






2.2 官方定义
SparkSQL模块官方定义:针对结构化数据处理Spark Module模块。

主要包含三层含义:
第一、针对结构化数据处理,属于Spark框架一个部分
- 结构化数据:一般指数据有固定的 Schema(约束),例如在用户表中,name 字段是 String 型,那么每一条数据的 name 字段值都可以当作 String 来使用;
- schema信息,包含字段的名称和字段的类型,比如:JSON、XML、CSV、TSV、MySQL Table、ORC、Parquet,ES、MongoDB等都是结构化数据;
第二、抽象数据结构:DataFrame
- 将要处理的结构化数据封装在DataFrame中,来源Python数据分析库Pandas和R语言dataframe;
- DataFrame = RDD + Schema信息;
第三、分布式SQL引擎,类似Hive框架
- 从Hive框架继承而来,Hive中提供bin/hive交互式SQL命令行及HiveServer2服务,SparkSQL都可以;
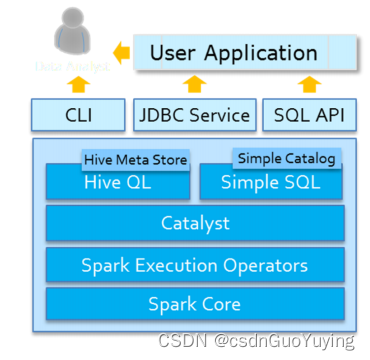
Spark SQL模块架构示意图如下:
2.3 SparkSQL 特性
Spark SQL是Spark用来处理结构化数据的一个模块,主要四个特性:

第一、易整合
- 可以使用Java、Scala、Python、R等语言的API操作。

第二、统一的数据访问 - 连接到任何数据源的方式相同。

第三、兼容Hive - 支持Hive HQL的语法,兼容hive(元数据库、SQL语法、UDF、序列化、反序列化机制)。

第四、标准的数据连接 - 可以使用行业标准的JDBC或ODBC连接

SparkSQL模块官方文档:http://spark.apache.org/docs/2.4.5/sql-programming-guide.html
第三章 DataFrame
DataFrame它不是Spark SQL提出来的,而是早期在R、Pandas语言就已经有了的。就易用性而言,对比传统的MapReduce API,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame AP不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











