







目标:
搞清楚高并发场景下,java内存模型是怎么支持的,对象在内存中是怎么布局的?
目录
搞清楚高并发场景下,java内存模型是怎么支持的,对象在内存中是怎么布局的?
CPU级别采用内存屏障保证或者Java的汇编指令 Lock :
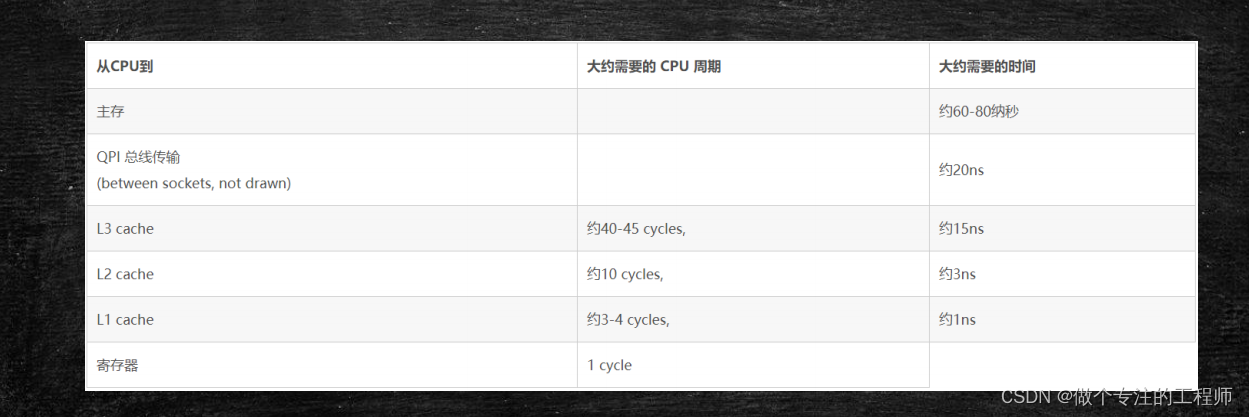
1.硬件层的并发优化基础知识

备注:
L3高速缓存也是在主板上,所以也是被所有的CPU共享的。
L0寄存器,存储着CPU内部核心的几个计算单元,用于计算。
离CPU越近容量越小,成本越高,速度越快。
比如说 有个变量int a=3;在 L2上,计算时CPU会先把a load到L1上,然后被L0直接加载计算。
2.多核CPU线程访问条件下数据不一致性问题?

原因:
两个CPU彼此独立,但是都是操作CPU的共享区域的数据,比如一个CPU 对X作了修改,另一CPU是不能及时知道的。这就造成了共享区域的数据对各个不同的CPU 来说数据不一致问题。
解决方案:
老的CPU:

总线锁会锁住总线,使得其他CPU甚至不能访问内存中其他的地址,因而效率较低
新的CPU
现在CPU的数据一致性,通过缓存锁+总线锁来解决
https://www.cnblogs.com/z00377750/p/9180644.html

新的CPU采用缓存锁(缓存一致性)来解决,一致性的协议又很多,Intel采用了MESI协议。
CPU会对缓存的内容做状态标记,如果读取的内容相对于主存来说被更改过(自己修改过),则状态改这个内容对应的缓存行状态改为Modified(别的cpu对这个内容所在缓存行状态就是Invalid);如果读取的内容自己独享,就将其所在缓存行状态改为Exclusive。如果读取的内容,我读的时候别人也在读取,该内容所在缓存行状态就修改为Shared。如果读取的内容别的cPU已经修改过,说明我的读的内容无效了,该内容所在缓存行 状态就变为Invalid。
缓存行
现在cpu 缓存数据,不是一个字节一个字节来缓存,而是以一个缓存行,默认64字节。一次性加载到缓存中。
MESI带来的伪共享问题
如果自己要修改某个数据A,发现它的状态已经变为了Invalid,则去缓存中再加载一次。

思考这个场景: x,y位于同一个缓存行,cpu1只想的读取x,cpu2只想读取y
由于读取时必须以缓存行为单位,cpu1 读取x时,也读取到了y。 cpu1改变了x的值后,x所在的缓存行的状态在CPU1中就会被改变为modified, 在cpu2中x所在的缓存行状态就会变为invalid。 因此,cpu2 本来想读取y,一看y 所在缓存行状态变为了 invalid 。就会去重新加载y所在的缓存行。问题是cpu2其实只关注y,y的值也没有变化,而x的变化和它无关。因此本质上cpu2不需要去进行这次缓存加载的。
同理cpu2对y作了修改,后cpu1也得重新加载x所对应的缓存行。
这样的重新加载是一种时间和资源的浪费,缓存一致性或者说缓存锁解决数据安全问题的的同时带来的 这个多次非必要加载缓存问题被称为伪共享问题。
3.CPU的乱序执行问题
首先明确一个事实,CPU执行指令的时候是乱序执行的。
CPU乱序执行的原因
https://www.cnblogs.com/liushaodong/p/4777308.html
CPU的执行指令在内存中做一些操作,因为CPU的执行速度相较于内存至少时100倍,所以CPU不能干等着执行结果,为了提高效率,CPU就 在一条指令执行结束之前,继续执行别的指令。这种不按照程序的编写顺序执行的情况,被称为CPU的乱序执行问题。乱序变现在读指令的乱序,和写指令的乱序。
当然乱序执行不能带来程序的最终执行结果的乱序。所以,计算机底层,对CPU的乱序执行也是作了规范,也保障乱序执行的结果是正确的。提高了执行效率,也保证执行结果的正确性。
CPU乱序执行的表现
读指令的乱序执行
CPU在执行一条读指令后等待该指令执行完(或者返回结果)前,回去执行另一条与该指令没有依赖关系的读指令
写指令的合并执行(write combining)
合并写:
CPU将计算好的值A缓存到L1,如果缓存失败,就会缓存到L2,再此过程中L2相对于CPU太慢了,如果这个过程中A值被改写了几次。CPU会直接将改写的最终结果刷到L2。这种情况被称为合并写
如何保证特定情况下,不乱序
某些特定场景写要保证顺序,如何保障有序性
CPU级别采用内存屏障保证或者Java的汇编指令 Lock :
sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。

原子指令,如x86上的”lock …” 指令是一个FullBarrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别再进行规范
LoadLoad屏障: 对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障: 对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
备注:这些规范的实现,是依赖于硬件级别的原理来实现的。具体用哪些硬件原理,怎么组合操作,JVM自己决定。
Java代码级别采用volatitle关键字保障
1.字节码层面(.class文件)
被volatile 修饰的变量在.class二进制字节码文件中多了一个acc_volatile 标记
2.JVM层面
JVM对被acc_volatile 修饰的变量,也即 .class文件中被 acc_volatile修饰的变量:
如果它是写操作指令,则在该写操作前面加一个 StoreStoreBarrier ,后面加一个StoreLoadBarrier ,保证该指令与上下两个指令不重排序
如果它是读操作指令,则在该读操作前面加一个 LoadLoadBarrier ,后面加一个LoadStoreBarrier ,保证该指令与上下两个指令不重排序
3. os和硬件层面
windows 上采用Lock 指令和MESI 实现,Linux我忘了,哈哈哈















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









