







一、中文分词-难点
一、中文分词的3大难点
1、没有统一的标准
- 目前中文分词没有统一的标准,也没有公认的规范
- 不同的公司和组织各有各的方法和规则
- 例如人名,在哈工大标准中姓和名是分开的,但在Hanlp(Han Language Processing汉语言处理包)中是合在一起的
- 需要根据不同的需求制定不同的分词标准
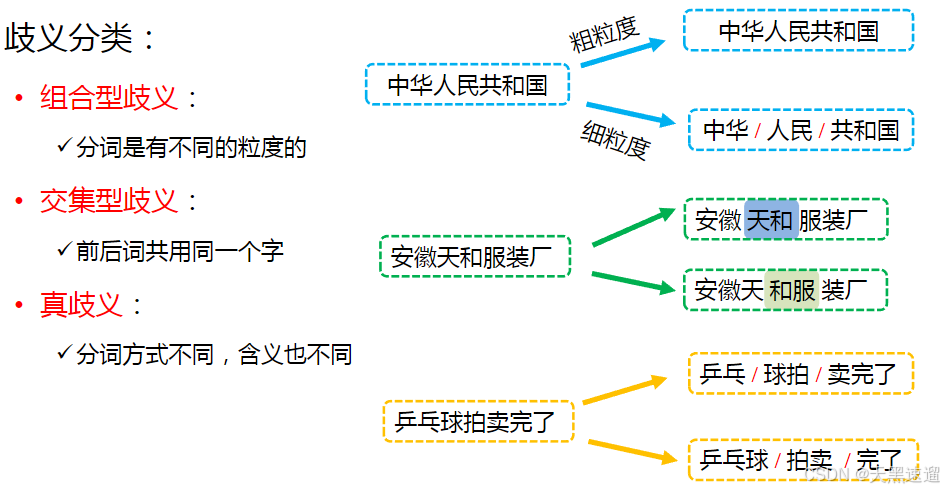
2、歧义如何划分
- 歧义:对同一个待切分字符序列存在多个分词结果
- 例:“乒乓球拍卖完了”有两种不同的分词方式,含义也不同
- 乒乓/球拍/卖完了
- 乒乓球/拍卖/完了
3、新词如何识别
- 信息爆炸的时代,三天两头就会冒出来一堆新词
- 蓝瘦香菇
- 泰裤辣
- 奥利给
- 酱紫
#jieba添加新词
jieba.add_word("蓝瘦香菇") #定义新词汇
str_6 = jieba.lcut("我看了这个电视剧有点蓝瘦香菇")
print(str_6)
# jieba删除本地新词
jieba.del_word("蓝瘦香菇")
str_8 = jieba.lcut("我看了这个电视剧有点蓝瘦香菇")
print(str_8)二、基于词典匹配的分词方法
将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配
成功则按照词典的词分词,匹配失败通过调整或者重新选择
代表方法:正向最大匹配、反向最大匹配法、双向最大匹配
正向最大匹配、反向最大匹配法、双向最大匹配的共同缺点:
- 对词表极为依赖,如果没有词表,则无法进行;如果词表中缺少需要的词,结果也不会正确
- 切分过程中不会关注整个句子表达的意思,只会将句子看成一个个片段
- 如果文本中出现一定的错别字,会造成一连串影响
- 对于人名等的无法枚举实体词无法有效的处理
一、中文分词-正向最大匹配
1、分词步骤:
1、收集一个词表;2、对于一个待分词的字符串、从前向后寻找最长的,在此表中出现的词,在词边界做切分;3、从切分处重复步骤2、直到字符串末尾
例:北京大学生前来报道
北京 生前
北京大学 前来
大学 报道
大学生
划分得:北京大学 / 生前 / 来 / 报道(不能确保划分结果的正确)
2、实现方式一
1、找出词表中最大词长度
2、从字符串开头开始选取最大词长度的窗口、检查窗口内的词是否在词表中
3、如果在词表中,在词边界处进行切分,之后移动到词边界处,重复步骤2
4、如果不在词表中,窗口右边界回退一个字符,之后检查窗口词是否在词表中
- 切分过程
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
#分词方法:最大正向切分的第一种实现方式
import re
import time
#加载词典
def load_word_dict(path):
max_word_length = 0
word_dict = {} #用set也是可以的。用list会很慢
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
word_dict[word] = 0
max_word_length = max(max_word_length, len(word))
return word_dict, max_word_length
#先确定最大词长度
#从长向短查找是否有匹配的词
#找到后移动窗口
def cut_method1(string, word_dict, max_len):
words = []
while string != '':
lens = min(max_len, len(string))
word = string[:lens]
while word not in word_dict:
if len(word) == 1:
break
word = word[:len(word) - 1]
words.append(word)
string = string[len(word):]
return words
#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):
word_dict, max_word_length = load_word_dict("dict.txt")
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict, max_word_length)
writer.write(" / ".join(words) + "\n")
writer.close()
print("耗时:", time.time() - start_time)
return
string = "北京大学生前来报道"
word_dict, max_len = load_word_dict("dict.txt")
print(cut_method1(string, word_dict, max_len))
main(cut_method1, "corpus.txt", "cut_method1_output.txt")
3、实现方式二(前缀字典)
1、从前向后进行查找
2、如果窗口内的词是一个词前则继续扩大窗口
3、如果窗口内的词不是一个词前缀,则记录已经发现的词,并将窗口移动到词边界
{ 0代表不是一个词,但是词的前缀 1代表是一个词
“北”:0,
“北京”:1,
“北京大”:0,
“北京大学”:1,
“北京大学生”:1,
“大”:0,
“大学”:0,
“大学生”:1
}
- 切分过程:
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
- 北京大学生前来报道
#分词方法最大正向切分的第二种实现方式
import re
import time
import json
#加载词前缀词典
#用0和1来区分是前缀还是真词
#需要注意有的词的前缀也是真词,在记录时不要互相覆盖
def load_prefix_word_dict(path):
prefix_dict = {}
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
for i in range(1, len(word)):
if word[:i] not in prefix_dict: #不能用前缀覆盖词
prefix_dict[word[:i]] = 0 #前缀
prefix_dict[word] = 1 #词
return prefix_dict
#输入字符串和字典,返回词的列表
def cut_method2(string, prefix_dict):
if string == "":
return []
words = [] # 准备用于放入切好的词
start_index, end_index = 0, 1 #记录窗口的起始位置
window = string[start_index:end_index] #从第一个字开始
find_word = window # 将第一个字先当做默认词
while start_index < len(string):
#窗口没有在词典里出现
if window not in prefix_dict or end_index > len(string):
words.append(find_word) #记录找到的词
start_index += len(find_word) #更新起点的位置
end_index = start_index + 1
window = string[start_index:end_index] #从新的位置开始一个字一个字向后找
find_word = window
#窗口是一个词
elif prefix_dict[window] == 1:
find_word = window #查找到了一个词,还要在看有没有比他更长的词
end_index += 1
window = string[start_index:end_index]
#窗口是一个前缀
elif prefix_dict[window] == 0:
end_index += 1
window = string[start_index:end_index]
#最后找到的window如果不在词典里,把单独的字加入切词结果
if prefix_dict.get(window) != 1:
words += list(window)
else:
words.append(window)
return words
#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):
word_dict = load_prefix_word_dict("dict.txt")
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict)
writer.write(" / ".join(words) + "\n")
writer.close()
print("耗时:", time.time() - start_time)
return
string = "王羲之草书《平安帖》共有九行"
# string = "你到很多有钱人家里去看"
# string = "金鹏期货北京海鹰路营业部总经理陈旭指出"
# string = "伴随着优雅的西洋乐"
# string = "非常的幸运"
prefix_dict = load_prefix_word_dict("dict.txt")
# print(cut_method2(string, prefix_dict))
# print(json.dumps(prefix_dict, ensure_ascii=False, indent=2))
main(cut_method2, "corpus.txt", "cut_method2_output.txt")
二、中文分词-反向最大匹配
- 北 京 大 学 生 前 来 报 到
- 正向匹配: 北京大学 / 生前 / 来 / 报到
- 反向匹配: 北京 / 大学生 / 前来 / 报到
- 友好的哥谭市民
- 正向匹配: 友好 / 的哥 / 谭 / 市民
- 反向匹配: 友好 / 的 / 哥谭 / 市民
三、中文分词-双向最大匹配
思路:同时进行正向最大切分,和负向最大切分,之后比较两者结果,决定切分方式。
比较方式:
1.单字词:词表中可以有单字,从分词的角度,我们也会把它称为一个词
2.非字典词:未在词表中出现过的词,一般都会被分成单字
3.词总量:不同切分方法得到的词数可能不同
- 我们在野生动物园玩
- 正向最大匹配法: “我们/在野/生动/物/园/玩”
- 词典词3个,单字字典词为2,非词典词为1。
- 逆向最大匹配法: “我们/在/野生动物园/玩”
- 词典词2个,单字字典词为2,非词典词为0。
词表:我们 在野 生动 动物 野生动物园 野生 动物园 在 玩 园
三、基于统计的分词方法
在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律(称为
训练),从而实现对未知文本的切分
常用的算法:HMM、CRF、N-gram
四、基于深度学习的分词方法
直接以最基本的向量化原子特征作为输入,经过多层非线性变换,输出层就可以很好的预测
当前字的标记或下一个动作。在深度学习的框架下,仍然可以采用基于子序列标注的方式,
或基于转移的方式,以及半马尔科夫条件随机场 算法:LSTM+CRF、BiLSTM+CRF
一、基于机器学习
上 海 自 来 水 来 自 海 上 对于每一个字,我们想知道它是不是一个词的边界
上 | 海 | 自 | 来 | 水 | 来 | 自 | 海 | 上
0 1 0 0 1 0 1 1 1
蓝色表示不是词边界,红色表示是词边界
问题转化为:对于句子中的每一个字,进行二分类判断,正类表示这句话中,它是词边界,负类表示它不是词边界



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











