




vscode编程插件cline 配置使用说明
cline 插件使用,四个剪头从左到右依次操作
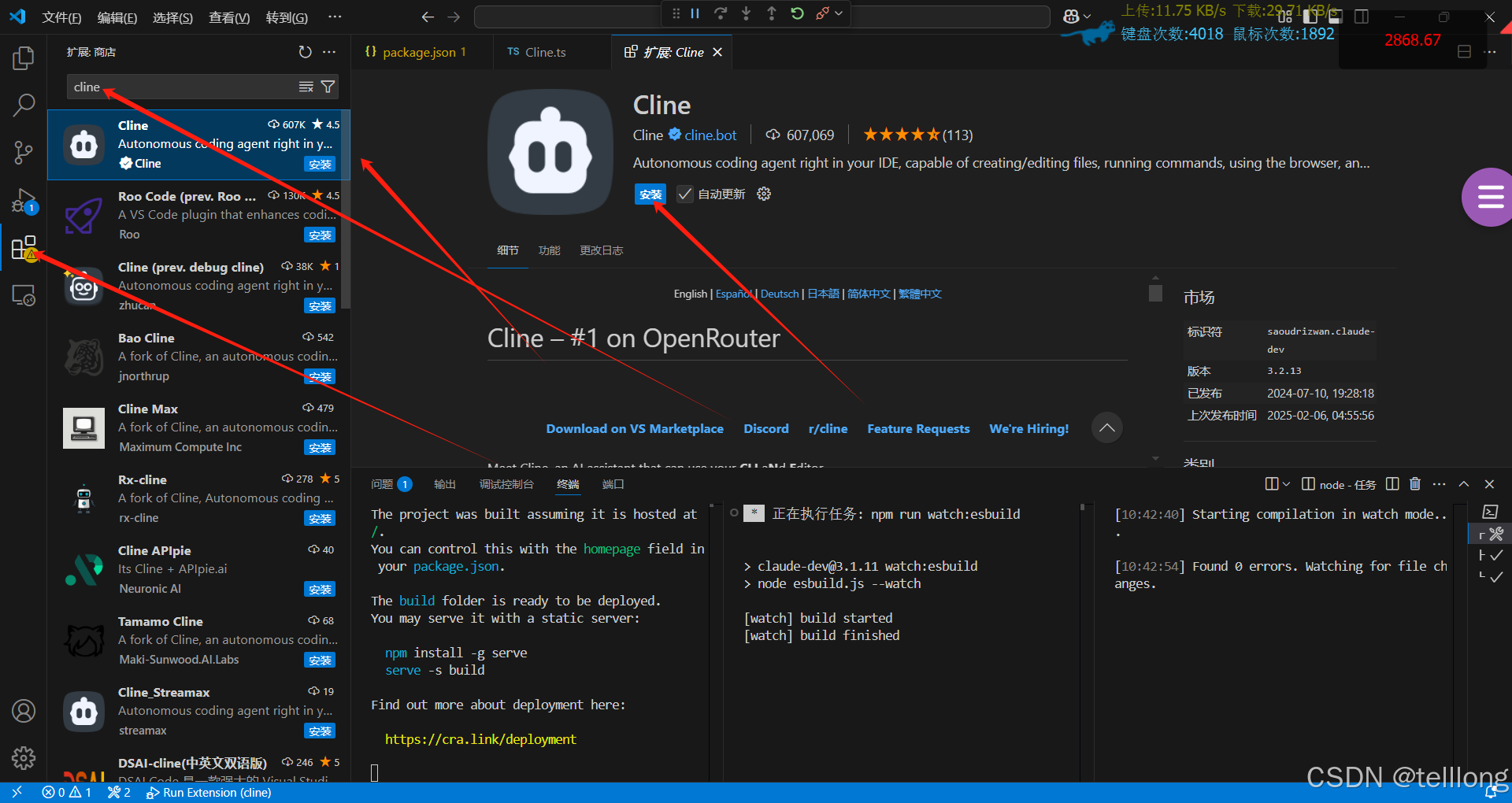
配置deepseek 公有云服务,依次配置,相关配置信息获取 首次调用 API | DeepSeek API Docs
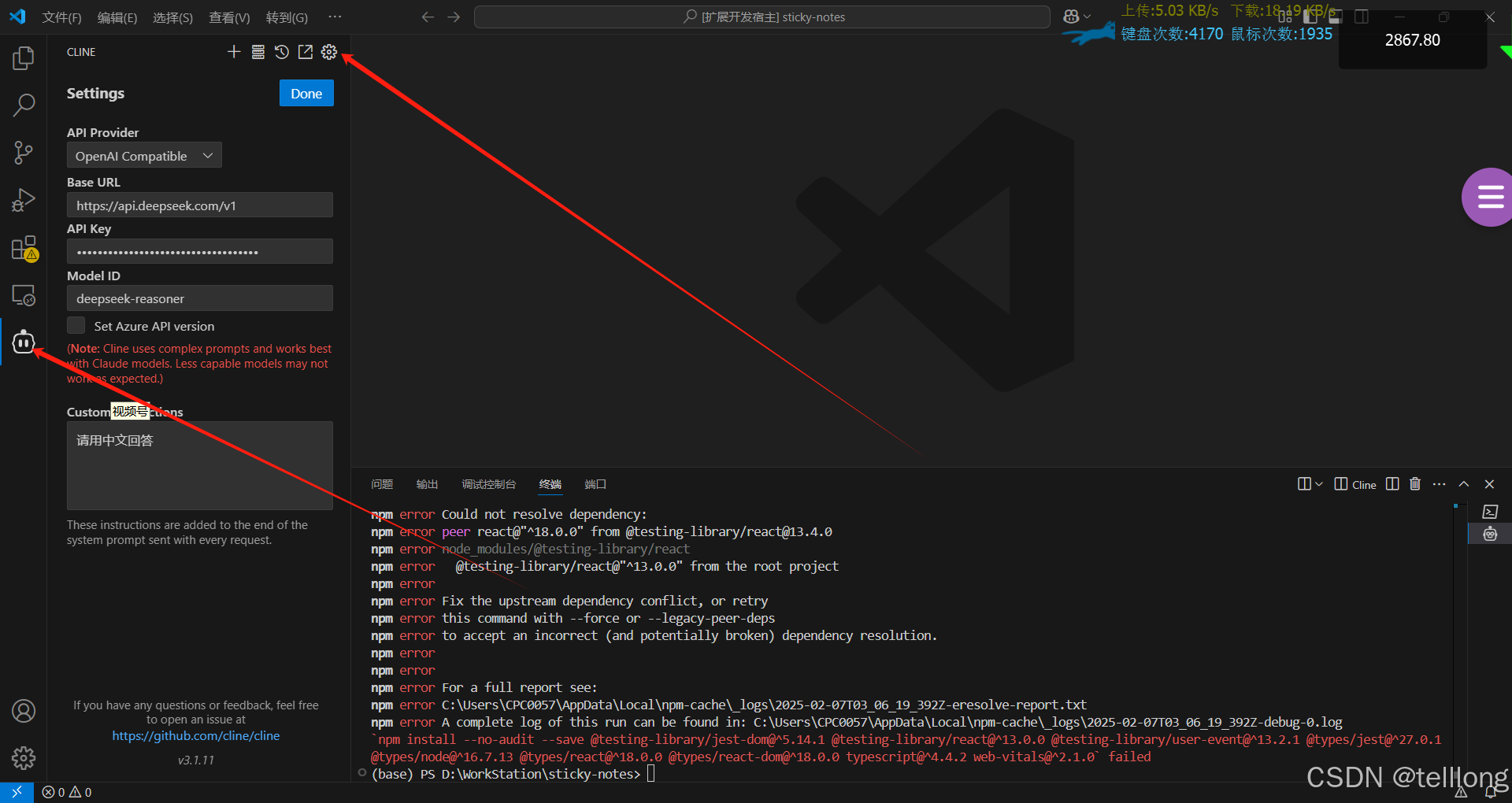
使用ollama在本地部署模型
最近deepseek用起来问题太多,不知道是用户太多把服务器挤爆了,还是美帝网络攻击的问题
使用ollama在本地部署模型 下载地址 Ollama
- 启动服务
ollama serve- 获取模型,运行个小一点的模型,大模型太大,下载时间久,而且运行起来也卡还慢
ollama run deepseek-r1:1.5b按照上面的方法配置好
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5437
5437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











