







操作系统导论期末复习
操作系统介绍
什么是操作系统:操作系统是管理计算机硬件与软件资源的计算机程序,提供其他程序和硬件之间的接口,对需求进行管理,对资源进行分配,对用户提供服务,是计算机中软件和硬件的总指挥部。
三大主题:虚拟化,并发,持久性。
1.虚拟化CPU
在硬件的一些帮助下,操作系统负责提供这种假象(illusion),即系统拥有非常多的虚拟CPU的假象。将单个CPU(或其中一小部分)转换为看似无限数量的CPU,从而让许多程序看似同时运行,这就是所谓的虚拟化CPU(virtualizing the CPU)。一次运行多个程序的能力会引发各种新问题。例如,如果两个程序想要在特定时间运行,应该运行哪个?这个问题由操作系统的策略(policy)来回答。
2.虚拟化内存
每个进程访问自己的私有虚拟地址空间(virtual address space)(有时称为地址空间,address space),操作系统以某种方式映射到机器的物理内存上。一个正在运行的程序中的内存引用不会影响其他进程(或操作系统本身)的地址空间。对于正在运行的程序,它完全拥有自己的物理内存。
3.并发
当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。这种方式我们称之为并发(Concurrent)。
4.持久性
在系统内存中,数据容易丢失,因为像DRAM这样的设备以易失(volatile)的方式存储数值。如果断电或系统崩溃,那么内存中的所有数据都会丢失。因此,我们需要硬件和软件来持久地(persistently)存储数据。这样的存储对于所有系统都很重要,因为用户非常关心他们的数据。硬件以某种输入/输出(Input/Output,I/O)设备的形式出现。在现代系统中,硬盘驱动器(hard drive)是存储长期保存的信息的通用存储库。
抽象:进程
操作系统提供的基本的抽象——进程。进程的非正式定义非常简单:进程就是运行中的程序。人们希望能同时运行多个程序,操作系统中可能有上百个进程在运行,但CPU是有限的。通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟 CPU 的假象。这就是时分共享CPU技术。
1.进程创建
运行程序第一步是将代码和所有静态数据(例如初始化变量)加载(load)到内存中,加载到进程的地址空间中。在早期的(或简单的)操作系统中,加载过程尽早(eagerly)完成,即在运行程序之前全部完成。现代操作系统惰性(lazily)执行该过程,即仅在程序执行期间需要加载的代码或数据片段,才会加载。
将代码和静态数据加载到内存后,操作系统在运行此进程之前还需要执行其他一些操作。比如为程序的运行时栈(run-time stack 或 stack)分配一些内存,为程序的堆(heap)分配一些内存,还将执行一些其他初始化任务,特别是与输入/输出(I/O)相关的任务。
最后一步就是启动程序,在入口处运行,即main()。通过跳转到main()例程(第 5 章讨论的专门机制),OS 将 CPU
的控制权转移到新创建的进程中,从而程序开始执行。
2.进程状态
进程在给定时间可能处于的不同状态(state),一般来说进程处于以下三种状态之一:运行,就绪,阻塞。
运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。
就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。
阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞,因此其他进程可以使用处理器。
从就绪到运行意味着该进程已经被调度(scheduled)。从运行转移到就绪意味着该进程已经取消调度(descheduled)。一旦进程被阻塞(例如,通过发起 I/O 操作),OS 将保持进程的这种状态,直到发生某种事件(例如,I/O 完成)。
3.数据结构
操作系统是一个程序,和其他程序一样,它有一些关键的数据结构来跟踪各种相关的信息。例如,为了跟踪每个进程的状态,操作系统可能会为所有就绪的进程保留某种进程列表(process list),以及跟踪当前正在运行的进程的一些附加信息。操作系统还必须以某种方式跟踪被阻塞的进程。当 I/O 事件完成时,操作系统应确保唤醒正确的进程,让它准备好再次运行。
对于停止的进程,寄存器上下文将保存其寄存器的内容。当一个进程停止时,它的寄存器将被保存到这个内存位置。通过恢复这些寄存器(将它们的值放回实际的物理寄存器中),操作系统可以恢复运行该进程。我们将在后面的章节中更多地了解这种技术,它被称为上下文切换(context switch)。
插叙:进程API
本章将讨论 UNIX 系统中的进程创建。UNIX 系统采用了一种非常有趣的创建新进程的方式,即通过一对系统调用:fork()和 exec()。进程还可以通过第三个系统调用 wait(),来等待其创建的子进程执行完成。本章将详细介绍这些接口,通过一些简单的例子来激发兴趣。
fork()
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
(1)在父进程中,fork返回新创建子进程的进程ID;
(2)在子进程中,fork返回0;
(3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。子进程并非是完全拷贝了父进程,它拥有自己的地址空间(即拥有自己的私有内存)、寄存器、程序计数器等。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。两个进程的运行先后有CPU调度程序决定,并不是父进程一定先于子进程执行。
wait()
wait能使当前进程延后运行,当另一个进程完成后再运行。比如前面fork之后,父子进程的运行先后不是固定的,但是如果在父进程中调用wait,延迟自己的运行,直到子进程执行完毕。当子进程结束时,wait才返回父进程,父进程再执行,此时运行的先后就是固定的了。
exec()
exec系统调用能让子进程执行与父进程不同的程序。给定可执行程序的名称(如 wc)及需要的参数(如 p3.c)后,exec()会从可执行程序中加载代码和静态数据,并用它覆写自己的代码段(以及静态数据),堆、栈及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过 argv 传递给该进程。因此,它并没有创建新进程,而是直接将当前运行的程序(以前的 p3)替换为不同的运行程序(wc)。子进程执行 exec之后,几乎就像p3.c 从未运行过一样。对 exec的成功调用永远不会返回。
机制:受限直接执行
为了虚拟化 CPU,操作系统需要以某种方式让许多任务共享物理 CPU,让它们看起来像是同时运行。基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换。通过以这种方式时分共享(time sharing)CPU,就实现了虚拟化。
但性能和控制权是实现这个虚拟化机制所要解决的问题,尤其是控制权,要保证进程不能无限制地运行并接管机器,或访问没有权限的信息。因此,要力求保持控制权的同时获得高性能。
问题 1:受限制的操作
用户模式:应用程序不能完全访问硬件资源,如发出I/O请求。
内核模式:操作系统就以这种模式运行,可以访问机器的全部资源。
用户希望执行某种特权操作,这时候操作系统提供用户程序执行系统调用的能力,来完成某些特权操作,而执行系统调用则要执行特殊的陷阱指令,从用户模式进入内核模式,完成所需要的特权操作后,操作系统调用一个特殊的从陷阱返回的指令,从内核模式回到用户模式,返回到发起调用的用户程序中。
问题 2:在进程之间切换
在进程之间切换,此时操作系统并没有在CPU上运行,所以由操作系统执行进程间切换成了问题。
协作方式:等待系统调用
在这种方式下,操作系统相信系统的进程会合理运行。运行时间过长的进程被假定会定期放弃CPU,以便操作系统可以决定运行其他任务。大多数进程通过进行系统调用,将 CPU 的控制权转移给操作系统,例如打开文件并随后读取文件,或者向另一台机器发送消息或创建新进程。像这样的系统通常包括一个显式的 yield 系统调用,它什么都不干,只是将控制权交给操作系统,以便系统可以运行其他进程。
非协作方式:操作系统进行控制
事实证明,没有硬件的额外帮助,如果进程拒绝进行系统调用(也不出错),从而将控制权交还给操作系统,那么操作系统无法做任何事情。因此通过时钟设备编程为每隔几毫秒产生一次中断,产生中断时当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得 CPU 的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。
保存和恢复上下文
如果决定进行切换,OS 就会执行一些底层代码,即所谓的上下文切换(context switch)。上下文切换在概念上很简单:操作系统要做的就是为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
进程调度:介绍
事实上,调度的起源早于计算机系统。早期调度策略取自于操作管理领域,并应用于计算机。
工作负载假设
我们对操作系统中运行的进程(有时也叫工作任务)做出如下的假设:
1.每一个工作运行相同的时间。
2.所有的工作同时到达。
3.一旦开始,每个工作保持运行直到完成。
4.所有的工作只是用 CPU(即它们不执行 IO 操作)。
5.每个工作的运行时间是已知的。
调度指标
周转时间:任务完成时间减去任务到达系统的时间,T周转=T完成-T到达。(性能)
响应时间:从任务到达系统到首次运行的时间,T响应=T首次-T到达。(交互性)
四种调度策略
从周转时间下考虑:
FIFO:先进先出,好处在于简单并易于实现,坏处在于容易造成护航效应。
SJF:最短任务优先,先运行最短的任务,然后是次短的任务,如此下去。(任务必须完成才能完成下一个)
STCF:最短完成时间优先,每当新工作进入系统时,它就会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作。
从响应时间下考虑:
RR:轮转调度,在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务完成。时间片越短,RR在响应时间上表现越好,但频繁的突然上下文切换的成本将会影响整体性能,因此要权衡时间片长度。
我们开发了两种调度程序。第一种类型(SJF、STCF)优化周转时间,但对响应时间不利。第二种类型(RR)优化响应时间,但对周转时间不利。我们还有两个假设需要放宽:假设 4(作业没有 I/O)和假设 5(每个作业的运行时间是已知的)。接下来我们来解决这些假设。
结合I/O
利用重叠思想:
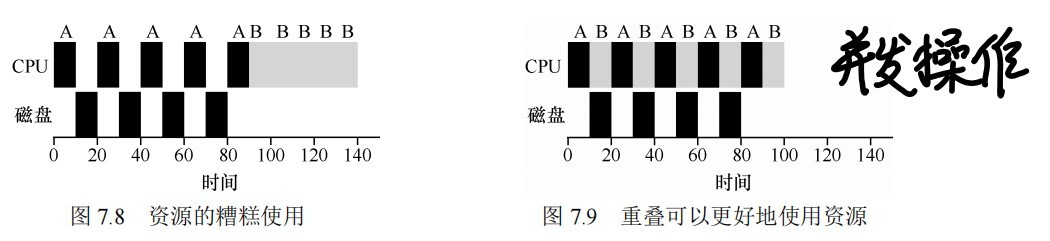
调度:多级反馈队列
多级反馈队列需要解决两方面的问题。首先,它要优化周转时间。在第 7 章中我们看到,这通过先执行短工作来实现。然而,操作系统通常不知道工作要运行多久,而这又是SJF(或 STCF)等算法所必需的。其次,MLFQ 希望给交互用户(如用户坐在屏幕前,等着进程结束)很好的交互体验,因此需要降低响应时间。然而,像轮转这样的算法虽然降低了响应时间,周转时间却很差。
MLFQ中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。任何时刻,一个工作只能存在于一个队列中。MLFQ 总是优先执行较高优先级的工作(即在较高级队列中的工作)。当然,每个队列中可能会有多个工作,因此具有同样的优先级。在这种情况下,我们就对这些工作采用轮转调度。
MLFQ在进程运行过程中学习其行为,从而利用工作的历史来预测它未来的行为
MLFQ基本规则:
规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
规则 2:如果 A 的优先级 = B 的优先级,轮转运行A 和 B。
MLFQ优化后规则:
规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
规则 3:工作进入系统时,放在最高优先级(最上层队列)。
规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(移入低一级队列)。
规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
通过这种方式,MLFQ 可以同时满足各种工作的需求:对于短时间运行的交互型工作,获得类似于 SJF/STCF 的很好的全局性能,同时对长时间运行的CPU 密集型负载也可以公平地、不断地稳步向前。
调度:比例份额
比例份额算法基于一个简单的想法:调度程序的最终目标,是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响应时间。比例份额调度有一个非常优秀的现代例子,名为彩票调度:每隔一段时间,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程。越是应该频繁运行的进程,越是应该拥有更多地赢得彩票的机会。
基本概念:彩票数表示份额
彩票数代表了进程占有某个资源的份额,一个进程拥有的彩票数占总彩票数的百分比,就是它占有的资源的份额。
彩票调度最精彩的地方在于利用了随机性(randomness)。当你需要做出决定时,采用随机的方式常常是既可靠又简单的选择。随机方法相对于传统的决策方式,至少有3点优势。第一,随机方法常常可以避免奇怪的边角情况。第二,随机方法很轻量。第三,随机方法很快。
彩票机制
彩票调度提供一些机制,以不同且有效的方式来调度彩票。
彩票货币:这种方式允许拥有一组彩票的用户以他们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。
彩票转让:通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
彩票通胀:利用通胀,一个进程可以临时提升或降低自己拥有的彩票数量。在进程之间相互信任的环境下,如果一个进程知道它需要更多 CPU 时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
实现
彩票调度中最不可思议的,或许就是实现简单。只需要一个不错的随机数生成器来选择中奖彩票和一个记录系统中所有进程的数据结构(一个列表),以及所有彩票的总数。
只有当工作执行非常多的时间片时,彩票调度算法才能得到期望的结果。并且彩票调度中最难的票数分配问题没有确定解决方法。
步长调度
由于随机方式偶尔不能产生正确的比例,尤其在工作运行时间很短的情况下,因此诞生了步长调度。
步长调度:系统中的每个工作都有自己的步长,这个值与票数值成反比。
比如A、B、C 这 3 个工作的票数分别是 100、50 和 250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用 10000 除以这些票数值,得到了 3 个进程的步长分别为 100、200 和 40。我们称这个值为每个进程的步长(stride)。每次进程运行后,我们会让它的计数器 (称为行程(pass)值) 增加它的步长,记录它的总体进展。之后,调度程序使用进程的步长及行程值来确定调度哪个进程。基本思路很简单:当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进程的行程值增加一个步长。
但步长调度相较于彩票调度需要全局状态,如果在步长调度执行过程中,有新的进程加入系统,就难以设置它的行程值。
分段
内外碎片之分
内部碎片:已经分配的内存单元内部有未使用的空间(即碎片),造成了浪费。
外部碎片:除了已分配的内存单元之外的空闲内存块(比如段和段之间存在外部碎片)。
分段的机制
如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。另外,如果剩余物理内存无法提供连续区域来放置完整的地址空间,进程便无法运行。
因此,在 MMU 中引入不止一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。一个段只是地址空间里的一个连续定长的区域,在典型的地址空间里有 3 个逻辑不同的段:代码、栈和堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中的未使用部分占用物理内存。
如何计算
ARG seed 0
ARG address space size 128
ARG phys mem size 512
Segment register information:
Segment 0 base (grows positive) : 0x00000000 (decimal 0)
Segment 0 limit : 20
Segment 1 base (grows negative) : 0x00000200 (decimal 512)
Segment 1 limit : 20
Virtual Address Trace
VA 0: 0x0000006c (decimal: 108) --> VALID in SEG1: 0x000001ec (decimal: 492)
VA 1: 0x00000061 (decimal: 97) --> SEGMENTATION VIOLATION (SEG1)
VA 2: 0x00000035 (decimal: 53) --> SEGMENTATION VIOLATION (SEG0)
VA 3: 0x00000021 (decimal: 33) --> SEGMENTATION VIOLATION (SEG0)
VA 4: 0x00000041 (decimal: 65) --> SEGMENTATION VIOLATION (SEG1)
如上述例子中,有两个段,一个段0一个段1。其中段0是正向增长,段1是反向增长的(栈)。对于VA0:0x0000006c即01101100,前两位为01,即在SEG1。对应的,如果前两位为00,即在SEG0,在不同的段对应不同的地址转换。对于VA0,由于其段是反向增长的,我们要得到正确的反向偏移,需要从108中减去最大的段地址128,即-20,反向偏移量(-20)加上基址(512)为492,在界限内。
空闲空间管理
四大匹配
最优匹配:首先遍历整个空闲列表,找到和请求大小一样或更大的空闲块,然后返回这组候选者中最小的一块(需要全部遍历)。
最差匹配:尝试找最大的空闲块,分割并满足用户需求后,将剩余的块(很大)加入空闲列表。最差匹配尝试在空闲列表中保留较大的块,而不是向最优匹配那样可能剩下很多难以利用的小块(需要全部遍历且开销很大)。
首次匹配:找到第一个足够大的块,将请求的空间返回给用户。同样,剩余的空闲空间留给后续请求(不需要全部遍历,有速度优势,但要求空闲块基于地址排序)。
下次匹配:不同于首次匹配每次都从列表的开始查找,下次匹配(next fit)算法多维护一个指针,指向上一次查找结束的位置。其想法是将对空闲空间的查找操作扩散到整个列表中去,避免对列表开头频繁的分割。这种策略的性能与首次匹配很接它,同样避免了遍历查找。
分离空闲列表
如果某个应用程序经常申请一种(或几种)大小的内存空间,那就用一个独立的列表,只管理这样大小的对象。其他大小的请求都交给更通用的内存分配程序。优点是,通过拿出一部分内存专门满足某种大小的请求,碎片就不再是问题了。而且,由于没有复杂的列表查找过程,这种特定大小的内存分配和释放都很快。
伙伴系统
因为合并对分配程序很关键,所以人们设计了一些方法,让合并变得简单,一个好例子就是二分伙伴分配程序。在这种系统中,空闲空间首先从概念上被看成大小为
2
N
2^N
2N 的大空间。当有一个内存分配请求时,空闲空间被递归地一分为二,直到刚好可以满足请求的大小(再一分为二就无法满足)。
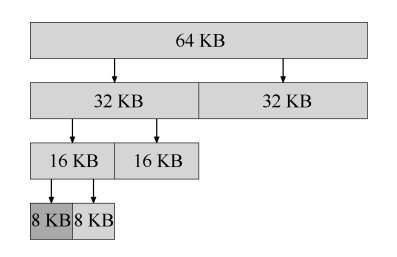
伙伴系统的漂亮之处在于块被释放时。如果将这个 8KB 的块归还给空闲列表,分配程序会检查“伙伴” 8KB 是否空闲。如果是,就合二为一,变成 16KB 的块。然后会检查这个 16KB 块的伙伴是否空闲,如果是,就合并这两块。这个递归合并过程继续上溯,直到合并整个内存区域,或者某一个块的伙伴还没有被释放。
分页
分页不是将一个进程的地址空间分割成几个不同长度的逻辑段(即代码、堆、段),而是分割成固定大小的单元,每个单元称为一页。相应地,我们把物理内存看成是定长槽块的阵列,叫作页帧(page frame)。每个这样的页帧包含一个虚拟内存页。其优点在于:灵活性,不会假定堆和栈的增长方向,以及它们如何使用。简单性,空闲空间管理更加简单,从空闲列表找出空闲页即可,并且还不会生成外部碎片。
为了记录地址空间的每个虚拟页放在物理内存中的位置,操作系统通常为每个进程保存一个数据结构,称为页表(page table)。页表一般保存在PCB中,即进程控制块。
页表中的每一项(页表项,PTE)内容如下:

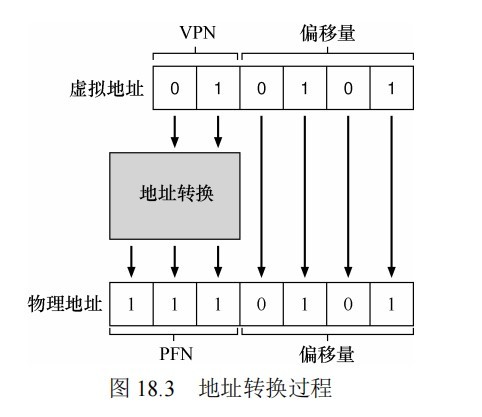
地址转换
为了转换(translate)该过程生成的虚拟地址,我们必须首先将它分成两个组件:虚拟页面号(virtual page number,VPN)和页内的偏移量(offset)。VPN长度取决于页的数目,VPO的长度取决于页的大小。
TLB
由于我们要记录虚拟地址转换到物理地址的映射信息,而这些映射信息一般存储在物理内存中,所以在转换虚拟地址时,分页逻辑上需要一次额外的内存访问。每次指令获取、显式加载或保存,都要额外读一次内存以得到转换信息,这慢得无法接受。因此我们增加所谓的地址转换旁路缓冲存储器(translation-lookaside buffer,TLB),它就是频繁发生的虚拟到物理地址转换的硬件缓存。
对于每次内存访问,硬件先检查 TLB,看看其中是否有期望的转换映射,如果有,就完成转换(很快),不用访问页表
(其中有全部的转换映射)。
多级页表
当页表过于大时,会消耗过多的内存,因此我们需要想办法来解决这个问题。一种方法就是采用多级页表,就像树一样。首先,将页表分成页大小的单元。然后,如果整页的页表项(PTE)无效,就完全不分配该页的页表。为了追踪页表的页是否有效(以及如果有效,它在内存中的位置),使用了名为页目录(page directory)的新结构。页目录因此可以告诉你页表的页在哪里,或者页表的整个页不包含有效页。
地址转换
由于加入了页目录,因此地址转换也要进行变化。
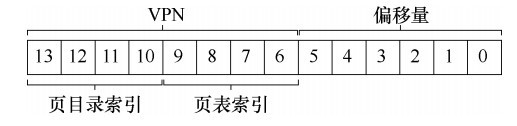
①从VPN中提取页目录索引(简称 PDIndex),从而计算出页目录项(PDE)的地址:
PDEAddr = PageDirBase +(PDIndex×sizeof(PDE)
②如果PDE有效,我们还要通过页表索引(Page-Table Index,PTIndex),计算出页表项(PTE)的地址:
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
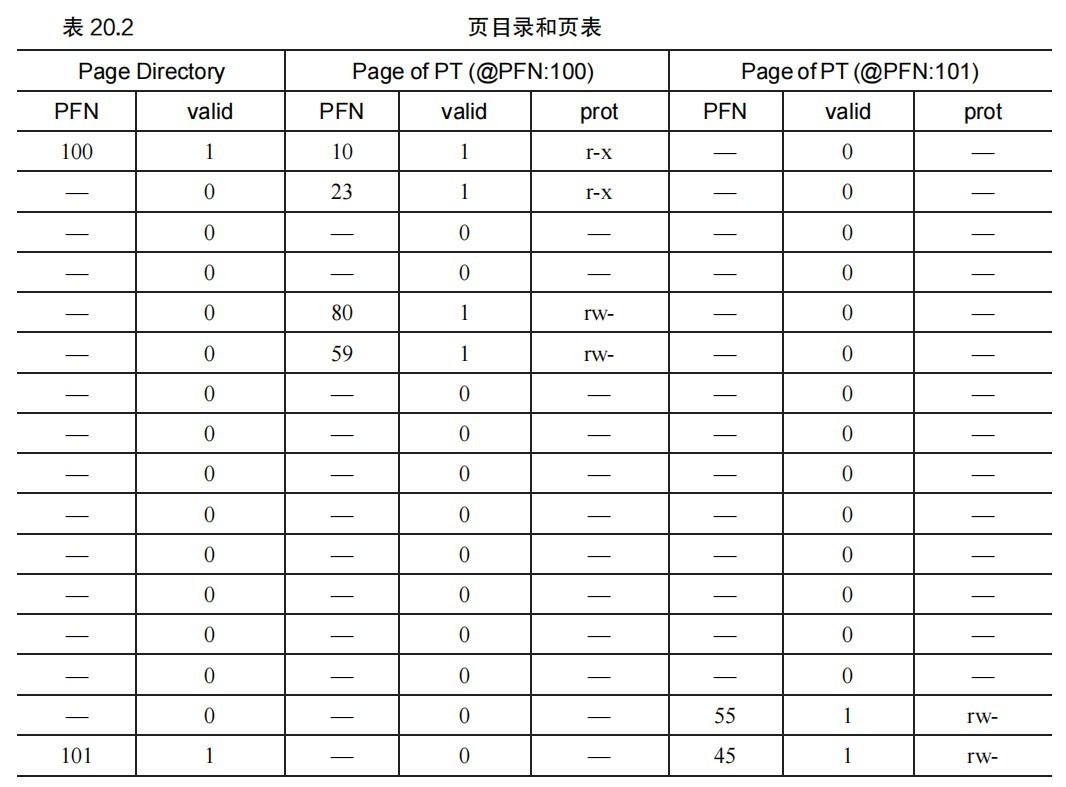
如图,假如现在有VA:0x3F80,即11 1111 1000 0000,提取有效信息:
PDI:1111;PTI:1110;VPO:000000
于是由图可知PDEAddr=101,随后查看101的PT,可知PTEAddr=55。即PFN=55(0x37),VPO=000000(0x0),因此组合一下就是物理地址就是0000 1101 1100 0000。
页替换
由于操作系统给用户态的应用程序提供了一个虚拟的“大容量”内存空间,而实际的物理内存空间又没有那么大。所以操作系统就就“瞒着”应用程序,只把应用程序中“常用”的数据和代码放在物理内存中,而不常用的数据和代码放在了硬盘这样的存储介质上。但当程序读取本应在内存中的数据时,发现其不在内存,会触发页访问异常,此时系统会把应用程序当前需要的数据或代码放到内存中来,然后重新执行应用程序产生异常的访存指令。如果此时内存已满,我们则需要把系统认为“不常用”的页换出到磁盘上去,以腾出内存空闲空间给应用程序所需的数据或代码,这便是页替换。
最优替换
最优替换策略即替换内存中在最远将来才会被访问到的页。遗憾的是,正如我们之前在开发调度策略时所看到的那样,未来的访问是无法知道的,你无法为通用操作系统实现最优策略。
FIFO
该算法总是淘汰最先进入内存的页,即选择在内存中驻留时间最久的页予以淘汰。但它无法确定页的重要性,那些常被访问的页,往往在内存中也停留得最久,结果它们因变“老”而不得不被置换出去。此外,FIFO在增加放置页的页帧的情况下,反而使页访问异常次数增多。
随机
在内存满的时候它随机选择一个页进行替换。随机具有类似于 FIFO 的属性。实现我来很简单,但是它在挑选替换哪个页时不够智能。
LRU
为了提高后续的命中率,我们再次通过历史的访问情况作为参考,根据局部性原则,是程序倾向于频繁地访问某些代码(例如循环)和数据结构(例如循环访问的数组)。因此我们可以根据页最近的访问次数来决定是否替换,这就是LRU的核心思想。
近似LRU(时钟页替换算法)
遗憾的是LRU的开销十分巨大,扫描所有页的时间字段只是为了找到最精确最少使用的页,这个代价太昂贵。因此我们考虑能不能实现近似LRU,获得预期效果的同时并且降低开销,而时钟页替换算法就是近似LRU的一种。
时钟页替换算法把各个页面组织成环形链表的形式,类似于一个钟的表面。然后把一个指针(简称当前指针)指向最老的那个页面,即最先进来的那个页面。我们除了要考虑访问情况,还要考虑修改情况,因为淘汰修改过的页面还需要写回硬盘,使得其置换代价大于未修改过的页面。因此我们为每一页的对应页表项内容中增加一位引用位和一位修改位,当该页被访问时,CPU中的MMU硬件将把访问位置“1”。当该页被“写”时,CPU中的MMU硬件将把修改位置“1”。
我们以(引用位,修改位)来表示四种可能的情况:(0,0)表示最近未访问未修改,因此优先替换掉;(0,1)表示最近未访问,但是被修改,其次替换;然后是(0,1),最后是(1,1)。
并发
我们希望能最大化的利用CPU,但CPU运算速度和IO传输速度是不平衡的,CPU完成计算任务后IO在花很长时间传输数据,此时CPU是空闲状态的。因此我们提出进程的概念,希望这个进程在执行IO操作时,CPU能切换到另一个进程来执行任务,这样提高了CPU的利用率。但是切换进程是需要切换内存映射地址,这是不小的性能开销。因此我们又提出线程的概念,一个进程创建的所有线程,都是共享一个内存空间的,这样线程做任务切换成本就很低了。而并发就是基于线程提出的:当多个线程执行时,CPU将运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。
我们先来介绍一些名词:
临界区(critical section)是访问共享资源的一段代码,资源通常是一个变量或数据结构。
竞态条件(race condition)出现在多个执行线程大致同时进入临界区时,它们都试图更新共享的数据结构,导致了令人惊讶的(也许是不希望的)结果。
不确定性(indeterminate)程序由一个或多个竞态条件组成,程序的输出因运行而异,具体取决于哪些线程在何时运行。这导致结果不是确定的(deterministic),而我们通常期望计算机系统给出确定的结果。
为了避免这些问题,线程应该使用某种互斥(mutual exclusion)原语。这样做可以保证只有一个线程进入临界区,从而避免出现竞态,并产生确定的程序输出。
锁
为了避免多个线程进入临界区同时修改共享的数据,我们提出锁这个概念,将锁放在临界区周围,保证临界区能够像单条原子指令一样执行,由于锁的存在,可以保证临界区内只有一个线程活跃。
对于锁,我们提出三个评价标准:
互斥:这是锁的最基本任务,阻止多个线程同时进入临界区。
公平性:每一个线程应该都有公平的机会抢到锁,不然会出现某一线程一直霸占锁不释放,导致与其竞争的线程被“饿死”。
性能:具体来说,是使用锁之后增加的时间开销。
死锁
此外,我们还要注意死锁的情况,即两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。如果在一个系统中以下四个条件同时成立,那么就能引起死锁:
互斥:线程对于需要的资源进行互斥的访问(例如一个线程抢到锁)。
持有并等待:线程持有了资源(例如已将持有的锁),同时又在等待其他资源(例如,需要获得的锁)。
非抢占:线程获得的资源(例如锁),不能被抢占。
循环等待:线程之间存在一个环路,环路上每个线程都额外持有一个资源,而这个资源又是下一个线程要申请的。
如果这4个条件的任何一个没有满足,死锁就不会产生。循环等待条件意味着持有并等待条件,这样四个条件并不完全独立。
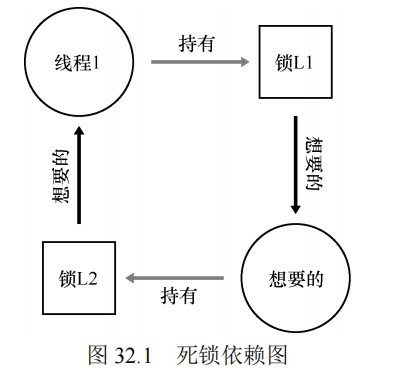
预防死锁的方法;每个策略都设法阻止某一个条件,从而解决死锁的问题。
通过调度避免死锁:除了死锁预防,某些场景更适合死锁避免(avoidance)。我们需要了解全局的信息,包括不同线程在运行中对锁的需求情况,从而使得后续的调度能够避免产生死锁。避免死锁的方法有银行家算法。
检查和恢复:最后一种常用的策略就是允许死锁偶尔发生,检查到死锁时再采取行动。
自旋锁
自旋锁就是当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。
int TestAndSet(int new, int mutex) { //xchg指令(原子交换指令)的伪代码实现,避免中断的打断
int old = mutex;
mutex = new;
return mutex;
}
for(int i=n;i>0;i--)
{
lock(mutex)
{
while(TestAndSet(1,mutex)==1); //自旋
}
count++;
unlock(mutex)
{
mutex=0;
}
}
休眠锁
可以看出来,简单的自旋锁无法保证多线程竞争的公平性,有可能有的线程一直抢不到锁,导致饿死。此外未得到锁的进程会一直自旋,浪费CPU资源。因此我们需要一个队列来保存等待锁的线程,并且让线程在获取不到锁时睡眠,在锁可用时被唤醒。
1 typedef struct lock_t {
2 int flag;
3 int guard;
4 queue_t *q;
5 } lock_t;
6
7 void lock_init(lock_t *m) {
8 m->flag = 0;
9 m->guard = 0;
10 queue_init(m->q);
11 }
12
13 void lock(lock_t *m) {
14 while (TestAndSet(&m->guard, 1) == 1)
15 ; //acquire guard lock by spinning
16 if (m->flag == 0) {
17 m->flag = 1; // lock is acquired
18 m->guard = 0;
19 } else {
20 queue_add(m->q, gettid());
21 m->guard = 0;
22 park();
23 }
24 }
25
26 void unlock(lock_t *m) {
27 while (TestAndSet(&m->guard, 1) == 1)
28 ; //acquire guard lock by spinning
29 if (queue_empty(m->q))
30 m->flag = 0; // let go of lock; no one wants it
31 else
32 unpark(queue_remove(m->q)); // hold lock (for next thread!)
33 m->guard = 0;
34 }
条件变量
锁并不是并发程序设计所需的唯一原语。具体来说,在很多情况下,线程需要检查某一条件(condition)满足之后,才会继续运行。例如,父线程需要检查子线程是否执行完毕。因此我们提出了条件变量这个概念。
条件变量是一个显式队列,当某些执行状态(即条件,condition)不满足时,线程可以把自己加入队列,等待(waiting)该条件。另外某个线程,当它改变了上述状态时,就可以唤醒一个或者多个等待线程(通过在该条件上发信号),让它们继续执行。
用消费者和生产者问题举例:假设有一个或多个生产者线程和一个或多个消费者线程。生产者把生成的数据项放入缓冲区;消费者从缓冲区取走数据项,以某种方式消费。因为有界缓冲区是共享资源,所以我们必须通过同步机制来访问它,以免产生竞态条件。所以我们可以使用条件变量和锁来解决这个问题,完整的代码如下:
put()和 get()方法
1 int buffer[MAX];
2 int fill = 0;
3 int use = 0;
4 int count = 0;
5
6 void put(int value) {
7 buffer[fill] = value;
8 fill = (fill + 1) % MAX;
9 count++;
10 }
11
12 int get() {
13 int tmp = buffer[use];
14 use = (use + 1) % MAX;
15 count--;
16 return tmp;
17 }
最终方案
1 cond_t empty, fill;
2 mutex_t mutex;
3
4 void *producer(void *arg) {
5 int i;
6 for (i = 0; i < loops; i++) {
7 Pthread_mutex_lock(&mutex); // p1
8 while (count == MAX) // p2
9 Pthread_cond_wait(&empty, &mutex); // p3
10 put(i); // p4
11 Pthread_cond_signal(&fill); // p5
12 Pthread_mutex_unlock(&mutex); // p6
13 }
14 }
15
16 void *consumer(void *arg) {
17 int i;
18 for (i = 0; i < loops; i++) {
19 Pthread_mutex_lock(&mutex); // c1
20 while (count == 0) // c2
21 Pthread_cond_wait(&fill, &mutex); // c3
22 int tmp = get(); // c4
23 Pthread_cond_signal(&empty); // c5
24 Pthread_mutex_unlock(&mutex); // c6
25 printf("%d\n", tmp);
26 }
27 }
信号量
信号量是一种同步互斥机制的实现,普遍存在于现在的各种操作系统内核里,即我们可以用信号量来实现锁和条件变量。对于信号量,它是有一个整数值的对象,有两个关键函数对其进行操作, POSIX 标准中,是sem_wait()和 sem_post(),即P操作和V操作。
#include <semaphore.h>
sem_t s; //信号量
sem_init(&s, 0, 1); //初始化信号量为1,第二个参数指信号量是在同一进程的多个线程共享的,第三个参数指将信号量初始化为1
对于sem_wait()函数,先判断信号量是否>0,如果是,它会将信号量减1。如果不是,那么该线程会进入睡眠等待(即最终信号量<0,调用该函数的线程就会进入睡眠)。
对于sem_post()函数,它会直接将信号量加1,如果此时信号量>0,那么它会唤醒等待队列中第一个正在睡眠的线程。
因此我们可以利用信号量来解决生产者消费者问题(注意锁要紧挨着临界区):
1 sem_t empty;
2 sem_t full;
3 sem_t mutex;
4
5 void *producer(void *arg) {
6 int i;
7 for (i = 0; i < loops; i++) {
8 sem_wait(&empty); // line p1
9 sem_wait(&mutex); // line p1.5 (MOVED MUTEX HERE...)
10 put(i); // line p2
11 sem_post(&mutex); // line p2.5 (... AND HERE)
12 sem_post(&full); // line p3
13 }
14 }
15
16 void *consumer(void *arg) {
17 int i;
18 for (i = 0; i < loops; i++) {
19 sem_wait(&full); // line c1
20 sem_wait(&mutex); // line c1.5 (MOVED MUTEX HERE...)
21 int tmp = get(); // line c2
22 sem_post(&mutex); // line c2.5 (... AND HERE)
23 sem_post(&empty); // line c3
24 printf("%d\n", tmp);
25 }
26 }
27
28 int main(int argc, char *argv[]) {
29 // ...
30 sem_init(&empty, 0, MAX); // MAX buffers are empty to begin with...
31 sem_init(&full, 0, 0); // ... and 0 are full
32 sem_init(&mutex, 0, 1); // mutex=1 because it is a lock
33 // ...
34 }
读者写者锁:
1 typedef struct _rwlock_t {
2 sem_t lock; // binary semaphore (basic lock)
3 sem_t writelock; // used to allow ONE writer or MANY readers
4 int readers; // count of readers reading in critical section
5 } rwlock_t;
6
7 void rwlock_init(rwlock_t *rw) {
8 rw->readers = 0;
9 sem_init(&rw->lock, 0, 1);
10 sem_init(&rw->writelock, 0, 1);
11 }
12
13 void rwlock_acquire_readlock(rwlock_t *rw) {
14 sem_wait(&rw->lock);
15 rw->readers++;
16 if (rw->readers == 1)
17 sem_wait(&rw->writelock); // first reader acquires writelock
18 sem_post(&rw->lock);
19 }
20
21 void rwlock_release_readlock(rwlock_t *rw) {
22 sem_wait(&rw->lock);
23 rw->readers--;
24 if (rw->readers == 0)
25 sem_post(&rw->writelock); // last reader releases writelock
26 sem_post(&rw->lock);
27 }
28
29 void rwlock_acquire_writelock(rwlock_t *rw) {
30 sem_wait(&rw->writelock);
31 }
32
33 void rwlock_release_writelock(rwlock_t *rw) {
34 sem_post(&rw->writelock);
35 }
哲学家就餐问题:
我们先来看哲学家就餐的主要代码,即思考,拿起叉子,进餐,放下叉子:
int state_sema[N]; /* 记录每个人状态的数组 */
/* 信号量是一个特殊的整型变量 */
semaphore_t mutex; /* 临界区互斥 */
semaphore_t s[N]; /* 每个哲学家一个信号量 */
struct proc_struct *philosopher_proc_sema[N];
int philosopher_using_semaphore(void * arg) /* i:哲学家号码,从0到N-1 */
{
int i, iter=0;
i=(int)arg;
cprintf("I am No.%d philosopher_sema\n",i);
while(iter++<TIMES)
{ /* 无限循环 */
cprintf("Iter %d, No.%d philosopher_sema is thinking\n",iter,i); /* 哲学家正在思考 */
do_sleep(SLEEP_TIME); //在SLEEP_TIME这段时间内,当前进程放弃CPU资源
phi_take_forks_sema(i);
/* 需要两只叉子,或者阻塞 */
cprintf("Iter %d, No.%d philosopher_sema is eating\n",iter,i); /* 进餐 */
do_sleep(SLEEP_TIME);
phi_put_forks_sema(i);
/* 把两把叉子同时放回桌子 */
}
cprintf("No.%d philosopher_sema quit\n",i);
return 0;
}
拿起 / 放下叉子时,由于需要修改当前哲学家的状态,同时该状态是全局共享变量,所以需要上锁来防止条件竞争。将叉子放回桌上时,如果当前哲学家左右两边的两位哲学家处于饥饿状态,即准备进餐但没有刀叉时,如果条件符合(有两个空闲叉子),则唤醒这两位哲学家并让其继续进餐。
void phi_take_forks_sema(int i) /* i:哲学家号码从0到N-1 */
{
down(&mutex); /* 进入临界区 */
state_sema[i]=HUNGRY; /* 记录下哲学家i饥饿的事实 */
phi_test_sema(i); /* 试图得到两只叉子 */
up(&mutex); /* 离开临界区 */
down(&s[i]); /* 如果得不到叉子就阻塞 */
}
void phi_put_forks_sema(int i) /* i:哲学家号码从0到N-1 */
{
down(&mutex); /* 进入临界区 */
state_sema[i]=THINKING; /* 哲学家进餐结束 */
phi_test_sema(LEFT); /* 看一下左邻居现在是否能进餐 */
phi_test_sema(RIGHT); /* 看一下右邻居现在是否能进餐 */
up(&mutex); /* 离开临界区 */
}
phi_test_sema函数用于设置哲学家的进食状态。如果当前哲学家满足进食条件,则更新哲学家状态,执行哲学家锁所对应的V操作,以唤醒等待叉子的哲学家所对应的线程。
void phi_test_sema(i) /* i:哲学家号码从0到N-1 */
{
if(state_sema[i]==HUNGRY&&state_sema[LEFT]!=EATING
&&state_sema[RIGHT]!=EATING)
{
state_sema[i]=EATING;
up(&s[i]);
}
}
持久性化
磁盘驱动器
磁盘如图所示:
IO时间计算
IO时间:
T
I
O
T_{IO}
TIO=
T
寻道
T_{寻道}
T寻道+
T
旋转
T_{旋转}
T旋转+
T
传输
T_{传输}
T传输
IO速率:
R
I
O
R_{IO}
RIO=传输大小/
T
I
O
T_{IO}
TIO
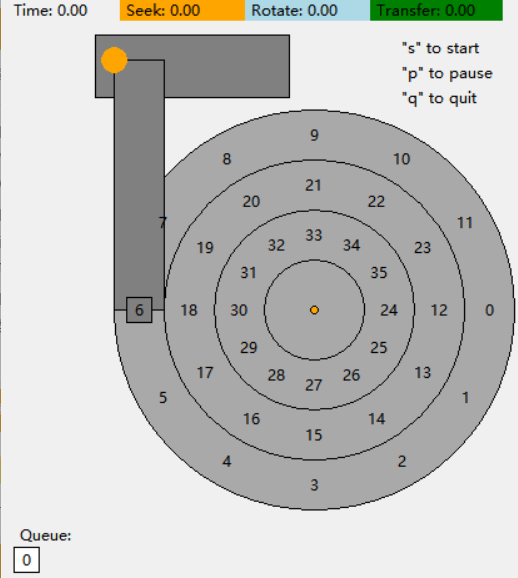
通过一个例子来理解IO时间如何计算,如图为磁盘初始状态:
假如现在有以下访问请求(访问扇区30,此处暂且不讨论多个扇区访问的请求):
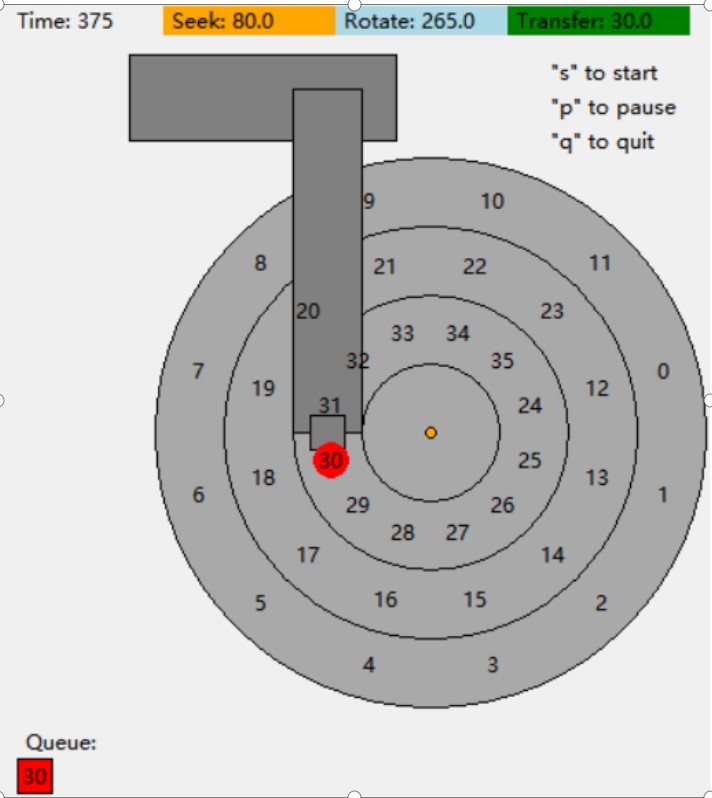
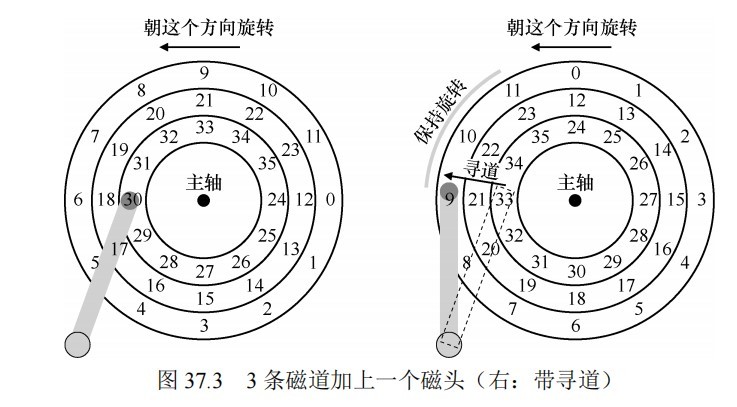
(顺时针旋转)现假定单位寻道时间为40,旋转1度旋转时间为1,一个扇区占30度,传输在扇区之间开始和结束。因此,要读取第10扇区,传输从9和10之间的一半开始,在10和11之间的一半结束,因此传输时间为30。则对于以上例子:
寻道时间:80(跨越两个磁道)
旋转时间:如果不用寻道,30和6在初始态是同一位置,意味着旋转到最后磁头要在6和5之间(这样才能完整读取6这个扇区),则旋转时间为360-15=345。由于存在寻道,因此寻道的过程中同时也在旋转,最后的旋转时间为345-80=265。(如果没有寻道,旋转时间小于寻道时间,比如45<80,那么找到对应磁道的时候,对应扇区旋转过去了,需要额外等待。则旋转时间为360-(80-45)=345)
传输时间:固定为30
总时间:80+265+30=375
理解磁道偏斜:
由上述例子不难看出,从一个磁道切换到另一个磁道时,磁盘需要时间来重新定位磁头,有可能此时要读取的扇区刚好错过,这时需要重新等待磁盘旋转一圈才能读取。因此我们引入了磁道偏斜:
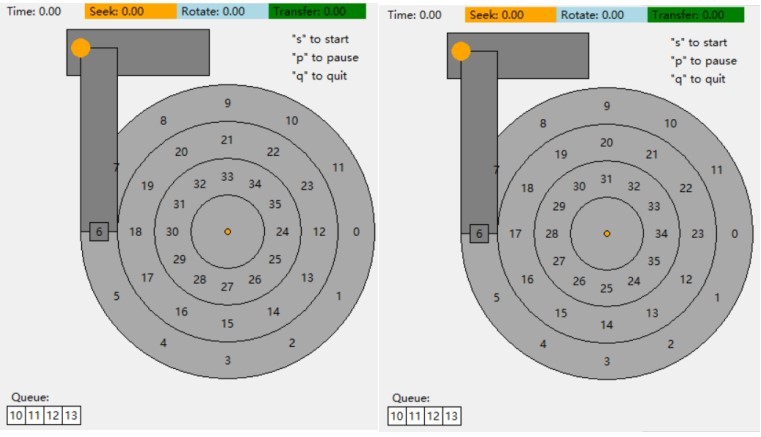
左为磁盘没有偏斜,右为磁盘偏斜为1,可以看出,相比没有磁道偏斜的情况,当磁道偏斜为1时,内侧磁道将相对于其外侧的那个磁道进行一个扇区的偏斜,因此最里面的磁道和最外面的磁道偏斜为2。
寻道时间为S,旋转角速度为W,一个扇区跨越的角度为A,偏斜为O,计算偏斜的公式可为:
S < A * O / W , 即 O > S * W / A,O取最小整数即可。
磁盘调度
当有多个扇区访问请求时,我们需要合理的规划访问计划,使得IO时间尽可能短。
FCFS(FIFO):先来先服务。
SSTF:最短寻道时间优先,SSTF 按磁道对 I/O 请求队列排序,选择在最近磁道上的请求先完成。但其有个致命缺点,也就是容易造成饥饿,如果有磁头当前所在位置的内圈磁道有稳定的请求,那么纯粹的 SSTF 方法将完全忽略对其他磁道的请求。
电梯(又称 SCAN 或 C-SCAN):针对上述的饥饿现象,我们提出了新的SCAN调度策略,简单地以跨越磁道的顺序来服务磁盘请求。我们将一次跨越磁盘称为扫一遍。因此,如果请求的块所属的磁道在这次扫一遍中已经服务过了,它就不会立即处理,而是排队等待下次扫一遍。而C-SCAN是其常见变体,它不是在一个方向扫过磁盘,该算法从外圈扫到内圈,然后从内圈扫到外圈,如此下去。其缺点在于,忽视了旋转时间。
SPTF(也称SATF):最短定位时间优先,其执行过程中总是视情况而定,以最短定位时间为优先原则(寻道时间和旋转时间相比较),当在同一磁道的旋转时间太长,大于先去其它磁道读取再回来的时间,此时SPTF优先读取其他磁道的扇区,相反如果寻道时间远大于旋转时间,那么SPTF等价于SSTF。
RAID
RAID即廉价冗余磁盘阵列,使用多个磁盘一起构建更快、更大、更可靠的磁盘系统。RAID有4个重要的级别:
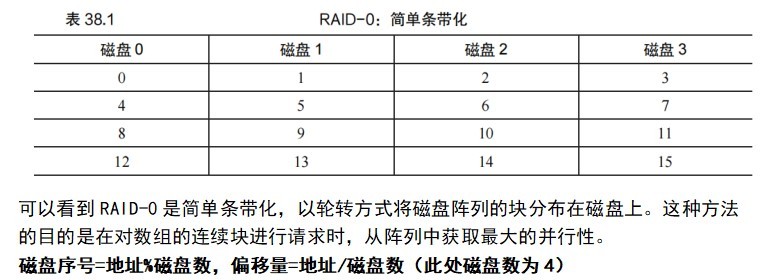
RAID-0:
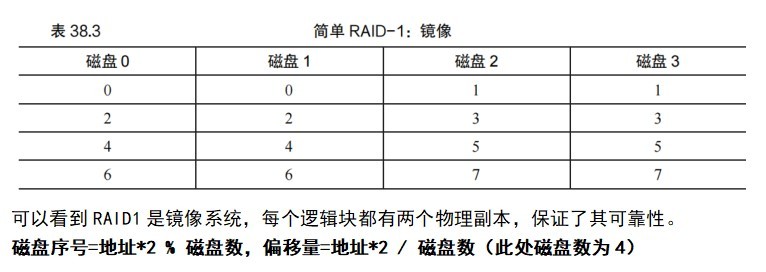
RAID-1
RAID-4
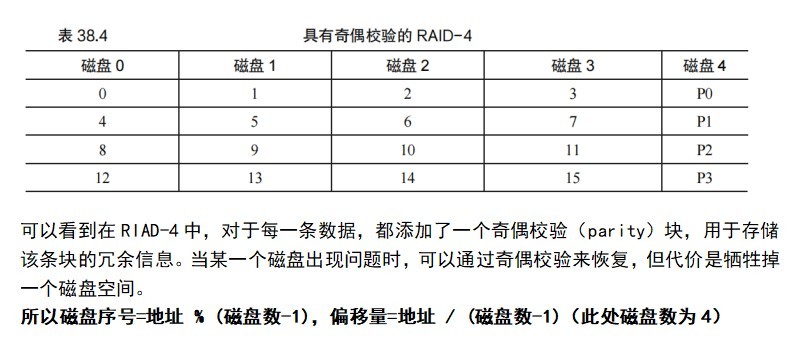
RAID-5
RAID-4的小写入问题:当我们同时往RAID-4写入写入块4和块13。这些磁盘的数据位于磁盘0和1上,因此对数据的读写操作可以并行进行,但出现的问题是奇偶校验磁盘。这两个请求都必须读取4和13的奇偶校验块,即奇偶校验块1和3(用+标记)。在这种类型的工作负载下,奇偶校验磁盘是瓶颈,因为你无法同时在disk4上读取两个扇区。此外RAID-4每次逻辑上的写入,都需要执行读和写两个操作,读是读取旧数据与新数据比较,看看是否要更改奇偶校验位,如果要那么就要进行更改,这使得随机小写入吞吐量很差。
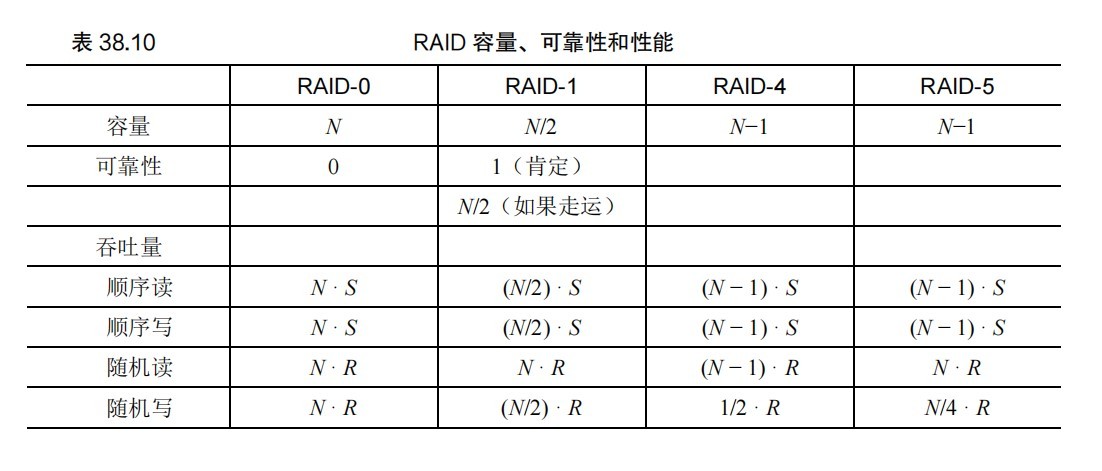
在此基础上发展出RAID-5,RAID-5有四种分布形式:

“左”、“右”表示校验和(也就是图中的P)如何分布,“左”的校验和都是从最后一个磁盘开始,依次前推,“右”的校验和从第一个磁盘开始,依次后推。“不对称”分布方式都是直接将数据按照磁盘的数据直接排下来的,而“对称”方式则将每个条带中的第一个数据放在校验和的后面,然后往后排列,需要时再绕回第一个磁盘,这样“对称”的数据排列方式就能始终按照磁盘的顺序依次下来。由于每个条带的奇偶校验块现在都在磁盘上旋转,以此来消除 RAID-4 的奇偶校验磁盘瓶颈。
S为单个磁盘顺序带宽(在连续工作负载下以 S MB/s 传输数据),R为单个磁盘随机带宽,N为磁盘数,T 为对单个磁盘的请求所需的时间
文件系统

文件系统在磁盘上的数据结构的整体组织:
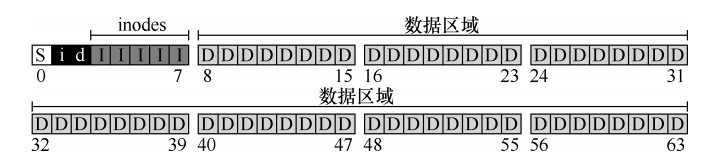
这是一个只有64块大小的磁盘,每个块4KB大。
S是超级块(SuperBlock),它主要从文件系统的全局角度描述特定文件系统的全局信息,例如文件系统中有多少个inode和数据块(在这个例子中分别为 80 和 56)、inode表的开始位置(块 3)等等。
i和d是inode和data的位图(bitmap),位图是一种简单的结构:每个位用于指示相应的对象/块是空闲(0)还是正在使用(1),这样就能记录inode和数据块是空闲还是已分配。
I是索引节点(inode),每个inode中实际上是所有关于文件的信息:文件类型(例如,常规文件、目录等)、大小、分配给它的块数、保护信息(如谁拥有该文件以及谁可以访问它)、一些时间信息(包括文件创建、修改或上次访问的时间文件下),以及有关其数据块驻留在磁盘上的位置的信息(如某种类型的指针)。实际上,文件系统中除了纯粹的用户数据外,其他任何信息通常都称为元数据。
D是数据块,即用户存放的数据。
多级索引:
为了支持更大的文件,文件系统设计者必须在 inode 中引入不同的结构。一个常见的思路是有一个称为间接指针(indirect pointer)的特殊指针。它不是指向包含用户数据的块,而是指向包含更多指针的块,每个指针指向用户数据。因此,inode 可以有一些固定数量(例如 12 个)的直接指针和一个间接指针。如果文件变得足够大,则会分配一个间接块(来自磁盘的数据块区域),并将 inode 的间接指针设置为指向它。
假如数据块大小为4KB,每个指针大小为4B。现在有一个直接指针,一个一级间接指针,一个二级间接指针,请问可寻址的文件大小是多少?
一个直接指针:1*4KB=4KB
一个一级间接指针:(4KB/4B)*4KB=4MB
一个二级间接指针:1024 * 1024 * 4KB=4GB















 2520
2520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









