









文章目录
python爬虫五部曲:
-
第一步:安装requests库
-
第二步:获取爬虫所需的header和cookie
-
第三步:获取网页
-
第四步:解析网页
-
第五步:分析得到的Json数据
1. 第一步:安装requests库
在程序中引用两个库的书写是这样的:
import requests
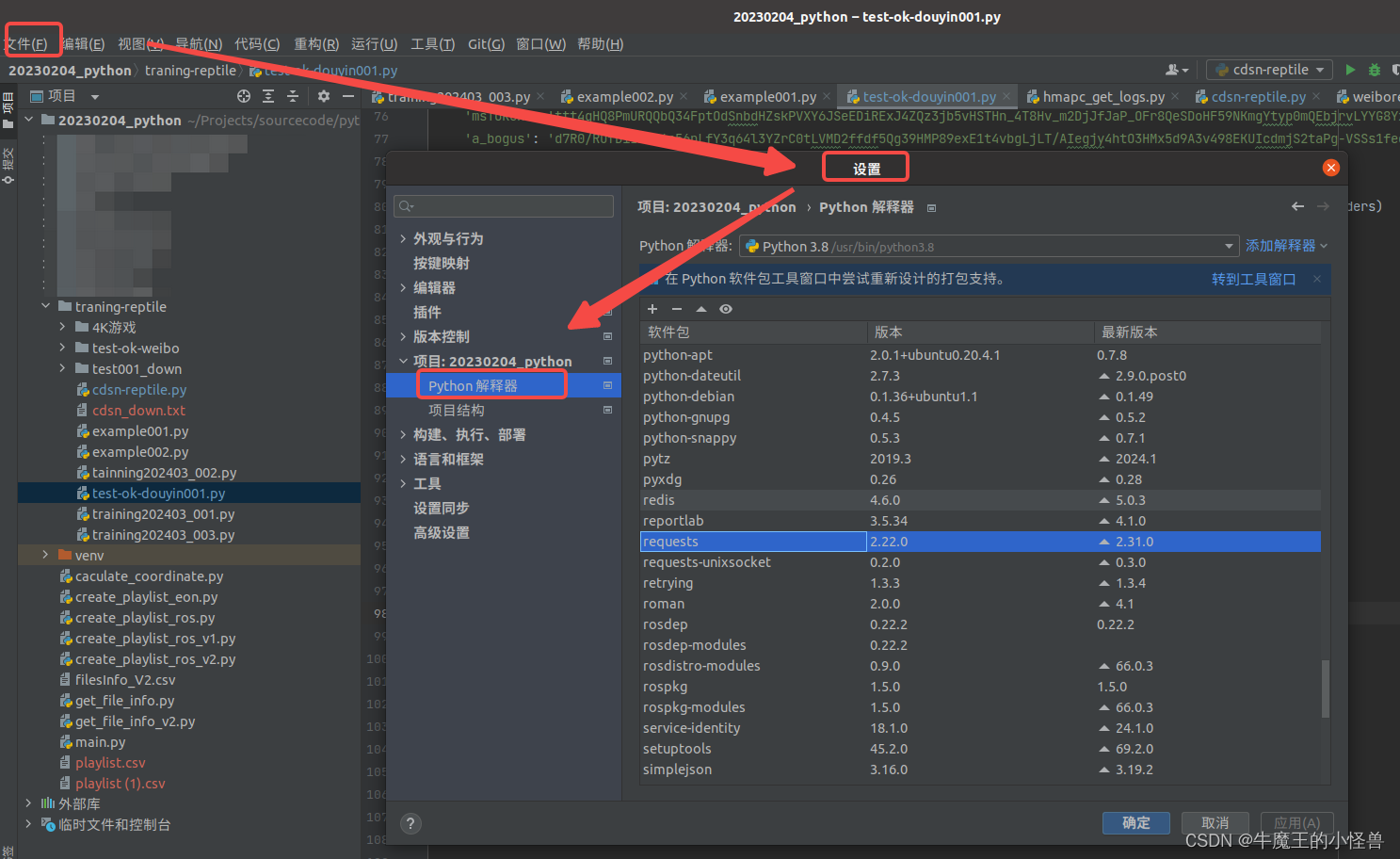
以pycharm为例,在pycharm上安装这个库的方法。在菜单【文件】–>【设置】->【项目】–>【Python解释器】中,在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
2. 第二步:获取爬虫所需的header和cookie
以爬取 个人微博 的爬虫程序为例。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
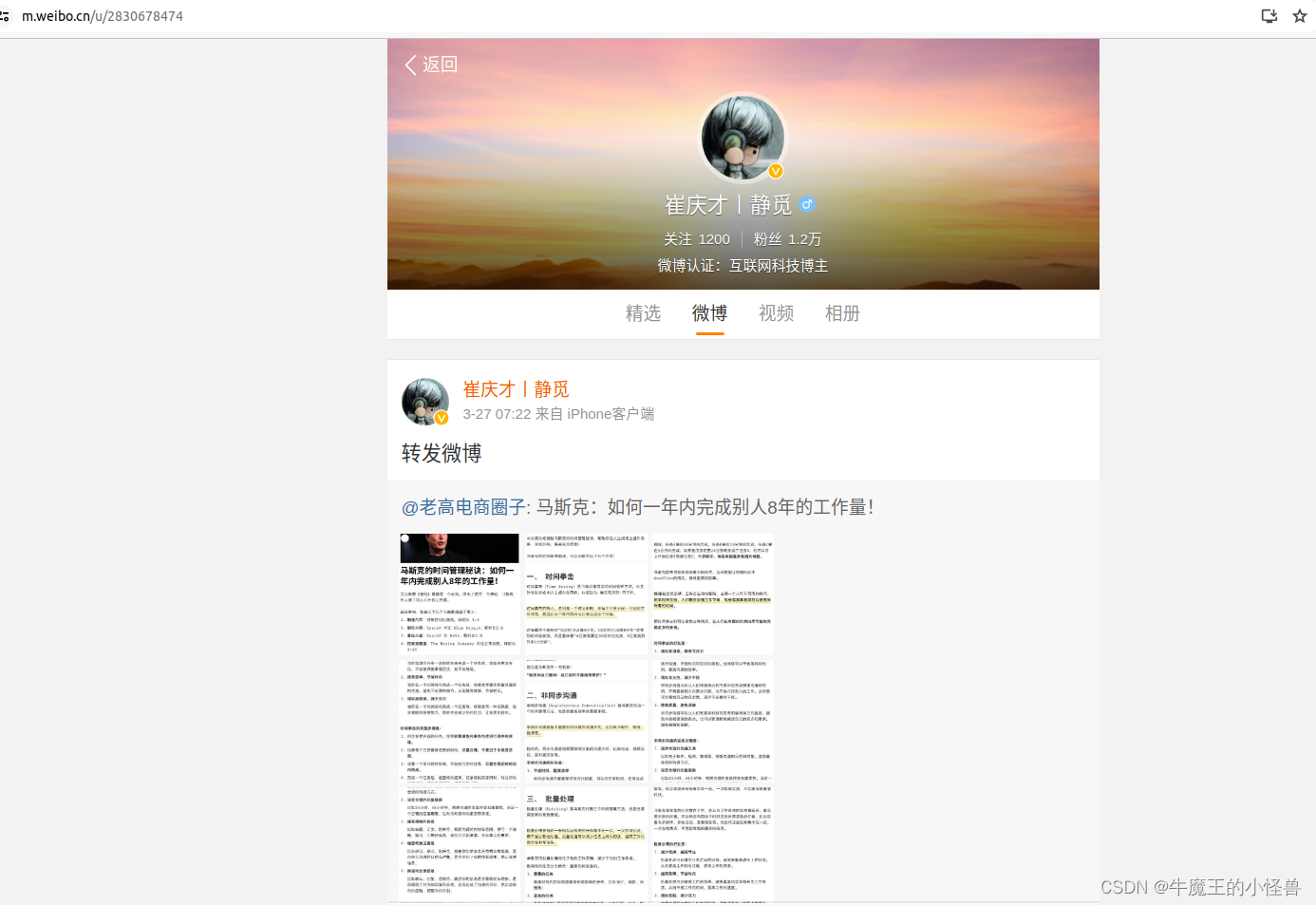
- 首先通过浏览器,打开个人微博主页 https://m.weibo.cn/u/2830678474,
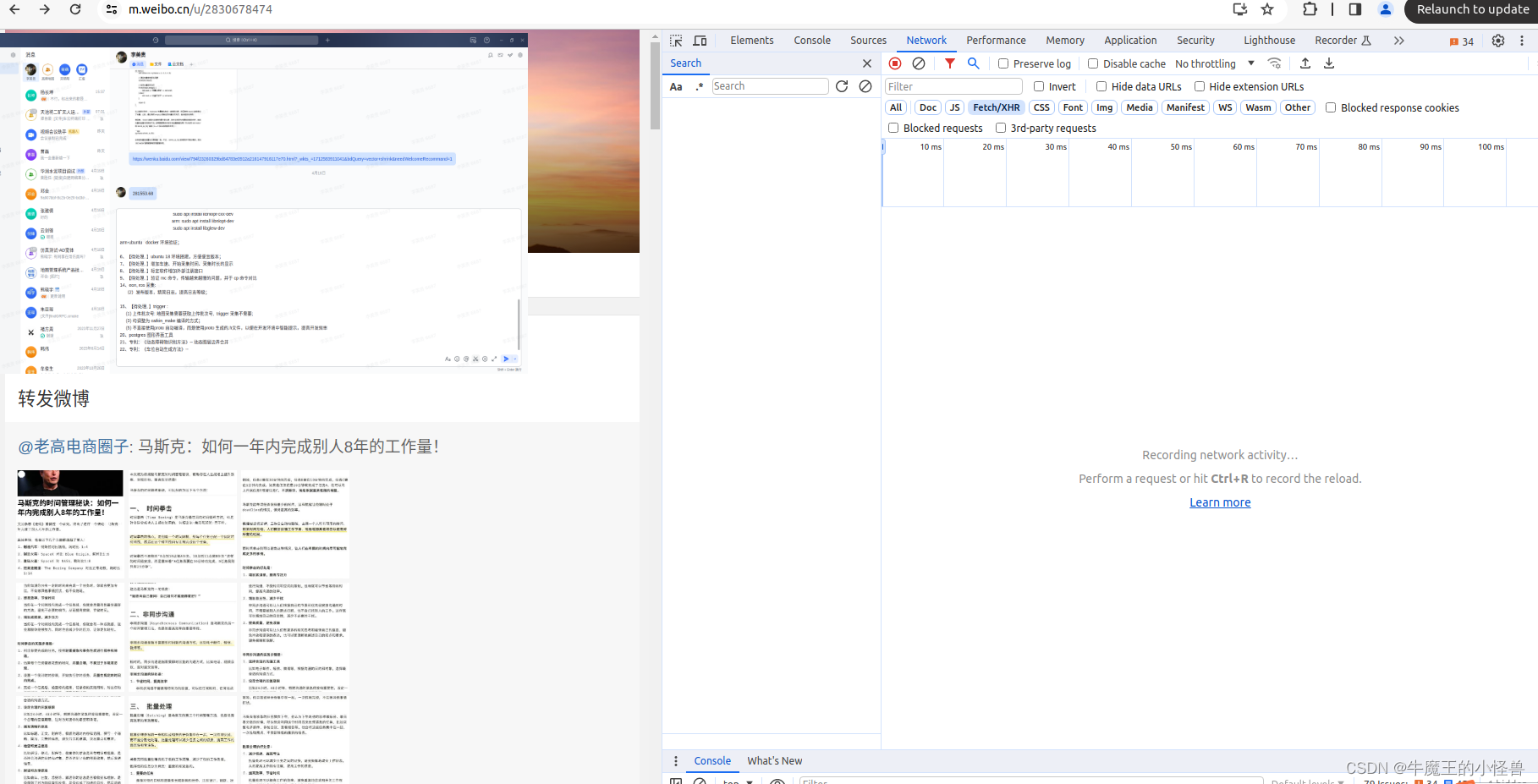
- [x]按下F12,就会出现网页的js语言设计部分,找到网页上的Network部分。并选中“放大镜(过滤)”,如下图所示:
- 然后按下ctrl+R刷新页面,此时发现右边 NetWork 部分出现很多信息。(如果进入后就有所需要的信息,就不用刷新了),当然刷新了也没啥问题。

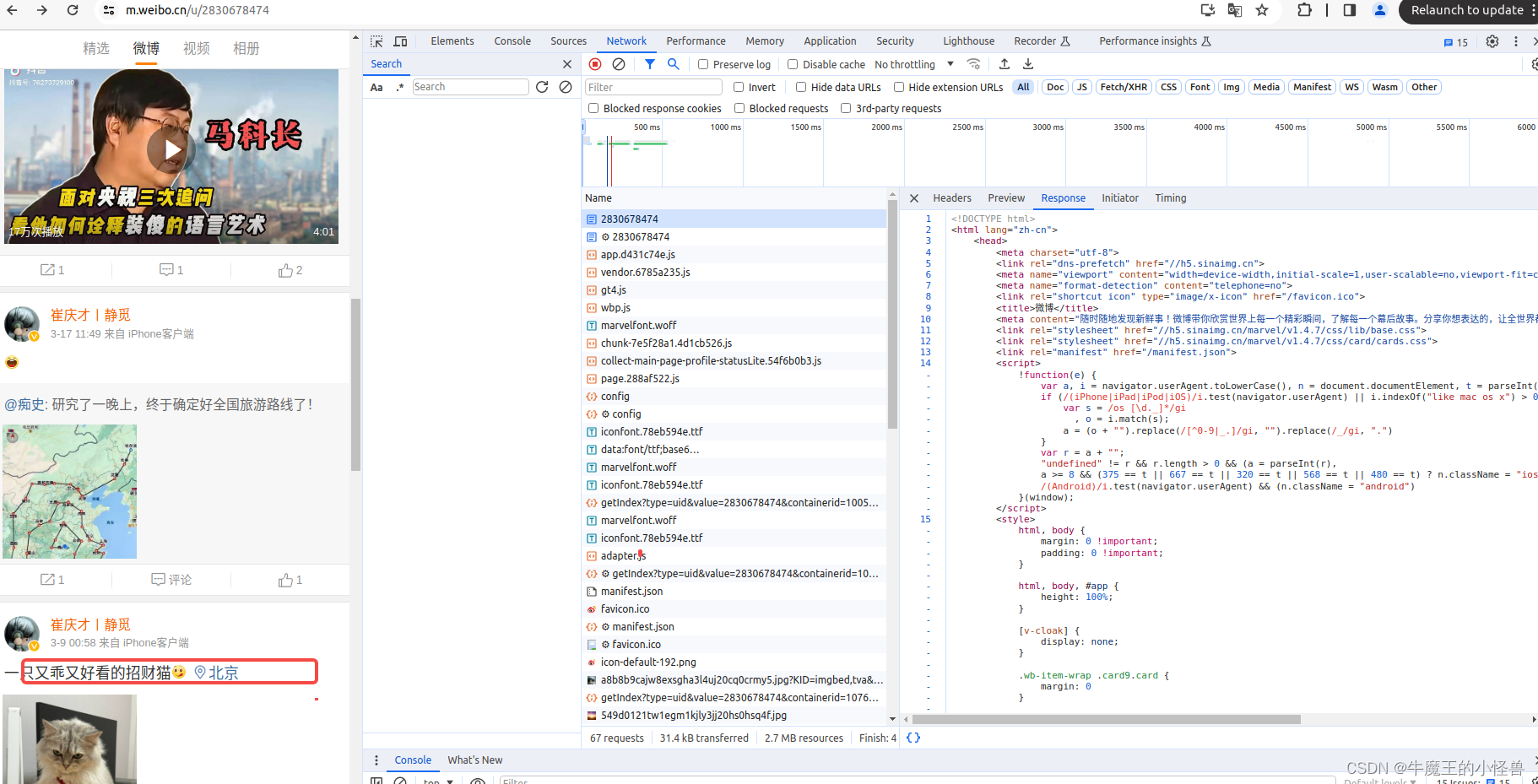
- 在选中放大镜后的输入框中,输入其中一个关注的信息,比如:马斯克,或者 招财猫,通过 放大镜 搜索 功能,搜索自己关注的信息,并点击 ”刷新按钮“,在Search 结果中,并没有显示相关的信息
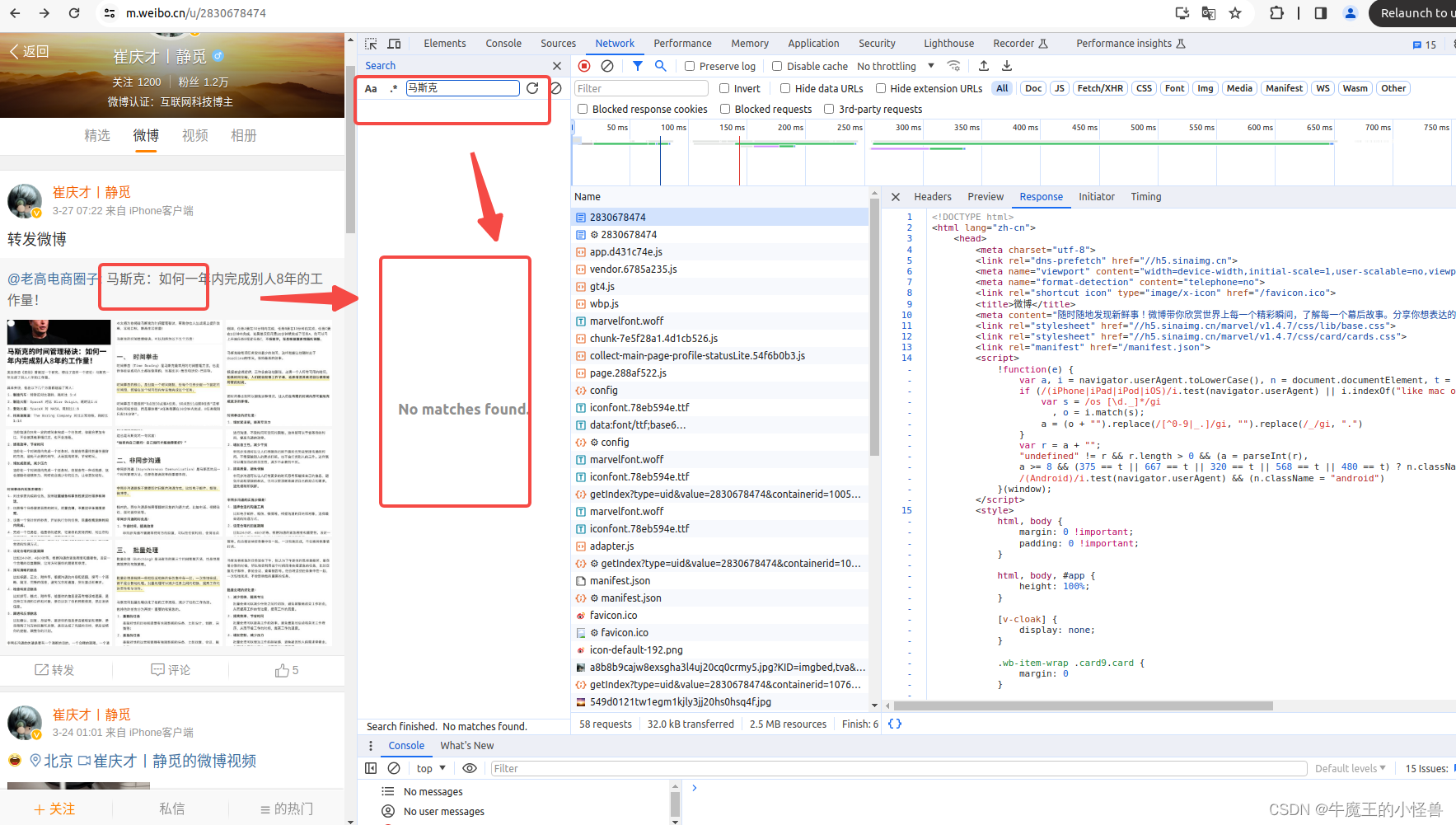
在Name列,选中第一条结果数据,观察 Response,并不是微博页面显示的真是数据,而是后来执行 JavaScript 后再次向后台发送了 Ajax请求采获取到了数据。
通过浏览器的开发者工具中,选中 XHR,可以过滤出所有的 Ajax 请求相关的数据。
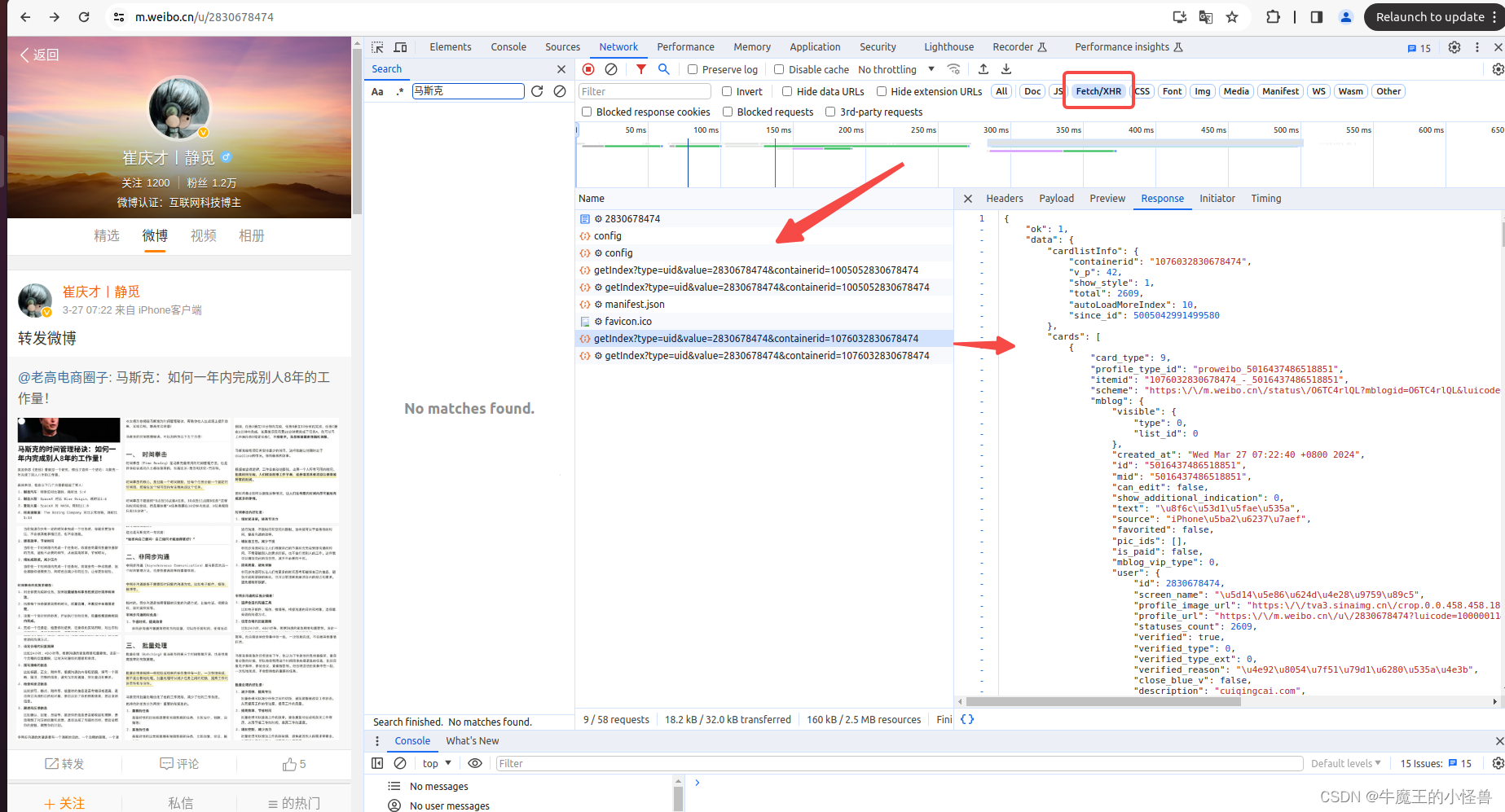
-
拷贝其 cURL 信息
在 Network --> Filter 中,关键信息进行过滤后(如:输入 2830678474),我们浏览Name这部分,找到我们想要爬取的文件(网络信息),鼠标右键,选择copy,复制下网页的URL。
过滤后,有效信息会少很多,如下所示。选中所需的条目,右键 --> Copy --> Copy as cURL
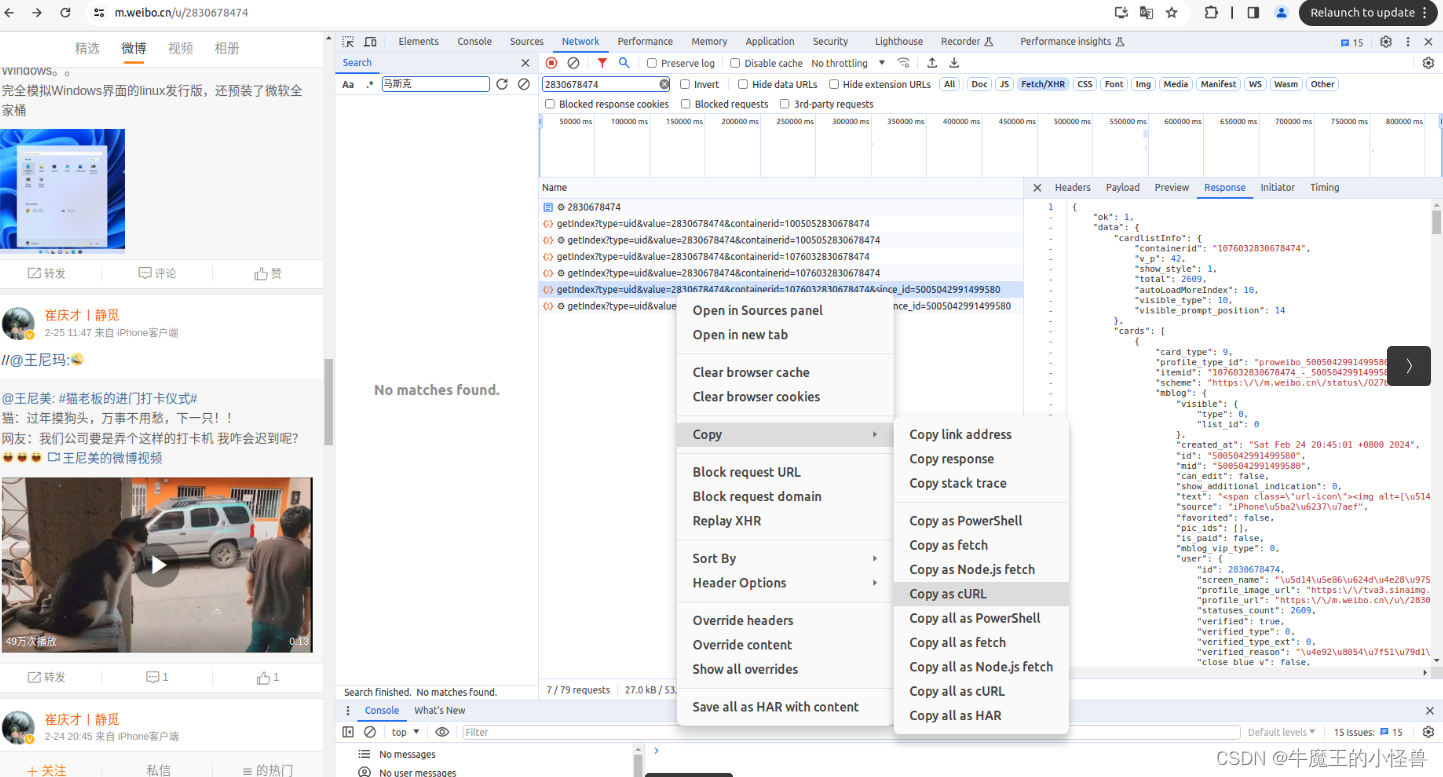
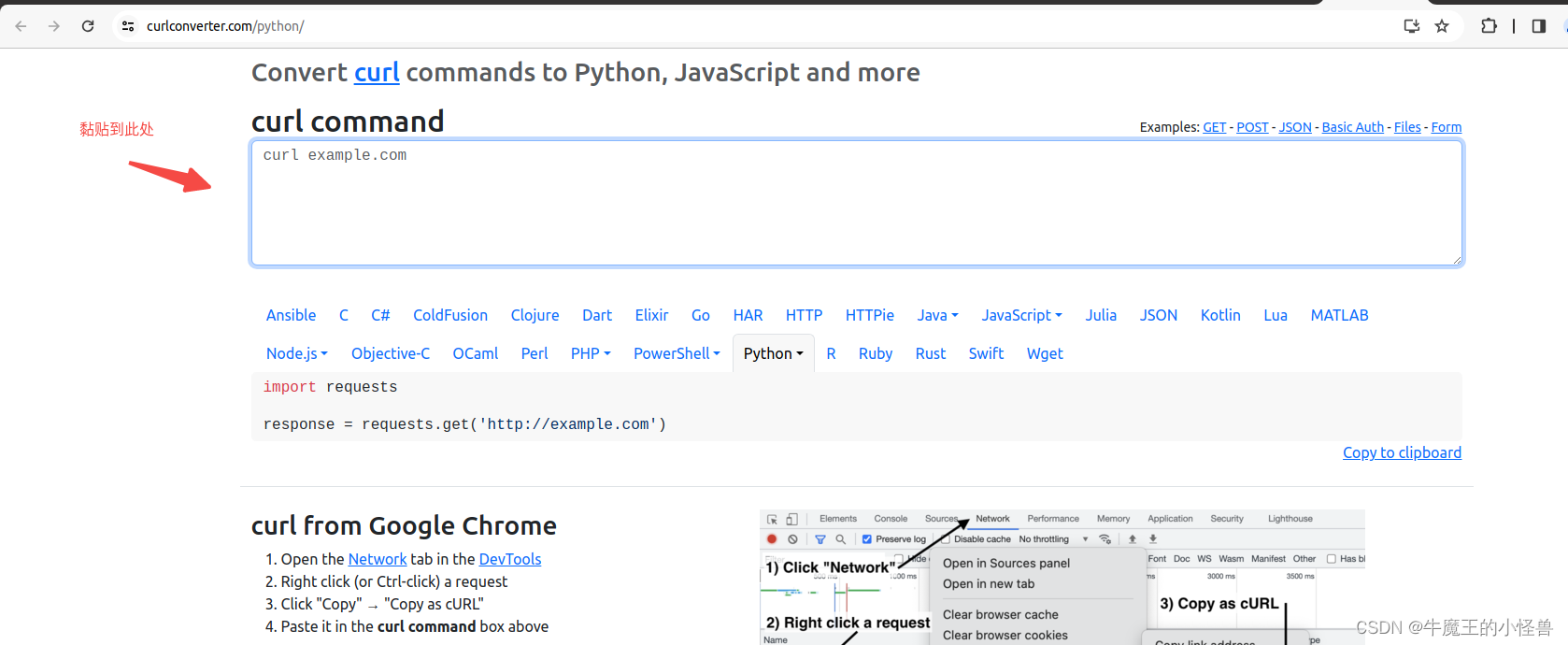
- 利用工具 Convert curl commands to code https://curlconverter.com/python/ 进行转换
curl 'https://m.weibo.cn/api/container/getIndex?type=uid&value=2830678474&containerid=1076032830678474&since_id=5005042991499580' \
-H 'sec-ch-ua: "Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"' \
-H 'X-XSRF-TOKEN: 6474f0' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' \
-H 'Accept: application/json, text/plain, */*' \
-H 'MWeibo-Pwa: 1' \
-H 'Referer: https://m.weibo.cn/u/2830678474' \
-H 'X-Requested-With: XMLHttpRequest' \
-H 'sec-ch-ua-platform: "Linux"' \
--compressed
转换后信息如下图所示,选择【Copy to clipboard】,并黏贴到Pycharm开发环境中即可直接使用:
转换后信息如下图所示,请关注: header 中的 ‘X-Requested-With’: ‘’, 传输格式为: XMLHttpRequest。 这也标记了此请求就是 Ajax 请求。
选择【Copy to clipboard】,并黏贴到Pycharm开发环境中即可直接使用:
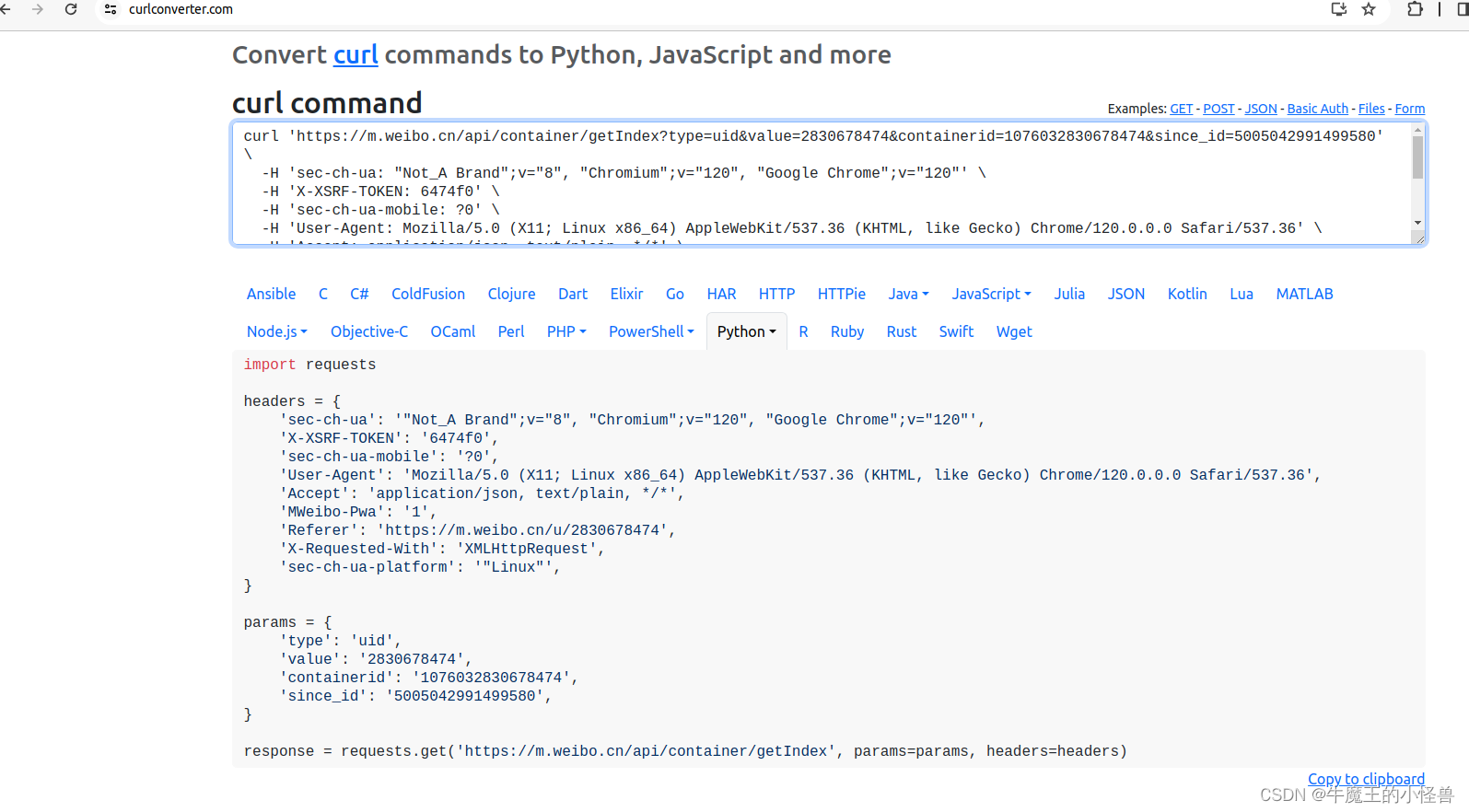
选择【Copy to clipboard】, 拷贝到 pycharm 中,可直接作为源代码使用:
import requests
headers = {
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
'X-XSRF-TOKEN': '6474f0',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
'MWeibo-Pwa': '1',
'Referer': 'https://m.weibo.cn/u/2830678474',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-platform': '"Linux"',
}
params = {
'type': 'uid',
'value': '2830678474',
'containerid': '1076032830678474',
'since_id': '5005042991499580',
}
response = requests.get('https://m.weibo.cn/api/container/getIndex', params=params, headers=headers)
3. 第三步:获取网页
通过requests.get() 即可获取网页内容:
response = requests.get('https://m.weibo.cn/api/container/getIndex', params=params, headers=headers)
print(f'response= {response}')
print(f'response.text= {response.text}')
print(f'response.json= {response.json()}')
4. 第四步:解析网页
由于 get 的结果,就是 json 数据,所以后续只需要针对 json格式进行解析即可:

格式化后应答数据内容如下:
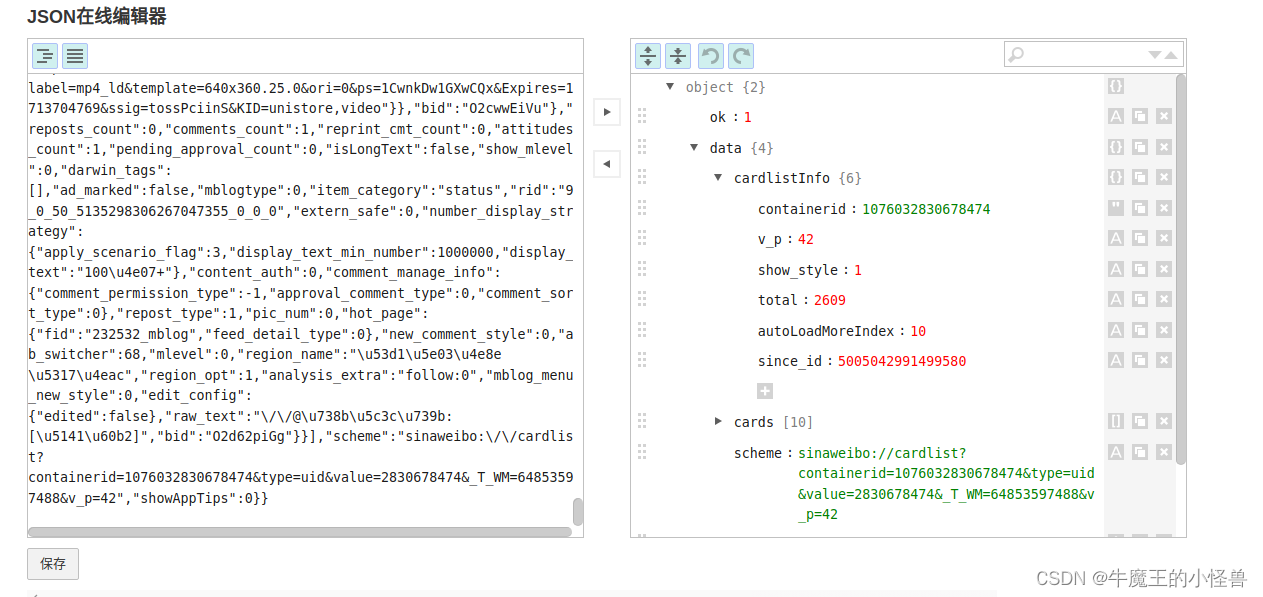
5. 第五步:解析 json 结构数据体
json_content = response.json()
print(f'json_content.ok = {json_content["ok"]}')
print(f'json_content.data.showAppTips = {json_content["data"]["showAppTips"]}')
print(f'json_content.data.cardlistInfo.total = {json_content["data"]["cardlistInfo"]["total"]}')
for item in json_content["data"]["cards"]:
print(f'itemid = {item["itemid"]}, '
f'scheme = {item["scheme"]} ')
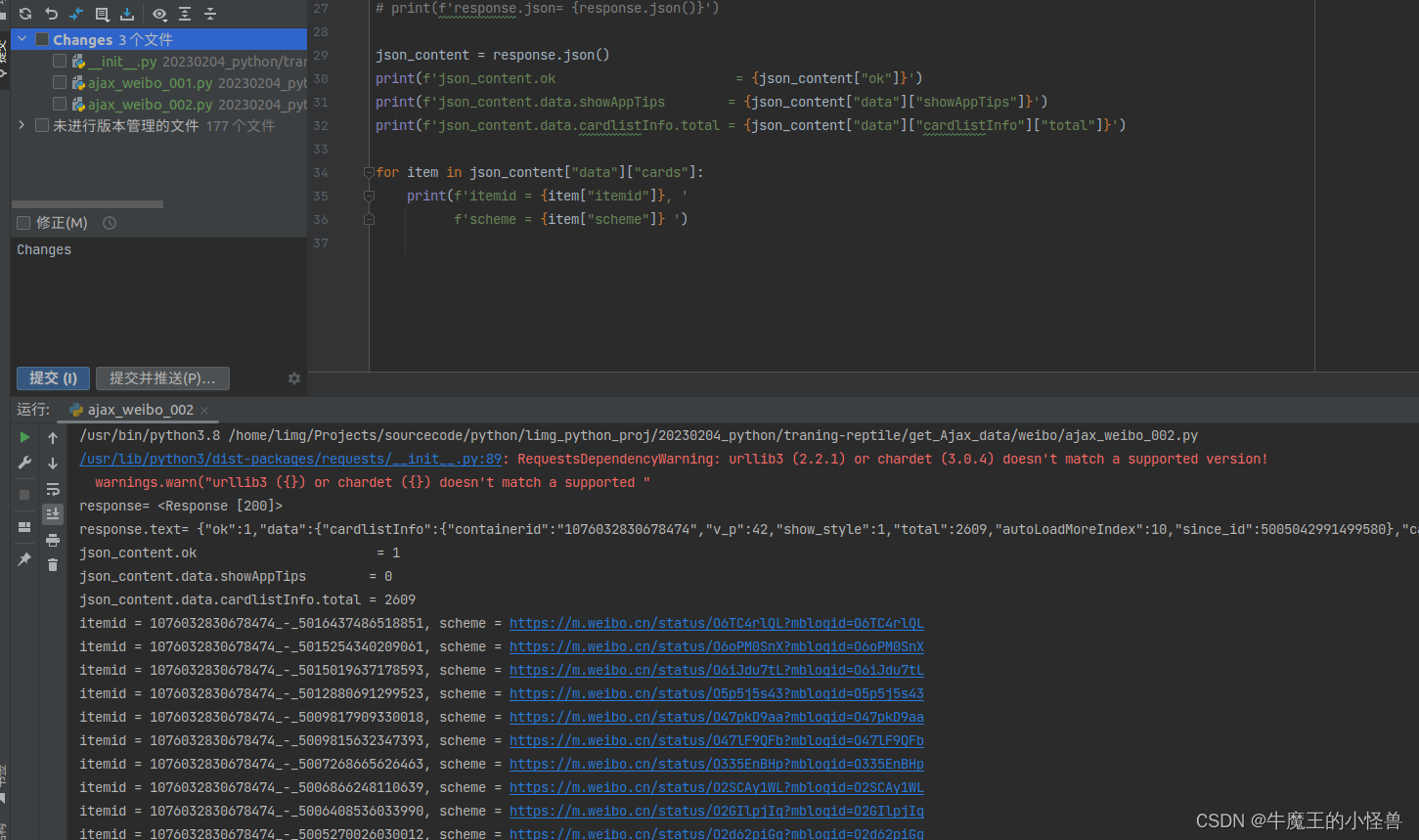
6. 代码实例以及结果展示
import requests
headers = {
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
'X-XSRF-TOKEN': 'c42512',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
'MWeibo-Pwa': '1',
'Referer': 'https://m.weibo.cn/u/2830678474',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-platform': '"Linux"',
}
params = {
'type': 'uid',
'value': '2830678474',
'containerid': '1076032830678474',
}
response = requests.get('https://m.weibo.cn/api/container/getIndex', params=params, headers=headers)
print(f'response= {response}')
print(f'response.text= {response.text}')
# print(f'response.json= {response.json()}')
json_content = response.json()
print(f'json_content.ok = {json_content["ok"]}')
print(f'json_content.data.showAppTips = {json_content["data"]["showAppTips"]}')
print(f'json_content.data.cardlistInfo.total = {json_content["data"]["cardlistInfo"]["total"]}')
for item in json_content["data"]["cards"]:
print(f'itemid = {item["itemid"]}, '
f'scheme = {item["scheme"]} ')
















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











