







不得不承认哈希表是一种效率很高的查找方法,理想的情况下它的时间复杂度为o(1),或者为一个常数。
当然,哈希查找的高效率也是有一定代价的,具体来说它是一种以时间换空间的查找算法,哈希表的构造需要合适的哈希函数,在构造哈希表时要分配跟多的空间来给记录,在记录发生冲突的时候,我们就需要一些冲突的处理方法。哈希表的构造过程也会因此更加复杂。
相关算法不一一例举了,书上和网上都有详细介绍,这里用链地址法来处理冲突,哈希地址相同的即冲突,接在链表尾部。
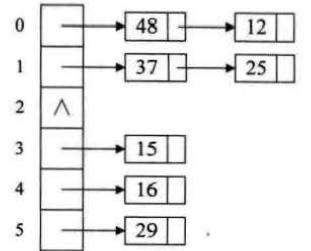
下面是c语言代码实现
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct Hnode{
struct Hnode *next;
ElemType data;
}HashNode;
typedef struct{
HashNode *hashtable; //哈希表基址,这里也可以用二维指针,但需要更多的地址空间
int hashsize; //哈希表容量
int count; //哈希表的当前元素个数
}Hashtable;
Hashtable *InitializeTable(int HASH_SIZE)
{//初始化哈希表
Hashtable* H;
H = (Hashtable*)malloc(sizeof(Hashtable)); //初始化表结构
if(NULL == H) return NULL;
H->count = 0;
H->hashsize = HASH_SIZE;
H->hashtable = (HashNode *)malloc(sizeof(HashNode)*H->hashsize);
if(!H->hashtable) return NULL;
for(int i=0; i<H->hashsize; i++)
{
H->hashtable[i].next = NULL; //H->hashtable[i]为每个分链表的头结点
H->hashtable[i].data = 0;
}
return H;
}
int hashfunction(ElemType key,int HASH_SIZE)
{//哈希函数,采用除留余数法
return key % HASH_SIZE;
}
HashNode* Find(ElemType key,Hashtable *H)
{//在哈希表中查找关键字
HashNode *h;
int addr = hashfunction(key,H->hashsize);
h = &H->hashtable[addr]; //求得哈希地址
if (H->hashtable[addr].data == 0) //没有记录
return NULL;
else if (H->hashtable[addr].data == key) //直接找到
return h;
else{ //记录冲突
HashNode *p = &H->hashtable[addr];
while (p != NULL)
{
p = p->next;
if (p == NULL)
return NULL;
else if (p->data == key)
return p;
}
return NULL;
}
}
void Insert(ElemType key,Hashtable *H)
{//在哈希表中插入元素
HashNode *h,*p;
int addr = hashfunction(key,H->hashsize);
if(H->hashtable[addr].data == 0) //没有插入关键字的表结点
{
H->hashtable[addr].data = key;
H->hashtable[addr].next = NULL;
}
else //记录相同,则插入分表中
{
HashNode *newnode = (HashNode *)malloc(sizeof(HashNode));
newnode->data = key;
newnode->next = NULL;
p = &H->hashtable[addr];
while(p->next !=NULL)
p = p->next;
p->next = newnode; //接在链表尾部
}
H->count++;
}
int main()
{
int a[13] = {15,26,18,32,66,14,108,40,17,31,53,16,44};
Hashtable *H;
H = InitializeTable(13);
int i;
for(i=0;i<13; i++)
Insert(a[i],H);
printf("请输入一个数:\n");
int key;
scanf("%d",&key);
HashNode* p = Find(key,H);
if(NULL == p)
printf("未找到\n");
else
printf("找到了: %d\n",p->data);
return 0;
}














 7413
7413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









