






 本文介绍了如何使用Pandas库中的pivot_table()函数创建数据透视表,以及crosstab()函数进行交叉表统计,以分析销售数据和按地区、国籍等维度的汇总。通过实例演示了如何计算地区销售和利润,以及根据不同变量的频数统计.
本文介绍了如何使用Pandas库中的pivot_table()函数创建数据透视表,以及crosstab()函数进行交叉表统计,以分析销售数据和按地区、国籍等维度的汇总。通过实例演示了如何计算地区销售和利润,以及根据不同变量的频数统计.
1. 数据透视表
pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),pivot_table函数可以产生类似于excel数据透视表的结果,相当的直观。其中参数index指定“行”键,columns指定“列”键。
函数形式:
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True)

【例】:对于DataFrame格式的某公司销售数据workdata.csv,存储在本地的数据的形式如下,请利用Python的数据透视表分析计算每个地区的销售总额和利润总额。
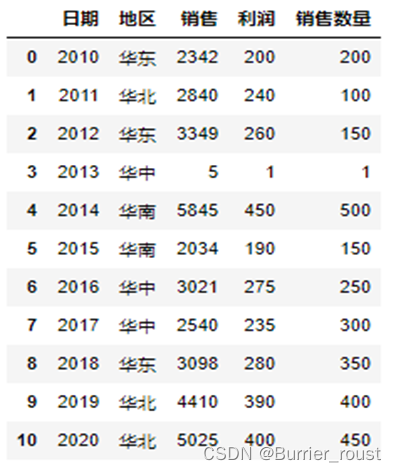
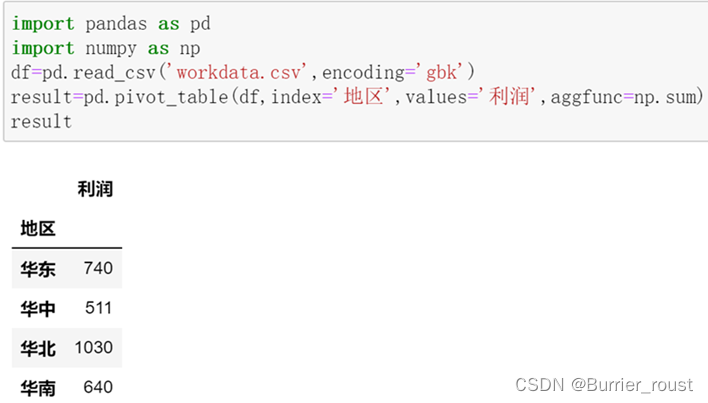
关键技术:在pandas中透视表操作由pivot_table()函数实现,其中在所有参数中,values、index、columns最为关键,它们分别对应Excel透视表中的值、行、列。程序代码如下所示:
2 .交叉表
交叉表采用crosstab函数,可是说是透视表的一部分, 是参数aggfunc=count情况下的透视表。crosstab函数 可以按照指定的行和列统计分组频数。
函数形式:
pd.crosstab(index,columns,values=None,rownames=None,colnames=None,aggfunc=None,margins=False,margins_name:str='All',dropna: bool = True,normalize=False)

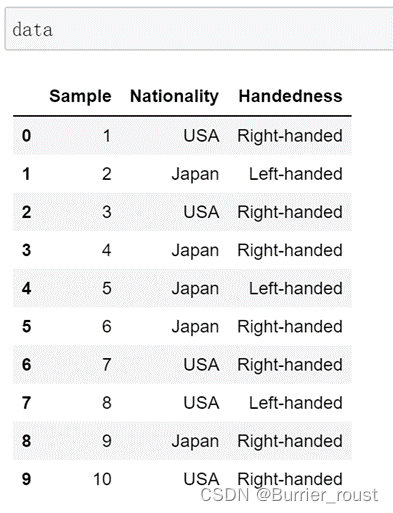
【例】:根据国籍和用手习惯对这段数据进行统计汇总。
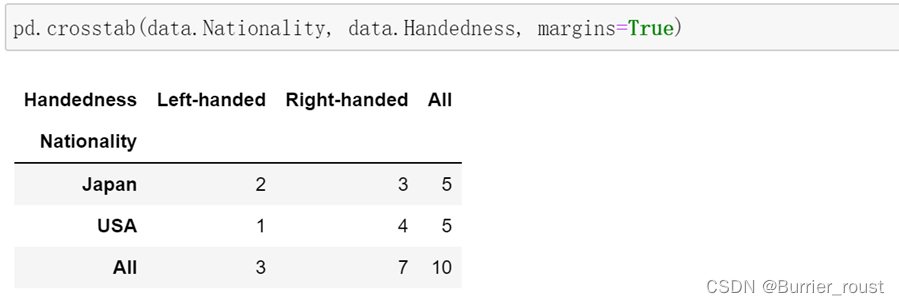
关键技术:频数统计时,使用交叉表(crosstab)更方便。传入margins=True参数(添加小计/总计),将会添加标签为ALL的行和列。
首先给出数据集:
对不同国家的用手习惯进行统计汇总:


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











