





DoorDash 是一家美国科技公司,主要提供在线食品配送服务。该公司成立于 2013 年,由斯坦福大学的三名学生共同创立。最初是在斯坦福大学校园内启动的一个小项目,后来迅速扩展到全美各大城市,甚至国际市场。
此前,DoorDash 依赖 Postgres 作为主要数据存储,并使用 Python Django 数据库模型来定义数据结构。默认情况下,会自动添加一个自增的整数 ID 作为主键作为主键,其上限约为 21 亿(2^31-1)。但是,为了支持业务的快速增长,我们需要在 Integer ID 范围用完之前将数据模型从 Integer 转换成 BigInt,以避免整数溢出。虽然我们能够在不停机的情况下完成主键数据类型的升级,但仍需要确保系统和 BigInt 升级完全兼容。
升级到 BigInt 的兼容性挑战
要使用超过 Integer 的 ID,我们需要将表的主键和引用主键的其他表升级到 BigInt。此外,使用升级后表的应用程序必须能够正确插入和接受超出 Integer 限制的数据。在我们开始向系统全面推广 BigInt 之前,我们需要解决以下一些挑战:
表之间的交叉引用并不总是存在外键约束
在升级表中的主键数据类型时,我们还需要升级有引用升级后主键的字段的其他表,例如,在更新后的主键上有外键的表。但是,有些表只是定义了一个普通字段,而没有使用外键约束来引用升级后的主键。在我们的案例中,当订单表中的订单 ID 下传给另一个服务时,订单 ID 被保存为一个普通字段,在其表中的命名为 target_id。这种缺乏外键约束的引用形式使得它们很难被准确识别和处理。
难以检测采用微服务架构的后端应用程序是否正确处理了 ID
没有简单的方法可以验证应用程序的代码能否正确处理新的 ID 数据类型。特别是对于在微服务架构下跨域使用的数据,不同的流是在孤立的服务中运行的。很难说清楚升级后的表 ID 是如何流动的,以及使用 ID 的服务内部是如何处理的。例如,如果 ID 的数据类型在服务间的 API 请求和响应中被定义为 Integer,或者如果代码中存在从 Long 到 Integer 的数据类型转换,那么当我们开始在任何表中使用超过 Integer 范围的 ID 时,都可能导致代码异常或数据不正确。
确保所有客户端平台和版本的兼容性
类似的数据类型不兼容问题也可能发生在面向用户的客户端上,例如我们的 Android、iOS 和 Web 应用程序。例如,如果客户端应用程序定义了一个带有整数 ID 的数据对象来接收来自后端的响应,那么当后端返回的响应的 ID 超过整数范围时,客户端将无法工作。此外,我们还必须确保不仅是未来版本的客户端能够适配 BigInt 类型的更新,即便是旧版本的应用也需保持良好的兼容性。这要求我们在更新过程中充分考虑并解决所有潜在的兼容性问题。
通过额外的 PostgreSQL 序列控制数据生成,来发现潜在的兼容性问题
我们开发了一种解决方案,可以在小规模用户中试验性地使用 BigInt,以便在推广到所有用户之前发现兼容性问题。以下是具体流程:
- 创建了一个额外的 PostgreSQL 序列,这个序列的起始 ID 设置在 Integer 上限之上,并与主键数据类型升级后的表关联。
- 开发一段新的代码,专门使用新序列插入超出 Integer 范围的数据。
- 在小规模用户中推广新代码,以发现并解决使用超出 Integer 范围的 ID 时可能出现的问题,而在 Integer 范围内的 ID 的原始序列则继续处理其他用户的数据请求。
- 一旦验证新序列的可靠性,我们便将其设为相关数据表的默认序列。
步骤 1:为已升级至 BigInt 的数据表创建新的序列
表中主键和其他引用表中列的数据类型从 Integer 升级到 BigInt 后(如何升级表中列的数据类型是另一个大话题,但不是本博客的重点),这些表就能处理超出 2^31-1 的数据量。为此,我们设立了一个新的序列,其起始 ID 设定在整数上限之上。我们选定的新起始点是 2^32。介于 2^31 和 2^32 -1 之间的值在截断为 32 位有符号整数时,会缠绕在一起并变成负数。如果我们没有在溢出前及时为所有系统做好准备,负整数可能是一个宝贵的逃生口。下面的示例展示了我们如何创建序列:
CREATE SEQUENCE __bigint_tablename_id_seq START WITH 4294967296;
步骤 2:使用两个不同的序列向同一个表插入数据
我们继续使用与表相关联的原始默认序列,为公共流量生成 Integer 范围内的主键。同时,我们创建了一个新的并行代码路径,在向表中插入记录时,专门使用步骤 1 中的新序列来生成超出 Integer 限制的 ID。我们设置了一个实验,用于决定在数据插入前采用哪个代码路径。具体流程如下图 1 所示。
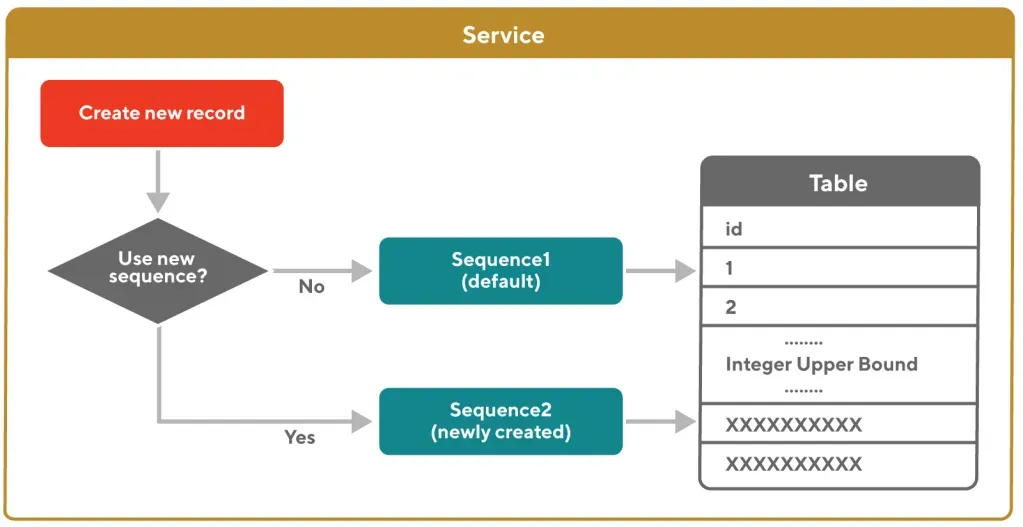
图 1 展示了我们如何根据是否使用新序列,采用不同序列为 ID 插入数据,涉及到的数据类型范围也不同。
下面的代码示例展示了我们如何在基于 Kotlin 的微服务中使用 JDBI 与数据库交互,实现图 1 的流程。
@GetGeneratedKeys
@SqlUpdate("insert into $sampleTable ( $insertColumns ) values ( $insertValues )")
fun create(@BindKotlin obj: DBObj): Long
我们最初使用上面的查询来插入新数据,其中 $insertColumns 和 $insertValues 不包括 ID 列及其值,因此它将由与表关联的默认序列自动生成。默认序列生成的 ID 在整数范围内。
@GetGeneratedKeys("id")
@SqlUpdate("insert into $sampleTable ( $insertColumnsWithId ) values ( $insertValuesWithIdInNewSequence )")
fun createWithIdInNewSequence(@BindKotlin obj: DBObj): Long
同时,我们定义了上述的新界面,以便在插入新数据时指定 ID 值。这个指定的 ID 值是从我们创建的新序列中生成的。在查询中,insertColumnsWithId = ":id, $insertColumns" 以及 insertValuesWithIdInNewSequence = "nextval('__new_sampletable_id_seq::regclass), $insertValues"。
而 nextval('__new_sampletable_id_seq::regclass) 用于从新序列中获取下一个值。在这种情况下,我们将从该接口插入的数据 ID 超过了 Integer 的限制,因此我们可以测试系统处理 BigInt 的能力。
我们进行了一次实验,以选择在系统中插入数据时使用哪个序列。选择新序列后,我们就可以使用超出 Integer 范围的 ID 插入数据了。
if(User in experiment){
createWithIdInNewSequence(obj)
} else{
create(obj)
}
步骤 3:通过插入超出整数范围的数据来检测潜在问题
如步骤 2 所述,在确认所有流量和应用程序都能处理 BigInt 升级之前,我们保留了默认的当前 ID 序列,以便为公共流量提供服务。同时,我们开始分批让内部用户试用新的序列代码,并对任何异常情况进行监控。
在我们逐步推广过程中,我们检测到了以下几个问题:
由于应用程序接口将请求/响应的 ID 定义为整数,导致升级主键的读取失败
虽然我们成功地将 ID 大于整数范围的数据插入到了表中,但一些 API 无法检索到这些数据,因为 API 请求只接受整数 ID。要修复此类错误,我们只需将请求或响应中的参数类型从 Integer 升级为 Long,从而修复有问题的端点。
引用表的写入失败,因为引用表未升级
从下达订单到交付订单,复杂的数据会流经不同的服务,这些服务会将所需数据持久化到各自的数据库中。在测试推广期间,我们收到下游服务的报告,称由于从我们的表中引用了一个 ID,导致数据持久化到他们的表中失败。
结果发现,我们没有将他们表中的引用列(不使用主键)升级到我们的 BigInt 升级表。他们表中引用我们升级后主键的列仍然是 Integer 格式,这导致在新序列生成引用 ID 时无法向他们的表中写入数据。我们通过升级引用列数据类型,使其与升级后的 BigInt 表保持一致,修复了这些被忽略的表。
由于 ID 向下转换操作没有适当的错误提示,导致错误的 ID 被错误地保存到了表中
从 BigInt 新序列中成功写入和读取数据还不够,我们还需要确认数据的正确性。例如,其中一个团队有一个 ETL 作业,要将事务表中的数据与订单表中的订单 ID 关联起来,以生成一份数据报告。ETL 任务正在运行一个结构如下的查询:
select * from order o
join transaction t on t.order_id = o.id
where …..
虽然订单表和事务表中订单 ID 的数据类型都已升级为 BigInt,但仍有一行代码将原始订单 ID 从 Long 向下转换为 Integer,并将结果持久化到事务表中。
这个 Long.toInt() 数据类型转换操作可以无误执行。但结果值由该 Long 值的最小有效 32 位展示。因此,从新序列生成的数据可以成功写入和读取,但并不正确。由于数据类型的错误转换,在我们修复之前,ETL 作业无法获得预期的结果!
步骤 4:将新序列切换为表的默认序列
解决了步骤 3 中的所有问题后,当 ID 开始超过整数范围时,我们确信我们的系统是兼容的。最后要做的是用新序列替换默认的原始序列,作为我们的默认 ID 生成器。这是必要的,因为尽管原始序列可以生成大于整数范围的 ID,但它并不知道整数范围之外的部分 ID 已被新序列占用。在两个序列重叠之前,我们只需要使用新序列。因此,我们将新序列作为默认值与表关联,并放弃了原始序列。
到此为止,Bigint 升级的迁移工作顺利完成,我们的系统可以支持超出整数范围的 ID。
结论
本文介绍了在 Postgres 表 BigInt 升级过程中添加额外序列来检测兼容性问题的技术,确保整个升级过程无漏洞。BigInt 的迁移是一项公司级的重大任务,涉及从底层数据存储到应用程序兼容性的多个方面,都可能带来不小的挑战。最近的一篇博客建议,默认情况下采用 BigInt,同时检测是否配备了适当硬件的生产数据库能否有效地处理这一变更带来的额外开销。如果您正在考虑执行 BigInt 升级,希望本文提供的策略和经验能帮助您识别并解决潜在的兼容性问题。
💡 更多资讯,请关注 Bytebase 公号:Bytebase















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









