







1. 匹配字符串
以A开头:select * from table where name like ‘A%’
以A结尾:select * from table where name like ‘%A’
包含A:select * from table where name like ‘%A%’
2. 手撕sql
1 . 写sql语句,一个表有一个字段age,写sql查出age<3,先根据age字段分组,求id最大的那个数据。
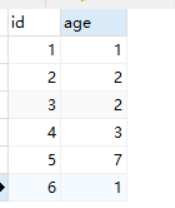
select max(id) from yue where age<3 group by age;
2 . 查询出播放量最高的视频
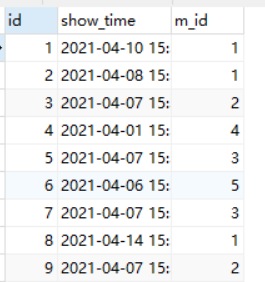
mysql> select m_id from movie group by m_id order by count(m_id) desc limit 1;
2 . 1 查询出播放量前三的视频
mysql> select m_id from movie group by m_id order by count(m_id) desc limit 3;
2 . 2 查询出播放量第二高的视频
mysql> select m_id from movie group by m_id order by count(m_id) desc limit 1,1;
3. 索引的创建
create unique index S#_index on S(S#);
=========================================================
以下是工作之后在学习sql方面的记录
主要是对postgresql数据库的操作
case when语句,用于计算条件列表并返回多个可能结果表达式之一
CASE input_expression
WHEN when_expression THEN
result_expression [...n ] [
ELSE
else_result_expression
END
不同时区之间的转换,cct表示中国沿海时间(北京时间),pst表示(美国)太平洋标准时间
select 列名(日期) at time zone 'cct' as time from 表名;
decode() 函数就是将某个字段进行判断,并根据条件,将符合条件的值返回
# condition是要判断条件的字段,如果condition的值于key1相同,则结果返回value1,如果condition的值于key2相同,则结果返回value2,如果key3…,如果都不匹配的话,这返回的结果为最后一个,及default位置的值。
decode(condition,key1,value1,key2,value2,key3,value3,...,default)
#string:指定的要截取的字符串
#start:规定在字符串的何处开始
#length:指定要截取的字符串长度
substr(string, start, length) # 截取字符串的内容
instr('源字符串' , '目标字符串' ,'开始位置','第几次出现') #截取的字符串在源字符串中的“位置”
# string:需要进行正则处理的字符串
# pattern:进行匹配的正则表达式
# position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
# occurrence:获取第几个分割出来的组(分割后最初的字符串会按分割的顺序排列成组)
# modifier:模式(‘i’不区分大小写进行检索;‘c’区分大小写进行检索。默认为’c’)针对的是正则表达式里字符大小写的匹配
REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
trunc( number, [ decimal_places ] ) # 返回一个数截断到一定的小数位数
lpad(number,一共需要的位数,填充的数字) #















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









