下载记录
UserDownloadRecord downloadRecord = new UserDownloadRecord();
downloadRecord.setUserId(userId);
downloadRecord.setLiteratureId(experimentalId);
downloadRecord.setTitle(experimentalDataIndex.getExperimentalTopic());
downloadRecord.setSummary(experimentalDataIndex.getExperimentalConclusion());
downloadRecord.setAuthor(experimentalDataIndex.getRecorder());
downloadRecord.setDataType(2);//实验数据
downloadRecord.setFinishTime(experimentalDataIndex.getFinishTime());
downloadRecord.setCreateId(userId);
downloadRecord.setCreateTime(new Date());
userDownloadRecordMapper.insert(downloadRecord);
}
// 如果是单条下载 则下载为word 批量下载是zip格式
if (list.size() == 1) {
ExperimentalDataIndex experimentalDataIndex = list.get(0);
String filePath = fileRoot;
this.downloadExperimentalSingle(experimentalDataIndex, filePath, response, request);
} else {
String filePath = fileRoot + File.separator + "zip_path" + System.currentTimeMillis() + File.separator;
this.downloadExperimentalBatch(list, filePath, response, request);
}
}
/**
* 批量下载
*
* @Param list
* @Param filePath
* @Param response
* @Param request
* @Return void
**/
private void downloadExperimentalBatch(List<ExperimentalDataIndex> list, String filePath, HttpServletResponse response, HttpServletRequest request) {
try {
for (ExperimentalDataIndex experimentalDataIndex : list) {
Map<String, Object> wordDataMap = new HashMap<>(32);
wordDataMap.put("experimentalTopic", experimentalDataIndex.getExperimentalTopic());
wordDataMap.put("recorder", userMapper.selectById(Long.parseLong(experimentalDataIndex.getRecorder())).getNickName());
wordDataMap.put("major", experimentalDataIndex.getMajor());
wordDataMap.put("classes", experimentalDataIndex.getClasses());
wordDataMap.put("analyticalMethods", experimentalDataIndex.getAnalyticalMethods());
wordDataMap.put("finishTime", experimentalDataIndex.getFinishTime());
wordDataMap.put("experimentalIndicators", experimentalDataIndex.getExperimentalIndicators());
wordDataMap.put("testConditions", experimentalDataIndex.getTestConditions());
wordDataMap.put("experimentalScheme", experimentalDataIndex.getExperimentalScheme());
// 实验附图
List<ExperimentalDataImg> experimentalDataImgList = experimentalDataImgMapper.selectList(new
LambdaQueryWrapper<ExperimentalDataImg>().eq(ExperimentalDataImg::getExperimentalId,
experimentalDataIndex.getId()));
// 附图导出封装类
List<ExperimentalDataImgExportVo> imgExportVos = new ArrayList<>();
int code = 1;
for (ExperimentalDataImg experimentalDataImg : experimentalDataImgList) {
ExperimentalDataImgExportVo experimentalDataImgExportVo = BaseDtoConvert.tToV(experimentalDataImg, ExperimentalDataImgExportVo.class);
experimentalDataImgExportVo.setCode(code);
if (StringUtils.isEmpty(experimentalDataImgExportVo.getRemarks())) {
experimentalDataImgExportVo.setRemarks("无");
}
imgExportVos.add(experimentalDataImgExportVo);
code++;
}
wordDataMap.put("experimentalImg", imgExportVos);
wordDataMap.put("experimentalConclusion", experimentalDataIndex.getExperimentalConclusion());
String downloadFileName =
experimentalDataIndex.getExperimentalTopic() + System.currentTimeMillis() + ".docx";
String savePath = filePath + downloadFileName;
if (!FileUtil.exist(filePath)) {
FileUtil.mkdir(filePath);
}
// 添加配置 循环表格行(实验附图)
LoopRowTableRenderPolicy policy = new LoopRowTableRenderPolicy();
Configure config = Configure.builder()
.bind("experimentalImg", policy).build();
//渲染文件
XWPFTemplate compile = XWPFTemplate.compile("./template/实验数据导出模板_template.docx", config);
compile.render(wordDataMap);
compile.writeToFile(savePath);
}
// 设置压缩后的文件名
String zipFileName = "实验数据.zip";
// 压缩文件保存的路径
String toPath = fileRoot + zipFileName;
// 要压缩的文件目录
String zipPath = filePath;
ZipUtil.zip(zipPath, toPath);
// 压缩完之后删除原文件
FileUtils.deleteDirectory(new File(zipPath));
try {
File file = new File(toPath);
String fileName = URLEncoder.encode(file.getName(), "UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
response.setContentType("application/zip");
response.setContentLength((int) file.length());
try (InputStream inputStream = new FileInputStream(file);
OutputStream outputStream = response.getOutputStream()) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
}
} catch (IOException e) {
e.printStackTrace();
}
} catch (Exception e) {
throw new ServiceException("下载实验数据失败!!" + e.getMessage());
}
}
/**
* 单独下载
*
* @Param experimentalDataIndex
* @Param filePath
* @Param response
* @Param request
* @Return void
**/
private void downloadExperimentalSingle(ExperimentalDataIndex experimentalDataIndex, String filePath, HttpServletResponse response, HttpServletRequest request) {
Map<String, Object> wordDataMap = new HashMap<>(32);
wordDataMap.put("experimentalTopic", experimentalDataIndex.getExperimentalTopic());
wordDataMap.put("recorder", userMapper.selectById(Long.parseLong(experimentalDataIndex.getRecorder())).getNickName());
wordDataMap.put("major", experimentalDataIndex.getMajor());
wordDataMap.put("classes", experimentalDataIndex.getClasses());
wordDataMap.put("analyticalMethods", experimentalDataIndex.getAnalyticalMethods());
wordDataMap.put("finishTime", experimentalDataIndex.getFinishTime());
wordDataMap.put("experimentalIndicators", experimentalDataIndex.getExperimentalIndicators());
wordDataMap.put("testConditions", experimentalDataIndex.getTestConditions());
wordDataMap.put("experimentalScheme", experimentalDataIndex.getExperimentalScheme());
// 实验附图
List<ExperimentalDataImg> experimentalDataImgList = experimentalDataImgMapper.selectList(new
LambdaQueryWrapper<ExperimentalDataImg>().eq(ExperimentalDataImg::getExperimentalId,
experimentalDataIndex.getId()));
// 附图导出封装类
List<ExperimentalDataImgExportVo> imgExportVos = new ArrayList<>();
int code = 1;
for (ExperimentalDataImg experimentalDataImg : experimentalDataImgList) {
ExperimentalDataImgExportVo experimentalDataImgExportVo = BaseDtoConvert.tToV(experimentalDataImg, ExperimentalDataImgExportVo.class);
experimentalDataImgExportVo.setCode(code);
if (StringUtils.isEmpty(experimentalDataImgExportVo.getRemarks())) {
experimentalDataImgExportVo.setRemarks("无");
}
imgExportVos.add(experimentalDataImgExportVo);
code++;
}
wordDataMap.put("experimentalImg", imgExportVos);
wordDataMap.put("experimentalConclusion", experimentalDataIndex.getExperimentalConclusion());
String downloadFileName =
experimentalDataIndex.getExperimentalTopic() + System.currentTimeMillis() + ".docx";
String savePath = filePath + downloadFileName;
if (!FileUtil.exist(filePath)) {
FileUtil.mkdir(filePath);
}
try {
// 添加配置 循环表格行(实验附图)
LoopRowTableRenderPolicy policy = new LoopRowTableRenderPolicy();
Configure config = Configure.builder()
.bind("experimentalImg", policy).build();
//渲染文件
XWPFTemplate compile = XWPFTemplate.compile("./template/实验数据导出模板_template.docx", config);
compile.render(wordDataMap);
compile.writeToFile(savePath);
this.httpDownload(response, request, downloadFileName, savePath);
} catch (Exception e) {
throw new ServiceException("下载实验数据失败!!" + e.getMessage());
}
}
private void httpDownload(HttpServletResponse response, HttpServletRequest request,
String downloadFileName, String savePath) throws IOException {
InputStream is = new FileInputStream(savePath);
OutputStream os = response.getOutputStream();
String userAgent = request.getHeader("user-agent").toLowerCase();
if (userAgent.contains("msie") || userAgent.contains("like gecko")) {
// win10 ie edge 浏览器 和其他系统的ie
downloadFileName = URLEncoder.encode(downloadFileName, "UTF-8");
} else {
//其他的浏览器
downloadFileName = new String(downloadFileName.getBytes(StandardCharsets.UTF_8),
StandardCharsets.ISO_8859_1);
}
response.setContentType(FileSuffixConstants.DOC);
response.setCharacterEncoding("UTF-8");
response.setHeader("content-disposition",
"attachment;filename=" + downloadFileName);
response.setHeader("Access-Control-Expose-Headers", "content-disposition");
IOUtils.copy(is, os);
is.close();
os.close();
os.flush();
}
下载模板 :

下载效果:
docx

zip(包含两个测试文档)

踩过的坑:
1.poi-tl的依赖跟xalan.jar有冲突,同时存在会报错
java.lang.IllegalArgumentException: 不支持:http://javax.xml.XMLConstants/property/accessExternalStylesheet
已知:poi-ti中已排除 xalan.jar
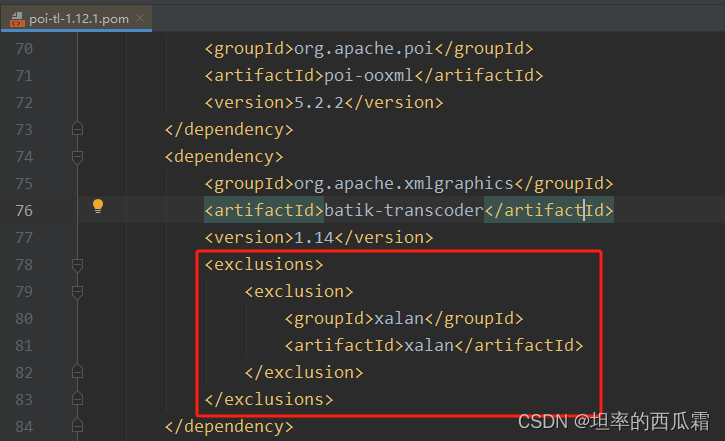
注:我的项目中引入的docx4j,docx4j中包含xalan.jar;删除docx4j相关依赖,不再报上述错误

2.poi-tl的版本号必须用最新版 (因为我需要在docx中插入图片,需要用到其附件功能)
![]()
否则会报错 Caused by: java.lang.NoSuchMethodError: org.apache.poi.xwpf.usermodel.XWPFRun.getFontSizeAsDouble()Ljava/lang/Double;
报的poi的方法找不到
最新版的poi-tl用的poi版本是:

我的工程中其他模块引入了poi-ooxml,所以也要对其做一个版本的升级
![]()
参考文档:Poi-tl Documentation

以上,就是整个使用poi-tl导出docx文档的全部细节以及注意事项。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









