







为什么要使用消息队列? 以下六个字:解耦、异步、削峰
Rabbitmq的手动ACK和自动ACK
当消息一旦被消费者接收,队列中的消息就会被删除。那么问题来了:RabbitMQ怎么知道消息被接收了呢?
这就要通过消息确认机制(Acknowlege)来实现了。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
自动ACK:消息一旦被接收,消费者自动发送ACK
手动ACK:消息接收后,不会发送ACK,需要手动调用
这两ACK要怎么选择呢?这需要看消息的重要性:
如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
如果消息非常重要,不容丢失。那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
消息补偿-重试机制:
Rabbitmq 默认情况下 如果消费者程序出现异常情况 会自动实现补偿机制 也就是 重试机制
消费者配置: 本地重试5次 不行就放入重试队列
listener:
simple:
retry:
####开启消费者重试
enabled: true
####最大重试次数(默认无数次)
max-attempts: 5
####重试间隔次数
initial-interval: 3000
广播模式:1对多,produce发送一则消息多个consumer同时收到。
注意:广播是实时的,produce只负责发出去,不会管对端是否收到,若发送的时刻没有对端接收,那消息就没了,因此在广播模式下设置消息持久化是无效的。
RabbitMQ工作队列的默认配置
默认情况下,RabbitMQ会将每个消息依次发送给下一个消费者,每个消费者收到的消息数量其实是一样的,我们把这种分发消息的方式称为轮训分发模式。
不设置 basicQos 则RabbitMQ 平等实现任务分发
设置每个消费者同时只能处理一条消息channel.basicQos(1);,这样会把消息分给空闲的消费者,让 RabbitMQ 实现分轻重地对任务进行分派。
RabbitMQ队列类型 详细介绍地址及代码片段
第一种模型(直连)

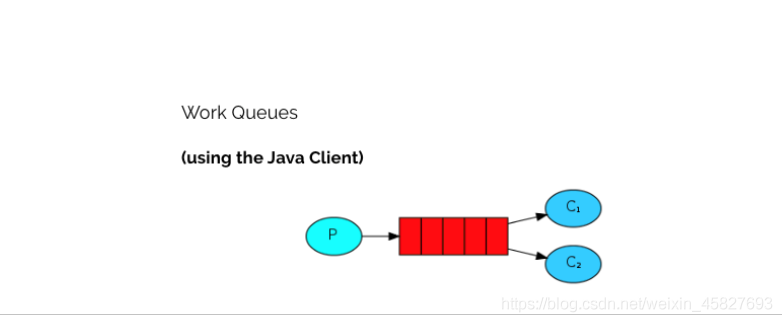
第二种模型(work quene)
默认情况下,RabbitMQ将按顺序将每个消息发送给下一个使用者。平均而言,每个消费者都会收到相同数量的消息。这种分发消息的方式称为循环。
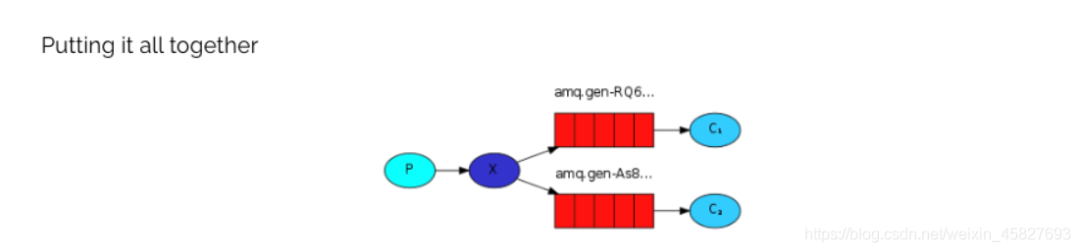
第三种模型(fanout) 也称为广播
在广播模式下,消息发送流程是这样的:
-
可以有多个消费者
-
每个消费者有自己的queue(队列)
-
每个队列都要绑定到Exchange(交换机)
-
生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
-
交换机把消息发送给绑定过的所有队列
-
队列的消费者都能拿到消息。实现一条消息被多个消费者消费
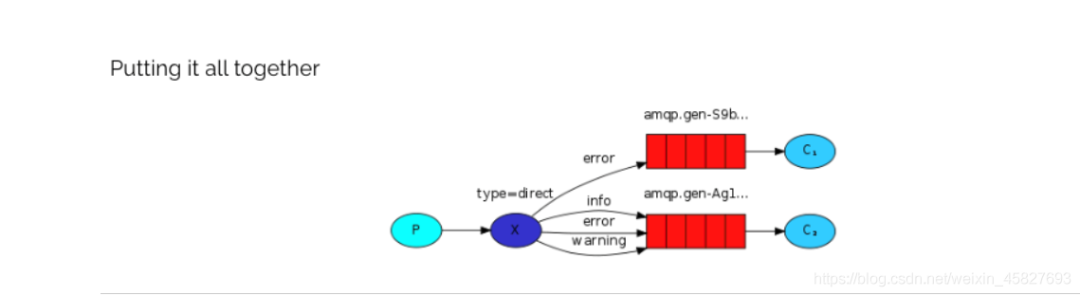
第四种模型(Routing)
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
在Direct模型下:
-
队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) -
消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 -
Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
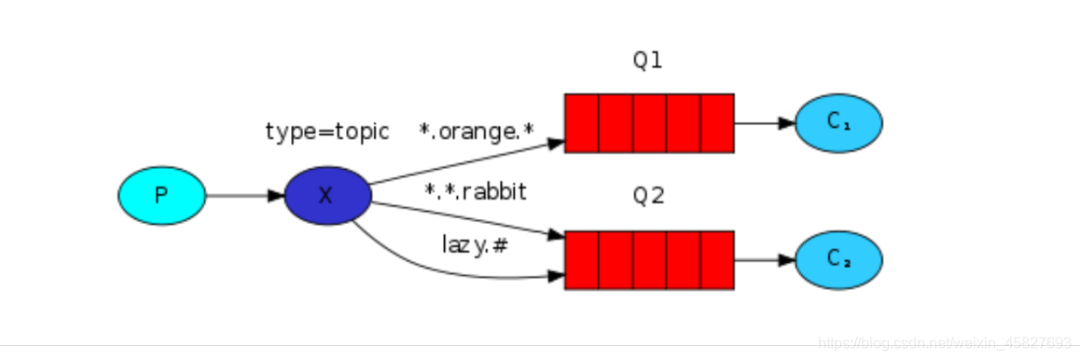
第五种 Routing 之订阅模型-Topic
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!这种模型Routingkey 一般都是由一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
JMQ的ACK
jmq应该是内部按照手动ack及本地重试封装好了,当接收到消息并处理完毕后才会ack,假如中间异常了会本地进行重试,重试几次失败后会向服务端发送retry消息,retry具有ack同等功能,服务端会把消息移除队列放入retry队列
Rabbitmq、Kafka 对比
1.Rabbitmq
队列消费 集群中有两个节点,每个节点上有一个broker,每个broker负责本机上队列的维护,并且borker之间可以互相通信。集群中有两个队列A和B,每个队列都分为master queue和mirror queue(备份)。那么队列上的生产消费怎么实现的呢?
如上图有两个consumer消费队列A,这两个consumer连在了集群的不同机器上。RabbitMQ集群中的任何一个节点都拥有集群上所有队列的元信息,所以连接到集群中的任何一个节点都可以,主要区别在于有的consumer连在master queue所在节点,有的连在非master queue节点上。
因为mirror queue要和master queue保持一致,故需要同步机制,正因为一致性的限制,导致所有的读写操作都必须都操作在master queue上(想想,为啥读也要从master queue中读?和数据库读写分离是不一样的。),然后由master节点同步操作到mirror queue所在的节点。即使consumer连接到了非master queue节点,该consumer的操作也会被路由到master queue所在的节点上,这样才能进行消费。
队列生产
原理和消费一样,如果连接到非 master queue 节点,则路由过去。
所以,到这里小伙伴们就可以看到 RabbitMQ的不足:由于master queue单节点,导致性能瓶颈,吞吐量受限。虽然为了提高性能,内部使用了Erlang这个语言实现,但是终究摆脱不了架构设计上的致命缺陷。
2. Kafka
Topic主题:一组消息抽象归纳为一个topic,是对消息的一个逻辑分类;Topic相当于传统消息系统MQ中的一个队列queue,producer端发送的message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上( hash(message) % [broker数量] )
partition分区:分区是kafka消息队列组织的最小单位;物理上存储上,一个topic 可以有多个partition,一个partition 可以有多个副本;
replica副本:是partition的备份,一个partition可以存在1个or多个replica,分布在集群不同代理上。
leader(领导者)副本与follower(追随者)副本:为保证一个partition的多个replica之间数据的一致性,kafka会在replica中选择一个作为leader副本,其余为follower副本,只有leader副本负责客户端的write/read请求,follower副本从leader副本同步数据,若leader副本失效,则选举其他follower副本为新的leader副本。
一个topic 可以有多个partition,每个partition有一个leader和多个follower副本
Kafka的特性: 高吞吐量、低延迟,可扩展性,持久性、可靠性,容错性,高并发
消费者组
什么是consumer group? 一言以蔽之,consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。(网上文章中说到此处各种炫目多彩的图就会紧跟着抛出来,我这里就不画了,请原谅)。个人认为,理解consumer group记住下面这三个特性就好了:
-
consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
-
group.id是一个字符串,唯一标识一个consumer group
-
consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者位置
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在Kafka中这个位置信息有个专门的术语:位移(offset)。很多消息引擎都把这部分信息保存在服务器端(broker端)。这样做的好处当然是实现简单,但会有三个主要的问题:1. broker从此变成有状态的,会影响伸缩性;2. 需要引入应答机制(acknowledgement)来确认消费成功。3. 由于要保存很多consumer的offset信息,必然引入复杂的数据结构,造成资源浪费。而Kafka选择了不同的方式:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









