






作者 | 我叫斯蒂芬 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/575058907
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【BEV感知】技术交流群
原文链接及代码:
https://arxiv.org/pdf/2112.00726.pdf
https://github.com/cv-rits/MonoScene
1. 背景:
最近Tesla的 Occupancy Network比较火爆,那么这里介绍一些相关方向的文章,并提供如何搭建OccupancyNetwork的一些建议。
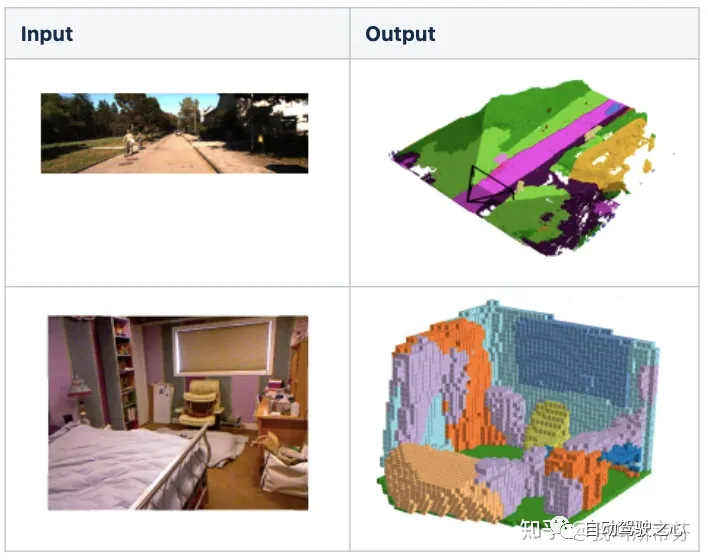
如果论方向(派系)的话,它主要继承至Semantic Scene Completion(SSC)系列的工作。这个工作简单描述起来就是,给定单帧、多帧的图像,预测出场景的3D重建表示(Occupancy Grid Map)以及每一份部分语义分类信息,即输入输出可以用下图来表示。MonoScene就是其中的代表作之一,接下来则介绍一下这篇工作。
2. Contribution:
其实SSC相关有很多工作,尤其是在机器人领域。而本文的MonoScene是第一篇不依赖于深度、雷达传感器作为输入信号,而是只输入单帧图像,且能支持室内室外场景下预测的方法。
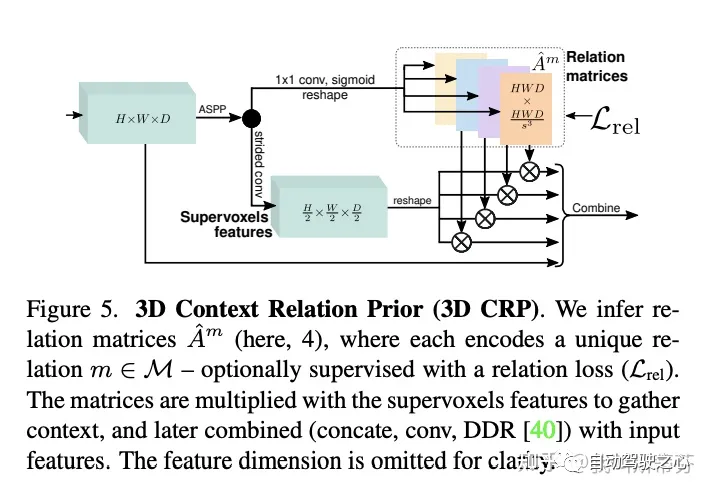
提出了一种从2D特征到3D特征的变换,本文将其命名为Feature Line of Sight Projection(FLoSP)模块。后续3.1节会描述
提出了3D Context Relation Prior(CRP)模块来提升网络语义信息的表征能力。3.2节描述
针对3D语义分割的任务,提出SSC losses来优化场景语义分类下的表现
3. 网络结构与细节:
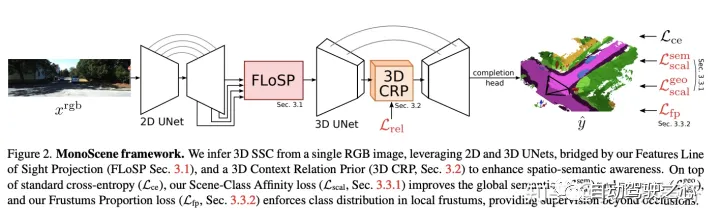
首先一图介绍整体的网络架构,图像 输入,首先经过2D Unet网络提取不同分辨率下的图像特征(C,H,W)。接着都送入FLoSP模块,将2D 特征转换成3D特征(C,D,H,W)。紧接着经过3D Uet加强深度维之间的联系,在其中加入3D CRP模块用来提升空间语义的响应能力(后续的消融实验来看3D CRP其实主要刷点的trick,主干的FLoSP部分更重要)。最后再接上head完成3D语义的输出。其中CRP模块会加入 的监督,在Head部分有交叉熵损失 ,提出的Scene-Class Affinity loss 全局语义损失 ,全局几何损失 ,Frustums Proportion loss(视锥比例损失) 提高在在局部视锥下的表现。
3.1 Features Line of Sight Projection(FLoSP):
由于单目设定下尺度无法准确定义(详情可以查看SLAM十四讲,单目深度相关介绍),将2D投影到3D是具有歧义性的。所以这里设计了如下图的结构来完成2D到3D的特征转换。通过将多尺度(scale)的2D特征投影到给定的 3D 特征图上,可以获得更好地3D-2D之间的联系。
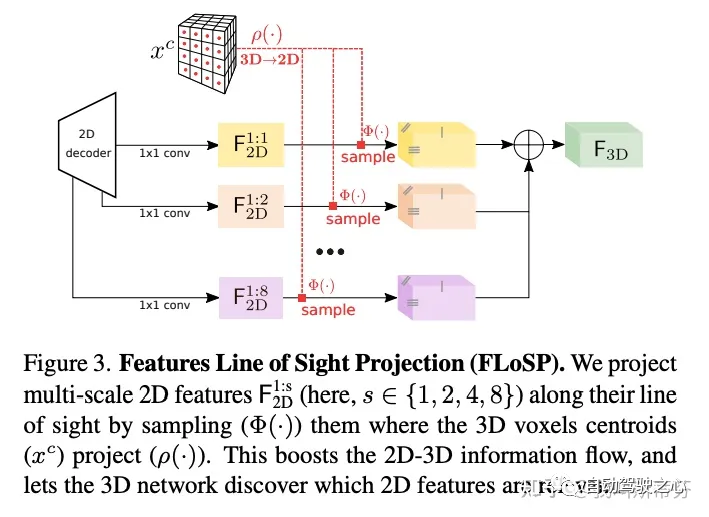
处理方式具体为,从2D到3D投影时,对各种不同的scale(1:s),分别将其3D的体素格点投影到2D上并且采样相应的特征,重复多次后对不同scale的3D特征进行加权。整个过程可以用如下公式来表示:
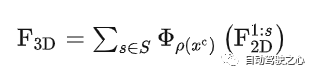
其中 表示在坐标a下对b进行采样, 为投影变换。一般来说scales = {1, 2, 4, 8}。在采样之前需要用1x1 conv充分融合特征。超出图像坐标的区域的特征被置为0。
其实从2D到3D的变换有很多不同的方法,比如说bevdet中的LSS操作,通过外积的形式来计算图像像素在不同深度下的响应。或者是petr系列方法,通过3D位置编码使2D特征具有3D的属性。又或者是构建frustum的方式,其实这很多种都可以进行尝试。
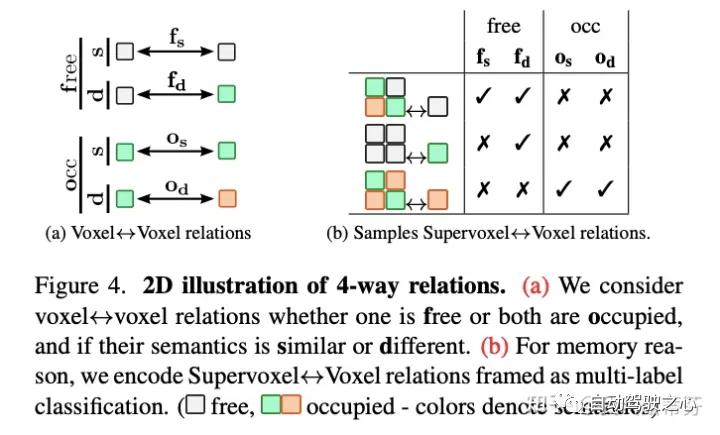
3.2 3D Context Relation Prior(CRP)
因为SSC高度依赖于图像语义,可以借鉴2D segmentation任务中CPNet中的二值语义先验方法。这里提出了3D 语义相关先验模块(3D CRP),将其插入到3D Unet之中。它给网络提供了一个全局的感受野,提升了空间语义的表达能力。
因为SSC是个高度不平衡的任务,学习二值关系不是最佳选项。考虑了n=4的情况,即将voxel的关系分成free和occupied来表示至少有一个voxel是空的和都被占据。对每个组,语义的类别分成similar或difference,这样形成四种组合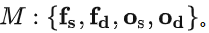 。下图a即是其2D表示:
。下图a即是其2D表示:


3.3 Losses
3.3.1 Scene-Class Affinity Loss
为了提升在3D下SSC的表现,使用 ,借鉴了CPNet(ContextPrior)中的2D binary affinity loss。详细模块可参见附录。

其中Pc和Rc衡量相似类别体素的precision和recall,而Sc衡量不同类别的体素。pi则是体素i的gt类别,hat pi,c是预测的类别。而loss则由三者组成
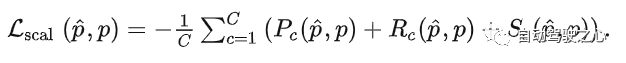
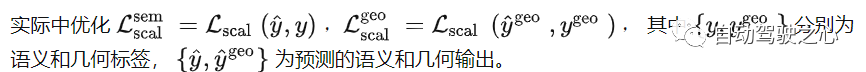
3.3.2 Frustum Proportion Loss
被遮挡的体素容易被预测成物体的阴影,为优化这种影响,提出了Frustum Proportion Loss在视锥中优化类别的分布。
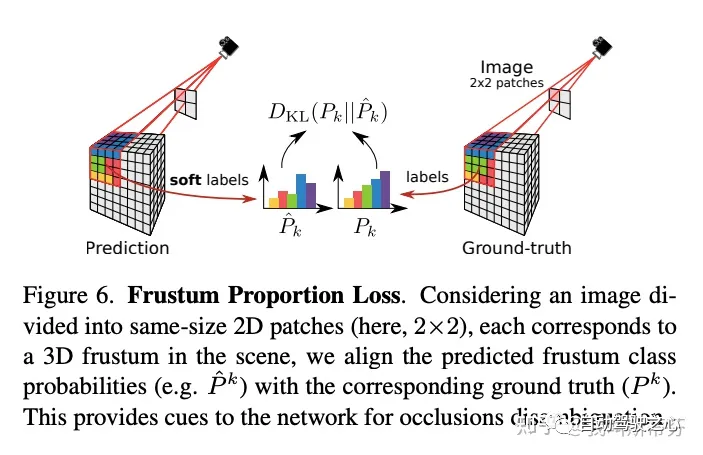
具体做法是将将输入图像分成大小相等 l*l (l=2)的小patch,计算对应每个小块的视锥中类别的分布。即用gt的类别分布给可见、遮挡区域来提供先验,比如车有很大可能会遮挡路。给定frustum k,计算k中体素GT类别的分布 ,特定类别c的分布 。,分别是网络输出的soft prediction(网络后接softmax)。分别计算网络预测与GT分布之间KL散度作为 。
3.4实验策略
直接是end-to-end的训练策略,直接将四种4loss加权后进行优化
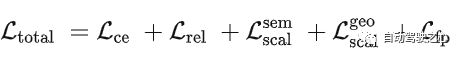
因为真实世界的数据之间有遮挡,所以是稀疏的,只有GT输出的地方计算loss。
4.实验
相关的实验是在NYUv2(室内)和semanticKitti(室外)的场景下验证。
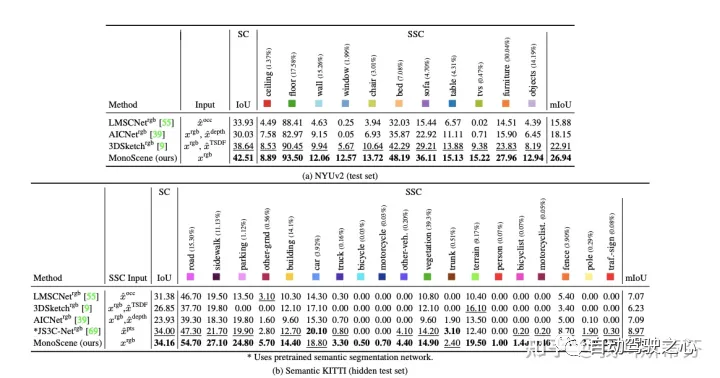
整体上在两个数据集上效果还不错,达到了超过baseline的水平。

直接与3D/2.5D输入进行比较,在NYU上mIOU是比较好的,IOU较差。可以发现输入TSDF后的3DSKetch明显更好,说明TSDF对于恢复几何结构有很大的帮助。另外在KITTI上,输入了激光雷达的方法明显都更好,说明在复杂场景下点云的重要性,以及单目恢复重建的难度。
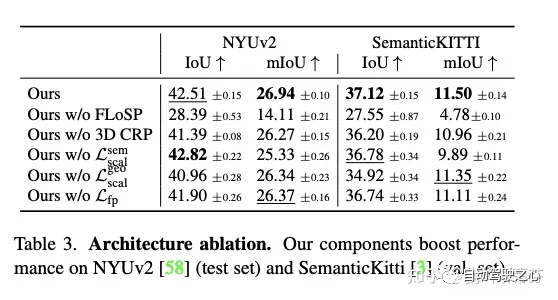
消融实验也是证明了FLoSP是更重要的,其他的只是一些比较小的trick。
5.总结
总结来说,如果要搭建Tesla Occupancy Network,这篇是一个不错的baseline。是第一篇纯单目视觉的3D 语义分割方法,并且在semantic-kitti上刷到了SOTA,其核心模块式FLosp(2D->3D)模块。但是如果要继续复现Occupancy Network,还需要继续加上,多摄、Nerf输出头等模块,有不小的工作量。另外如何生成voxel GT也值得持续深入研究。
附录;
CPNet中的CP:CVPR2020的论文,出发点是在做分割建模的时候考虑到整张图上其他同类以及不同类feature的信息,把每一个pixel显式的区分intra-class和inter-class,这篇论文的做法和CVPR2019的Dual Attention Network for Scene Segmentation就比较像。
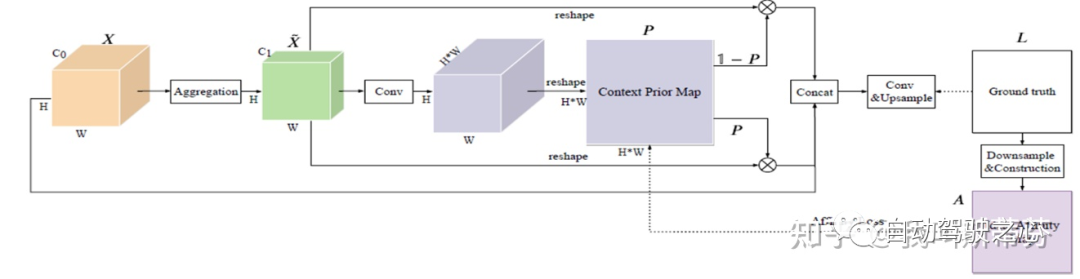
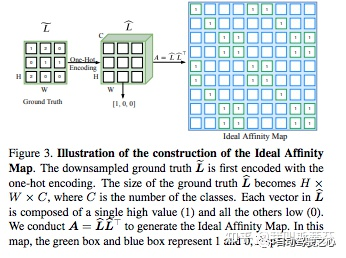
Context Prior模块具体做法为,网络预测出feature(C1xHxW)后,通过conv将channel维度变为HxW,接着reshape成(HW*HW)的维度,用来建模pixel与pixel之间的关系,这部分由GT生成Ideal Affinity Map来监督。具体生成步骤,是对每个像素根据类别进行one hot编码,那么可以得到(H,W,C)的feature map A,而Ideal Affinity Map 则由 A算得到,它的结果就是一堆的0、1 mask,反应每个像素之间的关系,并监督网络。用的时候就用这个mask 拍到feature map上作为intra-class的feature , 1 - mask再拍到feature map上作为inter-class的feature,加上原始的feature map三个concat到一起作为最后的feature map。
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









