







链表基础知识
1.链表概念
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头结点也就是head。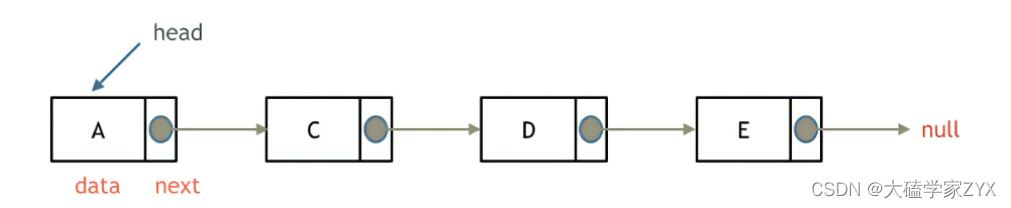
2.链表的类型
单链表
上面说的这种链表就是单链表,要区分单链表和stl中List容器的区别。区别整理在后面。
双链表
另一种叫做双链表。单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。

循环链表
循环链表,顾名思义,就是链表首尾相连。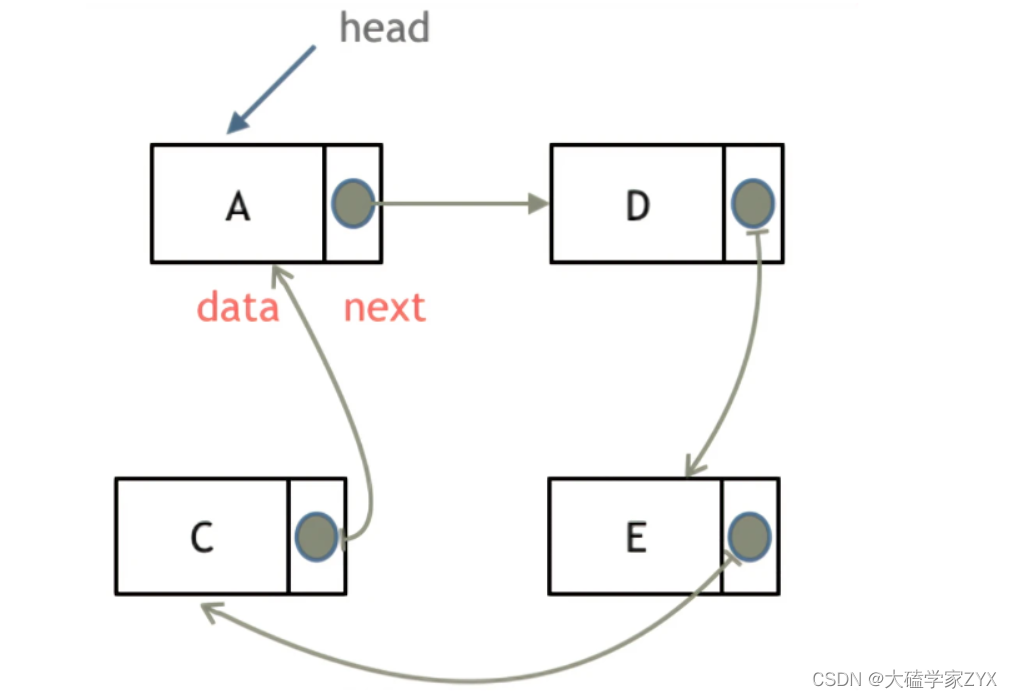
循环链表可以用来解决约瑟夫环问题。
3.链表存储方式
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。

图上这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
4.链表ListNode与STL中list容器的区别
listNode和STL中的list容器在设计和使用上有一些重要的区别:
- 设计原理:
listNode通常是一个简单的自定义数据结构,通常包含数据和指向其他节点的指针。这是链表数据结构的基础,它允许我们添加、删除和搜索节点。而STL中的list是一个双向链表容器,它不仅提供了基础的链表操作,还提供了大量的其他功能,如排序、逆序、合并等。 - 接口和操作:
listNode通常需要用户自己实现所有的操作,如添加节点、删除节点、搜索节点等。这需要对链表数据结构有一定的理解。而list提供了一套丰富的接口,可以很方便地进行各种操作,如插入、删除、排序、查找等,而无需用户了解链表的底层实现。 - 容器特性:
STL的list是一个容器类,可以存储任何类型的元素,例如,你可以有一个list<int>或list<string>等。而**listNode通常是针对特定类型的元素设计的,如果要存储其他类型的元素,可能需要重新设计listNode。** - 性能:在某些操作上,
list和listNode的性能会有所不同。例如,如果你需要频繁地在链表中间插入和删除元素,list可能会比listNode更快,因为list是双向链表,可以更快地找到插入和删除的位置。然而,如果你需要频繁地访问链表的头部和尾部元素,listNode可能会更快,因为它可以直接访问这些元素,而list需要遍历整个链表。 - 内存使用:一般来说,由于
list提供了更多的功能和接口,它可能会使用更多的内存。但这取决于具体的实现和使用情况。
总的来说,listNode和list各有其优点,根据你的具体需求和应用场景,你可以选择使用最适合的一个。
5.链表的定义方式
链表节点定义方式:
// 单链表的定义
struct ListNode{
int val; //节点上储存的元素
ListNode *next; //指向下一个节点的指针
ListNode(int x): val(x),next(NULL){
//节点的构造函数
}
}
自定义构造函数与不提供构造函数的区别:
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5); //定义指针,指向链表对象(虚拟头节点用法)
使用默认构造函数初始化节点:
ListNode* head = new ListNode();
head->val = 5;
所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
6.链表的操作
1.删除节点
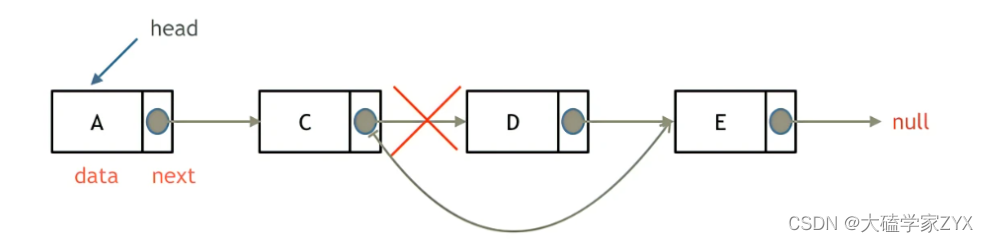
只要将C节点的next指针 指向E节点就可以了。
但,此时D节点不是依然存留在内存里,只不过是没有在这个链表里而已。
所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,不用自己手动释放。
手动释放内存的方法:
以移除链表元素的虚拟头节点算法为例,说明一下链表中节点被删除的过程。
1.让任意一个遍历链表的指针,跳过该元素指向该元素的下一个元素。
当cur->next->val == val,意味着cur->next指向的节点是要被删除的。然而在删除它之前,需要先将cur->next指向它的下一个节点,也就是cur->next = cur->next->next;。这样,要删除的节点就从链表中被移除了。
2.定义一个新指针暂时存储要删除的节点的地址,然后使用delete tmp;来删除这个节点,并释放它占用的内存。
但是,此时只是链表不再指向这个节点,并没有真正删除它。在C++中,使用new操作符动态创建的对象(如new ListNode(0))会在堆(heap)上分配内存,即使没有任何指针指向它,这块内存也不会被自动回收。如果不手动删除这些对象,会导致内存泄漏。
因此,需要使用delete操作符来删除这个节点,并释放它占用的内存。但是在**删除它之前,需要有一个指针指向它,否则就无法找到它的地址,也就无法删除它。**例子可以看下面虚拟头节点代码中的tmp指针。
总结:删除节点的过程
在链表数据结构中,删除一个节点的基本步骤如下:
- 首先,你需要一个指针来找到要删除的节点。这个指针通常是通过遍历链表得到的。
- 然后,你需要改变指向要删除节点的前一个节点的
next指针,使其跳过要删除的节点,直接指向要删除节点的下一个节点。这样,要删除的节点就从链表中被移除了。 - 最后,你需要删除这个节点,并释放它占用的内存。这就需要定义一个新的指针来暂时存储要删除的节点的地址,然后使用
delete操作符来删除这个节点。
这是删除链表节点的基本方法。当然,实际操作中可能会有一些变化,这取决于链表的类型(单链表、双链表等)以及具体的应用场景。例如,如果链表是双链表,就需要同时处理前一个节点和后一个节点的指针。另外,如果要删除的节点是链表的头节点或尾节点,可能也需要特殊处理。
(注意:第二步中,是改变任意一个遍历指针的指向就可以的。比如虚拟头节点代码中 cur->next = cur->next->next;改变节点指向,用的是遍历指针cur。)
提问:是否可以不使用遍历指针的情况下,删除链表元素?
实际上,**在链表中删除一个元素,总是需要进行遍历才能找到需要删除的元素。**这是因为链表是一种线性数据结构,我们只能从头节点开始,按照链表的顺序一个一个检查节点。
但是,如果我们已经有了直接指向目标节点的指针,那么在一些特定情况下,我们可以在不进行完整遍历的情况下删除元素。例如,如果链表是一个双向链表,我们可以利用目标节点的前后节点指针来删除元素。
这里是一个例子,假设node是一个指向双向链表中目标节点的指针:
void deleteNode(ListNode* node) {
if (node->prev != NULL) {
node->prev->next = node->next;
}
if (node->next != NULL) {
node->next->prev = node->prev;
}
delete node;
}
2.添加节点

可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
关于链表删除的时间复杂度操作,gpt4给出的回答:

在谈论数据结构操作的时间复杂度时,我们通常假设我们已经在所需要的节点处。对于链表结构,如果我们已经有一个指向要删除的节点的指针,那么删除该节点的操作只需O(1)的时间。这就是为什么我们通常说链表的删除操作是O(1)的。
但你提到的问题是非常实际的。在实际情况中,我们通常需要先找到要删除的节点,这确实需要O(n)的时间,n是链表的长度。因此,如果我们考虑查找和删除两个步骤,那么整个删除操作的时间复杂度是O(n)的。
7.链表性能分析
再把链表的特性和数组的特性进行一个对比,如图所示:
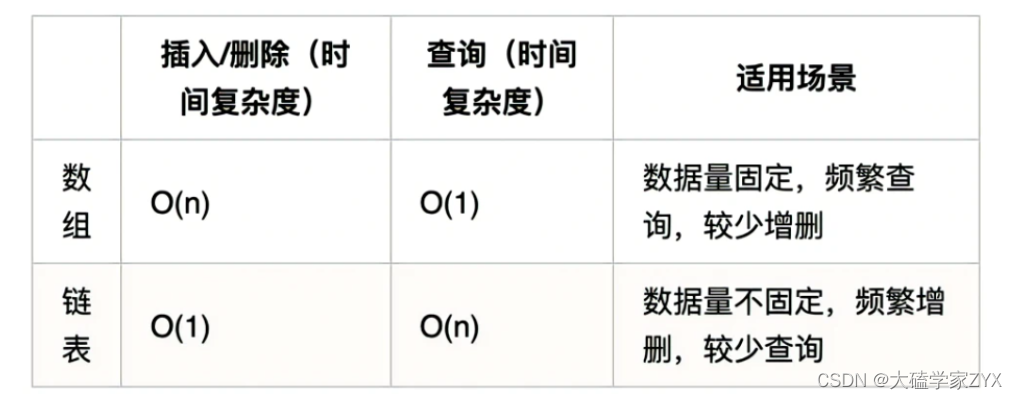
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
题目练习:203.移除链表元素
使用虚拟头节点(dummy head)的方式,统一头节点和非头节点的删除方式,不需要if再判断该节点是不是头节点
1.不使用虚拟头节点
(先确保不为空,操作空指针的话编译会报错)
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 删除头结点
while (head != NULL && head->val == val) { // 注意这里不是if
ListNode* tmp = head;
head = head->next;
delete tmp;
}
// 删除非头结点
ListNode* cur = head;
while (cur != NULL && cur->next!= NULL) {
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
return head;
}
};
注意:
-
不用虚拟头节点的话,需要考虑两种情况,第一种是head本身就符合删除条件,第二种是head本身不符合删除条件。
-
c++需要进行手动内存释放!也就是指针
tmp做的事情。 -
检查指针是否为空,空指针会报错。
-
移除头节点是一个持续移除的操作,因此应该使用while而不是if操作
-
定义的临时指针是从head开始的,而不是从head的下一个元素开始。原因在于,如果我要删除该元素,我需要找到这个元素的前一个元素。
如果head的下一个元素刚好是需要删除的,但这是一个单向链表,无法找到这个节点的上一个节点,该元素就无法删除。
-
因此,临时指针current必须从=head开始,而不是head->next.
2.使用虚拟头节点
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
//注意:listNode* 表示一个listNode类型的指针,而listNode表示一个链表类型的对象
//ListNode对象包括一个表示其值val和指向下一个对象的指针next.
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head; //head是算法输入直接给出的头节点,注意指针指向头节点
ListNode* cur = dummyHead;//临时指针cur不要重新定义,需要令cur和dummyHead指向同一块内存。
while(cur->next!=NULL){
//链表遍历结束的标志:最后一个节点的next指针为空
//遍历未结束的时候,判断内容是否等于val
if(cur->next->val==val){
//如果相等,那么需要删除,先定义新指针存储需要删除的节点地址
ListNode* tmp = cur->next;
//再令遍历指针删除该节点
cur->next = cur->next->next;
//根据刚刚新建的指针找到该节点内存地址,手动释放内存
delete tmp;
}
else
//cur->next++;注意,链表中的指针++没有意义,因为链表内存不连续
cur = cur->next;
//
}
//返回新的头节点
return dummyHead->next; //此处dummyHead->next才是新的头节点
}
};
注意:
-
dummy head是new出来一个新的节点,让他的next指向原来链表的head. -
定义一个临时指针cur,用来遍历整个链表。注意不能用头节点来遍历,头节点遍历会导致头节点指向的值是在不断改变的。最后会无法返回原先列表的头节点。头结点指针是不能改的,需要定义临时指针。
-
临时指针指向虚拟头节点,而不是真的头节点。因为是单向链表。
-
一定要记住时刻判断指针是否为空。
-
return的时候,题目要求返回删除后新的头节点,此时我们return的不是head,而是虚拟头节点的下一个。不return head的原因是head有可能已经被删了。只有**
dummy_head->next才是新链表的头节点**。一定不要return head。
做题过程遇到的问题:
listNode*而不是listNode的原因
注意第一句new的用法,new是生成一个指向listNode对象的指针。
因此,生成的虚拟头节点,实质上是一个指向链表第一个head对象的指针。
C++中,ListNode*表示一个ListNode类型的指针,而ListNode表示一个ListNode类型的对象。在C++中,对象和指针是两个不同的概念。
- 对象(Object):在C++中,一个对象是内存中的一块区域,这块区域包含了数据和与这些数据相关的操作。在你的代码中,
ListNode对象包括一个表示其值(val)的整数和一个指向下一个ListNode的指针(next)。 - 指针(Pointer):指针是一种特殊的变量,其值为另一个变量的地址。在你的代码中,
ListNode*是一个指针,它的值是一个ListNode对象在内存中的地址。
在代码中使用ListNode*的原因是,希望通过指针来操作链表。链表是一种动态数据结构,需要频繁地插入和删除节点,如果使用对象(即ListNode)来操作,那么在插入和删除时就需要大量的复制和移动操作,这在性能上是不可接受的。
然而,如果使用指针(即ListNode*),你可以通过改变指针的指向来改变链表的结构,无需移动和复制大量的数据。因此,在处理链表这种动态数据结构时,通常会使用指针。
本算法是删除链表中所有值为给定值的节点,函数的参数是一个指向链表头节点的指针(ListNode* head)和一个整数(int val)。函数通过改变链表中的指针来删除所有值为val的节点,最后返回删除节点后的链表的头节点。
链表遍历结束的标志
q: while (cur->next != NULL),这一句,指的是当这个链表被完全遍历结束之后,cur->next就是NULL吗?但是此处的链表没有说遍历结束之后是什么,意思是链表被遍历结束之后。最后一个元素的后面本来就会是空的吗?
a: 是的,你的理解是正确的。
在**单链表(linked list)**这种数据结构中,每个节点(node)包含一个数据元素和一个指向下一个节点的指针。链表的最后一个节点的“下一个节点”指针通常会被设置为NULL,表示这是链表的结束。
所以,while (cur->next != NULL)这个循环会一直执行,直到cur指向链表的最后一个节点。因为对于链表的最后一个节点来说,cur->next就是NULL,所以这时候循环就会结束。
这也是链表和数组或其他线性数据结构的一个主要区别:数组有一个固定的长度,你可以直接访问数组的任何位置;而链表没有固定的长度,如果你想找到链表的最后一个元素,你就必须从链表的头部开始,沿着每个节点的“下一个节点”指针一直走到最后。
为什么是cur->next->val 而不是cur->next.val?
在C++中,指针和对象的成员访问方式是不同的。
- 对于对象,我们使用
.操作符来访问其成员。比如,如果obj是一个ListNode对象,我们可以使用obj.val来访问其val成员。 - 对于指针,我们使用
->操作符来访问其指向对象的成员。比如,如果p是一个指向ListNode对象的指针,我们可以使用p->val来访问其指向的对象的val成员。
所以,在代码中,cur->next是一个指向下一个ListNode对象的指针,因此我们需要使用->操作符来访问其val成员,即cur->next->val。
另外,如果想使用.操作符来访问指针指向的对象的成员,我们需要先对指针进行解引用(dereference)。比如,(*p).val和p->val是等价的,它们都表示p指向的对象的val成员。但是,->操作符更常用,因为它更简洁,更容易读。
补充:cur->next到底是什么
cur->next 是指向虚拟头节点的 next 指针。
在代码中,我们创建了一个虚拟头节点 dummyHead,它的作用是为了方便操作链表。我们将 cur 指针初始化为 dummyHead,然后使用 cur->next 来访问和修改链表中的节点。
当我们执行 cur->next = cur->next->next; 时,我们实际上是在修改虚拟头节点的 next 指针,从而删除了链表中的一个节点。
所以,cur->next 在这段代码中是指向虚拟头节点的 next 指针。
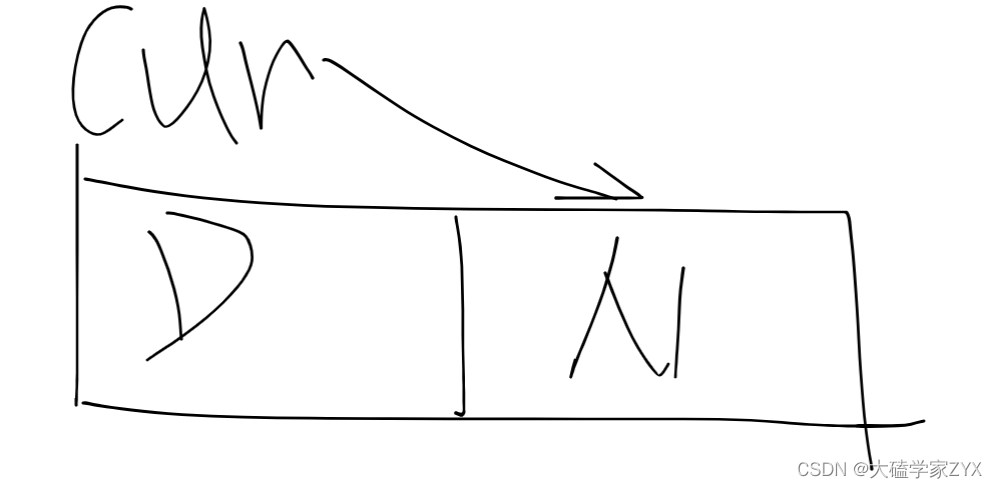
删除节点操作分析
本段代码中,cur->next = cur->next->next;这一行就是在执行删除节点这个操作。这里的**cur是一个遍历指针,cur->next指向的是要删除的节点**,cur->next->next则指向的是要删除节点的下一个节点。**通过将cur->next设置为cur->next->next,我们就将要删除的节点从链表中移除了。**即,直接修改遍历指针的指向,就可以删除链表节点。但是释放内存,还需要建立新的指针tmp来释放。
这个操作的前提是,**cur必须是要删除节点的前一个节点。**因为在单链表中,我们只能通过一个节点的next指针来找到它的下一个节点,但无法找到它的前一个节点。所以,我们需要在遍历链表的过程中,始终保持cur指向要删除节点的前一个节点,这样才能在找到要删除的节点后,通过cur->next = cur->next->next;将其从链表中移除。
指针tmp的作用
tmp指针的作用是暂时存储要删除的节点的地址。
当cur->next->val == val,意味着cur->next指向的节点是要被删除的。然而在删除它之前,需要先将cur->next指向它的下一个节点,也就是cur->next = cur->next->next;。这样,要删除的节点就从链表中被移除了。
但是,**此时只是链表不再指向这个节点,并没有真正删除它。**在C++中,使用new操作符动态创建的对象(如new ListNode(0))会在堆(heap)上分配内存,即使没有任何指针指向它,这块内存也不会被自动回收。如果不手动删除这些对象,会导致内存泄漏。
因此,**需要使用delete操作符来删除这个节点,并释放它占用的内存。**但是在删除它之前,需要有一个指针指向它,否则就无法找到它的地址,也就无法删除它。这就是tmp指针的作用:tmp指针暂时存储了要删除的节点的地址,然后使用delete tmp;来删除这个节点,并释放它占用的内存。
链表中的指针为什么不能直接++?
在C++中,你可以对指针进行加法操作(如ptr++),但这通常用于指向数组元素的指针。对于链表,这种加法操作并没有意义,因为链表中的节点可能存储在内存的非连续位置。所以,我们不能直接使用cur->next++来访问链表中的下一个节点。
在链表中,我们通过使用next指针来遍历。例如,在你提供的代码中,我们通过**cur = cur->next;**这一行来将cur指针移动到链表中的下一个节点。这样,我们可以从链表的头节点开始,沿着next指针遍历整个链表。
重要问题:为什么cur必须=dummyHead,而不是像dummyHead一样重新定义?
例图:

这是错误的,力扣运行会执行出错。
正确写法应该为:
原因分析:
cur = dummyHead; 这句代码使得 cur 和 dummyHead 指向同一块内存(即同一个 ListNode 对象)。
当你改变 cur->next 时(例如,cur->next = cur->next->next;),你实际上是在改变 cur 所指向的那个节点的 next 指针。因为 cur 和 dummyHead 最初指向同一个节点,所以这个操作也会影响到 dummyHead->next。
然而,在遍历链表时,当你改变 cur 本身(例如,cur = cur->next;),dummyHead 并不会受到影响,它仍然指向原来的那个节点。所以,在这种情况下,dummyHead->next 是不变的。
dummyHead->next 表达的是 dummyHead 指针所指向的节点的 next 指针,即该节点的下一个节点。所以,dummyHead->next 实际上是指向链表中的头节点(不包括虚拟头节点)。
也就是说,cur = dummyHead;这句代码,是让这两个指针指向同一个链表节点。也就是链表的头节点。因此,只有cur->next改变的时候,dummyHead->next才会改变。(因为cur->next改变的是头节点的next指针)cur本身改变的时候,dummyHead->next一直不变。















 4582
4582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









