







Time Series Forecasting
时序信号预测是指根据时间序列数据的历史记录来预测未来值的过程。即用过去的自己预测未来的自己,属于时序自回归。这在很多领域都有广泛的应用,比如金融市场的股票价格预测、销售量预测、天气预报等。时序预测通常涉及到统计学和机器学习的方法。
常见的时序预测方法:

选择合适的预测方法取决于数据的特点、预测目标、计算资源等因素。预处理时序数据是确保模型能够有效学习和预测的关键步骤。预处理的目的是清理数据、增强信号并减少噪声,从而提高预测模型的性能。
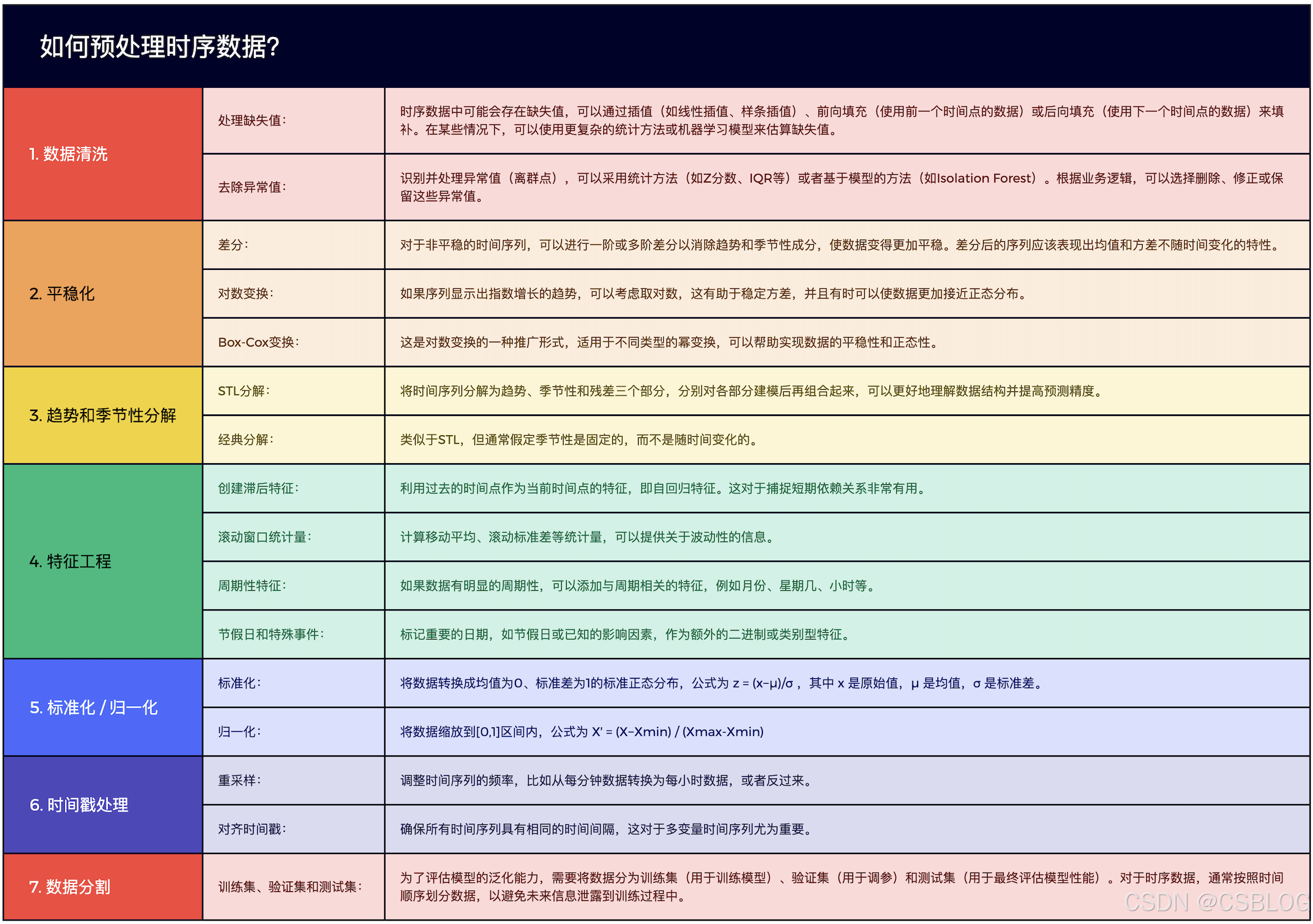
如何预处理时序数据?
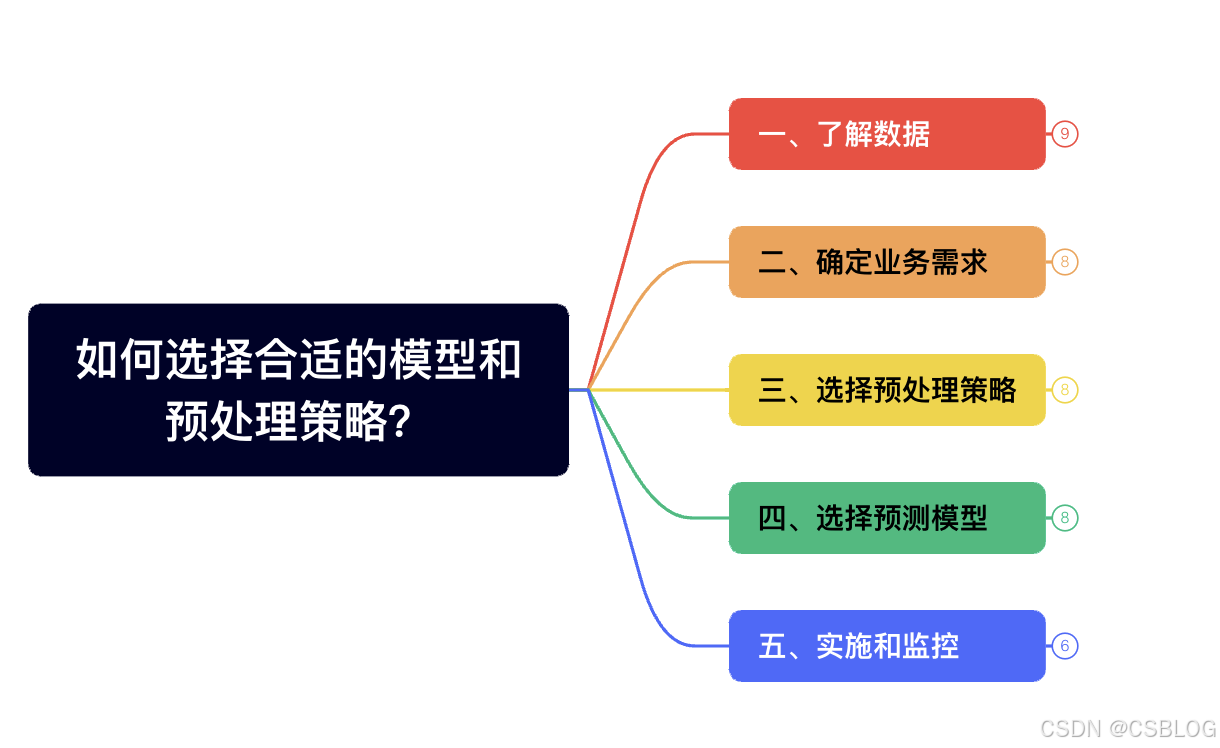
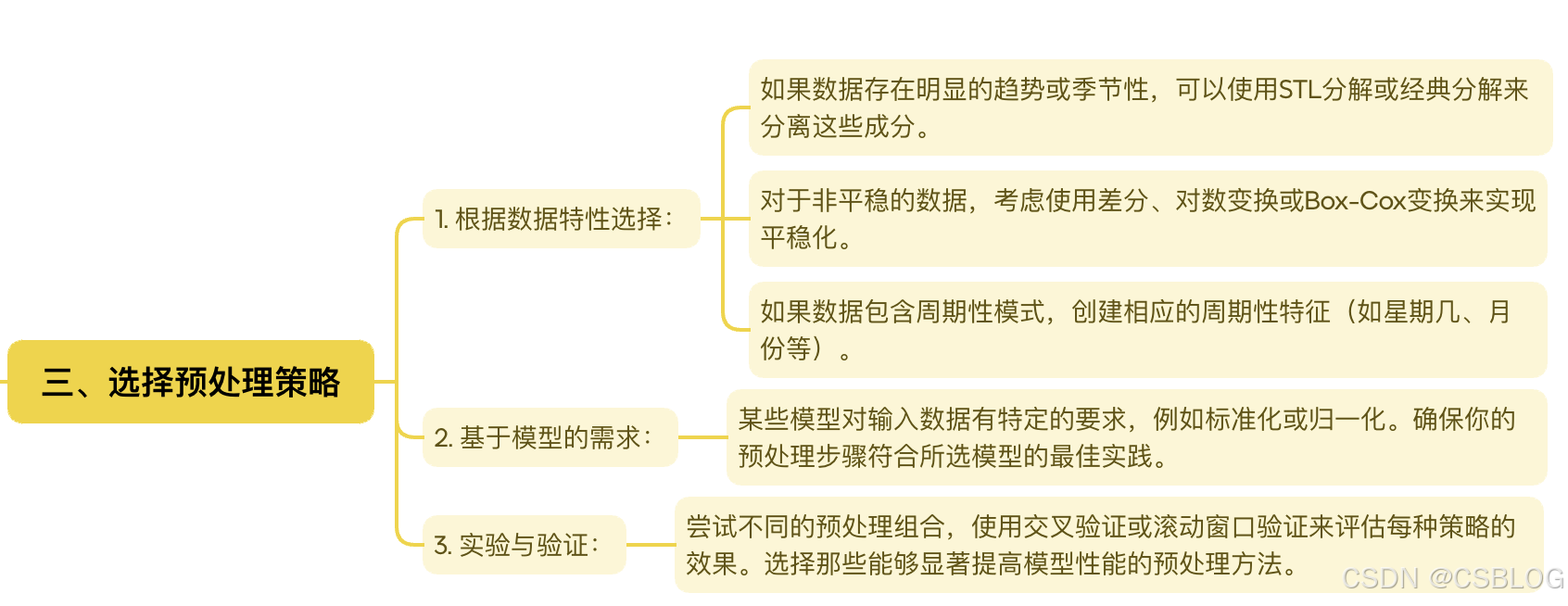
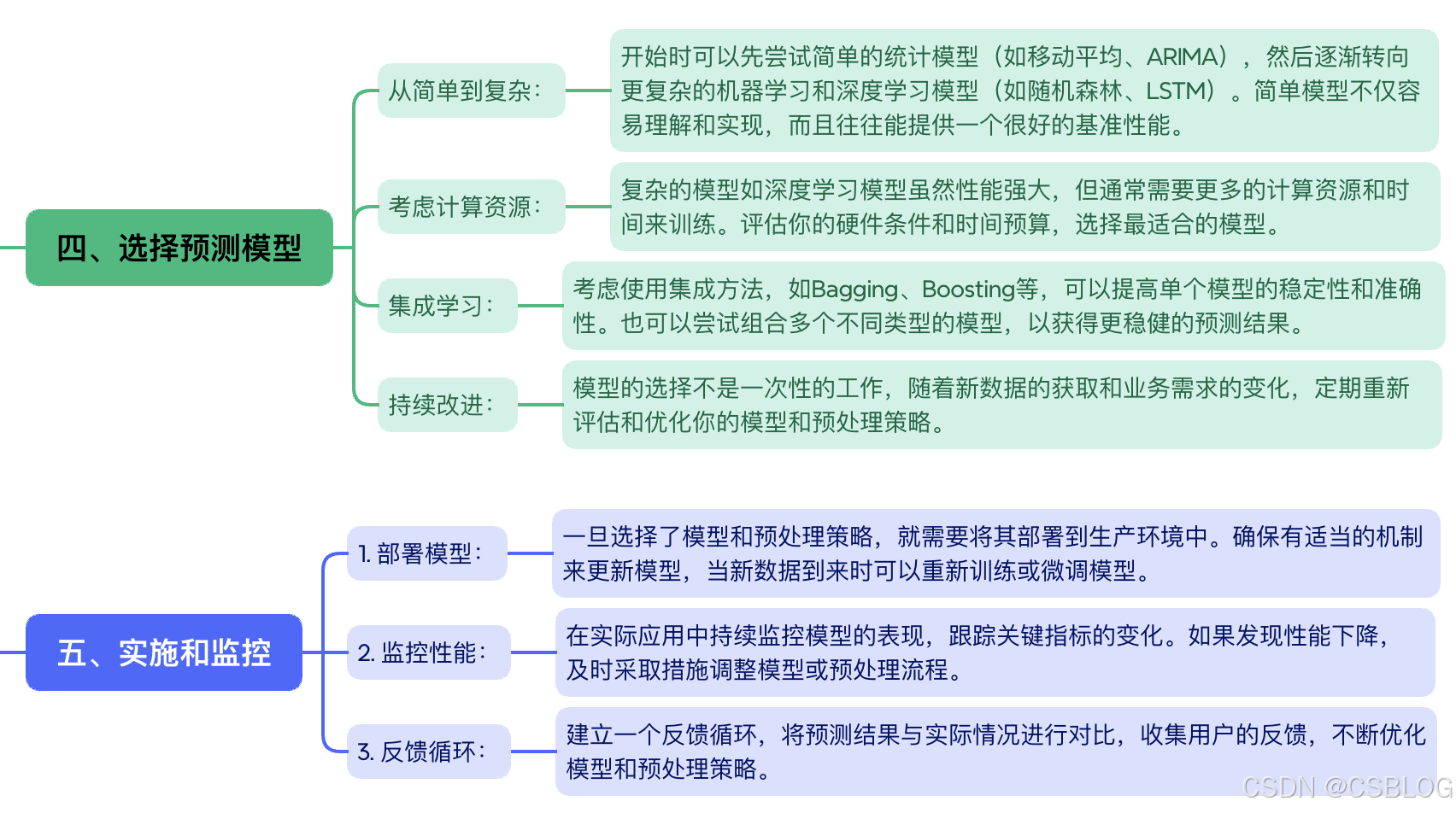
如何选择合适的模型和预处理策略?
选择合适的时序预测模型和预处理策略是一个动态迭代的过程,需要结合数据特性、业务需求以及计算资源等多个因素不断地试验和优化,可通过以下步骤,逐步找到最符合场景的解决方案。
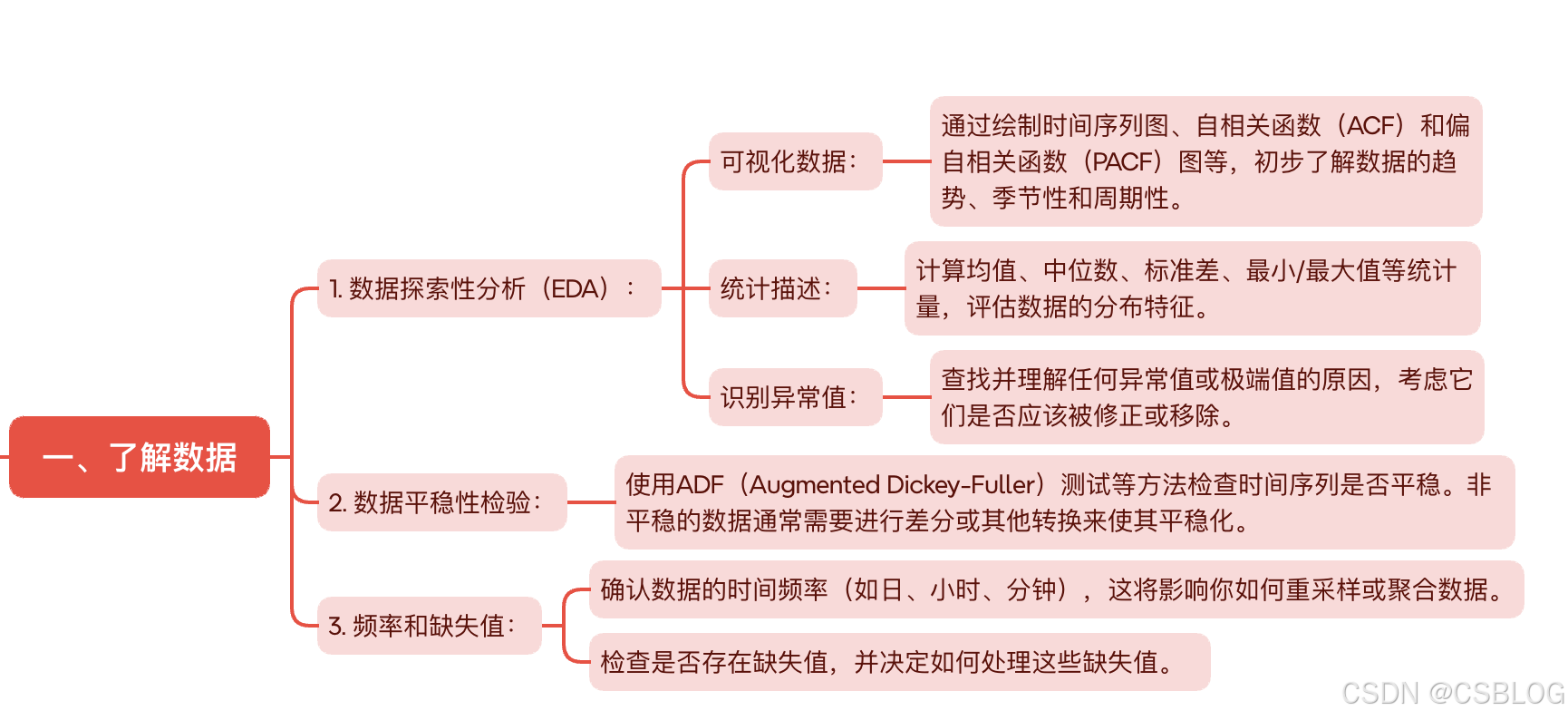
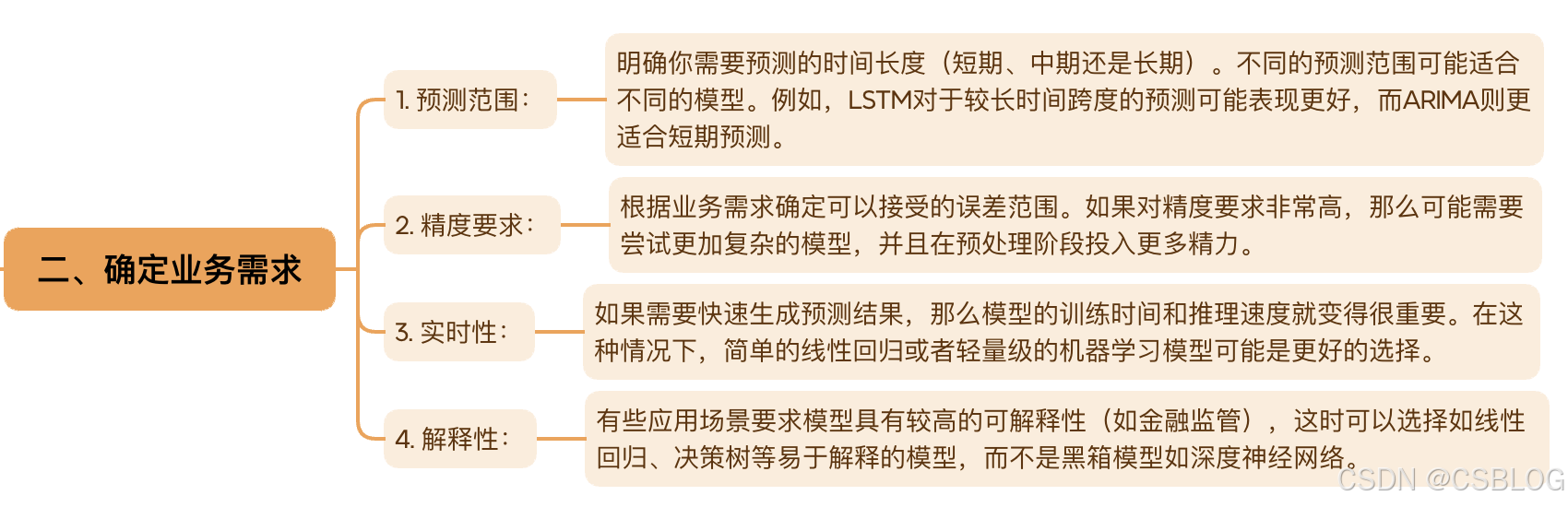
时间序列分析和模型训练的简短示例:
import pandas as pd
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import adfuller
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据
data = pd.read_csv('path_to_your_data.csv', parse_dates=['date_column'], index_col='date_column')
# EDA: 分解时间序列
result = seasonal_decompose(data['target_column'], model='additive')
result.plot()
# 平稳性检验
def check_stationarity(ts):
result = adfuller(ts)
print(f'ADF Statistic: {result[0]}')
print(f'p-value: {result[1]}')
for key, value in result[4].items():
print('Critical Values:')
print(f' {key}, {value}')
check_stationarity(data['target_column'])
# 创建滞后特征
for i in range(1, 13): # 假设我们想要12个滞后特征
data[f'lag_{i}'] = data['target_column'].shift(i)
# 处理缺失值(由于滞后特征引入)
data.dropna(inplace=True)
# 划分训练集和测试集
X = data.drop('target_column', axis=1)
y = data['target_column']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# 训练模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测并评估
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}') 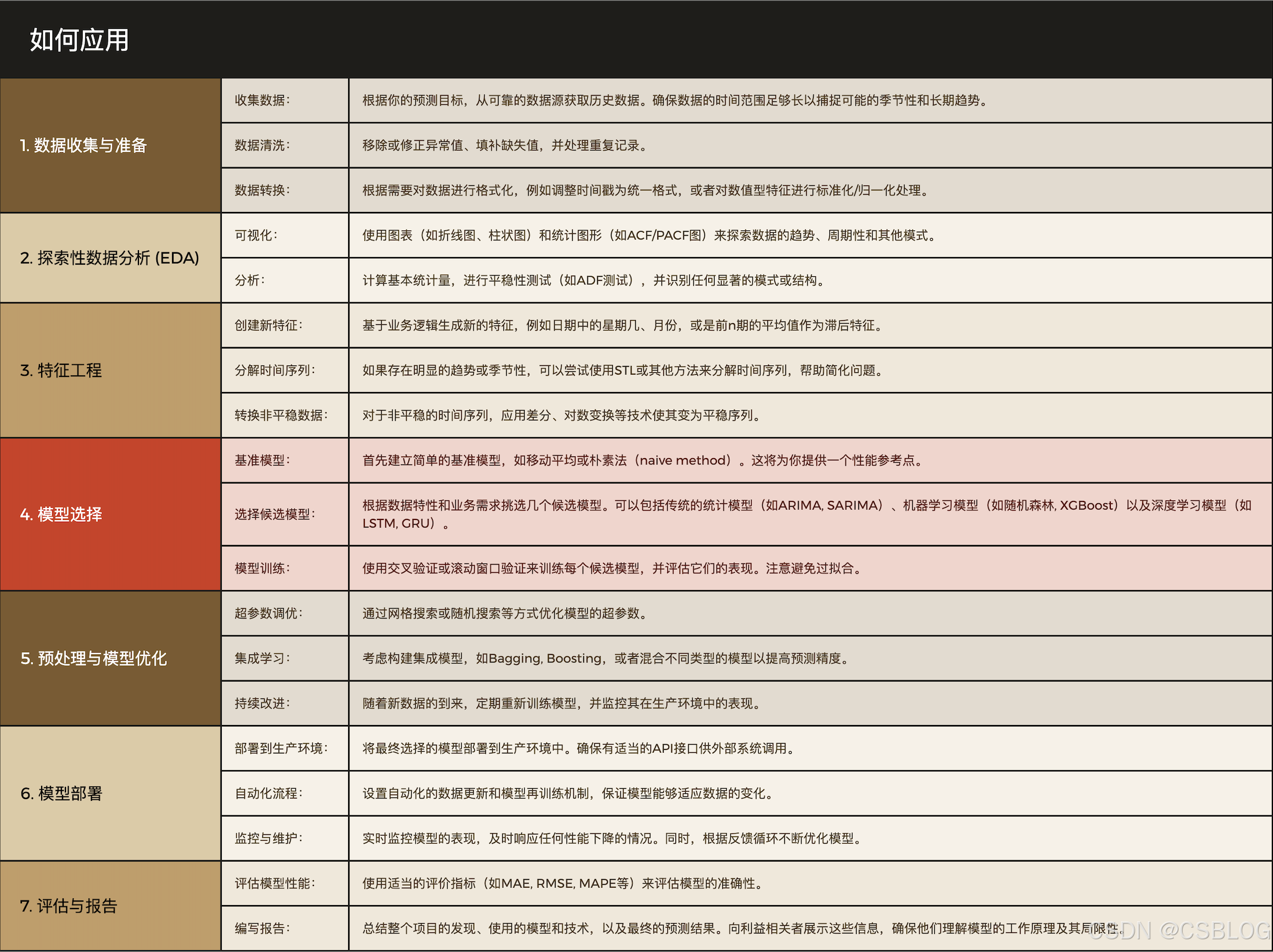


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









