







一、架构与存储的关系
一个新的硬盘在linux系统里使用一般来说就三步:(分区,格式化)-挂载-使用block
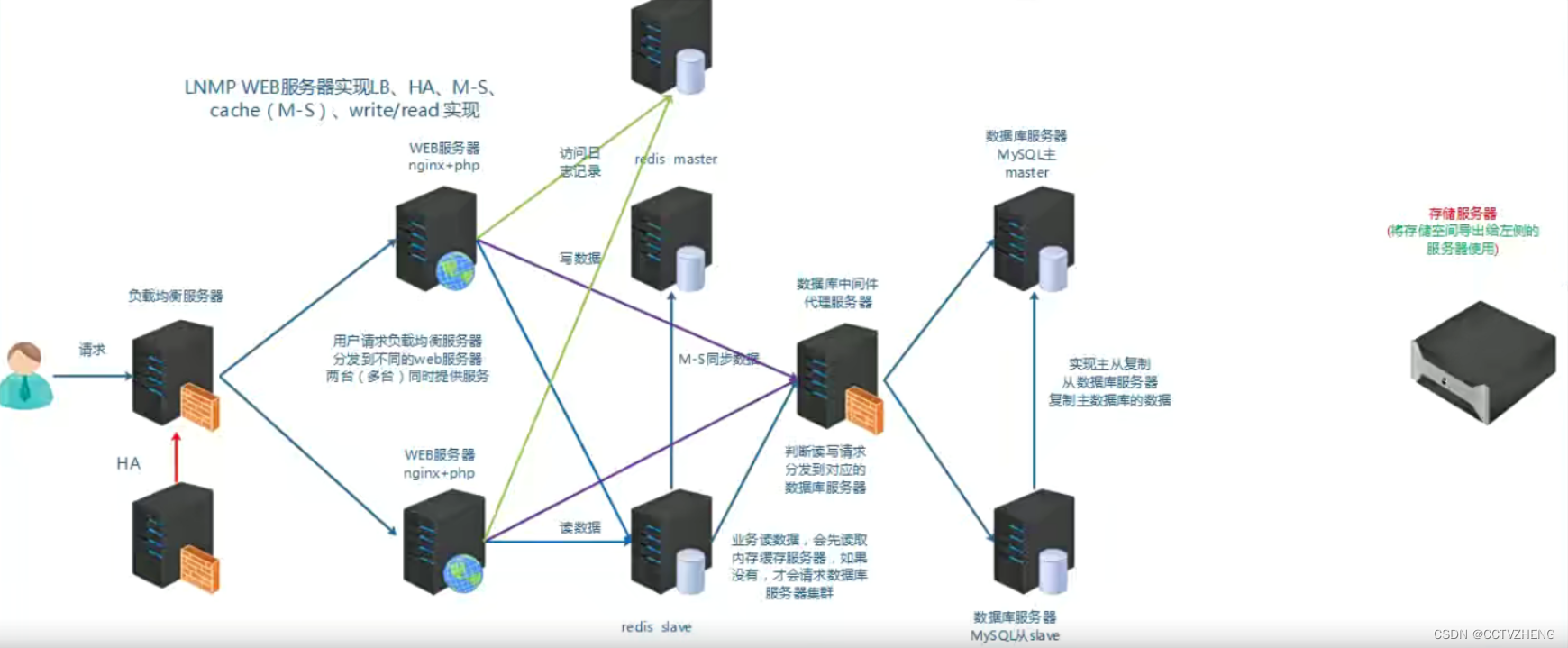
lvs:四层负载均衡,nginx、haproxy四层和七层都有
redis、memcache缓存中间件是缓存后端数据库读的信息。
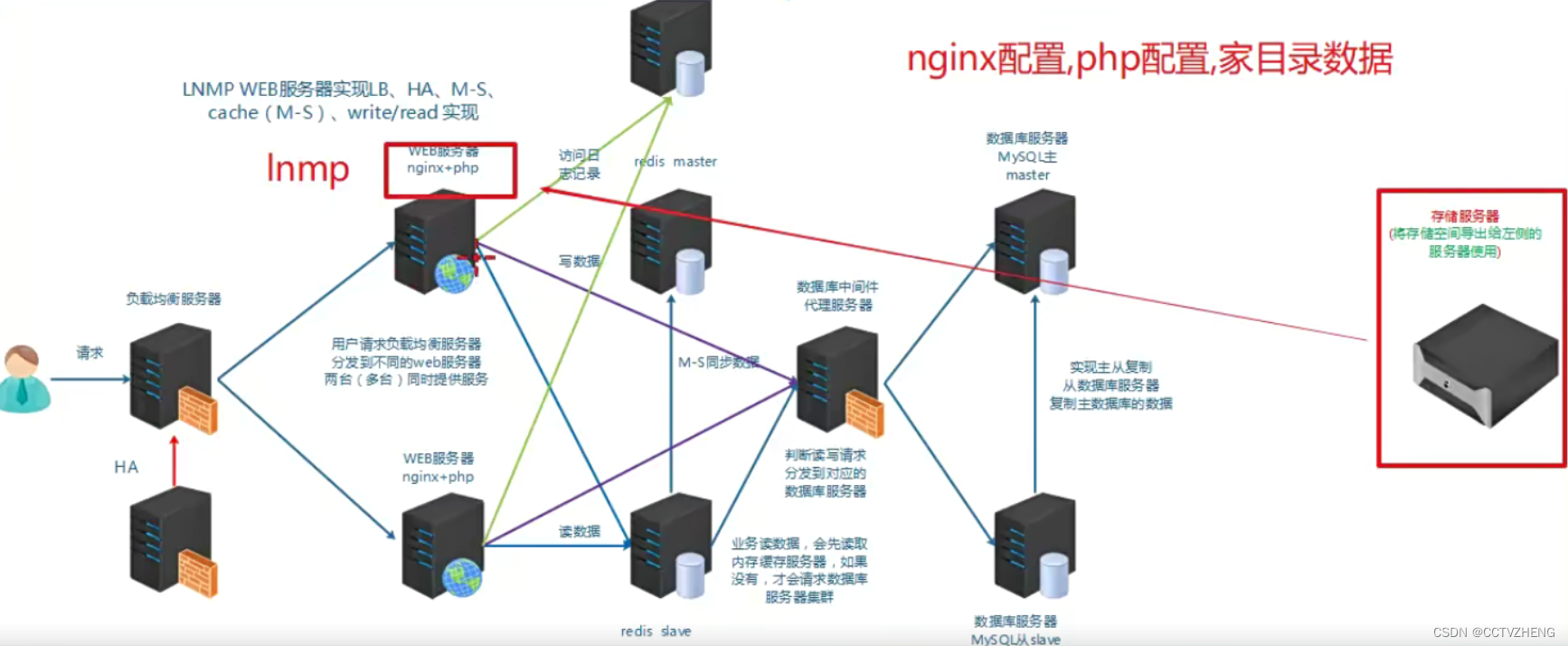
高端的容器技术,一旦系统出现可以可以直接重装系统,所以系统盘与数据盘必须分开
远程存储服务器可以为web服务器和数据库服务器提供内存,负载均衡服务器不用(请求内容数据太小)

系统盘和数据盘分开就是把lnmp整个架构放在本地服务器上,但是 配置的数据和家目录放在远程服务器
将系统数据与业务数据(web数据,数据库数据,日志等)分开,将业务数据放到远程存储(保证HA,LB),然后通过某种技术远程共享给应用服务(跑nginx,mysql等)使用
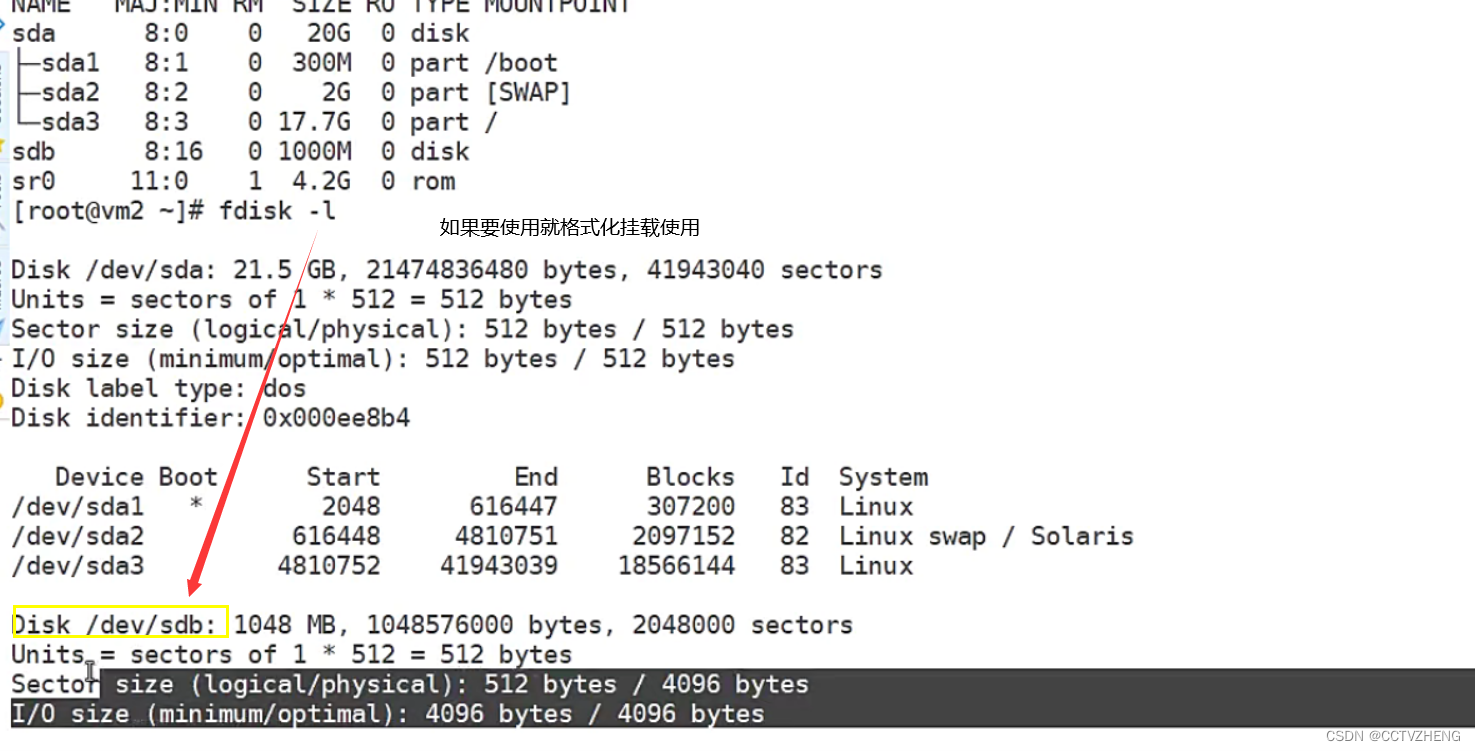
问题: linux上如何挂载ntfs格式的移动硬盘?
linux内核支持ntfs,但centos7系统并没有加上此功能
1、重新编译内核,在内核加上支持ntfs(此方法不推荐,因为编译内核会造成内核运行不稳定,没有过硬的实力不要做)
2、安装软件,为内核加上支持ntfs的模块
# yum install epel-release-y //安装epel源
# yum install ntfs-3g
挂载命令
#mount.ntfs-3g /dev/sdb1 /mnt二、Linux存储五层:

lsmod 查看操作系统的模块
可以跨文件系统拷贝,ext4文件系统是CentOS6的,可以拷贝文件到CentOS7的xfs文件系统
上面比较难理解的是虚拟文件系统:又名VFS (Virtual File System),作用就是采用标准的Unix系统调用读写位于不同物理介质上的不同文件系统,即为各类文件系统提供了一个统一的操作界面和应用编程接口API。
简单来说,就是使用上层应用程序不用关注底层是什么文件系统,统一使用。
本地就是第一层物理卷,远程存储就是第二层模块驱动,需要协议
比如samba远程同步cifs
三、存储类型和分类

文件存储:类似一个大的目录,多个客户端都可以挂载过来使用。·
优点:利于数据共享
·缺点:速度较慢
块存储:类似一个block设备,客户端可以格式化,挂载并使用,和用一个硬盘一样。
·优点:和本地硬盘—样,直接使用,速度较快
缺点:数据不共享
对象存储:一个对象我们可以看成一个文件,综合了文件存储和块存储的优点。
优点:速度快,数据共享
缺点:成本高,不兼容现有的模式


1、SAN的分类
两种SAN:
1.FC-SAN:早期的SAN,服务器与交换机的数据传输是通过光纤进行的,服务器把SCSI(small computer )指令传输到存储设备上,不能走普通LAN网的IP协议。
2.IP-SAN:用IP协议封装的SAN,可以完全走普通网络,因此叫做IP-SAN,最典型的就是ISCSI。
FC-SAN优缺点:速度快(2G,8G,16G),成本高。
IP-SAN优缺点:速度较慢(已经有W兆以太网标准),成本低。
lP-SAN之iscsi实现
iscsi: internat small computer system interface
(网络小型计算机接口,就是一个通过网络可以实现SCSI接口的协议)
2、lP-SAN之iscsi实现
iscsi: internat small computer system interface
(网络小型计算机接口,就是一个通过网络可以实现SCSI接口的协议)
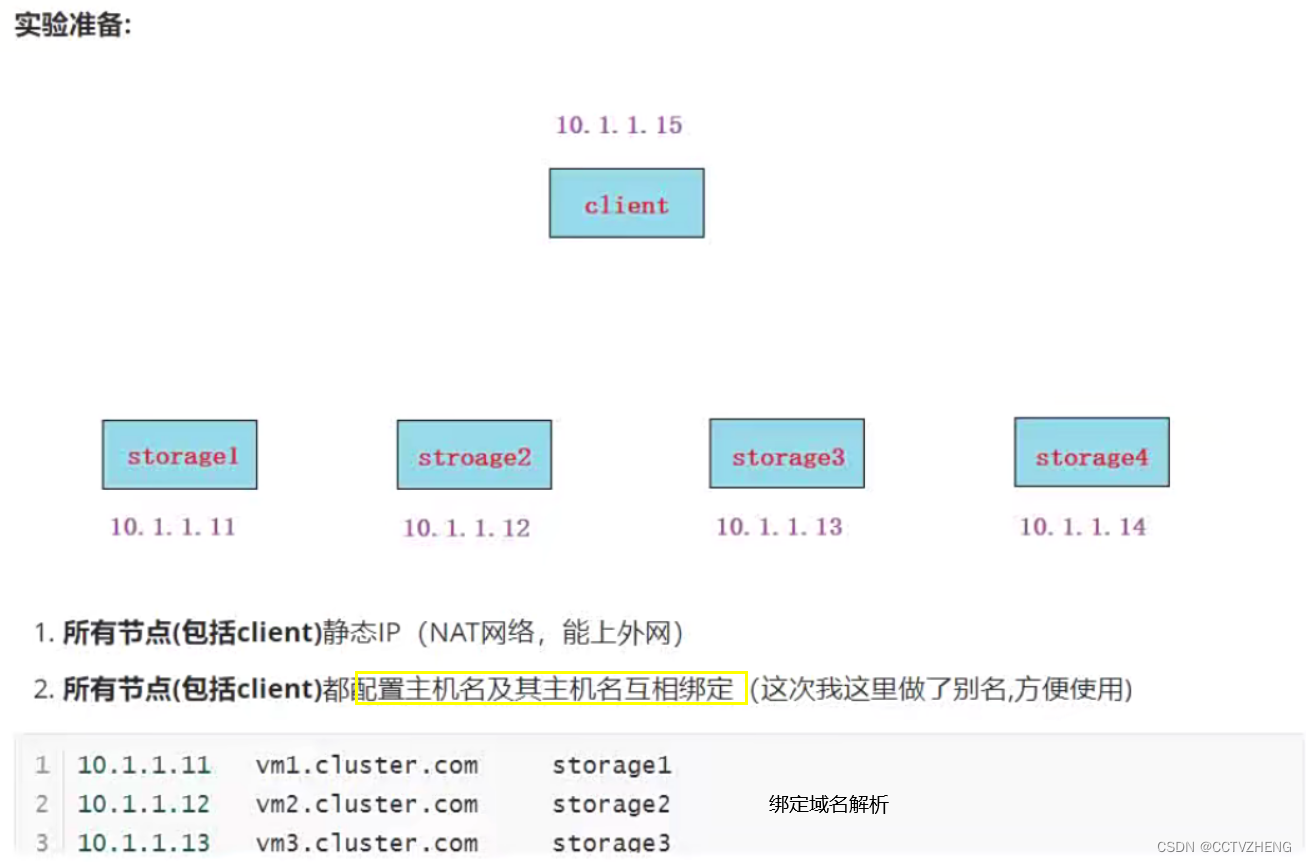
实验: Linux平台通过iscsi实现IP-SAN
实验准备:两台虚拟机(centos7平台)同网段(比如vmnet8),交换机不用模拟,因为同网段的虚拟机就相当于连在同一个交换机上

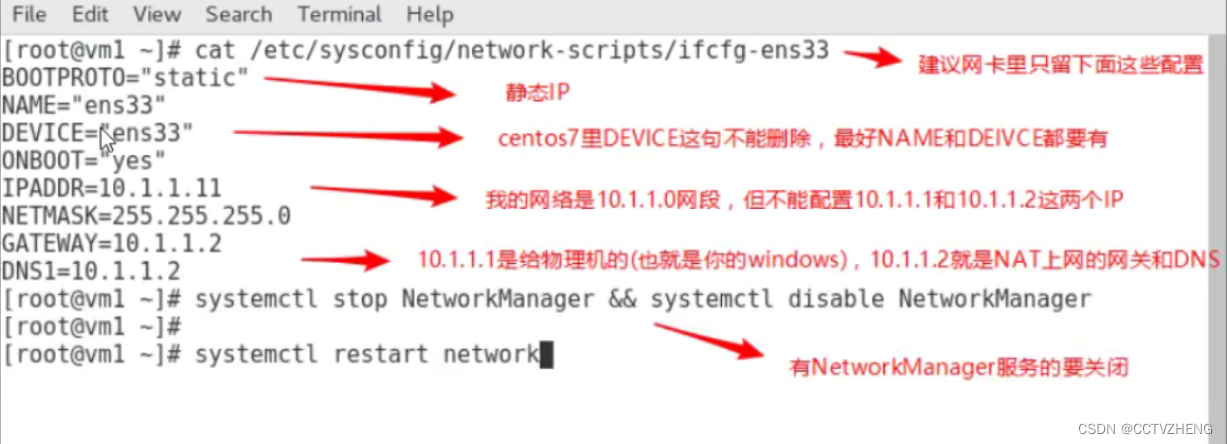
1.静态IP(两台IP互通就行,网关和DNS不做要求)
2.都配置主机名及其主机名互相绑定
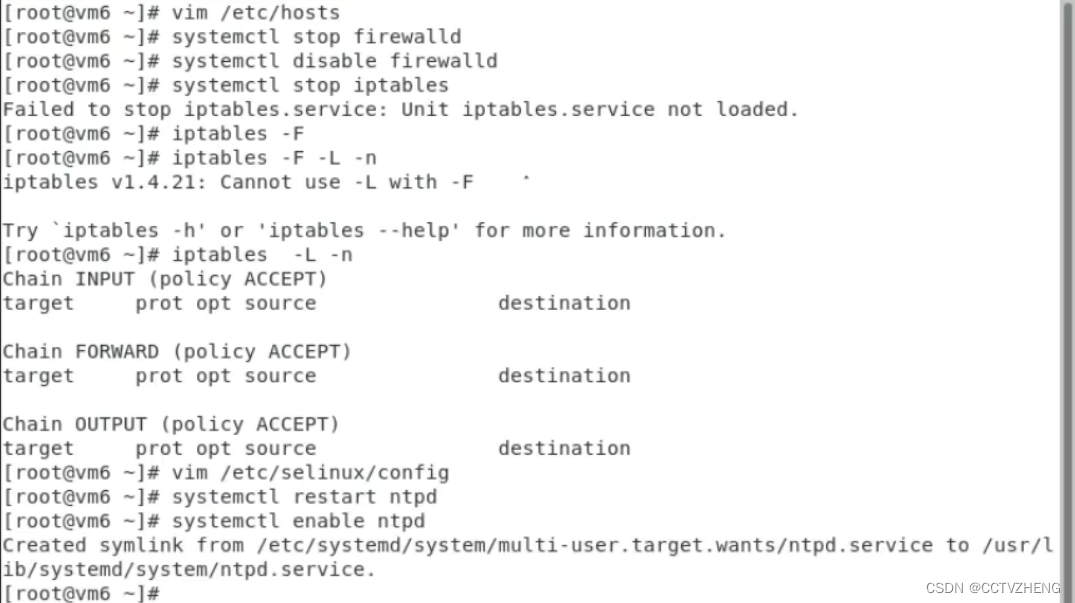
3.关闭防火墙,selinux
4.时间同步
5.配置好yum (需要加上epel源)epel源不用先安装,因为网速慢
使用NAT网络模式,因为桥接网络模式会造成ip冲突
最后reboot关机,然后打开查看配置是否 生效,拍摄快照之后关机 按照需求克隆
iptables -L
-L -list
显示所选链的所有规则。如果没有选择链,所有链将被显示。也可以和z选项一起使用,这时链会被自动列出和归零。精确输出受其它所给参数影响。
-F-flush
清空所选链。这等于把所有规则—个个的删除。
iptables -F清空所有规则只能暂时停止防火墙,最好别用,除非没有配置防火墙
6.在存储导出端模拟存储(模拟存储可以使用多种形式,如硬盘:/dev/sdb,分区:/dev/sdb1,软raid:/dev/md0,逻辑卷:/dev/vg/lv01, dd if=/dev/zero of=/tmp /storage_file bs=1M count=1000创建1000M大文件等物理卷),本实验请自行加一个硬盘来模拟
storage存储
实验步骤:
1.export导出端安装软件,配置导出的存储,启动服务
2.import导入端安装软件,导入存储,启动服务
实验过程:
第1步:在导出端上安装iscsi-target-utils软件包
export# yum install epel-release -y
没有安装epel源的,再次确认安装
export# yum install scsi-target-utils -y
第2步;在导出端配置存储的导出
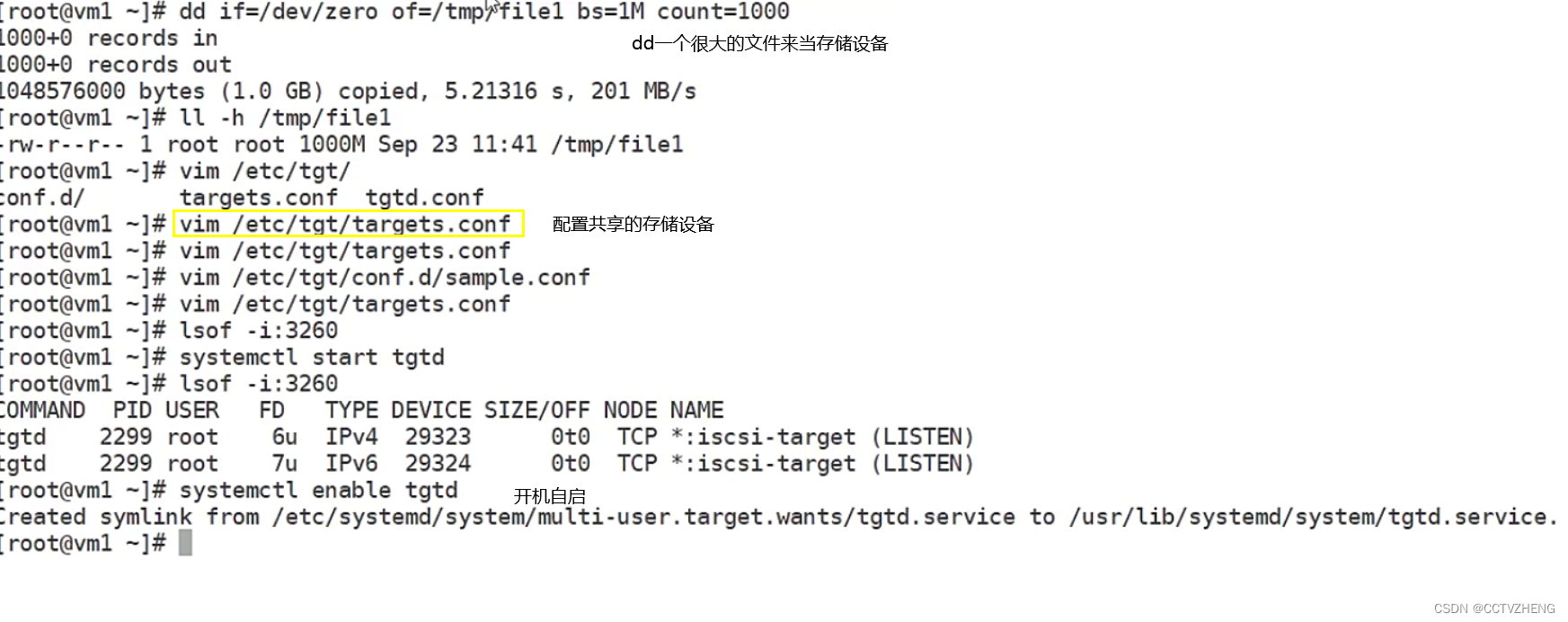
rpm -qc 是查看配置文件的
export#cat /etc/tgt/targets.conf |grep -v "#"
(配置定后的结果如下)
default-driver iscsi
<target iscsi:data> #共享名,也就是存储导入端发现后看到的名称
backing-store /dev/sdb #/dev/sdb是实际共享的设备
</target>

第3步;导出端启动服务并验证
systemctl start tgtds
systemctl enable tgtd
验证端口和共享资源是否ok
lsof -i:3260
第四步:在导入端上安装软件包

在登录前必须要先连接并发现资源(discovery)

连接的是导出存储端服务器ip

最后import存储导入端可以开启服务并设置开机自启
物理卷就是块分区,不能共享,只能一个人用
问题:如果再加一个新的导入服务器,两个导入服务器导入同一个存储,然后格式化
挂载。能实现同读同写吗?
不可以,除非一个人分配一个块服务,但是依旧不能共享数据
四、分布式存储概念(云存储)
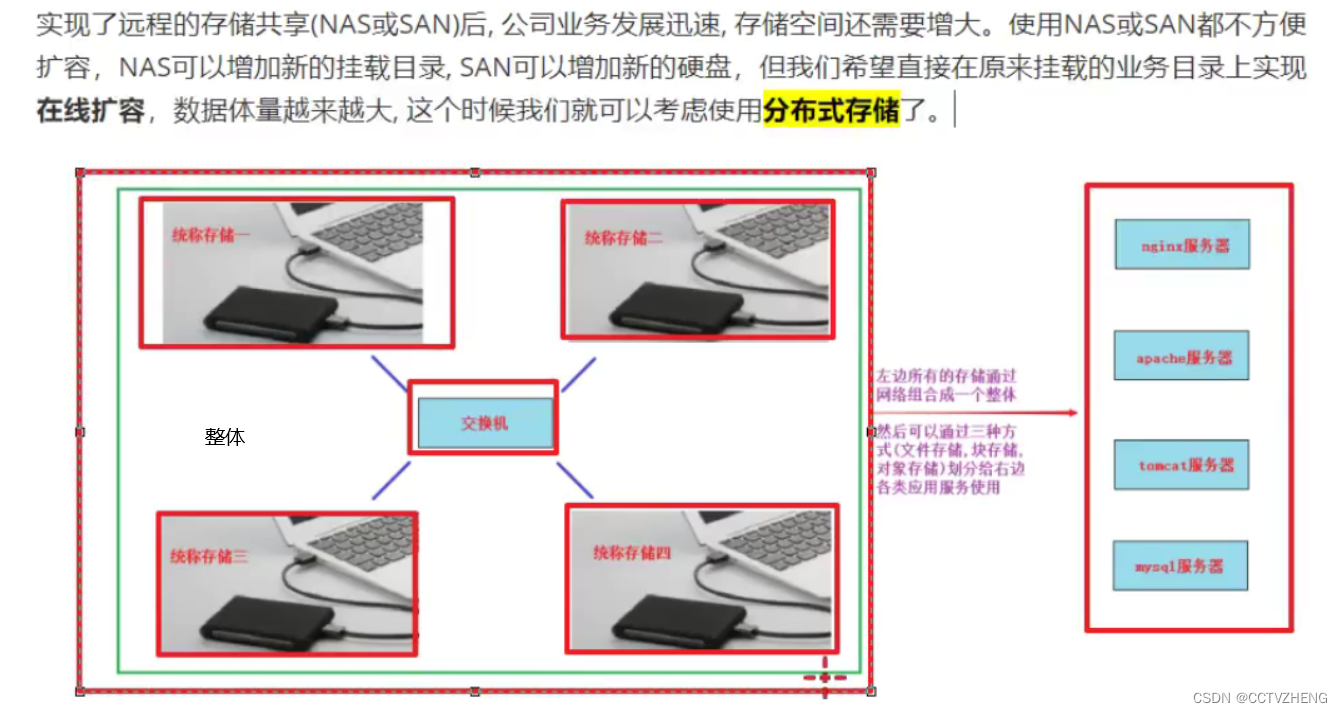
分布式存储介绍
我们已经学习了NAS是远程通过网络共享目录,SAN是远程通过网络共享块设备。
那么分布式存储你可以看作拥有多台存储服务器连接起来的存储导出端。把这多台存储服务器的存储合起来做成一个整体再通过网络进行远程共享,共享的方式有目录(文件存储),块设备(块存储),对象网关或者说一个程序接口(对象存储)。
常见的分布式存储开源软件有:GlusterFs,Ceph(谐音:C伏),HDFSTMooseFS,FastDFS等。
分布式存储一般都有以下几个优点:
1.扩容方便,轻松达到PB级别或以上 1PB=1024TB 扩容就是扩展存储整体(文件、块、对象)
2.提升读写性能(LB)或数据高可用(HA)
3.避免单个节点故障导致整个架构问题
4.价格相对便宜,大量的廉价设备就可以组成,比光纤SAN这种便宜很多

存储柜组成一个整体
Glusterfs介绍

glusterfs是一个免费,开源的分布式文件系统(它属于文件存储类型**)。
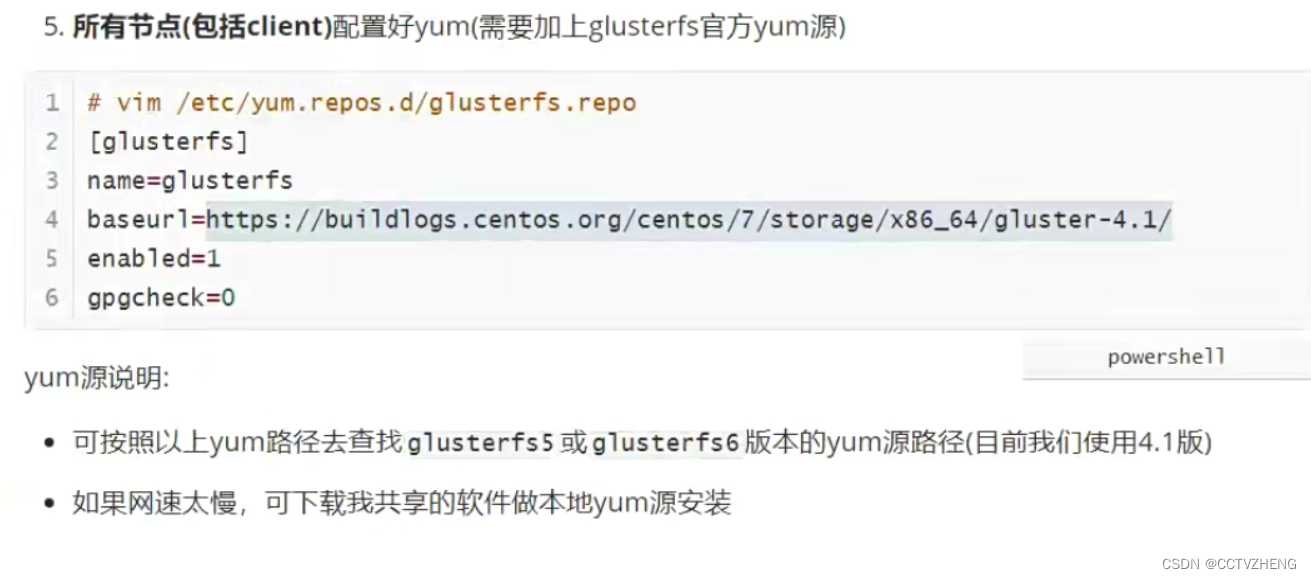
实验步骤:
1.在所有storage服务器上安装相关软件包,并启动服务
2.所有storage服务器建立连接,成为一个集群
3.所有storage服务器准备存储目录
4.创建存储卷
5.启动存储卷
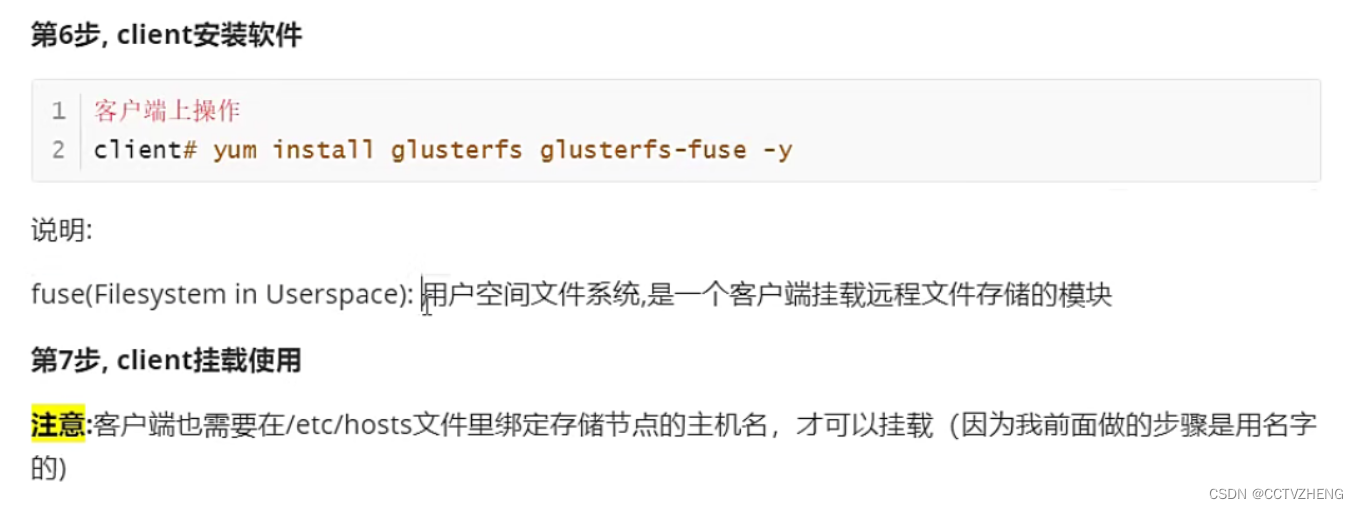
6.client安装挂载软件
7.client挂载使用
replica模式(复制卷)
实验过程:
第1步,在所有storage服务器上(不包括client)安装glusterfs-server软件包,并启动服务
下面的命令所有存储服务器都要做
#yum install glusterfs-server
#systemctl start glusterd
#systemctl enable glusterd
#systemct1 status glusterd
分布式集群一般有两种架构:
·有中心节点的―中心节点一般指管理节点,后面大部分分布式集群架构都属于这种
·无中心节点的――所有节点又管理又做事,glusterfs属于这一种
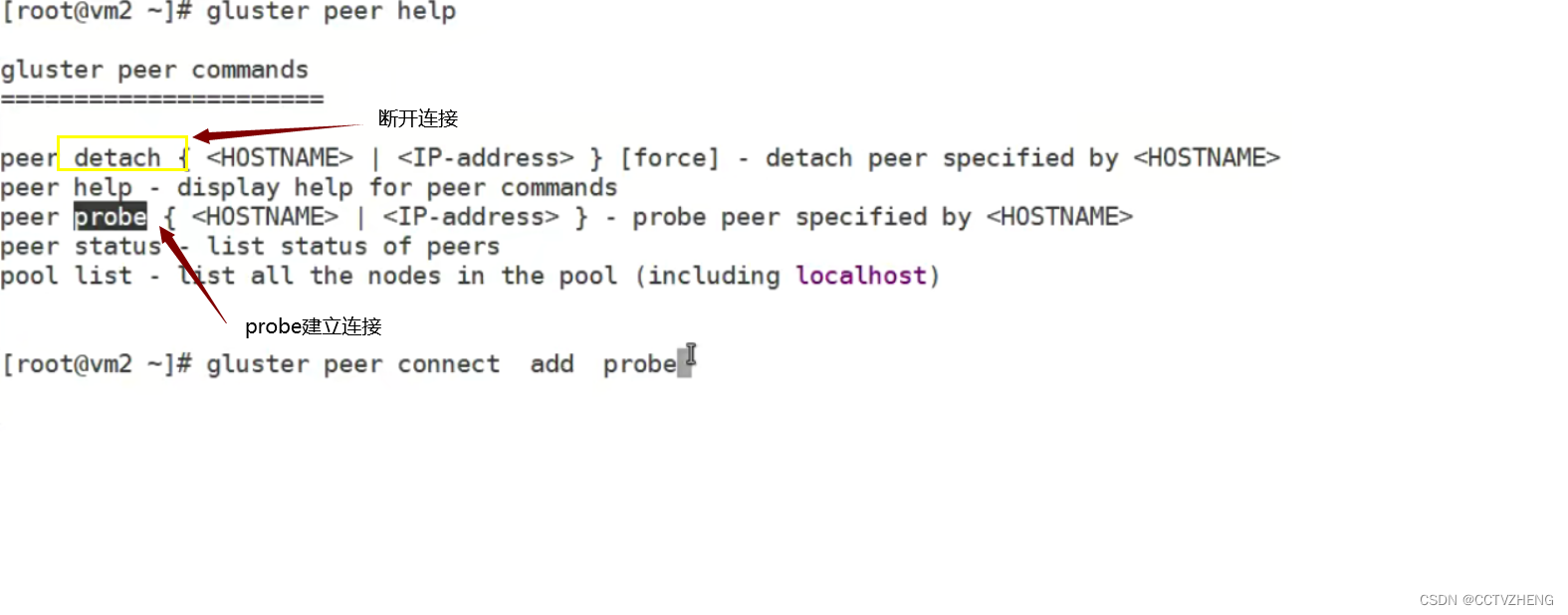
第2步,所有storage服务器建立连接,成为一个集群
4个storage服务器建立连接不用两两连接,只需要找其中1个,连接另外3个各一次就oK了
下面我就在storage1上操作
storage1# gluster peer probe storage2
storage1# gluster peer probe storage3
storage1# gluster peer probe storage4
--这里使用ip,主机名,主机名别名都可以
然后在所有存储上都可以使用下面命令来验证检查
# gluster peer status
没有管理节点都可以看状态注意:
如果这一步建立连接有问题(一般问题会出现在网络连接,防火墙,selinux,主机名绑定等);如果想重做这一步,可以使用gluster peer detach xxxxx [force]来断开连接,重新做 强制断开可以不加

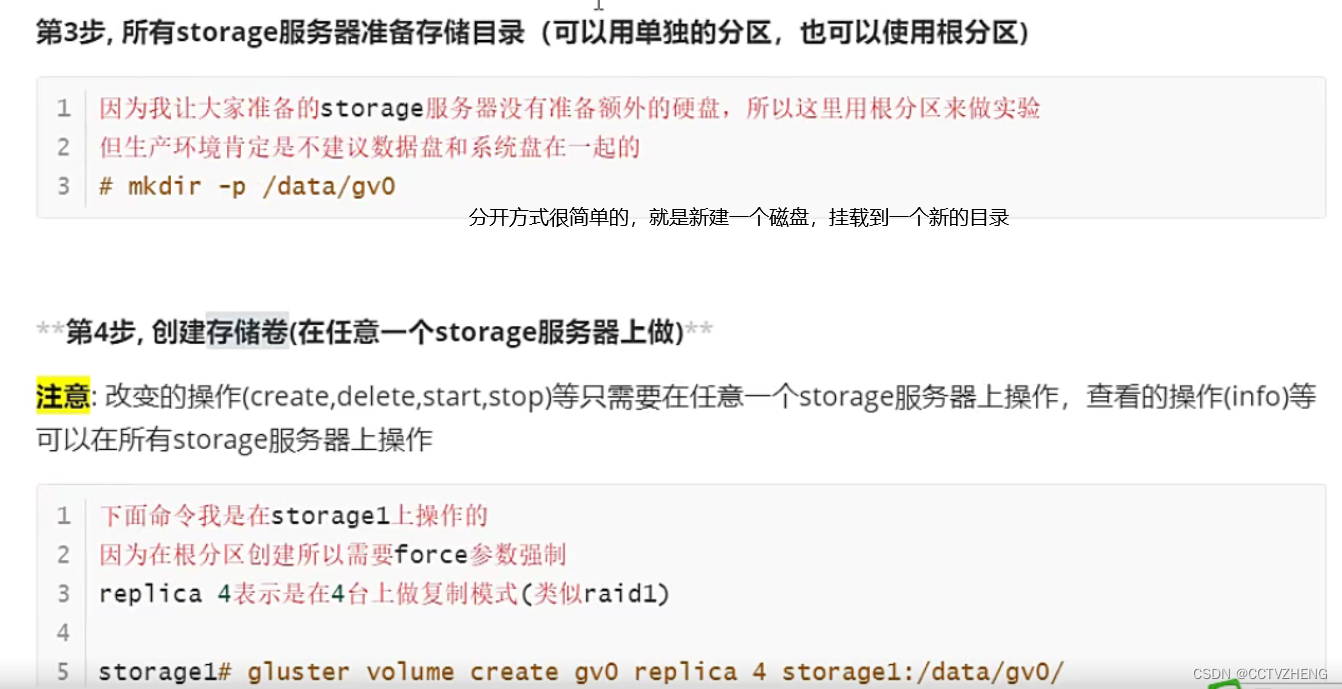
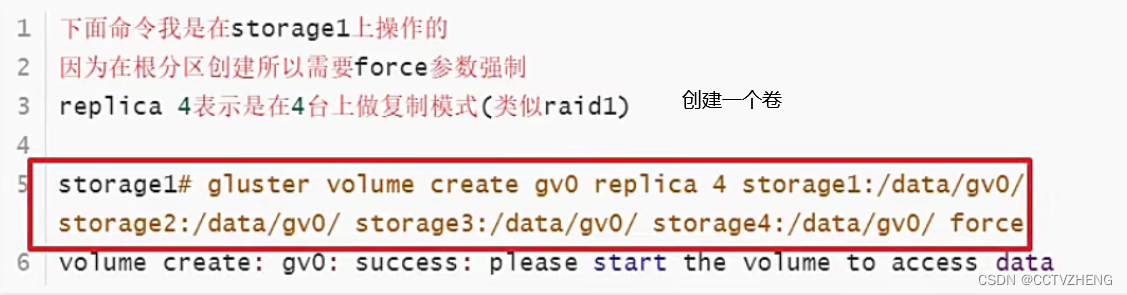
replica 复制 由于是实验是在/分区操作的所以只能force

启动glusterfs 官方文档上一模一样



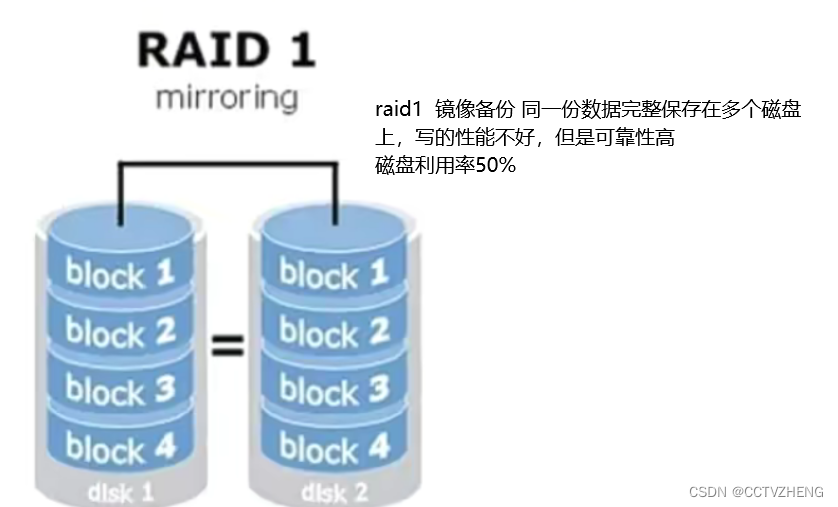
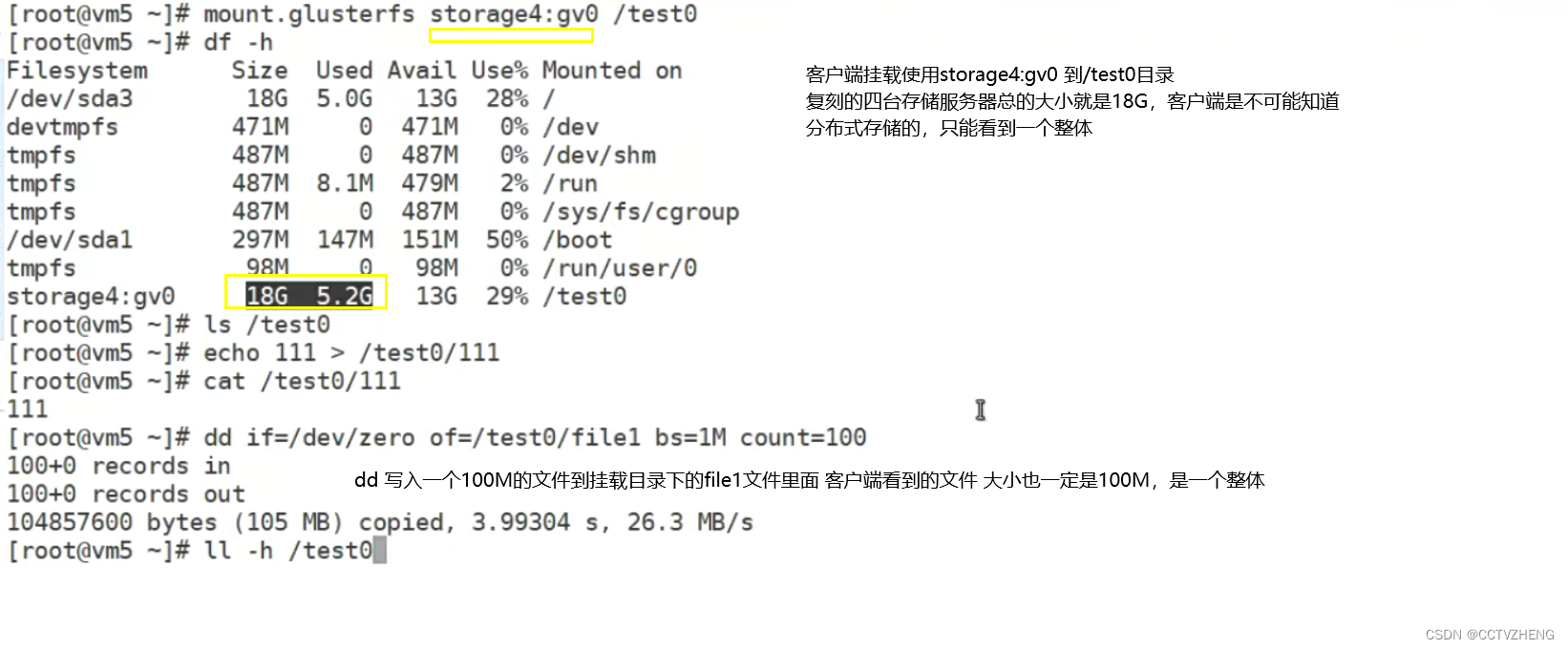
复刻四个存储卷太浪费了,类似raid1镜像备份模式。最好复刻2个存储就ok
其他两台存储服务器可以自由复刻2个存储到其他客户端(nginx、mysql)
lsof -i :80 //查看相关端口
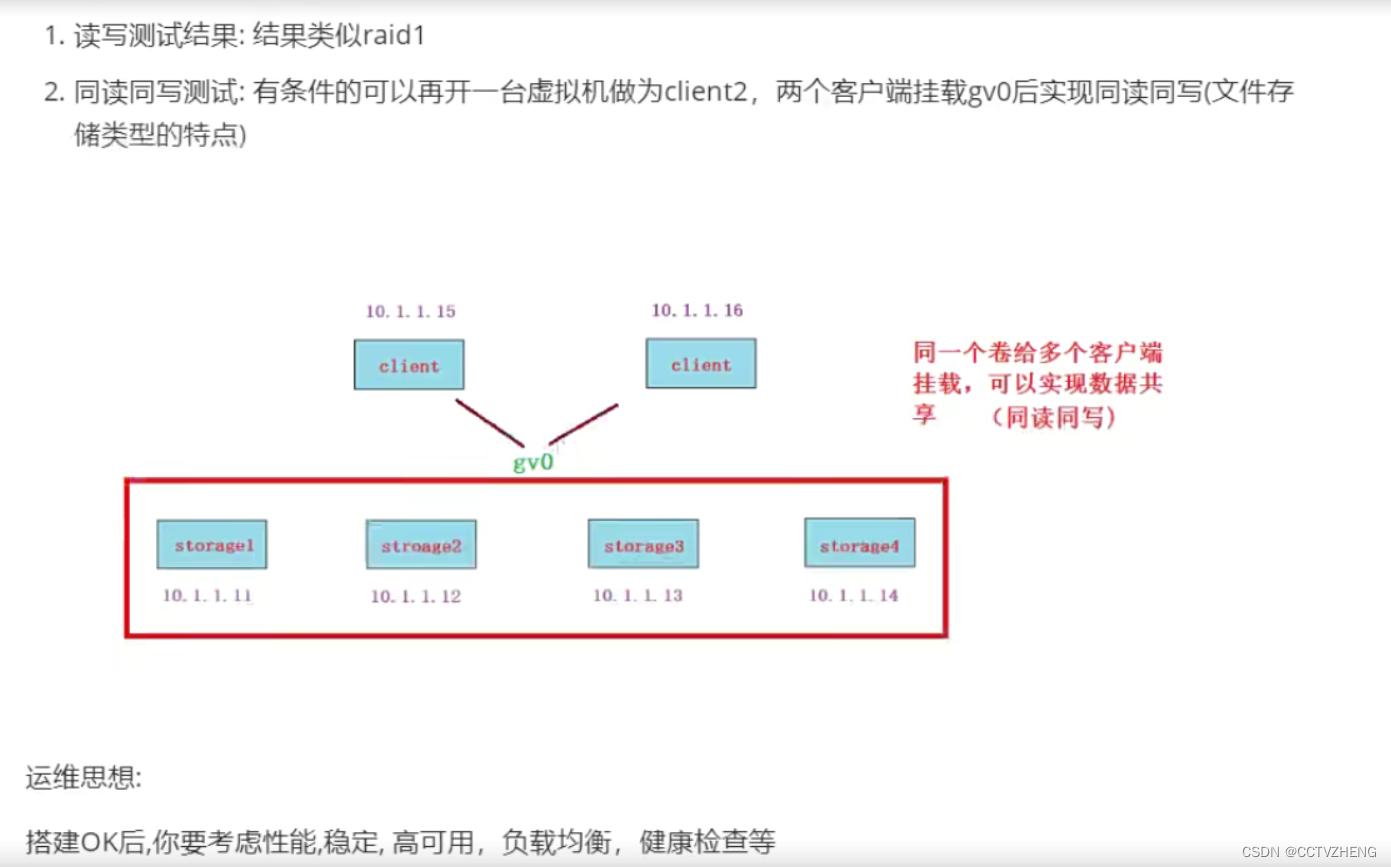
把前端nginx服务器的家目录挂载到存储服务器,如果nginx出问题了就可以直接重新安装,不用排查
单个节点挂了,不会影响其他节点的挂载和使用
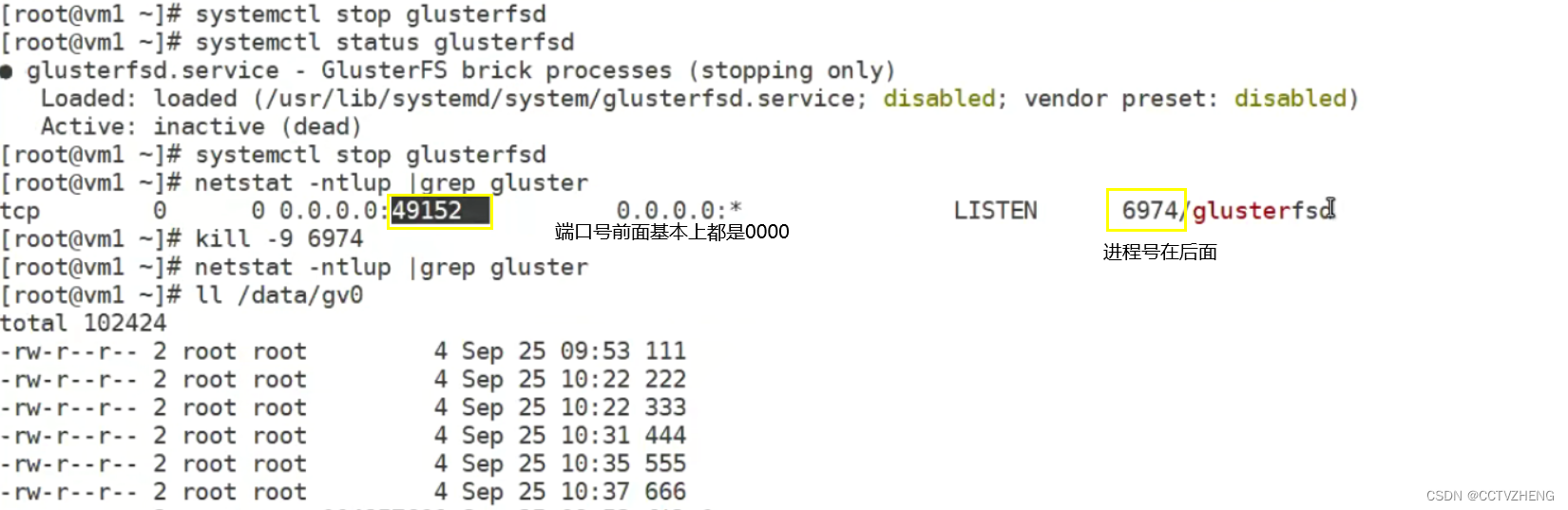
HA的区别
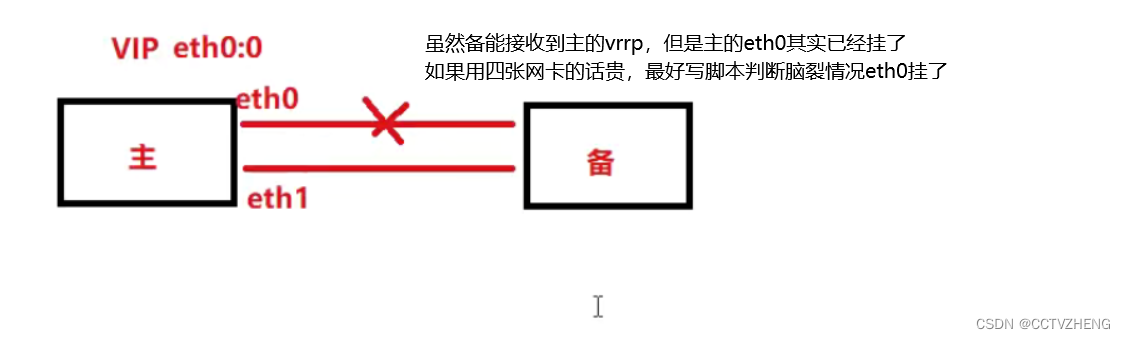
分布式存储和热备一样,都是HA,但是还是有区别的,分布式存储的高可用更灵活
无论单点服务器如何折腾,都不能影响客户端

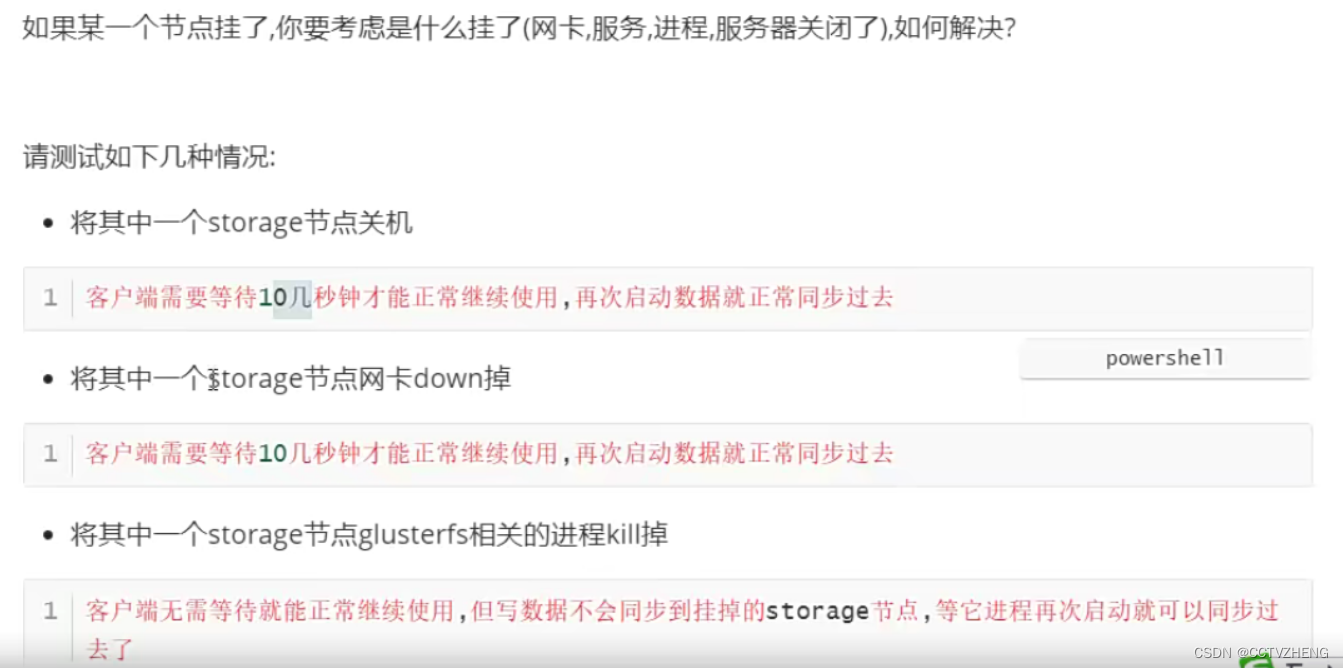
服务器关闭 网卡坏了 网线断了 交换机挂了 服务进程被误杀等等
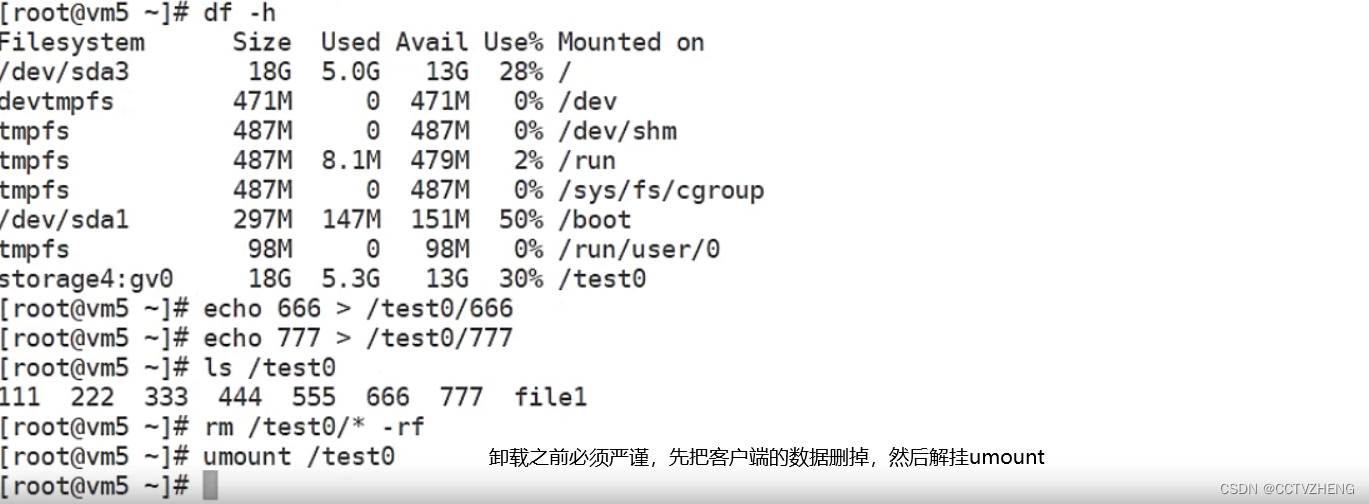
删除存储卷
第一步先把前端服务器的数据删掉
第二步umount 挂载目录 两台客户端服务器都必须卸载挂载目录
第三步停止glusterfs的存储卷服务
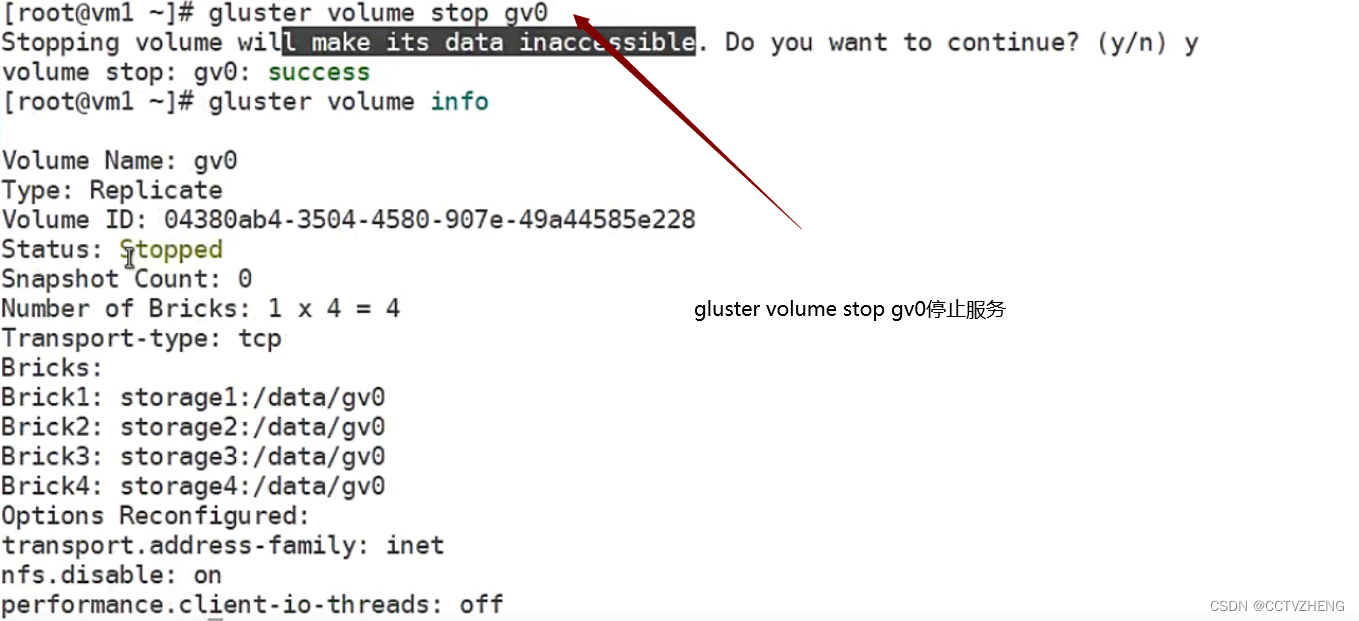
删除存储卷gv0 gluster volume delete gv0
如果要卸载重装,可以把断开存储服务器之间的连接 把挂载目录删掉,停止glusterd服务 卸载安装包
gluster peer detach 主机名
stripe模式(条带卷)

最后进行读写测试:
读写测试结果:文件过小,不会平均分配给存储节点。有一定大小的文件会平均分配。类似raid0。
提升IO性能,LB。挂了一个节点就不能使用了,利用率高一个目录10G,四个就是40G
distributed模式(分布卷)
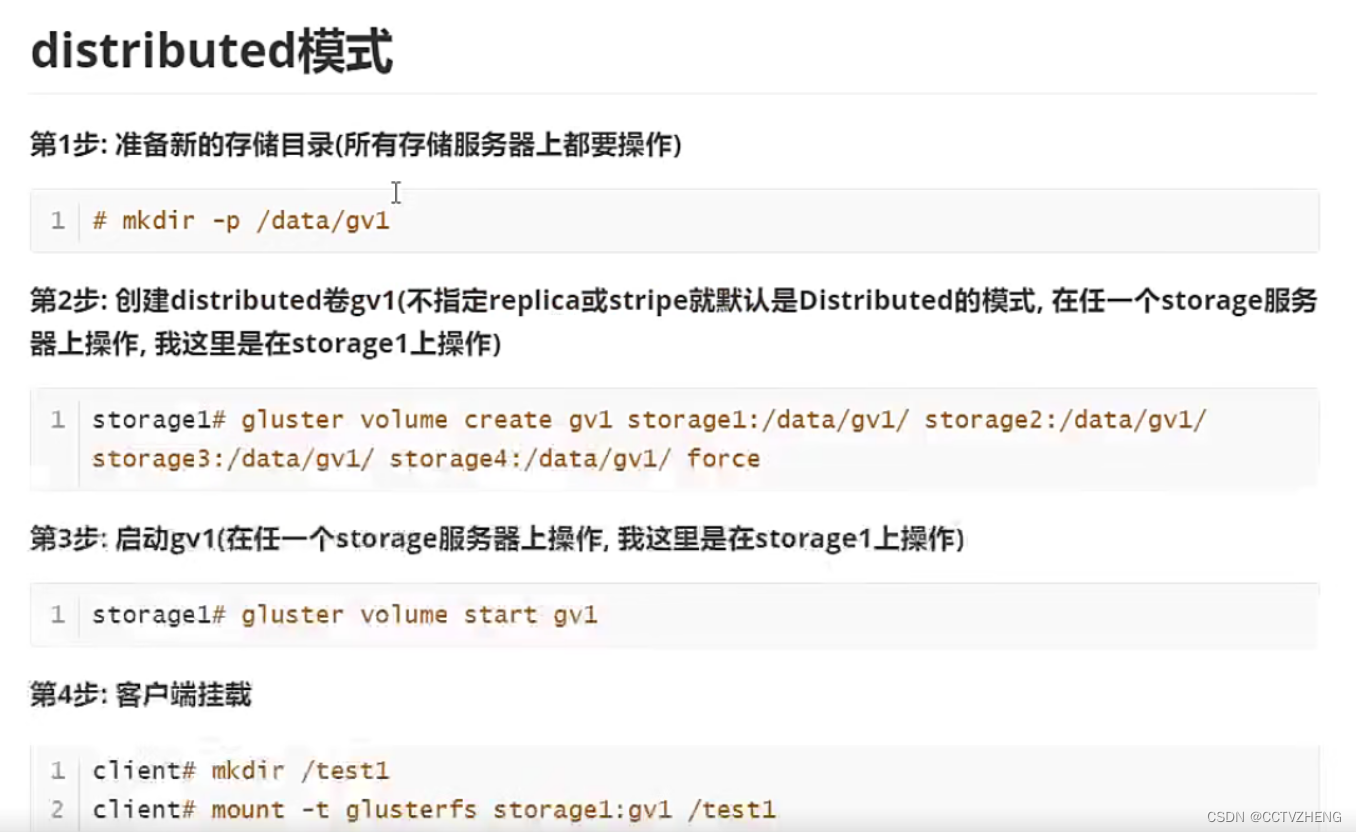
读写测试结果:测试结果为随机写到不同的存储里,直到写满为止。
方便扩容 (在多个brick中随机存储,在线扩容)
不保障的数据的安全性(挂掉一个节点,等待大概1分钟后,这个节点就剔除了,被剔除的节点上的数据丢失)
也不提高lO性能
distributed replicated
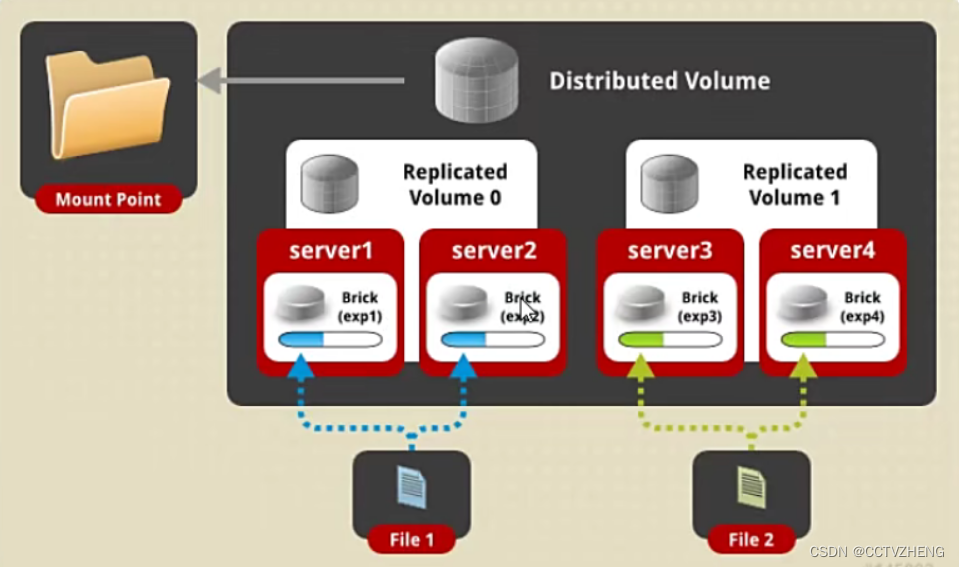
实际上就是复制两个组,两个brick一个组,然后随机上传文件到 任意一个组中的两个brick
如果其中一个组的节点出问题了还能实现HA,但是一个组出问题的话就会导致数据丢失。
replica 2就ok

Deprecated是将来的版本会淘汰这个功能
dispersed模式(raid5)
dispersed 分散
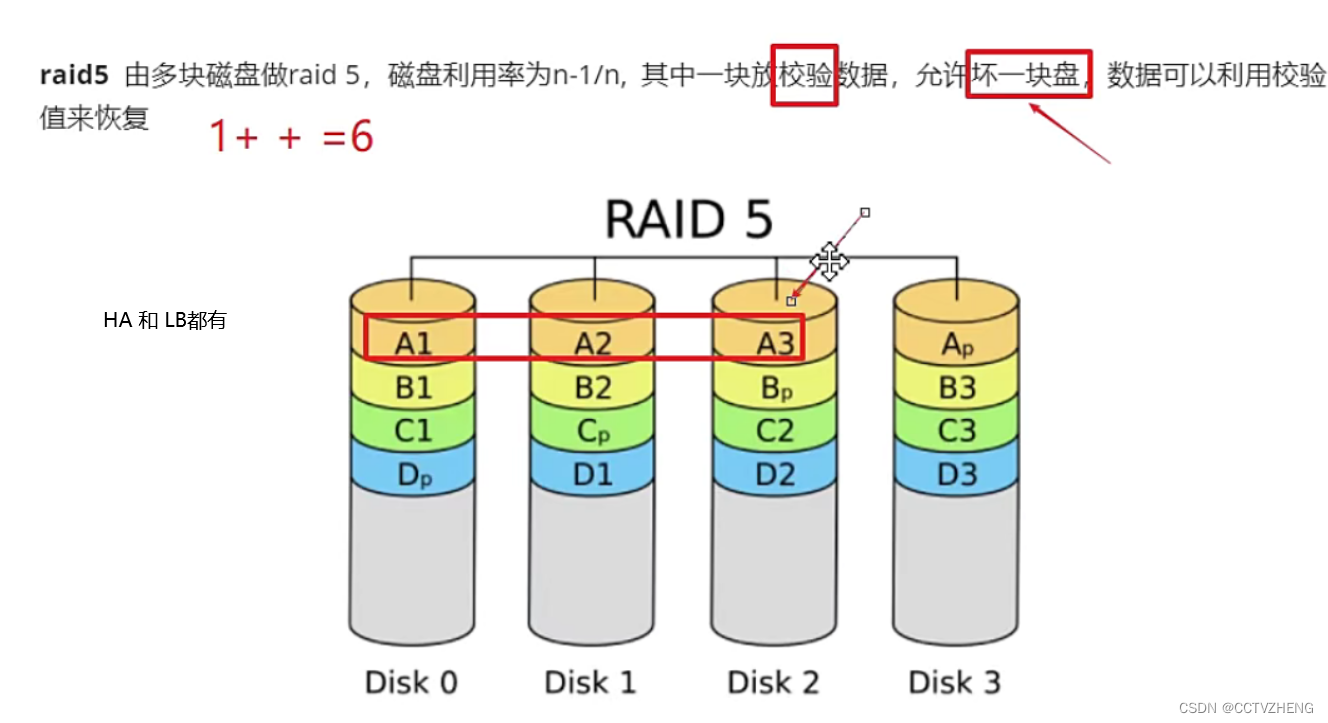
防止单点故障,提升IO性能(LB),RAID6就是在加一块校验disk
每个节点都必须创建挂载目录,mkdir /data/gv0

这不是redundancy value冗余值配置,你确定要用第一块盘做冗余吗?
默认都是5块,4块的话,只有三块做节点
可以实现高可用,负载均衡,单节点故障之后可以利用冗余盘恢复
disperse 4 创建存储卷
在线裁减与在线扩容
在线裁减要看是哪一种模式的卷,比如stripe模式就不允许在线裁减。
下面我以distributed卷来做裁减与扩容
在线裁减(注意要remove没有数据的brick)
gluster volume remove-brick gv1 storage4 : / data/gv1 force
Removing brick(s) can result in data loss. Do you want to continue? (y/n) y3 volume remove-brick commit force: success
在线扩容
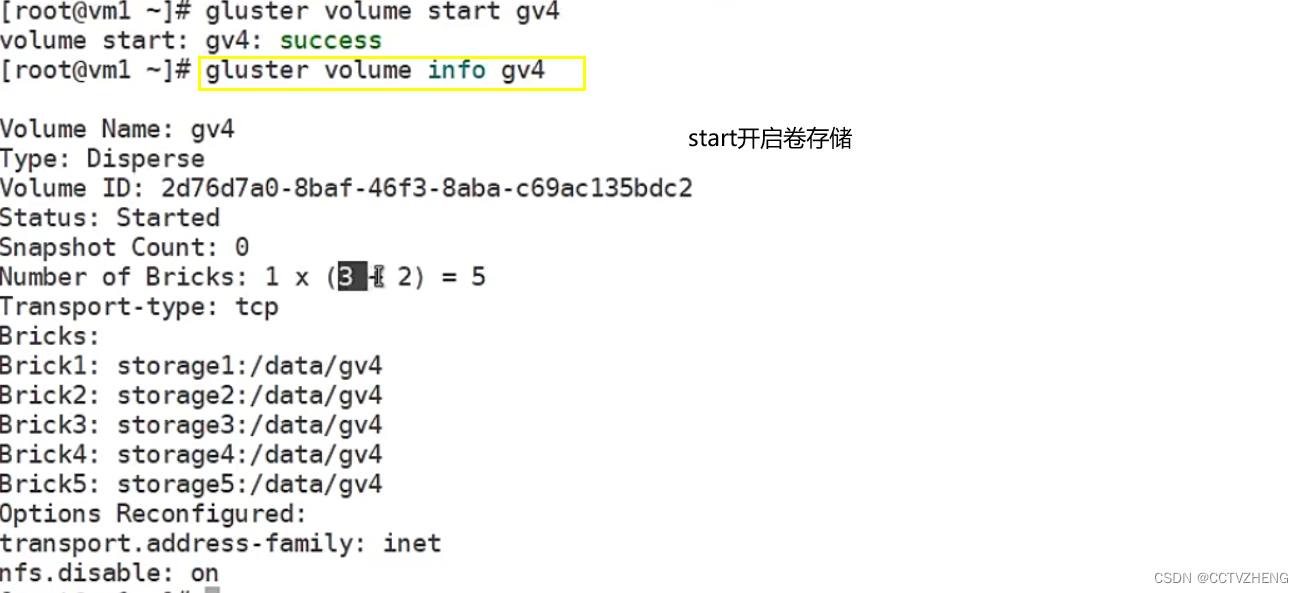
gluster volume add-brick gv1 storage4 : /data/gv1 force
volume add-brick : success
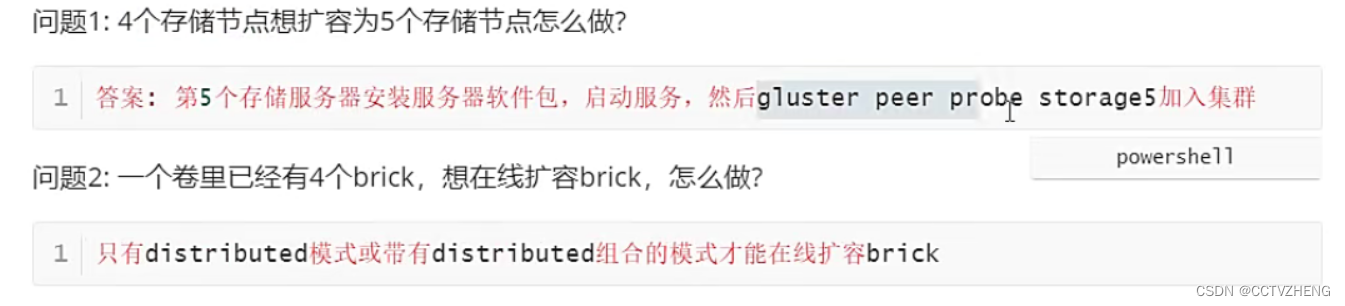
细节:扩容对象必须绑定域名解析,每个节点都要绑定主机名称

mkdir /data/gv0 这个节点是加入了,但是没有加入存储卷,
总结

属于文件存储类型,可以数据共享,就是速度较慢
Ceph
ceph是一个能提供文件存储,块存储和对象存储的分布式存储系统。它提供了一个可无限伸缩的Ceph存储集群。
一、Ceph架构
参考官档: http://docs.ceph.org.cn/

RADOS: Ceph的高可靠,高可拓展,高性能,高自动化都是由这一层来提供的,用户数据的存储最终也都是通过这一层来进行存储的。
可以说RADOS就是ceph底层原生的数据引擎,但实际应用时却不直接使用它,而是分为如下4种方式来使用:
LIBRADOS是一个库,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言。如Python,C,C++等.简单来说,就是给开发人员使用的接口。
.CEPH FS通过Linux内核客户端和FUSE来提供文件系统。(文件存储)
RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。(块存储).
RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。(对象存储)
二、Ceph集群
1、集群组件
ceph集群包括Ceph OSD Ceph Monitor两种守护进程。
Ceph OSD(object Storage Device):功能是存储数据,处理数据的复制、恢复、回填、
再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息。
ceph Monitor:是一个监视器,监视ceph集群状态和维护集群中的各种关系。Ceph存储集群至少需要一个ceph Monitor和两个OSD守护进程。
2、集群环境准备
准备工作:
准备四台服务器,需要能上外网,IP静态固定(除client外每台最少加1个磁盘,最小1G,不用分区);
配置主机名和主机名绑定(所有节点都要绑定)
(注意:这里都全改成短主机名,方便后面实验。如果你坚持用类似vm1.cluster.com这种主机名,或者加别名的话,ceph会在后面截取你的主机名vm1.cluster.com为vm1,造成不一致导致出错

关闭防火墙和selinux,开启时间同步ntpd
配置Ceph的yum源两种方法:
公网ceph源(centos7默认的公网源+epel源+ceph的aliyun源)
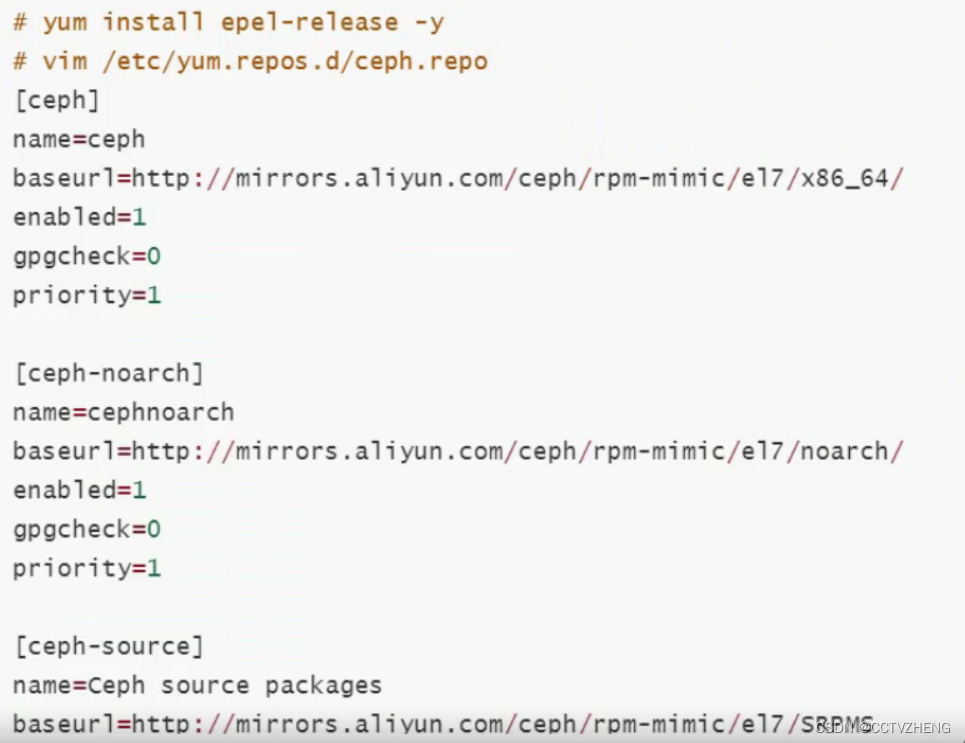
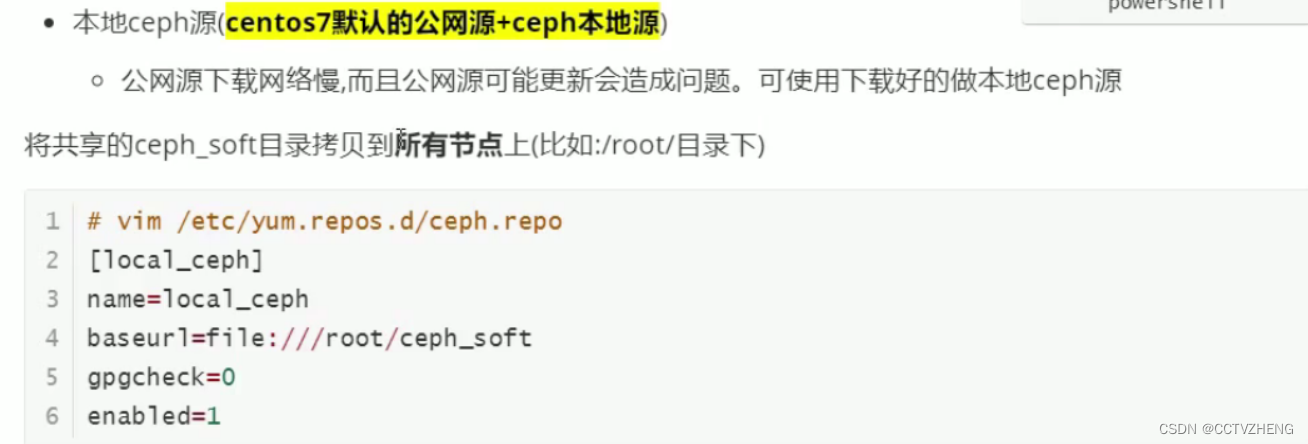
本地源需要提前下载上传到所有节点
3、集群部署过程
第1步:配置ssh免密
以node1为部署配置节点,在node1上配置ssh等效性(要求ssh node1,node2,node3 ,client都要免密码)
说明:此步骤不是必要的,做此步骤的目的:
·如果使用ceph-deploy来安装集群,密钥会方便安装
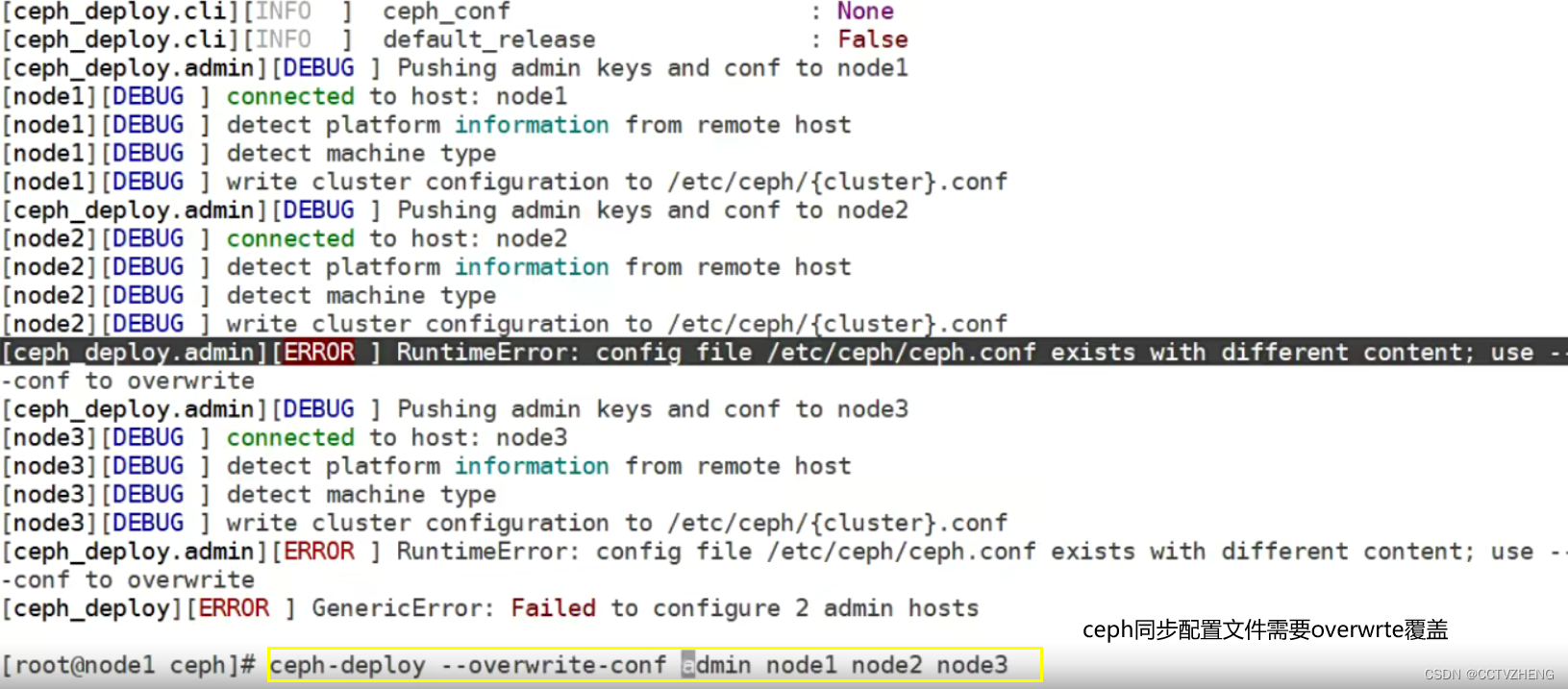
·如果不使用ceph-deploy安装,也可以方便后面操作:比如同步配置文件

第2步:在node1上安装部署工具(其它节点不用安装)

第3步:在node1上创建集群建立一个集群配置目录
注意:后面的大部分操作都会在此目录

创建一个ceph集群 不会用可以ceph-deploy --help

ceph.mon.keyring中心节点 监控 验证key文件
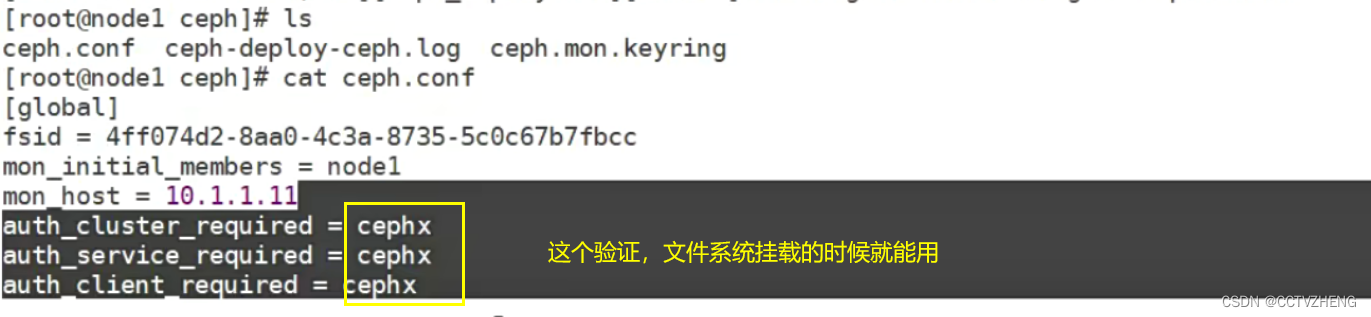
第4步: ceph集群节点安装ceph
前面准备环境时已经准备好了yum源,在这里所有集群节点(不包括client)都安装以下两个软件
ceph-radosgw ceph的对象存储模块

补充说明:
·如果公网OK,并且网速好的话,可以用ceph-deploy install node1 node2 node3命令来安装,但网速不好的话会比较坑
所以这里我们选择直接用准备好的本地ceph源或者阿里源ceph,然后yum install ceph ceph-radosgw -y安装即可。
第5步:客户端安装ceph-common
yum -y install ceph-common
交叉环境报错解决方法
同时安装了glusterfs和ceph,会冲突。
只能卸载,不卸载依赖 rpm -e 冲突的软件 --nodeps
然后把源删掉
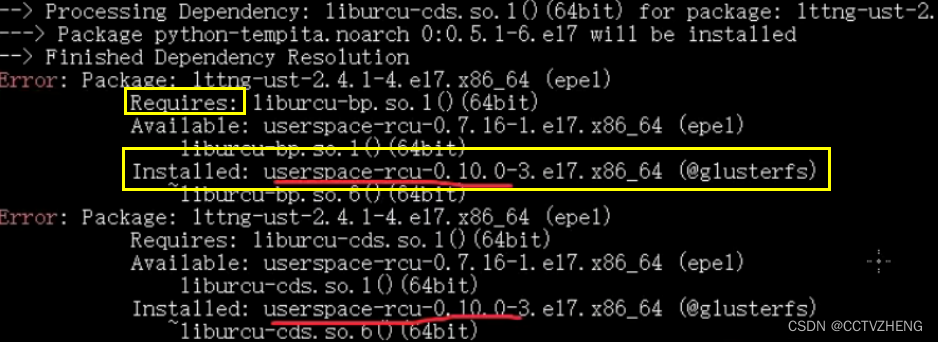
本来人家需要的软件被安装了,所以报错
第6步:创建mon(监控)
增加public网络用于监控
vim ceph.conf


监控节点初始化,并同步配置到所有节点(node1,node2,node3,不包括client)
ceph-deploy mon create-initial
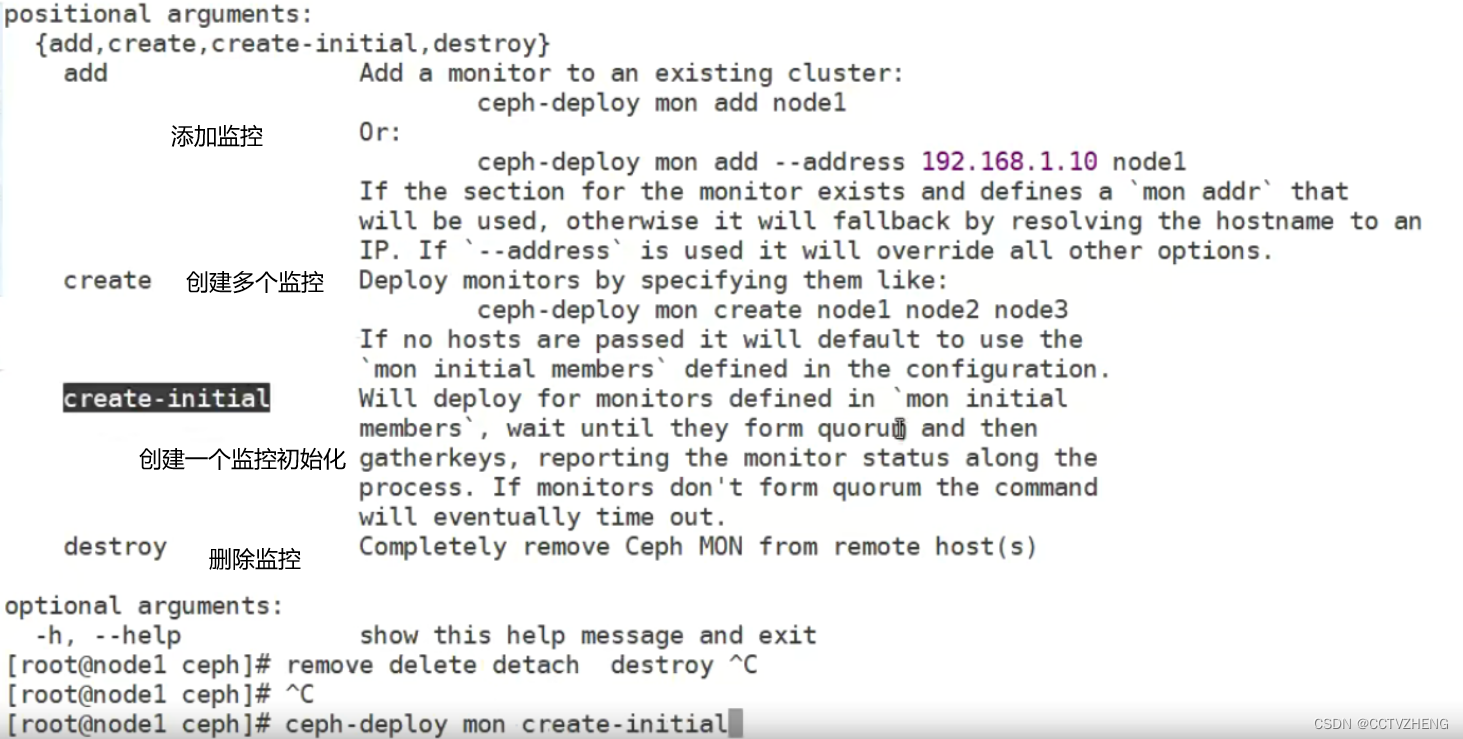
初始化监控节点安装完成之后查看集群状态
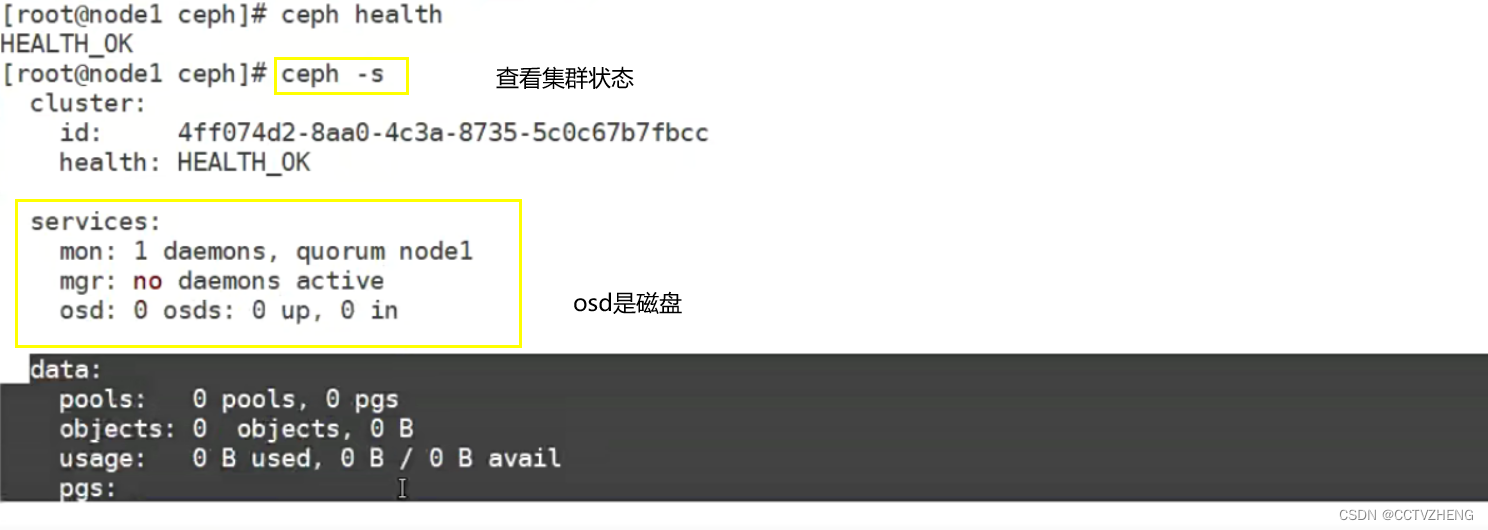
ceph health 查看集群健康
多个mon健康最好是奇数

多个监控容易出时间同步问题
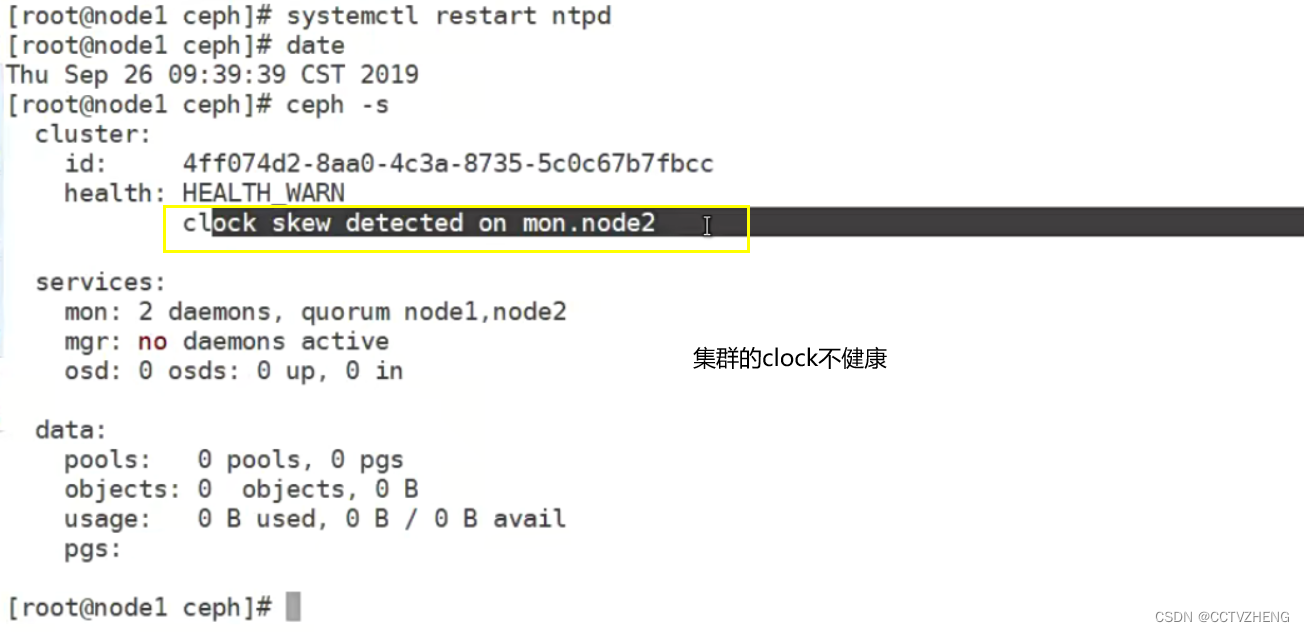
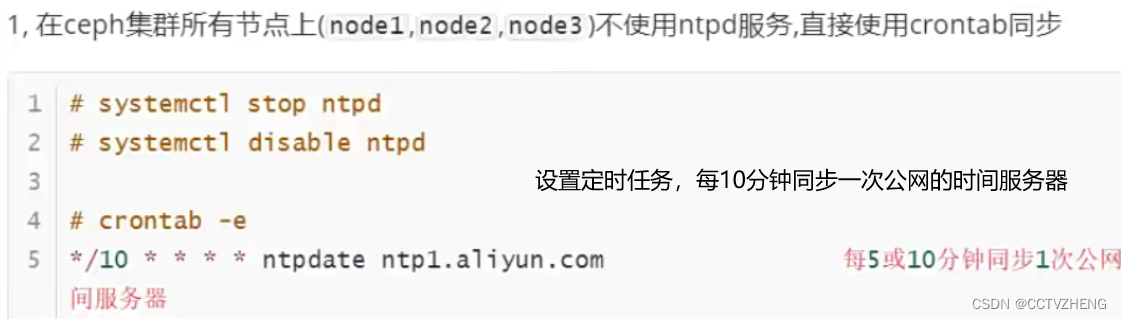
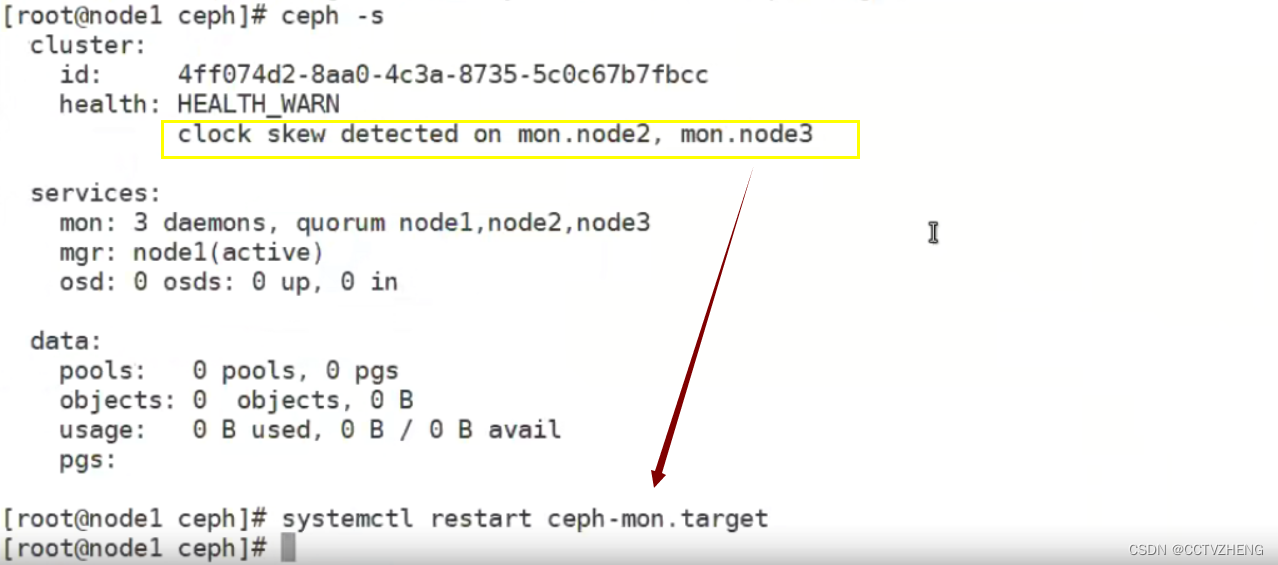
解决方法:

第7步:创建mgr(管理)
ceph luminous版本中新增加了一个组件: ceph Manager Daemon,简称ceph-mg
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。
创建一个mgr
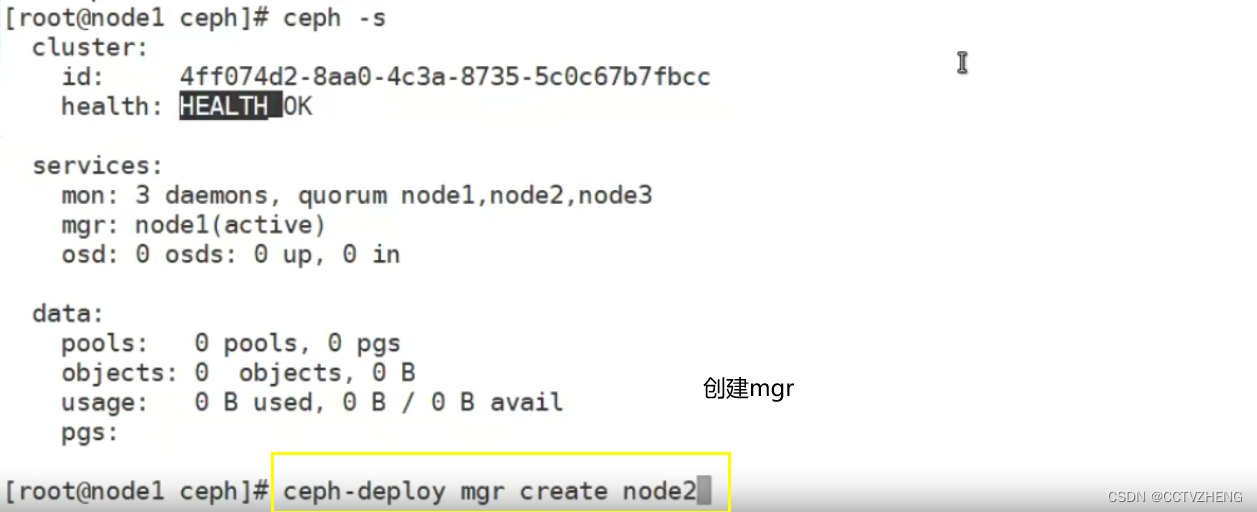
同理创建三个就行
第8步:创建osd(存储盘)
每个节点都必须提前就添加一块硬盘

列出所有磁盘,zap,清空数据,格式化,再创建存储盘
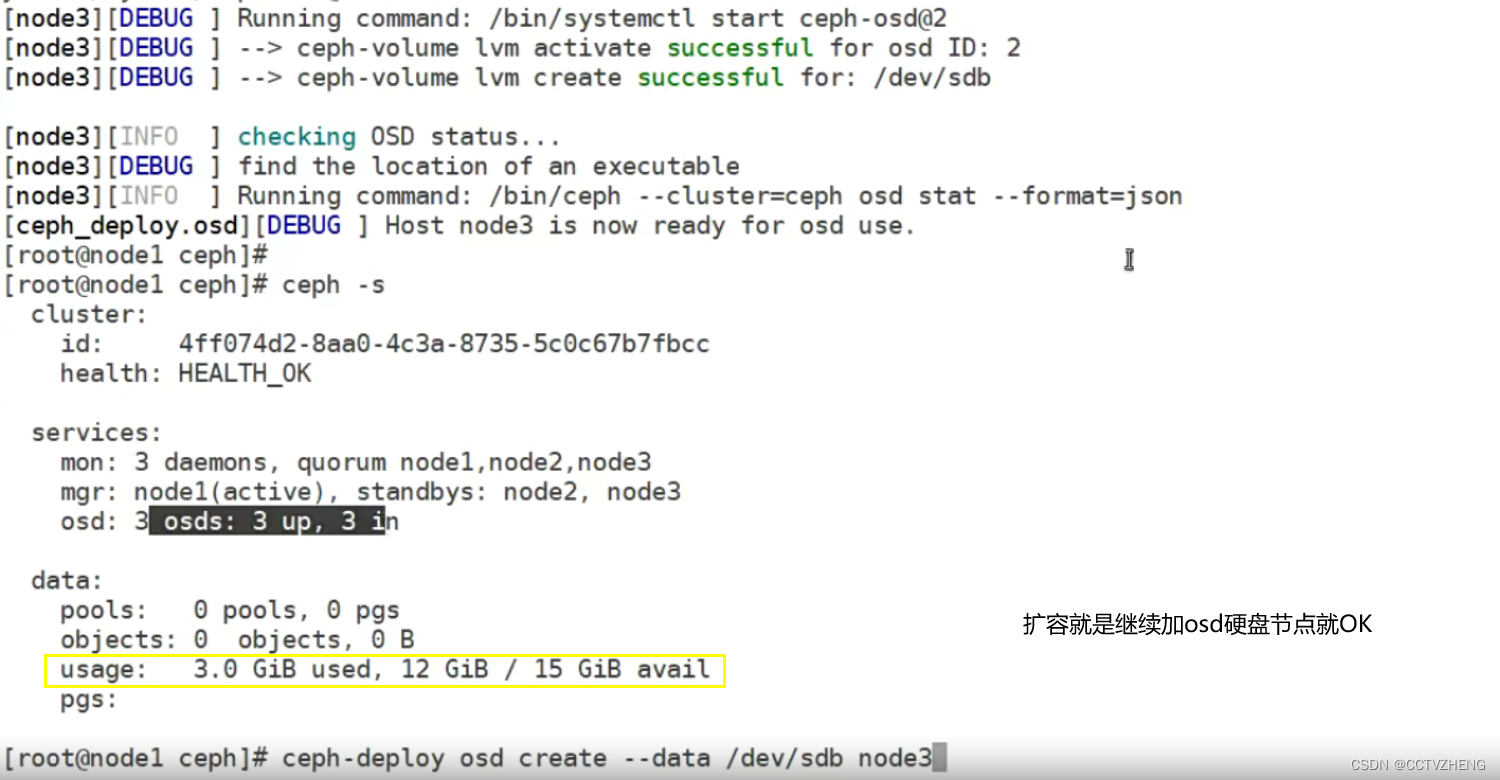
集群节点的扩容方法
假设再加一个新的集群节点node41,主机名配置和绑定
2,在node4上yum insta1l ceph ceph-radosgw -y安装软件
3,在部署节点node1上同步配置文件给node4. 'ceph-deploy admin node44,按需求选择在node4上添加mon或mgr或osd等
RADOS存储原理
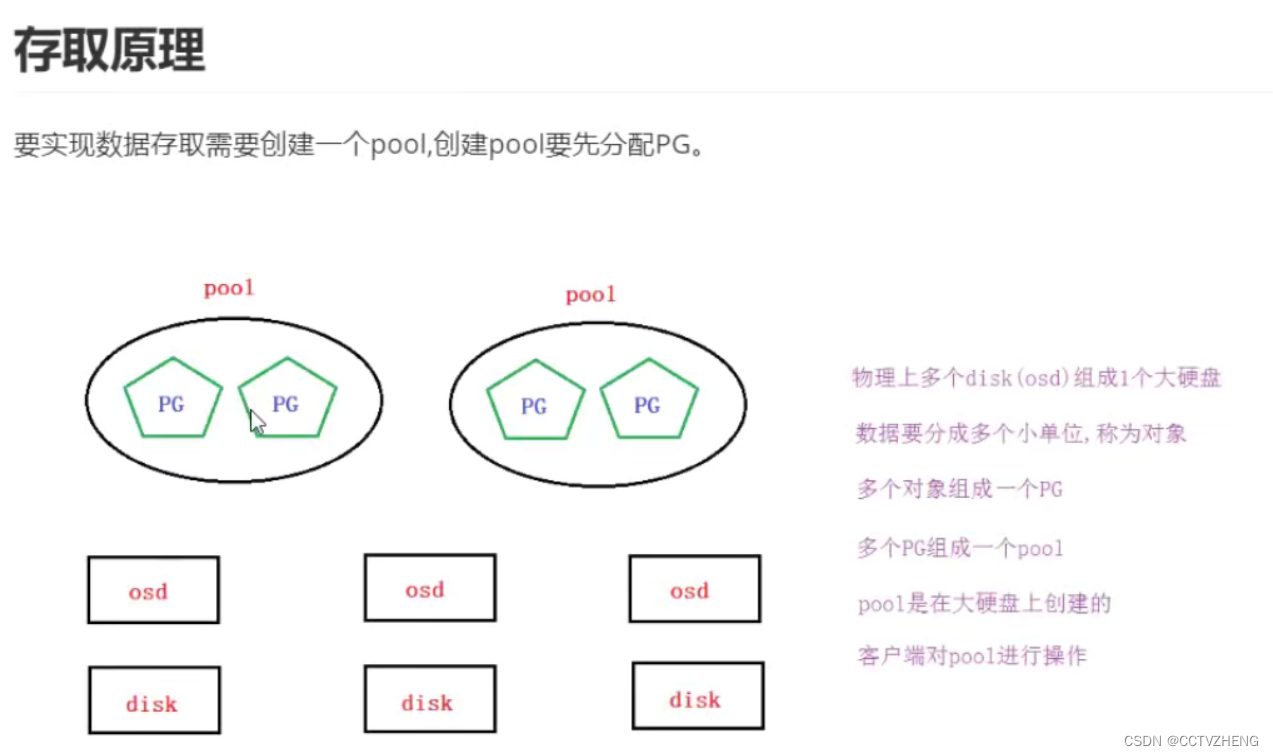
了解就行
五、创建ceph文件存储
要运行Ceph文件系统,你必须先创建至少带一个mds的Ceph存储集群.(Ceph块设备和Ceph对象存储不使用MDS)。
Ceph MDS: Ceph文件存储类型存放与管理元数据metadata的服务(元数据就是磁盘里面什么都没有,然后还占空间的,那些其实就是属性)
创建文件存储并使用
第1步:在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)

第2步:一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,另一个用于元数据


第4步:客户端准备验证key文件
·说明: ceph默认启用了cephx认证,所以客户端的挂载必须要验证在集群节点(node1,node2,node3)上任意一台查看密钥字符串
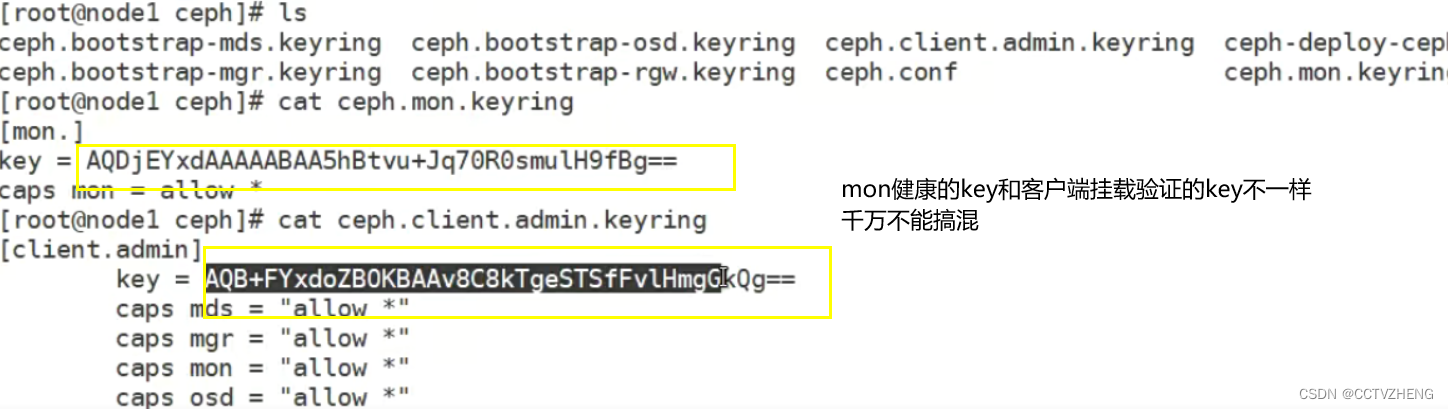
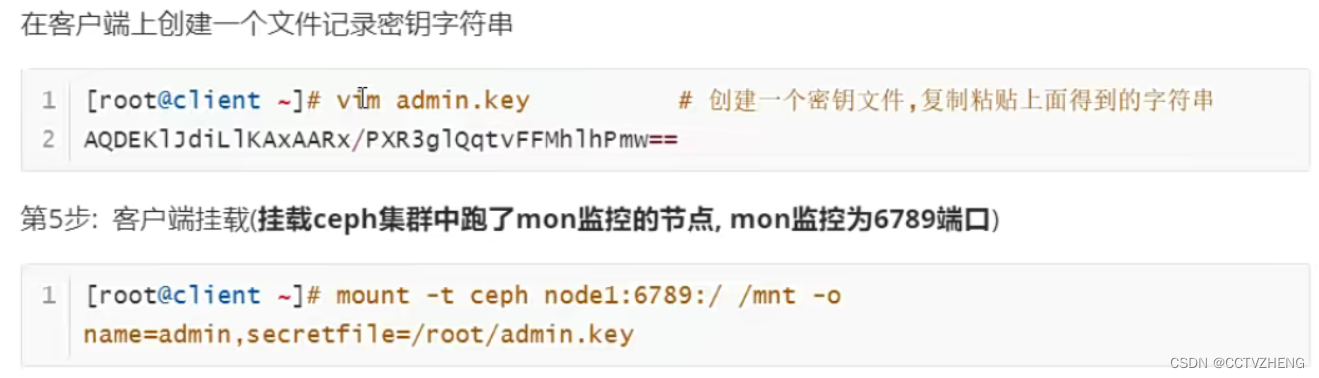
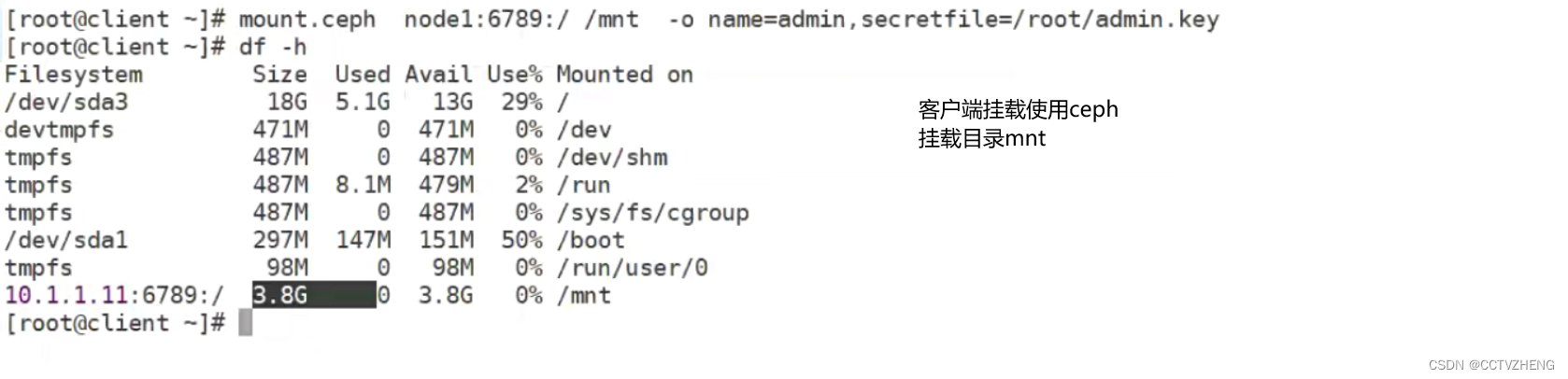
客户端通过密钥文件挂载ceph到/mnt
删除文件存储的步骤
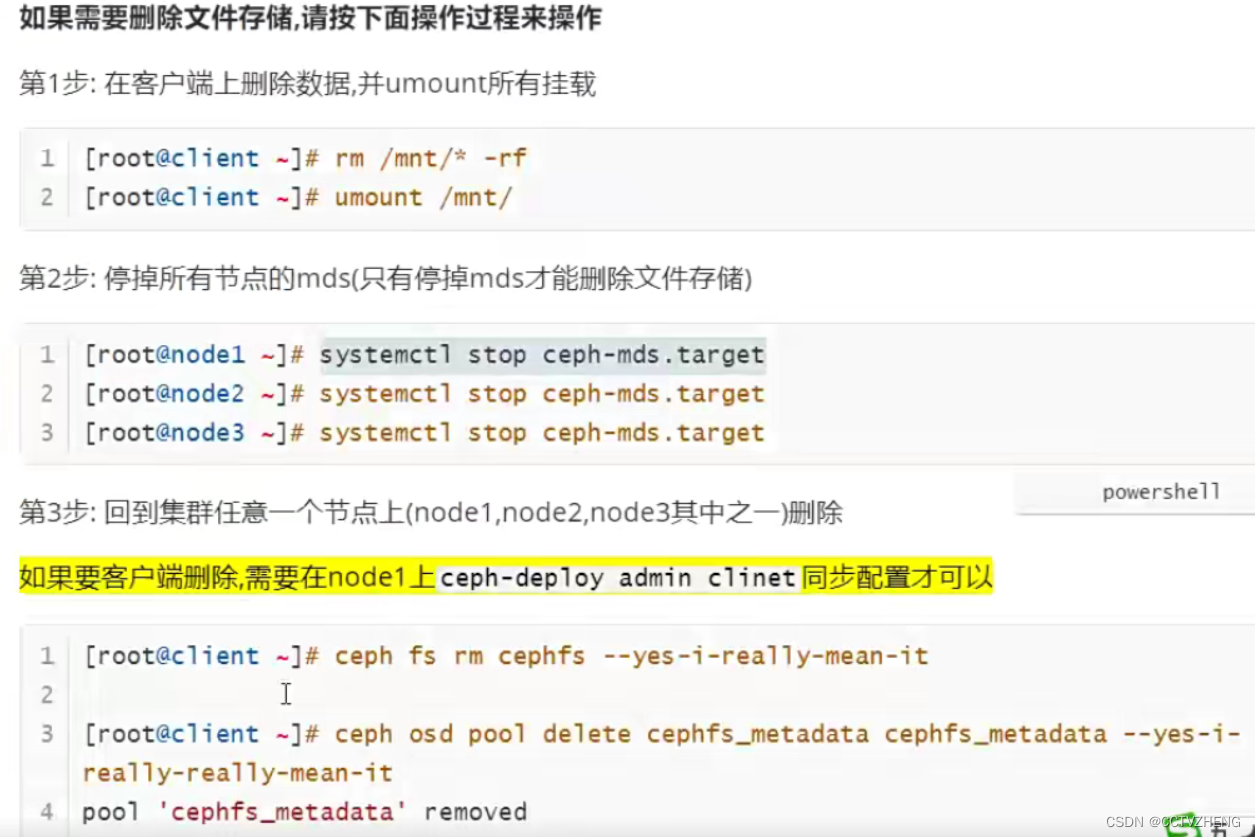


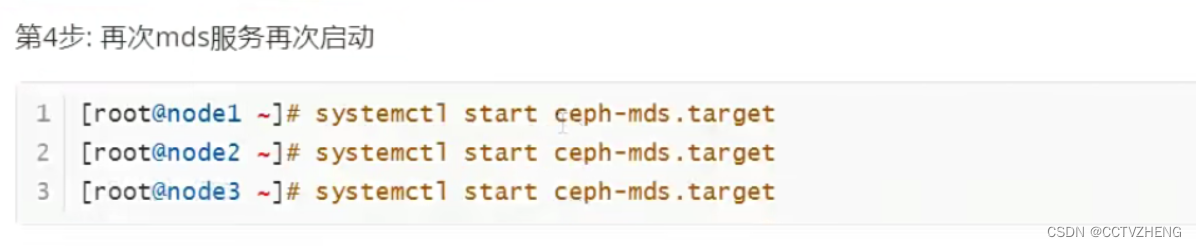
如果还要创建mds,必须重新开启mds服务
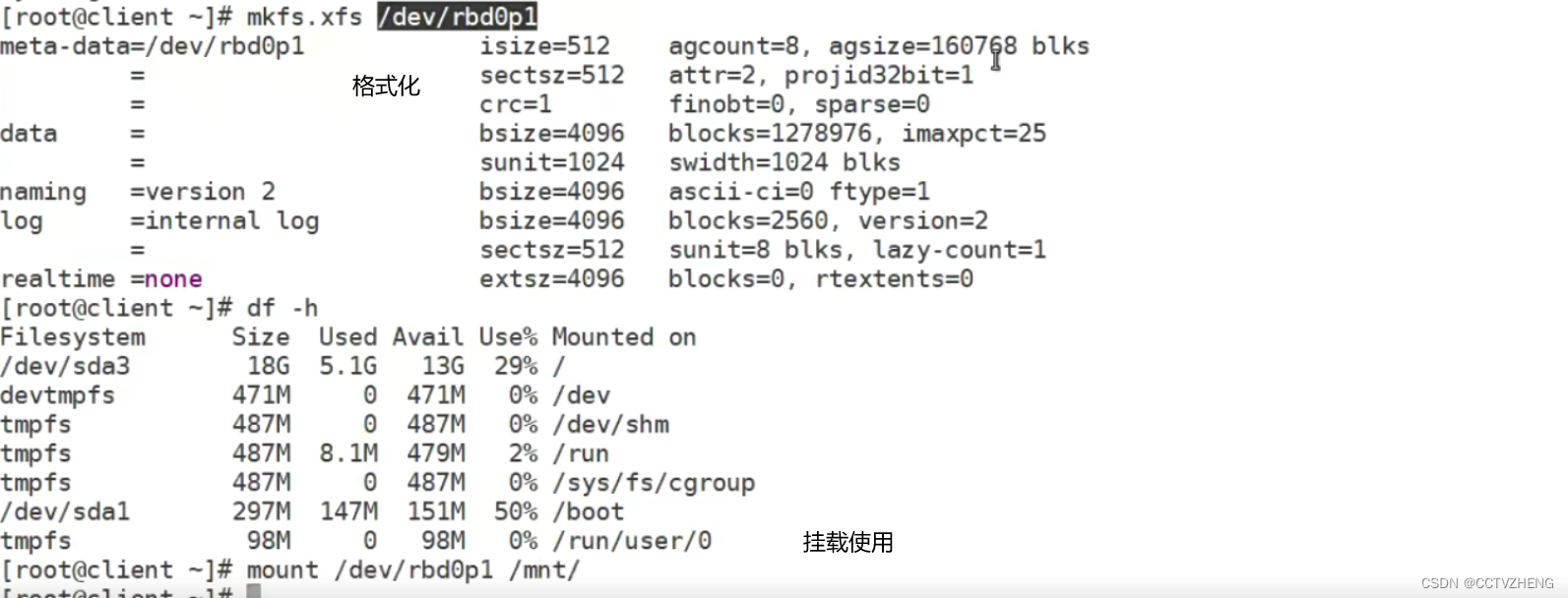
创建ceph块设备存储
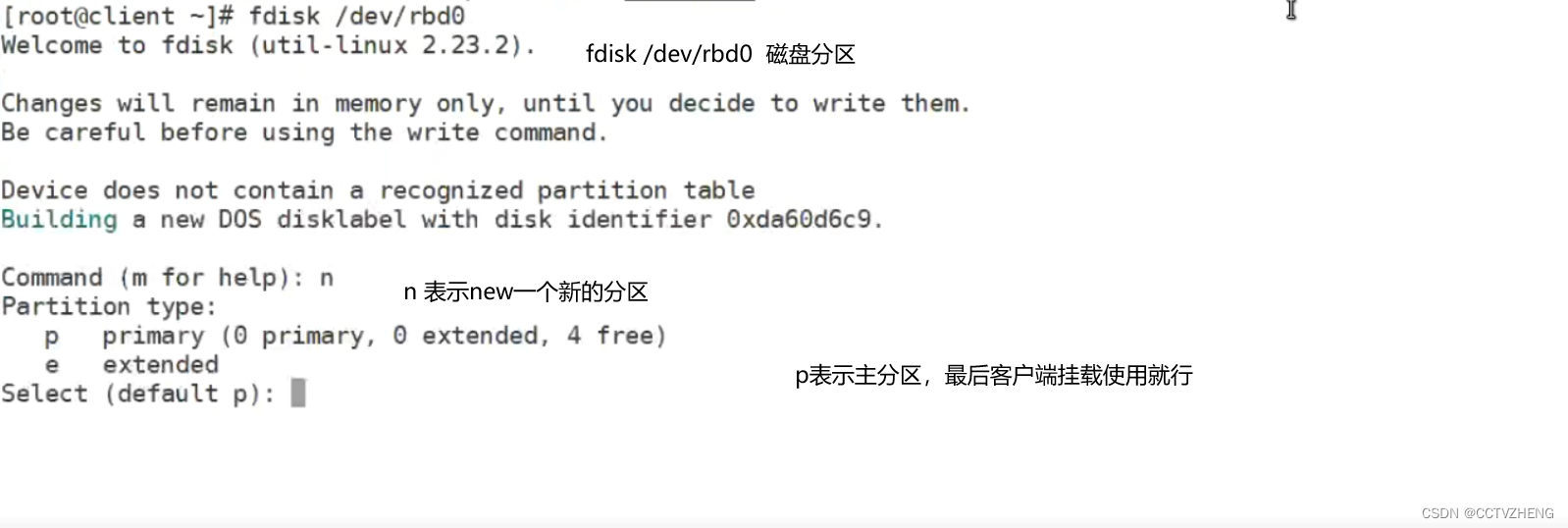
分区是可以分,就是后面扩容很可能失败
ceph块设备扩容
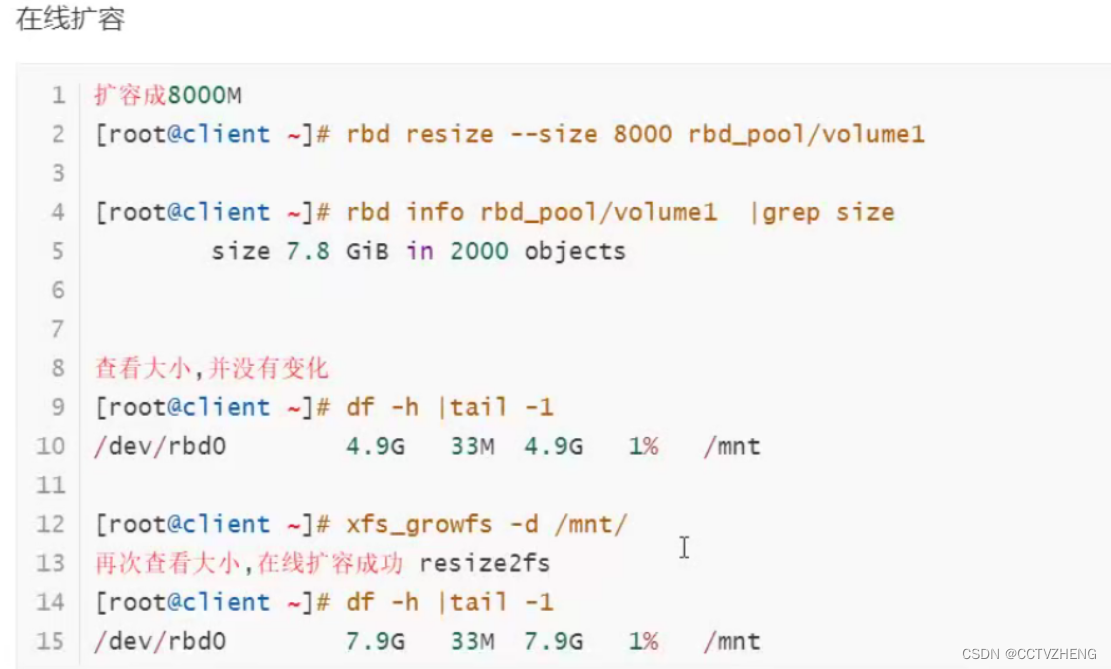
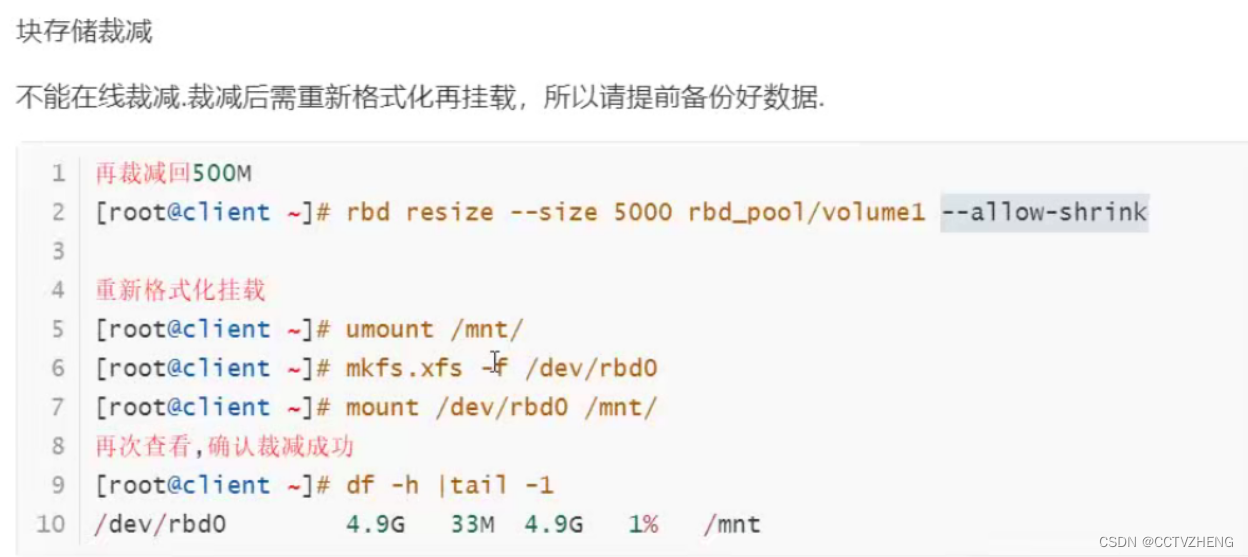
shrink缩水
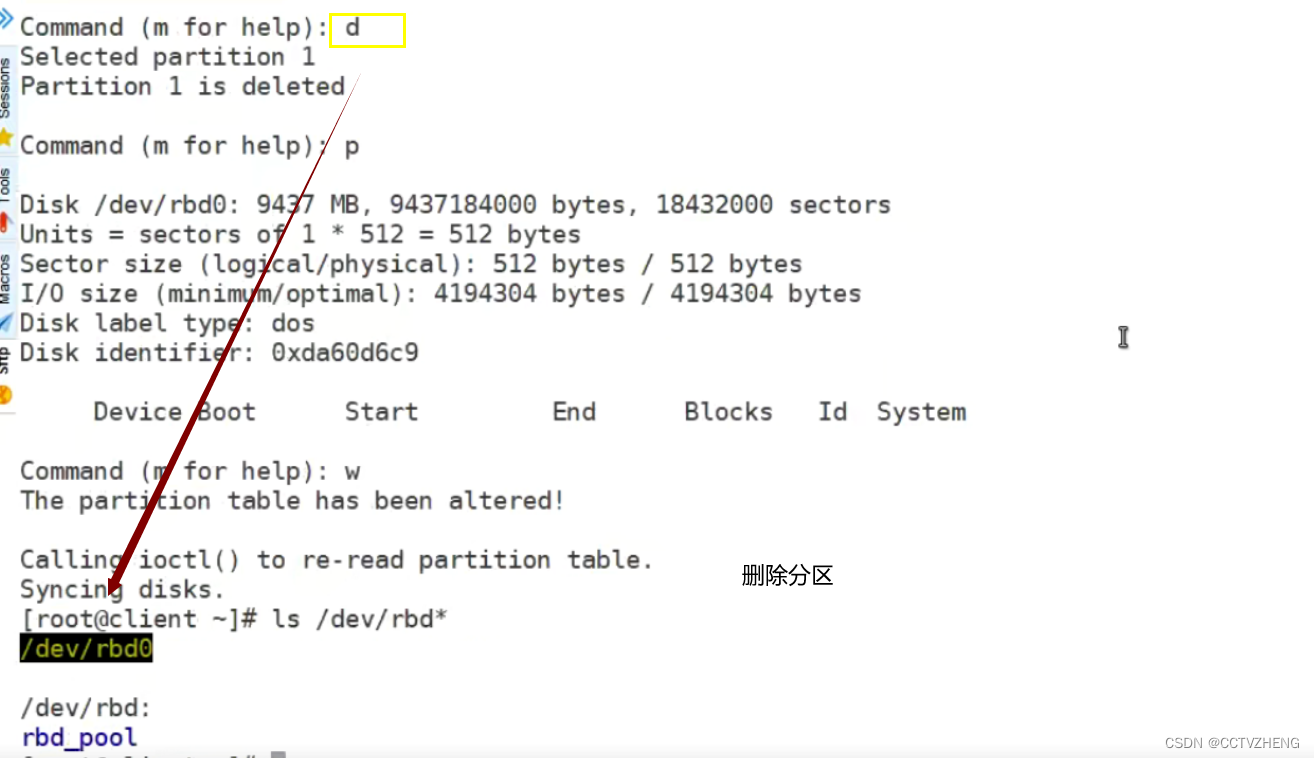
删除分区才能正常扩容,但是扩容的大小不是实际值
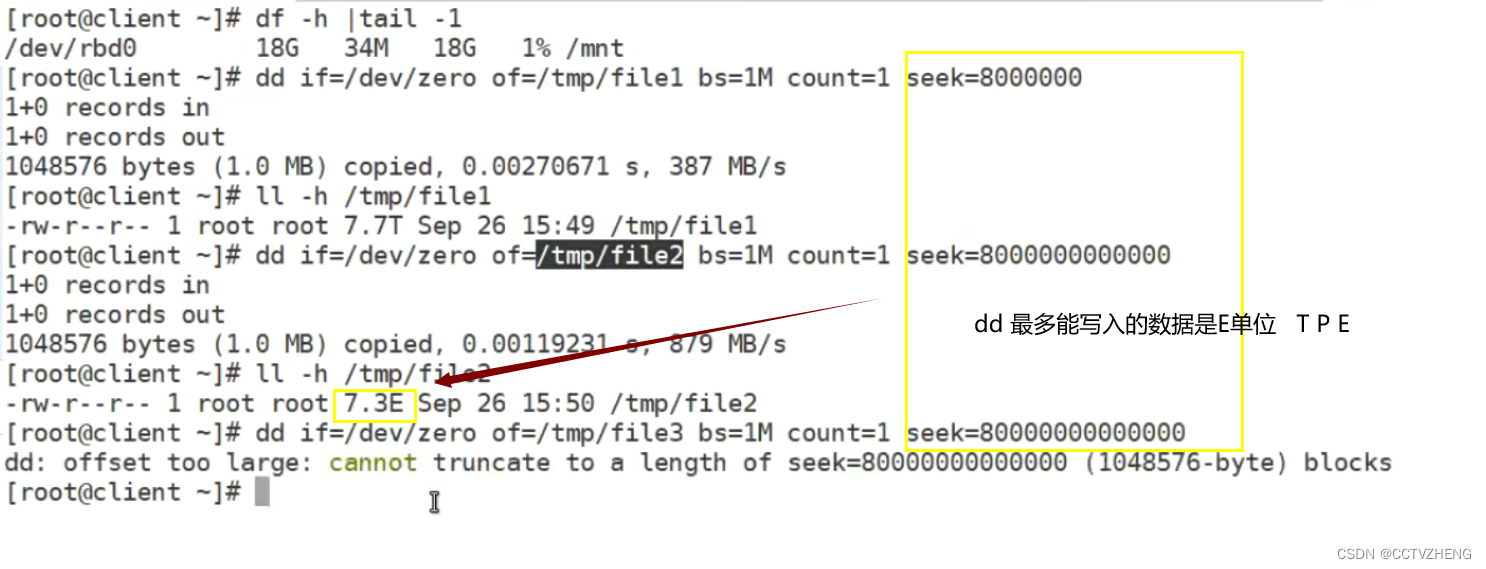
xfs文件系统最多可以扩容到E
六、Ceph对象存储
测试ceph对象网关的连接
第1步:在node1上创建rgw(对象存储网关)
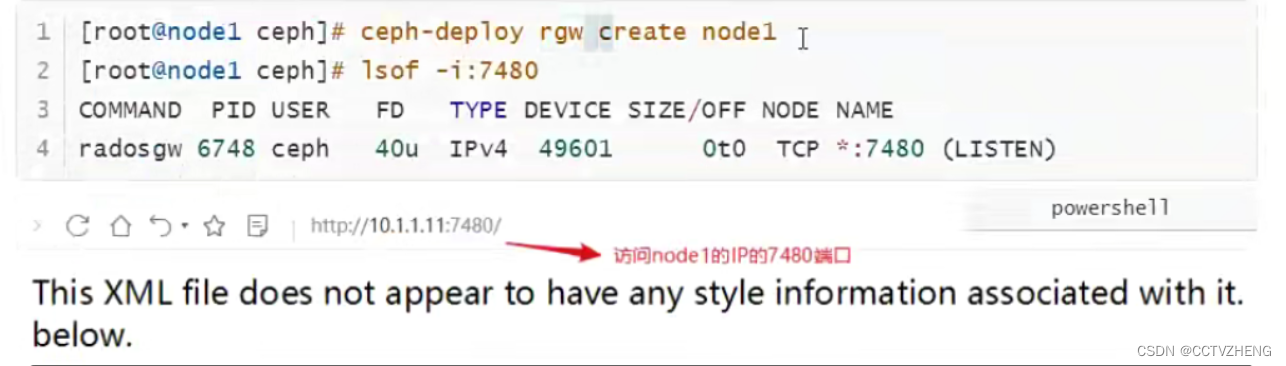
第二步:在客户端创建一个用户(客户端必须安装了ceph客户端工具)


display,一定要加,是别名
S3连接ceph对象网关
s3cfg的配置文件复制给另外一台客户端相当于同一个账户换了一台电脑
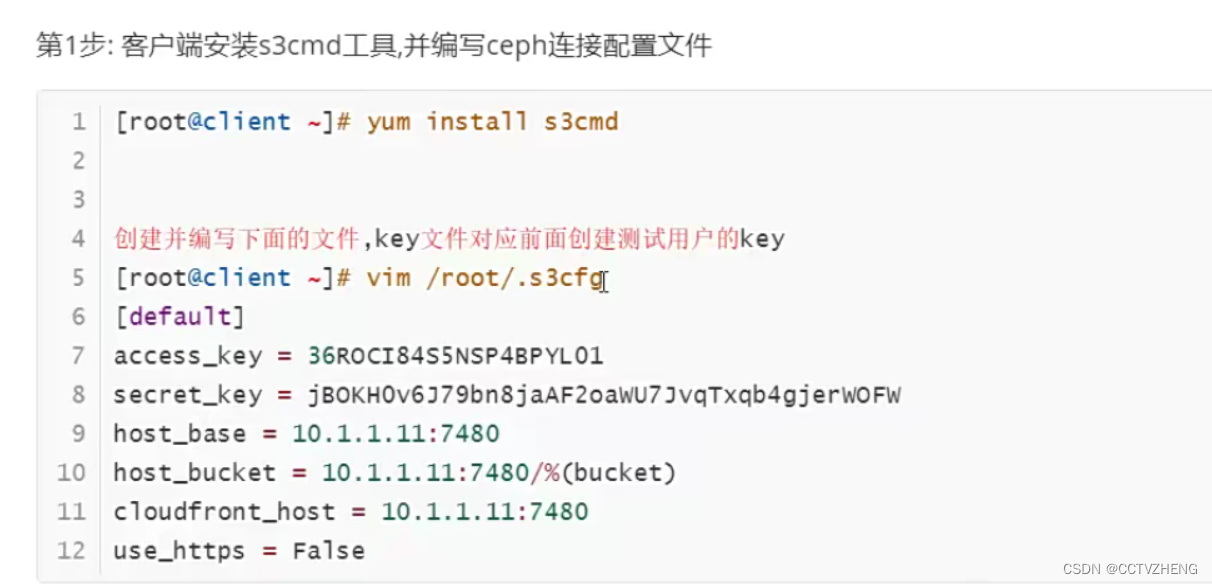
bucket桶就是对象存储里面的目录
不用https加密传输
把配置文件里面的密钥、IP、端口号、配置好之后就可以创建一个桶
全世界只有一个桶,不能同名,不能文件共享,类似百度云盘,只能共享链接,分享

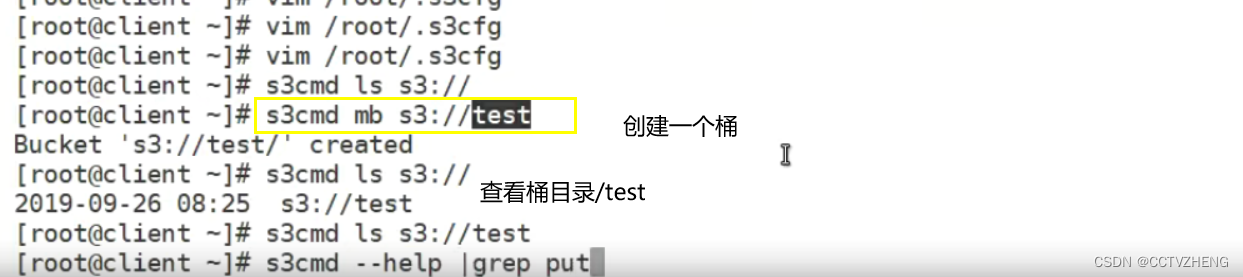
可以制作一个云盘















 6777
6777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









