







插入排序的算法复杂度为O(n2),但如果序列为正序可提高到O(n),而且直接插入排序算法比较简单,希尔排序利用这两点得到了一种改进后的插入排序。
一. 算法描述
希尔排序:将无序数组分割为若干个子序列,子序列不是逐段分割的,而是相隔特定的增量的子序列,对各个子序列进行插入排序;然后再选择一个更小的增量,再将数组分割为多个子序列进行排序......最后选择增量为1,即使用直接插入排序,使最终数组成为有序。
增量的选择:在每趟的排序过程都有一个增量,至少满足一个规则 增量关系 d[1] > d[2] > d[3] >..> d[t] = 1 (t趟排序);根据增量序列的选取其时间复杂度也会有变化,这个不少论文进行了研究,在此处就不再深究;
本文采用首选增量为n/2,以此递推,每次增量为原先的1/2,直到增量为1;
下图详细讲解了一次希尔排序的过程:
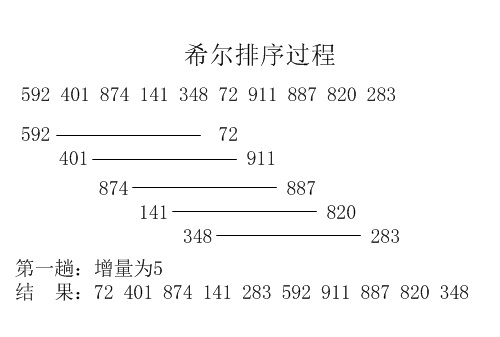

二. 算法分析
平均时间复杂度:希尔排序的时间复杂度和其增量序列有关系,这涉及到数学上尚未解决的难题;不过在某些序列中复杂度可以为O(n1.3);
空间复杂度:O(1)
稳定性:不稳定
三. 算法实现
/********************************************************
*函数名称:ShellInsert
*参数说明:pDataArray 无序数组;
* d 增量大小
* iDataNum为无序数据个数
*说明: 希尔按增量d的插入排序
*********************************************************/
void ShellInsert(int* pDataArray, int d, int iDataNum)
{
for (int i = d; i < iDataNum; i += 1) //从第2个数据开始插入
{
int j = i - d;
int temp = pDataArray[i]; //记录要插入的数据
while (j >= 0 && pDataArray[j] > temp) //从后向前,找到比其小的数的位置
{
pDataArray[j+d] = pDataArray[j]; //向后挪动
j -= d;
}
if (j != i - d) //存在比其小的数
pDataArray[j+d] = temp;
}
}
/********************************************************
*函数名称:ShellSort
*参数说明:pDataArray 无序数组;
* iDataNum为无序数据个数
*说明: 希尔排序
*********************************************************/
void ShellSort(int* pDataArray, int iDataNum)
{
int d = iDataNum / 2; //初始增量设为数组长度的一半
while(d >= 1)
{
ShellInsert(pDataArray, d, iDataNum);
d = d / 2; //每次增量变为上次的二分之一
}
}














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









