







lodash 封装的方法通常不好奇的话也不会管它怎么实现的,直到遇到问题。。。
camelCase 是一个很常用的方法,将字符转换为小驼峰嘛,直到我发现 camelCase 将 ABCTest 转化成 abcTest 的时候才开始对其实现原理感到好奇。
我以为的小驼峰和camelCase以为的小驼峰究竟是不是一样?
字符串中的连续大写字母会被如何处理?
字符串中的特殊字符会被如何处理?
先看一组测试

一、camelCase代码实现

1、camelCase首先将字符串中的单引号和右单引号转换为空字符串

2、调用words方法拆分字符串
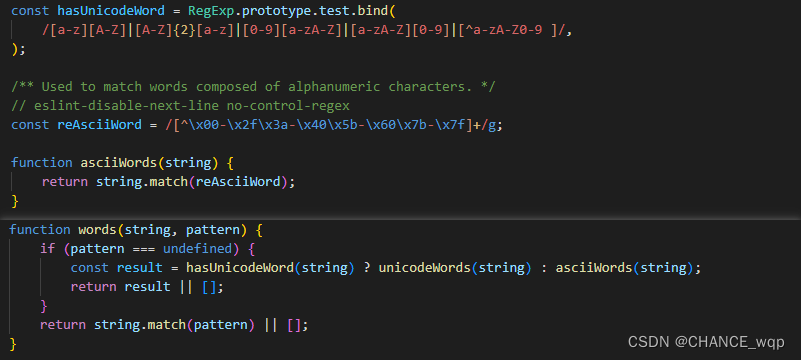
拆分规则如下:
- 有自定义规则按自定义规则拆分
- 没有自定义规则按字符类型为unicode或ascii拆分,无论unicode还是ascii都是通过match方法匹配字符串中符合规则的部分,因此不符合规则的部分被删除掉了(这正是字符串中%.特殊符号消失的原因)
3、对于通过words方法得到的数组执行reduce方法
先将所有字符转换为小写,并将除数组第一项外的字符首字母转换为大写,并合并为一个字符串

二、基于camelCase实现原理解释开头遇到的问题

1、ABCTest 转化成 abcTest
通过 words 拆分会得到 [‘ABC’,‘Test’],执行 reduce 回调后得到 ‘abcTest’
2、testAB 转化成 testAb
通过 words 拆分会得到 [‘test’,‘AB’],执行 reduce 回调后得到 ‘testAb’
3、aaa111aaa.aaa%aaa 转化成 aaa111AaaAaaAaa
通过 words 拆分会得到 [‘aaa’, ‘111’, ‘aaa’, ‘aaa’, ‘aaa’],执行 reduce 回调后得到 ’aaa111AaaAaaAaa’
4、最后看下lodash官方实例如何转换的
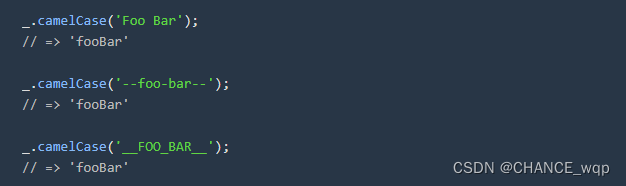 __FOO_BAR__通过 words 拆分得到 [‘FOO’,‘BAR’],执行 reduce 回调得到 ‘fooBar’
__FOO_BAR__通过 words 拆分得到 [‘FOO’,‘BAR’],执行 reduce 回调得到 ‘fooBar’















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









