






MPI提供四种通讯模式:
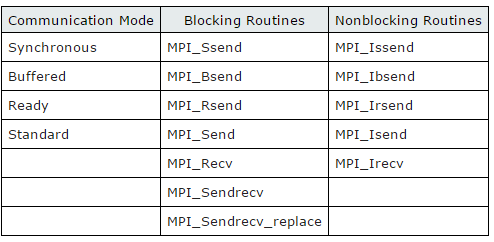
“MPI defines four communication modes which are selected via the specific SEND routine used. The communication mode instructs MPI on the algorithm that should be used for sending the message: synchronous, buffered, ready, or standard. Choice of the mode is separate from the selection of blocking/nonblocking; in other words, each communication mode can be applied to either a blocking or a nonblocking send. It should be noted that the RECV routine does not specify the communication mode—it is simply blocking or nonblocking. The table below provides the names of the MPI routines corresponding to each communication mode.”
决定使用何种通讯模式,主要考虑是overhead, 即进程中多少时间将用来等待blocking send or receive 返回。每种模式有不同的overhead特点。overhead 通常有两个来源:
1) 系统overhead-转移buffer内容花费的时间
2) 同步overhead-等待另一个进程花费的时间
System overhead is incurred from transferring the message data from the sender’s message buffer onto the network (directly or indirectly), and from transferring the message data from the network into the receiver’s message buffer. It’s worth noting that this overhead does not generally encompass waiting for the message to be received, just for the sender’s buffer to be clear.
Synchronization overhead is the time spent waiting for an event to occur on another task. In certain modes, the sender must wait for the receive to be executed and for the handshake to arrive before the message can be transferred. The receiver also incurs some synchronization overhead in waiting for the handshake to complete. Synchronization overhead can be significant, not surprisingly, in synchronous mode. As we shall see, the other modes try different strategies for reducing this overhead.
This means that the speed of an MPI program is dependent on good network connections (low system overhead) and intelligent programming (low synchronization overhead). Generally speaking, MPI communications operate in what is known as the rendezvous protocol, which involves a handshake procedure in order to establish communication. This Flash animation illustrates this generalized procedure as well as showing how a pair of processes operate in concert to communicate with each other. Next, we’ll explore the 4 different communication modes that MPI provides, all of which perform slight modifications of the generalized procedure shown here.
(MPI程序性能依赖好的网络连接(低系统overhead)以及灵巧的编程(低同步overhead))
(一)Standard communication mode(标准通讯模式)
此种模式下,MPI 将决定是否缓存发出的消息。如果MPI缓存发出的消息,那么send操作能够在有匹配的接收操作前完成。换句话说,send能够在消息缓存之后立即返回,不管有没有匹配的接收操作。另一种情况是可能没有足够空间buffer,或者MPI选择不buffer消息,此时,send操作不会完成,直到有一个匹配的接收操作出现,并且数据被移动到接收器。
因此,标准模式下的send不管有没有匹配的接收操作都可以开始。它可以在有匹配的接收前完成。
消息缓存代价有时比较高,因为涉及到分配额外的存贮空间以及在内存间的拷贝操作。因此MPI提供了选择,程序员可以自己指定通讯模式。
”standard send, is actually the hardest to define. Its functionality is left open to the implementer in the MPI-1 and -2 specifications. The prior MPI communication modes are all defined explicitly, so the developer knows exactly what behavior to expect, regardless of the implementation or the computational platform being used. Standard send, however, is intended to take advantage of specific optimizations that may be available via system enhancements.
In practice, one finds that standard-mode communications follow a similar pattern in most MPI implementations, including those available on Stampede. The strategy is to treat large and small messages differently. As we have seen, message buffering helps to reduce synchronization overhead, but it comes at a cost in memory. If messages are large, the penalty of putting extra copies in a buffer may be excessive and may even cause the program to crash. Still, buffering may turn out to be beneficial for small messages.
A typical standard send tries to strike a balance. For large messages (greater than some threshold), the standard send follows the rendezvous protocol , equivalent to synchronous mode. This protocol is safest and uses the least memory. For small messages, the standard send follows instead what is called the eager protocol. This protocol is like buffered mode, but the buffering is all done on the receiving side rather than the sending side, as shown below:“
(二)Buffered model(缓存模式)
此种模式下的send不管有没有匹配的接收都能够开始。在有匹配的接收之前,也可以完成。此种模式下最好明确的给buffer分配空间,MPI_Buffer_attach. 如果buffer溢出,则出错。
”Buffered mode incurs extra system overhead, because of the additional copy from the message buffer to the user-supplied buffer. On the other hand, synchronization overhead is eliminated on the sending task—the timing of the receive is now irrelevant to the sender. Synchronization overhead can still be incurred by the receiving task, though, because it must block until the send has been completed.
In buffered mode, the programmer is responsible for allocating and managing the data buffer (one per process), by using calls to MPI_Buffer_attach and MPI_Buffer_detach. This has the advantage of providing increased control over the system, but also requires the programmer to safely manage this space. If a buffered-mode send requires more buffer space than is available, an error will be generated, and (by default) the program will exit.“
(三)Synchronous model(同步模式)
此种模式下的send不管有没有匹配的接收都能够开始。然后,send只有在有一个匹配的接收操作时,并且接收操作开始接收发送的数据时,才能够成功完成。因此,同步模式的发送完成,首先暗示发送的buffer能够重新使用,其次暗示匹配的接收操作已经开始。
同步模式是最快的点到点通讯模式。因为sender要求receiver提供一个准备接收就绪的信号来触发send操作。
”Message transfer must be preceded by a sender-receiver “handshake”. When the blocking synchronous send MPI_Ssend is executed, the sending task sends the receiving task a “ready to send” message. When the receiver executes the receive call, it sends a “ready to receive” message. Once both processes have succesfully received the other’s “ready” message, the actual data transfer can begin.
In the diagram above, the sender is shown waiting for the receiver to become available, but this delay can also occur in the other direction. If the receiver posts a blocking receive first, then the synchronization delay will occur on the receiving side. Given large numbers of independent processes on disparate systems, keeping them in sync is a challenging task and separate processes can rapidly get out of sync causing fairly major synchronization overhead. MPI_Barrier() can be used to try to keep nodes in sync, but probably doesn’t reduce actual overhead. MPI_Barrier() blocks processing until all tasks have checked in (i.e., synced up), so repeatedly calling Barrier tends to just shift synchronization overhead out of MPI_Send/Recv and into the Barrier calls.“
(四)Ready model(就绪模式)
此种模式的发送只有在一个匹配的接收出现时才能开始,否则,操作出错并且给一个不确定的输出。
*Receive must initiate, before Send starts
*Lowest sender overhead (No Sender/Receiver handshake ,No extra copy to buffer )
”The ready send attempts to reduce system and synchronization overhead by assuming that a ready-to-receive message has already arrived. Conceptually this results in a diagram that is identical to that first used to describe the simple view of point-to-point communication:
The idea is to have a blocking send that only blocks long enough to send the data to the network. However, if the matching receive has not already been posted when the send begins, an error will be generated.
How does this mode compare with buffered-mode communication? For the sender, it obviously reduces system overhead by eliminating the extra data copy. For the receiver, however, it may increase synchronization overhead, since in general the receive must be posted earlier than in buffered mode. Moreover, if the receive is not posted soon enough, an error will be triggered that is detected only at the receiver and not by the sender, which can make successful handling of the error difficult. Due to the risk of generating such an error, it only makes sense to use ready mode when the logic of the program dictates that the receive must be posted first, e.g., if the message is the expected response to a query that was sent previously.“















 2247
2247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









