






 本文介绍了ApacheHive作为分布式SQL计算工具的作用,它如何将SQL转换为MapReduce任务,以及为何选择Hive以降低开发成本和简化复杂查询。重点讨论了Hive的架构、使用Hive处理数据的好处和Metastore元数据管理器的角色。
本文介绍了ApacheHive作为分布式SQL计算工具的作用,它如何将SQL转换为MapReduce任务,以及为何选择Hive以降低开发成本和简化复杂查询。重点讨论了Hive的架构、使用Hive处理数据的好处和Metastore元数据管理器的角色。
Apache Hive 概述
分布式SQL计算
1.以分布式的形式,执行SQL语句,进行数据统计分析
2.对数据进行统计分析,SQL是目前最为方便的编程工具。
3.大数据体系中充斥着非常多的统计分析场景,使用SQL去处理数据,在大数据中是有极大的需求的

4.不过MapReduce支持程序开发(Java、Python等),但不支持SQL直接进行开发,所以,我们要用到Apache Hive(一款分布式SQL计算的工具), 其主要功能是:将SQL语句 翻译成MapReduce程序运行。即:基于Hive为用户提供了分布式SQL计算的能力、写的是SQL、执行的是MapReduce。
为什么使用Hive
- 使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高 需要掌握java、Python等编程语言
- MapReduce实现复杂查询逻辑开发难度太大
Apache Hive是做什么的
-
将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。
-
传统MapReduce开发:写MR代码->得到结果
-
使用Hive开发:写SQL->得到结果
-
底层都是MR在运行,但是使用层面上更加简单了。
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)、Hive会将写入的HiveSQL语法自动转成MR任务, 交由Yarn来调度执行.
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理
注:Hive是依赖Hadoop的, 想使用Hive, 必须先搭建和启动Hadoop集群.
基于MapReduce构建分布式SQL执行引擎,主要需要有元数据管理器、SQL解析器
- 元数据管理器:维护和管理元数据的, 且要能存储元数据.
- SQL解析器:解析SQL语法的, 就将其转成MR任务.
- 分析的结果图, 如下:
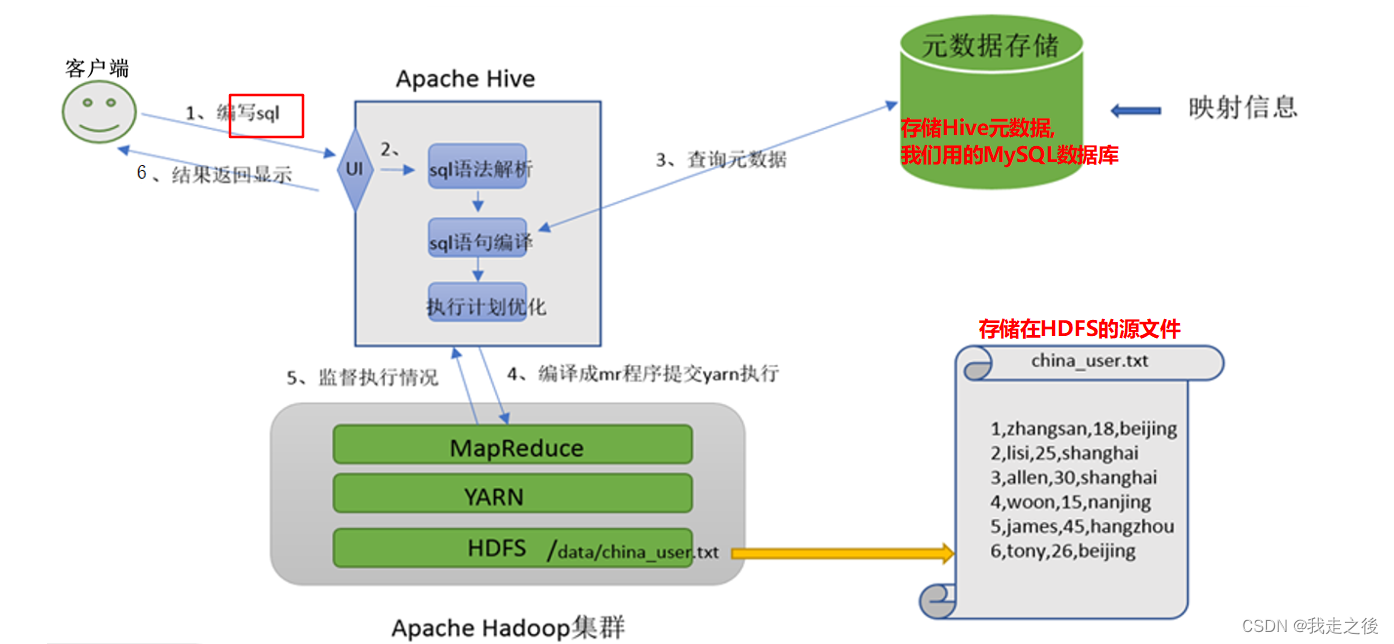
Apache Hive架构图
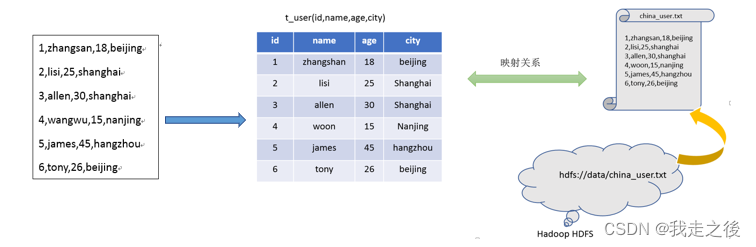
Hive本质
把HDFS文件映射成1张Hive表,然后就可以写HiveSQL表分析,底层会被解析成MR任务交由Yarn调度执行。
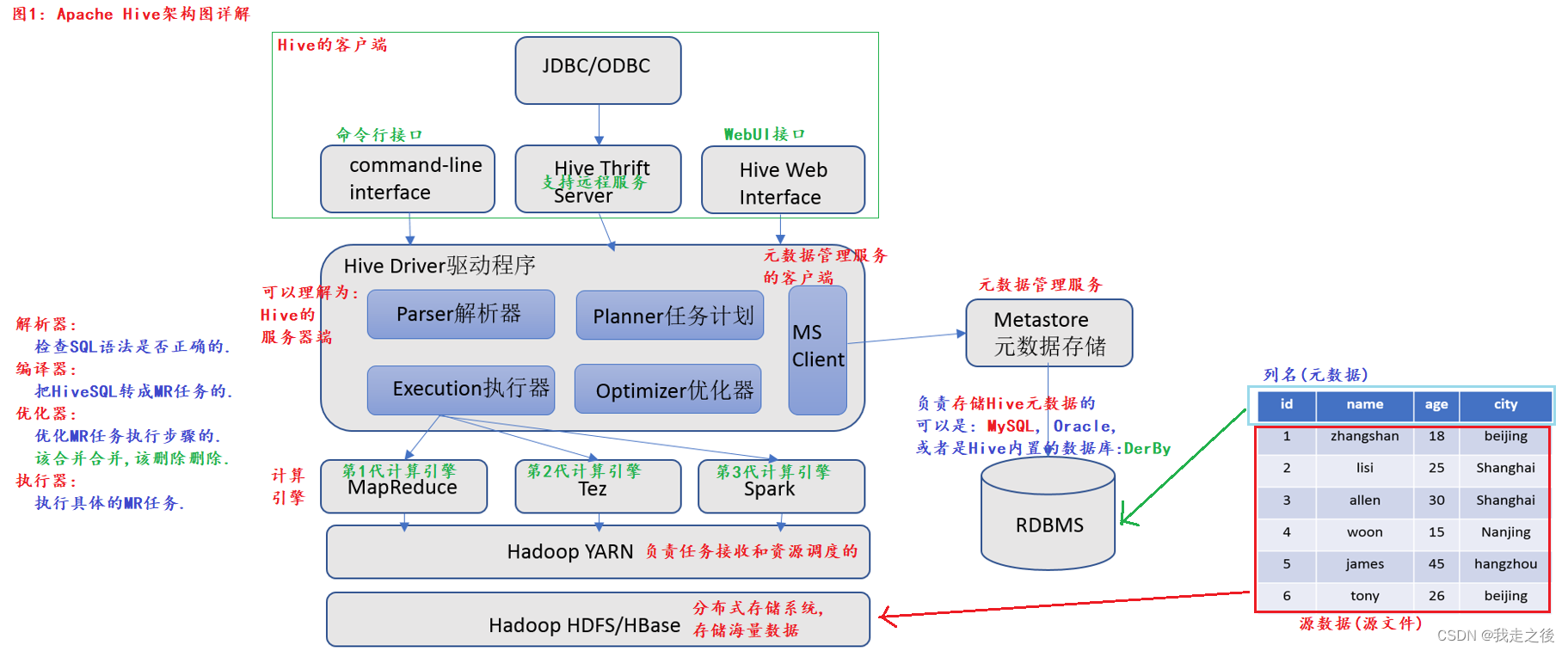
Hive的架构图
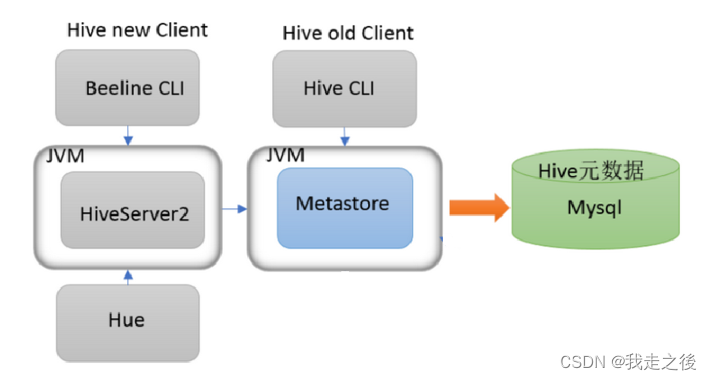
用户接口(Hive的客户端)
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
Driver驱动程序(Hive的服务器端)
解析器:检查SQl语法是否是正确的
计划编译器:把HiveSQL转成MR任务
优化器:优化MR任务执行步骤(合并、删除)
执行器:执行具体的MR任务
作用: 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Metastore元数据存储
元数据包含:用Hive创建的database、table、表的字段等元信息。
元数据存储:存在关系型数据库中,如:hive内置的Derby数据库或者第三方MySQL数据库等。
Metastore:即元数据存储服务,作用是:客户端连接metastore服务,metastore再去连接MySQL等数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL等数据库的用户名和密码,只需要连接metastore 服务即可。
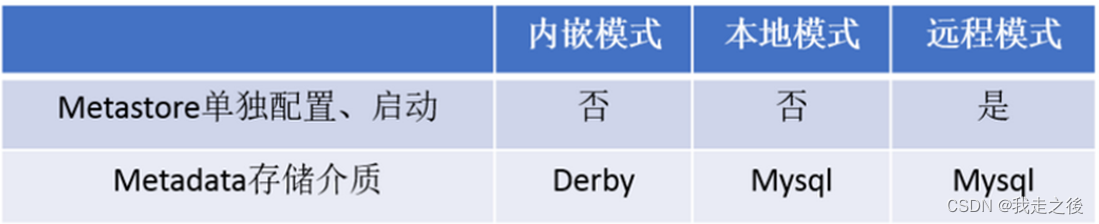
注意:metastore服务配置有3种模式:内嵌模式、本地模式、远程模式
远程模式(推荐使用)
优点: 可以单独使用外部库(mysql) ,可以共享元数据,可以连接metastore服务也可以连接hiveserver2服务,metastore可以单独启动,配置 其他依赖hive的软件都可以通过Metastore访问hive。
缺点: 需要注意的是如果想要启动hiveserver2服务需要先启动metastore服务。
Hive元数据存储三种模式的区别















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









