






就在昨日,DeepSeek团队发布最新论文《洞察 DeepSeek-V3:规模的挑战和对AI架构硬件的思考》,首次系统性公开了其在大模型训练与推理中实现成本效益的“软硬协同”方法论。论文从硬件架构与模型设计的双重视角出发,揭示了如何通过技术协同突破内存、计算和通信瓶颈。该论文章节的主要包含5个章节内容:
1. DeepSeek 模型的设计原则;
2. 低精度驱动设计;
3. 以互联为驱动的设计;
4. 大规模网络驱动设计;
5. 面向未来的硬件架构设计。

1、DeepSeek 模型的设计原则
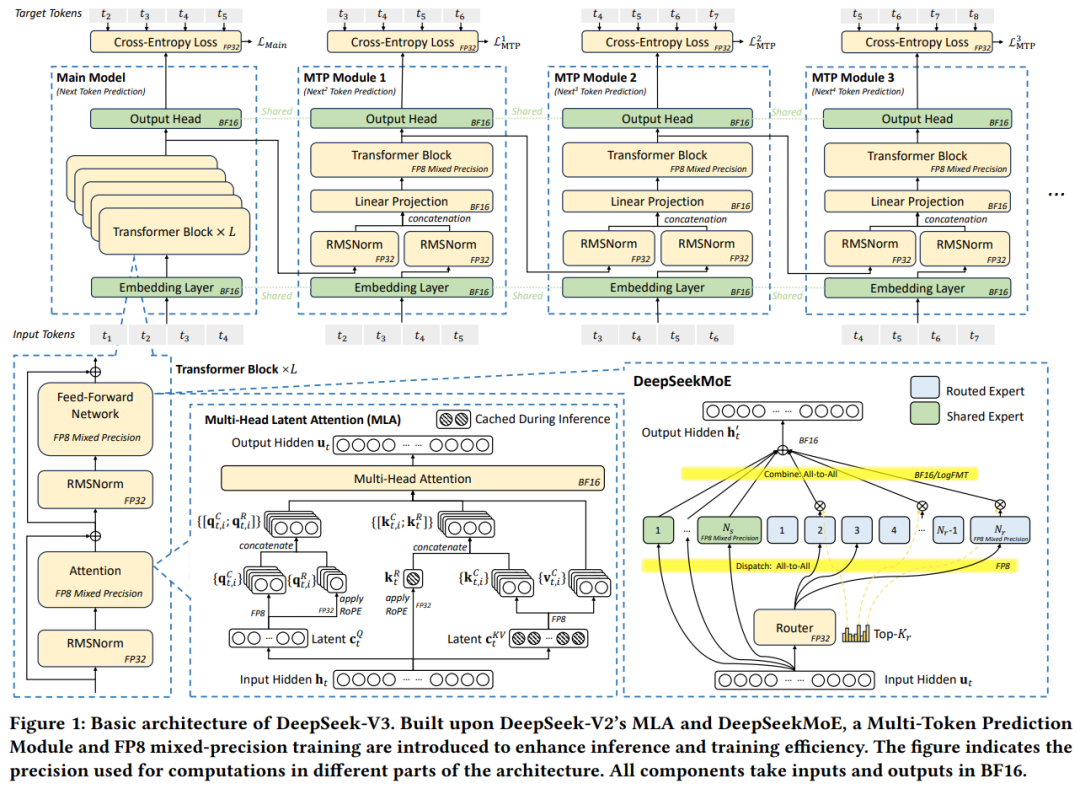
DeepSeek-V3的设计以“硬件导向”为核心,通过算法与系统的深度协同优化,实现性能与成本的平衡。其核心架构包括:
(1)多头潜在注意力(MLA):通过投影矩阵压缩键值(KV)缓存,将每个token的KV缓存从传统模型的数百KB降至70KB,显著降低内存占用。
(2)混合专家(MoE)架构:总参数量达6710亿,但每个token仅激活37亿参数,减少计算需求。相比密集模型(如LLaMA-3.1 405B),计算成本降低一个数量级。
(3)流水线优化:采用双微批处理重叠技术,将计算与通信解耦,减少GPU空闲时间,提升吞吐量。
这一设计原则的目标是解决大模型训练的三大核心挑战:内存效率、成本效益、推理速度
2、低精度驱动设计
低精度计算是DeepSeek-V3成本优化的关键技术突破:
FP8混合精度训练:首次在MoE模型中实现FP8训练框架,通过细粒度量化策略(激活按1×128分块、权重按128×128分块),将内存消耗降低50%,同时精度损失控制在0.25%以内。
硬件适配挑战:现有硬件(如NVIDIA Hopper)的FP8累积精度不足,导致训练稳定性问题。团队提出未来硬件需支持可配置累积精度(如FP32)和原生细粒度量化的矩阵乘法单元。
通信压缩优化:在专家并行(EP)阶段,使用FP8量化传输token,通信量减少50%,并通过LogFMT等实验探索进一步压缩潜力。
3、以互联为驱动的设计
针对硬件互联瓶颈(如NVIDIA H800的NVLink带宽受限至400GB/s),DeepSeek-V3提出多项优化:
并行策略调整:训练阶段禁用张量并行(TP),转而增强流水线并行(PP)与专家并行(EP),利用8×400G InfiniBand网卡实现跨节点高速通信。
节点限制路由(Node-Limited Routing):通过算法将专家分组部署到同一节点内,减少跨节点通信次数。例如,256个专家分为8组,每组部署于单节点,使跨节点通信流量降低至原成本的1/4。
网络拓扑优化:采用双层多平面Fat-Tree网络,替代传统三层结构,降低集群网络成本并提升扩展性。
4、大规模网络驱动设计
为支撑超大规模训练(2048个H800 GPU),DeepSeek-V3构建了创新的网络架构:
多平面Fat-Tree(MPFT)拓扑:每个节点的8个GPU与8个IB网卡分别连接独立网络平面,理论上支持16,384块GPU的扩展,网络成本较传统三层结构降低40%以上。
通信与计算重叠:通过双流推理策略,将不同微批次的通信与计算任务并发执行,最大化硬件利用率。
5、面向未来的硬件架构设计
论文对未来AI硬件的发展提出了关键建议:
低精度计算单元:需支持FP8等格式的原生细粒度量化,并改进累加器精度(如FP32)以提升训练稳定性。
通信协处理器:引入专用硬件处理网络流量,卸载GPU的计算负载,并支持跨纵向/横向网络的灵活数据转发。
同步原语优化:硬件需提供细粒度的同步指令,减少基于软件的同步延迟。
总结:技术协同的行业启示
DeepSeek-V3的实践表明,软硬协同设计是突破大模型成本瓶颈的核心路径。其通过MLA、MoE、FP8与网络优化的多维度创新,将训练资源需求降至2048个H800 GPU,为中小团队提供了竞争可能性。未来,硬件厂商需响应算法需求,推动低精度计算、高带宽互联等技术的迭代,进一步释放AI规模化潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









