










集群容错
在集群调用失败时,dubbo提供了多种容错方案,缺省为failover重试。
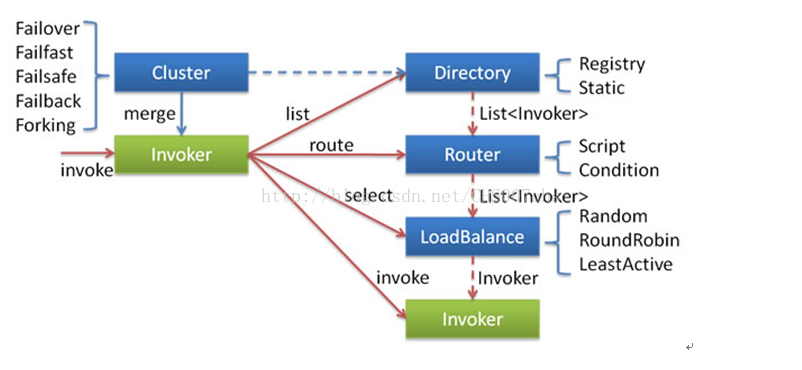
(1)这里的invoker是provider的一个可调用service的抽象,invoker封装了provider地址及service 接口信息。
(2)Directory代表多个invoker,可以把它看成List<Invoker>,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更。
(3)Cluster将Director中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
(4)Router负责从多个Invoker中按路由规则选出子集,比如读写分离、应用隔离。
(5)LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
Failover Cluster:
失败自动切换,当出现失败,重试其它服务器。通党用于读操作,但重试会带来更长延迟。可通过retries="2"来设置重试次数(不含第一次)。
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过forks="2"来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
负载均衡
缺省为random随机调用。
Random LoadBalance
按权重设置随机概率。
RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求问题。
LeastActive LoadBalance
最少活路调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
一致性Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供塲请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
线程模型
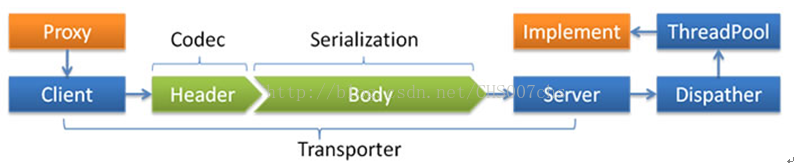
Dispatcher
(1)all 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。
(2)direct所有消息都不发到线程池,全部在IO线程上直接执行。
(3)message 只有请求响应消息发到线程池,其它连接断开事件,心跳等消息,直接在IO线程上执行。
(4)execution 只请求消息发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在IO线程上执行。
(5)connection 在IO线程上,将连接断开事件放入队列,有序逐个执行,其它消息发到线程池。
ThreadPool
(1)fixed 固定大小线程份池,启动时建立线程,不关闭,一直持有。(缺省)
(2)cached 缓存线程池,空闲一分钟自动删除,需要时重建。
(3)limited 可伸缩线程池,但池中的线程数只会增长不会收缩(为避免收缩突然引起的性能问题)
最后欢迎大家访问我的个人网站:1024s















 6218
6218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









