







上一篇文章我们完成了YOLOv7环境的配置,接下来我们来介绍怎么标注、训练、推理。
1 训练自己的数据集
关于数据集的获取方式主要有两种,分别是获取网上开源数据集,另一个就是自己标注,我只讲怎么自己标注数据集。
1.1 标注数据集
首先我们需要安装一个用来标注图片的软件:Labelimg
第一步:我们需要为这个软件创建一个虚拟环境(参考上一篇文章)。
conda create -n labelimg python=3.12创建完成之后使用如下命令进入虚拟环境。
conda activate labelimg第二步:虚拟环境准备完成之后,开始安装Labelimg,使用pip安装,命令如下。
pip install labelimg等待加载过程完毕,我们的Labelimg也就安装完成了
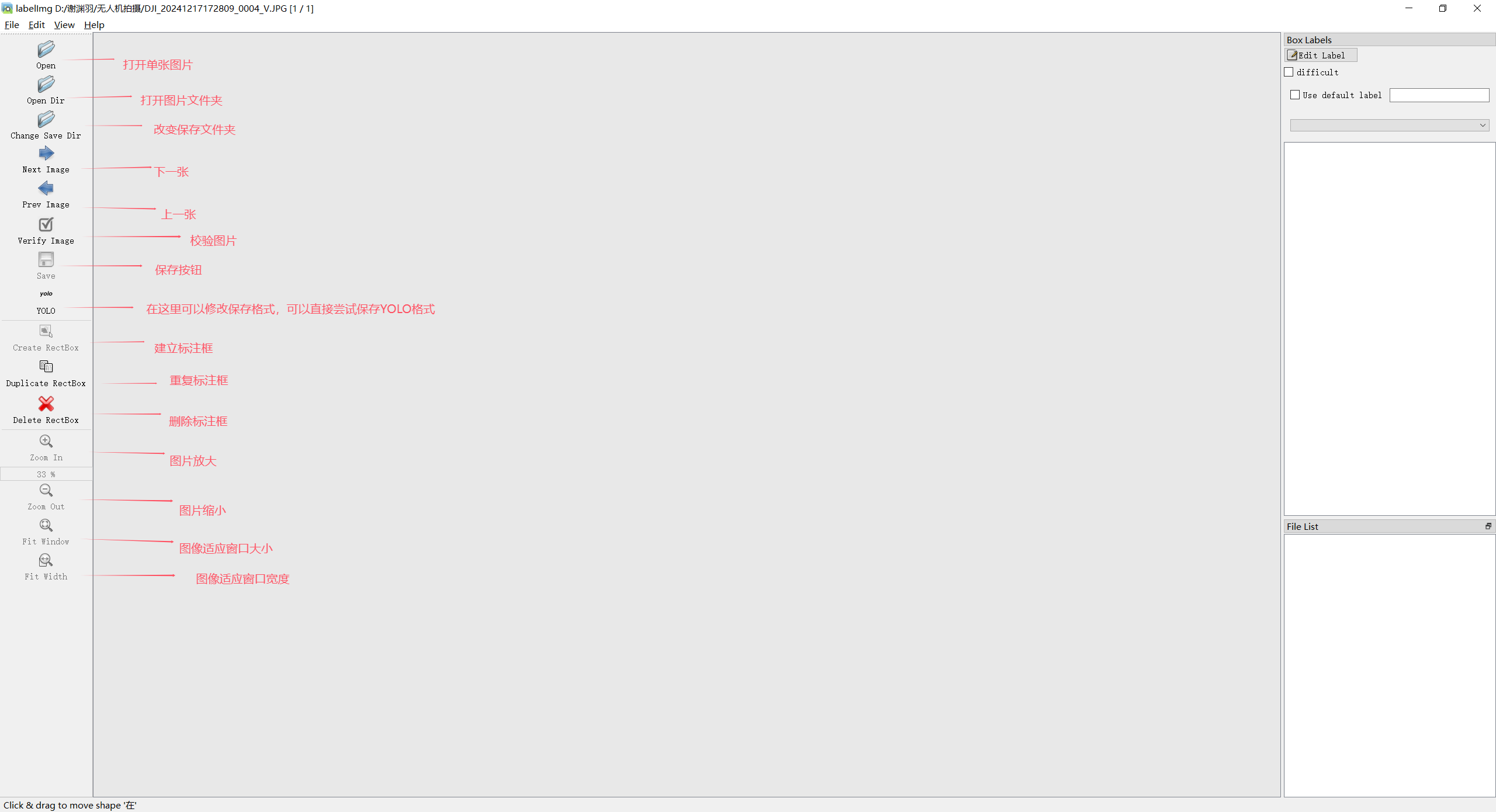
然后直接输入labelimg就可以打开操作页面,具体一些按键操作我已经在图中标注出来了。
“Open”是打开单个图像,“Open Dir” 打开图像文件夹,"Change Save Dir"图像保存的路径,“Next Image” 切换到下一张图像,“Prev Image”切换到上一张图像,“Verify Image”校验图像,“Save”保存图像,这里可以选择我们的保存格式,因为我们是使用YOLO,所以可以先试试直接保存问YOLO格式,如果出现问题再尝试进行格式的转换,“Create RectBox”画标注框一个,“Duplicate RectBox”重复标注框,“Delete RectBox”删除标注框,“Zoom In”放大图像,“Zoom Out” 缩小图像,“Fit Window”图像适用窗口,“Fit Width”图像适应宽度。
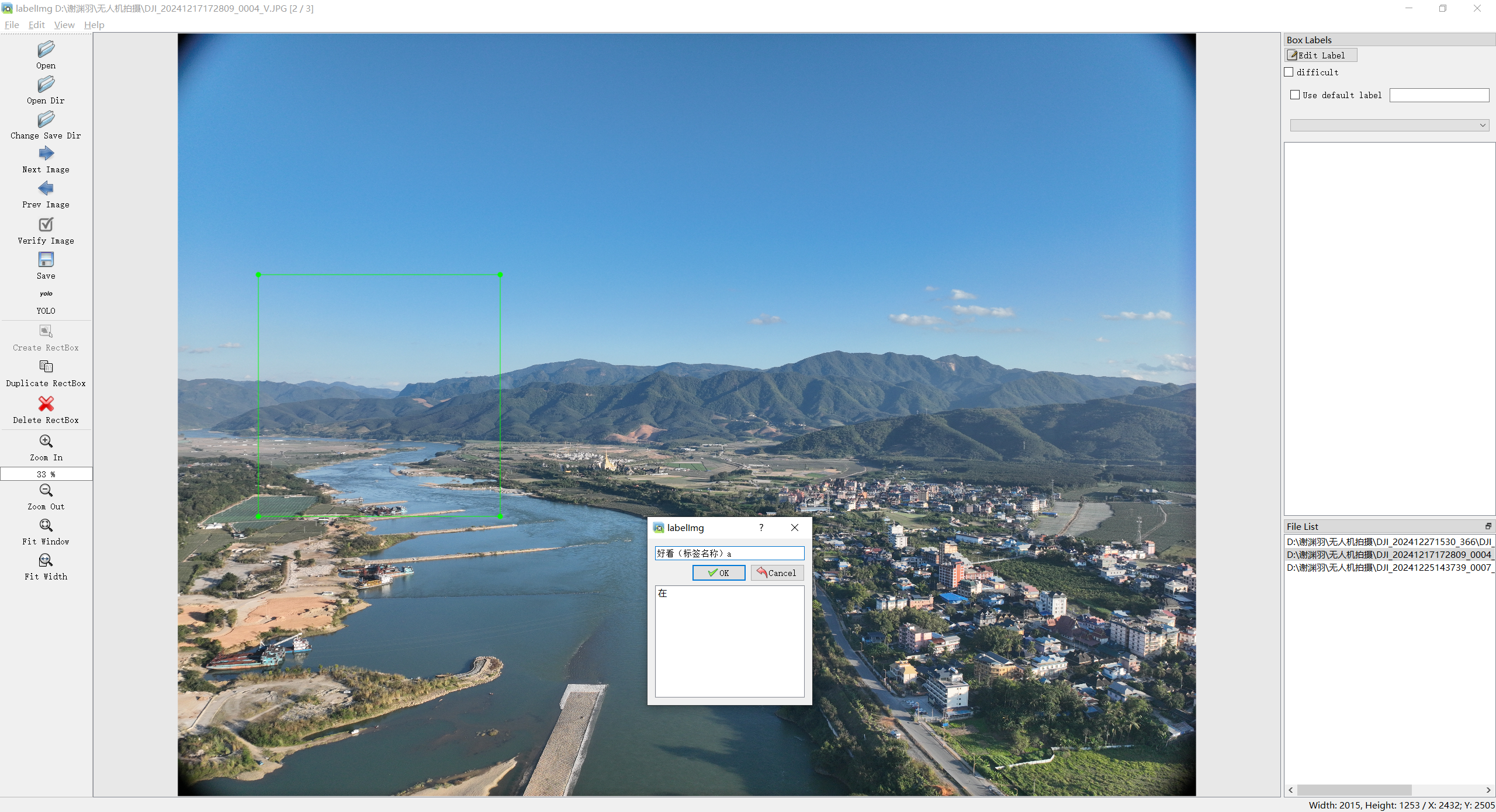
一般操作的顺序:open/open dir→create rectbox →输入类别名称 →change save dir→ 改变保存格式→Save。最后在保存文件的路径下生成.txt文件,.txt文件的名字是和标注照片的名字一样的。

这样当我们标注完成之后,就会得到一个包含照片和.txt文件的文件夹,下一步我们就是需要将其划分成为我们训练所要求的格式。
1.2 数据集划分
未划分前你的文件夹中照片与.txt文件混合在一起。

我们先将照片与标签文件分开,然后使用代码随机划分未train和val,具体结构如下:
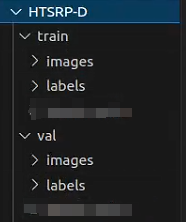
划分代码如下,这个代码是我自己在AI的帮助下写的,不一定适合所有人,如果不合适自己可以再去找AI帮助或者在评论区留言咱们互相帮助。我这里的划分比例是按训练集和验证集8:2。
import os
import random
import shutil
def find_image(label_file, image_dir):
"""
在指定目录中查找与 label_file 对应的图片文件(支持 jpg、png、jpeg、webp)
:param label_file: 标注文件名(.txt)
:param image_dir: 图片存放目录
:return: 匹配的图片路径(如果找到),否则返回 None
"""
base_name = os.path.splitext(label_file)[0] # 获取文件名(不含扩展名)
extensions = ['.jpg', '.png', '.jpeg', '.webp'] # 支持的图片格式
for ext in extensions:
image_path = os.path.join(image_dir, base_name + ext)
if os.path.exists(image_path):
return image_path # 找到匹配的图片文件
return None # 没有找到匹配的图片
def split_images_and_labels(image_dir, label_dir, train_image_dir, test_image_dir, train_label_dir, test_label_dir, train_ratio=0.8):
"""
将 YOLO 数据集中的图片和标注文件随机分配到训练集和测试集中
:param image_dir: 存放原始图片文件的目录
:param label_dir: 存放原始标注文件的目录
:param train_image_dir: 用于存放训练集图片的目录
:param test_image_dir: 用于存放测试集图片的目录
:param train_label_dir: 用于存放训练集标注文件的目录
:param test_label_dir: 用于存放测试集标注文件的目录
:param train_ratio: 训练集所占比例,默认80%
"""
# 获取所有标注文件列表
label_files = [f for f in os.listdir(label_dir) if f.endswith(".txt")]
# 打乱文件顺序
random.shuffle(label_files)
# 根据比例划分数据集
total_files = len(label_files)
train_count = int(total_files * train_ratio)
train_labels = label_files[:train_count]
test_labels = label_files[train_count:]
# 创建目标目录(如果不存在)
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(test_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
# 复制标注文件和对应的图片到训练集
for label_file in train_labels:
image_path = find_image(label_file, image_dir) # 查找对应图片
if image_path:
shutil.copy(image_path, os.path.join(train_image_dir, os.path.basename(image_path)))
shutil.copy(os.path.join(label_dir, label_file), os.path.join(train_label_dir, label_file))
# 复制标注文件和对应的图片到测试集
for label_file in test_labels:
image_path = find_image(label_file, image_dir) # 查找对应图片
if image_path:
shutil.copy(image_path, os.path.join(test_image_dir, os.path.basename(image_path)))
shutil.copy(os.path.join(label_dir, label_file), os.path.join(test_label_dir, label_file))
print(f"已将 {train_count} 个标注文件及其图片分配到训练集,{total_files - train_count} 个标注文件及其图片分配到测试集。")
# 假设标注文件存放在 'labels/' 目录,图片存放在 'images/' 目录
image_directory = "C:/Users/123/Desktop/HTSRP-D/images"#修改为你自己的路径
label_directory = "C:/Users/123/Desktop/HTSRP-D/labels"
# 假设训练集和测试集标注文件和图片的目标目录
train_image_directory = "C:/Users/123/Desktop/HTSRP-D/train/images" #都修改为你自己的路径
val_image_directory = "C:/Users/123/Desktop/HTSRP-D/val/images"
train_label_directory = "C:/Users/123/Desktop/HTSRP-D/train/labels"
val_label_directory = "C:/Users/123/Desktop/HTSRP-D/val/labels"
# 调用函数进行数据集划分
split_images_and_labels(image_directory, label_directory, train_image_directory, test_image_directory, train_label_directory, test_label_directory)划分完成之后,我们数据集准备工作也就完成了,下面就是训练前的参数以及一些代码的修改。
1.3 训练
这里我默认你们已经下载完成了YOLOv7的源码和所有权重。
第一步:修改ymal文件
在yolov7-main/data下有一个coco.yaml文件,这是用来指定训练数据集的文件。
我是直接复制一个副本然后重命名为myyolo.yaml。
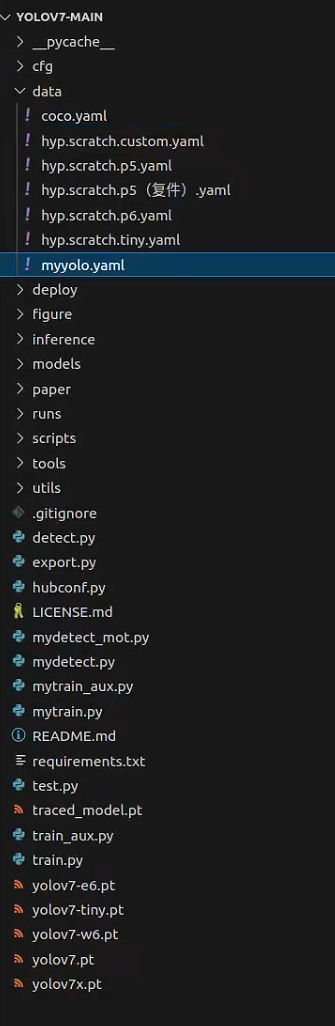
然后打开这个yaml文件,进行修改
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/sci/XXA/datasets/HTSRP-D/train/images # 1123 images这里是你的train文件路径
val: /home/sci/XXA/datasets/HTSRP-D/val/images # 281 images这是val文件路径,根据你的数据集路径修改
#test: ./coco/test-dev2017.txt # 20288 of 40670 images, submit to ,https://competitions.codalab.org/competitions/20794因为我不用test所以直接#了
# number of classes
nc: 2#你的标签数量,比如你只有猫和狗,那就是2
# class names
names: [ 'cat', 'dog' ]#这里修改为你的标签名称第二步:放入权重
将之前下载的yolo模型的权重放到yolov7-main下,根据你自己的需要来,如果你的电脑性能不高就可以试试tiny,因为他比较轻量化,对电脑负担没那么重,我这里就直接使用yolov7.pt。在第一步的图片中可以看到我已经把那个pt文件放进去了。
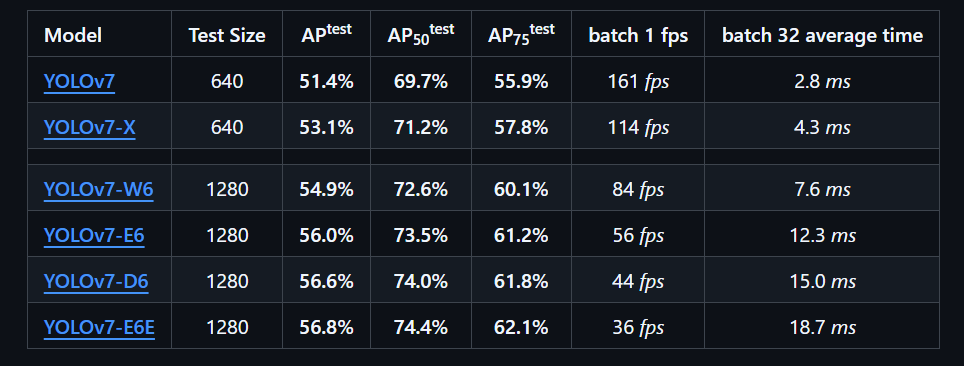
第三步:修改train.py文件
weights修改成自己的权重
cfg要修改成对应的yaml文件,比如我用的是yolov7.pt那么就在yolov7-main/cfg文件夹里找到对应的yolov7.yaml,我在下面第二幅图中忘记标出来了,见谅见谅。
batch-size一般默认是2的倍数。如8、16、32等
这里还有一个img-size这是照片尺寸,可以先不改,等熟悉之后根据自己爹需要来修改
epochs是训练轮次,第一次测试就简单测试一下,搞个10就可以了
device就是来修改你用来训练的设备用的是cpu还是gpu

ok,上述修改都完成之后,就可以开始训练了。
我们直接在终端中激活虚拟环境,切换到我们的train文件所在的目录,然后运行train.py文件

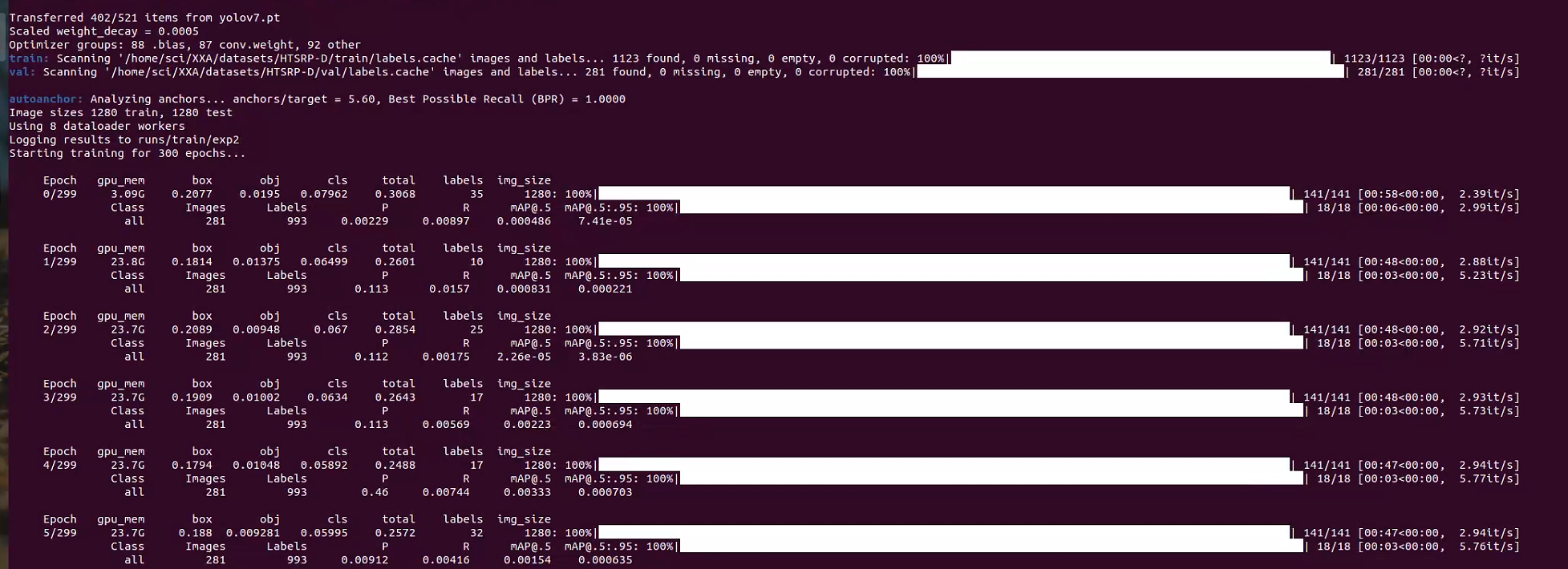
这样就开始训练了,静静等待训练结束即可,训练结束之后,一些数据会提示你保存到什么什么位置。你可以根据这位置去查看训练中的最优权重best.pt。这个要用于后续的推理过程。

2 进行推理
如果你能顺利完成上述步骤,那么推理过程就很简单了。所谓推理过程其实就是使用你训练之后得到的最好的权重(也可以不是)对没有标注的图片进行检测。这里需要用到detect.py文件。
第一步:先找到我们训练后的最优权重best.pt的保存路径,然后复制这个路径到detect.py中的weights中代替原先的yolov7.pt,然后修改source里的数据来源,你可以将你需要检测的照片放入图中的路径,也可以指定一个新的路径。修改完毕之后,在终端直接输入命令python detect.py运行检测程序。
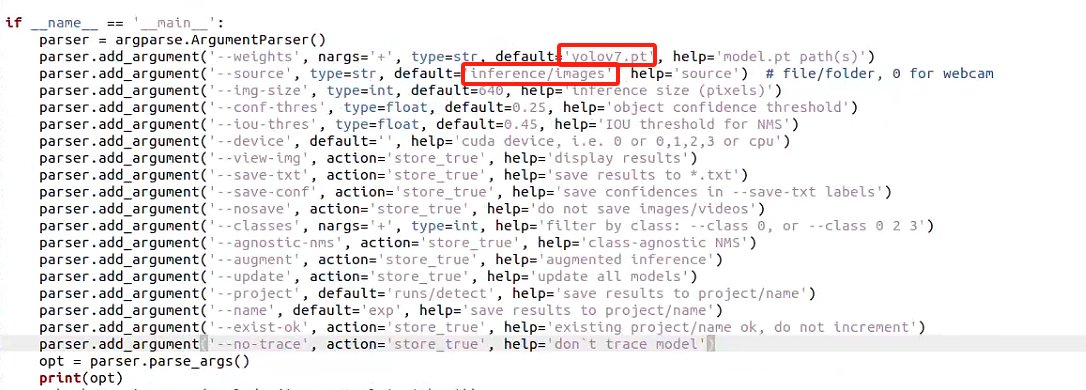
测试过程中就可以看到如下的提示,我们可以根据他给的路径去查看检测效果。

3 结束
到此为止,关于YOLOv7的部署和训练以及后续的推理就已经介绍完毕了,如果各位朋友们有任何疑问,或者发现我哪里有错误的的地方欢迎在评论区留言。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









