






作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群

参数有效转移学习(PETL)是一个新兴的研究领域,旨在廉价地将大规模预训练模型应用于下游任务。最近的进展通过更新或注入少量参数而不是完全微调,在节省各种视觉任务的存储成本方面取得了巨大成功。然而,作者注意到,大多数现有的PETL方法在推理过程中仍然会产生不可忽略的延迟。
在本文中提出了一种用于大型视觉模型的参数高效且计算友好的适配器,称为RepAdapter。具体来说,作者证明了即使具有复杂结构,自适应模块也可以通过结构重参化无缝集成到大多数大型视觉模型中。此属性使RepAdapter在推断过程中成本为零。除了计算效率之外,由于RepAdapter的稀疏结构和精心部署,它比现有的PETL方法更有效、更轻量级。
为了验证RepAdapter,作者对3个视觉任务(即图像和视频分类和语义分割)的27个基准数据集进行了广泛的实验。实验结果表明,RepAdapter的性能和效率优于最先进的PETL方法。例如,通过只更新0.6%的参数可以将Sun397上的ViT性能从38.8提高到55.1。它的可推广性也通过一系列视觉模型得到了很好的验证,即ViT、CLIP、Swin Transformer和ConvNeXt。
源代码:https://github.com/luogen1996/RepAdapter
1、简介
一两年来,大规模预训练模型的研究吸引了计算机视觉界的大量兴趣。随着在各种视觉任务上的出色表现,大规模预训练也导致参数大小的快速增长。在这种情况下,直接在下游任务上微调这些预训练的模型,这是以前使用的一种常见的转移学习策略,在存储开销方面变得非常昂贵。例如,当在VTB-1k的19个视觉任务上完全微调ViT-G时,它需要存储超过350亿个参数用于部署。
为了解决这一问题,最近致力于参数有效转移学习(PETL)。受自然语言处理(NLP)的巨大成功的启发,用于巨型视觉模型的PETL方法还旨在通过为每个下游任务更新或注入一小部分参数来降低调整成本,这可以大致分为两大类,即视觉适配器和提示调整。值得注意的是,最近的进展还表明,与Vision Transformers上的完全微调相比,在更低的参数成本下,性能更好。
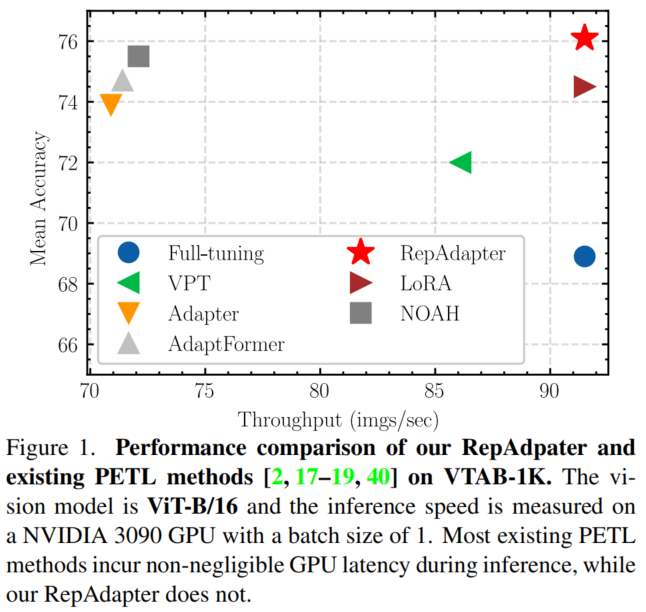
尽管取得了巨大的成功,但作者观察到,大多数现有的PETL方法不可避免地会减缓模型推断,如图1所示。对于快速调整方法,插入的Token大大增加了视觉模型的计算成本,特别是基于Transformer的模型。
就视觉适配器而言,它们的理论成本实际上很便宜,例如视觉适配器的+0.03 GFLOP。但添加的模块也增加了网络复杂性,例如,使模型更深,从而降低了GPU并行计算的效率。如图1所示,当批量大小设置为1时,ViT的延迟几乎增加了20%,这在实际应用中非常重要。
该问题的自然解决方案是保持网络结构和输入完整,并且仅微调部分预训练模型,例如分类器或偏差。然而,该策略的性能仍然落后于对主流视觉任务的全面微调。
另一种可能的选择是一种新提出的用于预训练语言模型的PETL方法,称为LoRA。LoRA学习两个低秩分解矩阵,这些矩阵可以在推理过程中与多头注意力中的投影权重相结合。然而,当应用于其他神经模块时,例如,大卷积核或高维MLP,其参数大小将显著增加。尽管如此,这种重参化操作仍然提供了关于有效视觉适应的提示。
在本文中研究了公共自适应模块是否可以完全合并到预训练的模型中。在现有的重参化方法中,合并的参数都来自并行添加的分支,例如LoRA和RepVGG。然而,大多数视觉适配器是在线部署的,以直接优化下游任务的特征空间,如图2所示。
在本文中发现当自适应模块去除非线性时,它们也可以在前馈结构中重参化,而不会导致性能退化。这一发现允许在推断过程中保持网络完整,同时保持适配器的有效性。
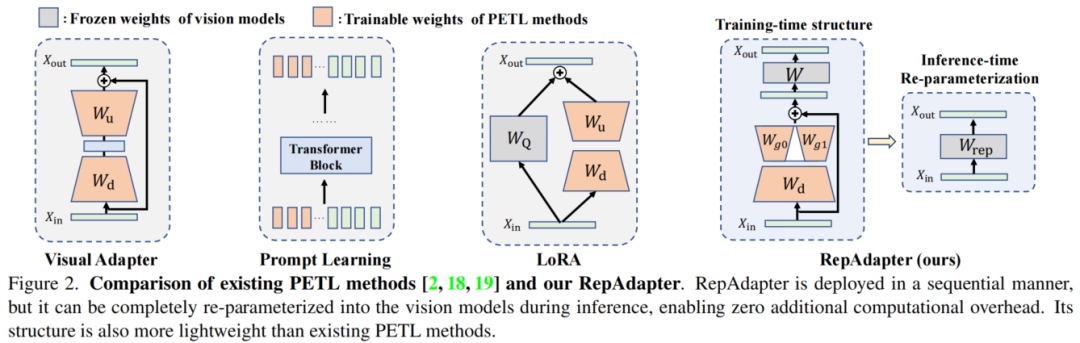
基于这一发现进一步提出了一种新的PETL方法,称为RepAdapter。如图2所示,RepAdapter还将轻量级网络插入到预训练的模型中,并且在训练后,将将附加参重参化为附近的投影权重。为了最大化RepAdapter对视觉模型的好处,还仔细研究了插入位置。同时,继续通过引入密集稀疏连接来减轻适配器的权重。与最新的视觉适配器相比,RepAdapter甚至可以节省大约25%的参数。
为了验证RepAdapter,进一步将其应用于广泛的视觉模型,从卷积神经网络(CNN)(如ConvNeXt)到单模态和多模态Transformer(如ViT和CLIP)。在27个图像和视频分类和语义分割的基准数据集上进行了广泛的实验。实验结果表明,RepAdapter在性能和参数大小方面都优于最先进的(SOTA)PETL方法,同时在推断过程中不需要额外的计算。同时,还研究了RepAdapter在不同实验环境下的性能,包括Few-Shot学习和域自适应,其中还可以看到其优异的性能和可推广性。
总之,贡献有三个方面:
-
证明了普通视觉适配器也可以通过结构重参化无缝地合并到预训练的视觉模型中。
-
基于这一发现提出了一种新的PETL方法,称为RepApapter,用于视觉模型,该方法在推理过程中不会产生额外的成本。它也比现有的PETL方法更具参数效率。
-
在所有实验设置下,RepAdapter在性能和效率方面都优于现有的PETL方法。同时,它可以应用于不同类型的视觉模型。
2、本文方法
2.1、原理
首先在一个广泛使用的预训练模型称为视觉Transformer(ViT)的视觉适应。由于页面限制,本文的方法如何适应其他视觉模型,如ConvNeXt在论文的附录中描述。
1、Vision Transformer
给定一个输入图像,ViT通过patch embedding将其序列化为视觉Token 。然后,将用于分类的可学习标记与X拼接,并添加positional embeddings ,可以用
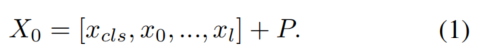
然后,这些视觉输入由一组Transformer层进行处理。第1个Transformer块可以被解定义为
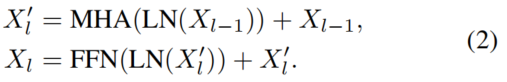
MHA、FFN和LN分别表示多头注意力、前馈网络和层归一化。特别是,MHA可以由
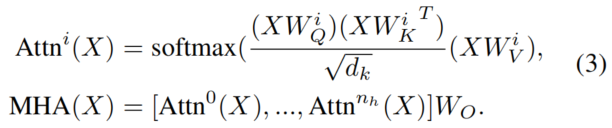
这里,是第个Head的scale-dot product attention。[·]表示连接操作。、、和是投影矩阵。FFN可以被定义为
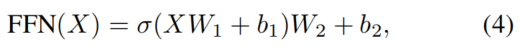
其中和是两个投影权值。和是偏置标量。σ是GELU函数。
2、Visual Adapter
视觉适配器通常由一个具有瓶颈结构的轻量级神经网络和一个残差连接组成,它可以由
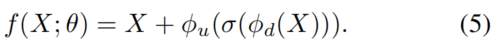
这里,σ为激活函数,和分别表示下采样和上采样投影。由定义,其中和分别为投影权值和偏置项。在实践中,适配器的隐藏大小非常小,这使得它非常轻量级。
有两种常见的方法可以将适配器部署到视觉Transformer上。第一个是顺序方式,它将适配器放置在FFN之后。在此部署下,等式2可以被修改
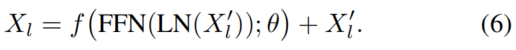
另一个是并行部署,其中适配器并行放置到FFN。在这种情况下,等式2可以被重写
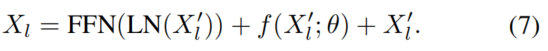
根据重参化的原理,由于FFN的非线性问题,并行适配器不能与Transformer的权值相结合。
2.2、RepAdapter
1、Adapter Structure
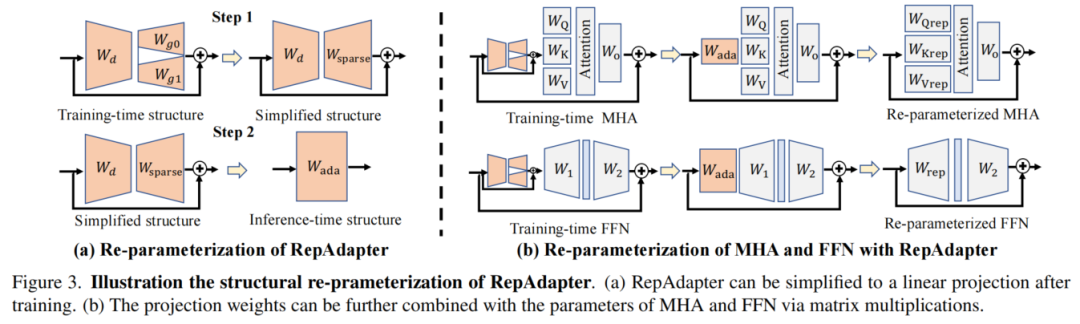
首先介绍RepAdapter的结构,它与现有的视觉适配器仍然不同,如图3所示。首先,RepAdapter中没有激活函数,这是重参化的关键条件。其次,RepAdapter采用了一个密集到稀疏的结构。其稀疏部分由群变换构造。第三,RepAdapter采用预插入放置,以最大限度地提高其对视觉模型的好处。
Linear structure
所有现有适配器遵循非线性结构以适应下游任务。然而,在去除适配器的非线性之后发现视觉模型中没有性能下降。在视觉模型中,适配器的隐藏尺寸通常比NLP模型小得多,例如8对96。在这种情况下,非线性的影响将在视觉模型中变得不明显。同时,消除非线性还提供了允许适配器在训练后重参化的显著优点。具体而言,RepAdapter的θ公式可以改写为
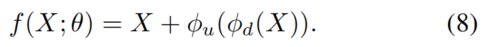
Dense-sparse connections
在等式中8、和通常是现有适配器中的两个完全连接的层。相比之下,RepAdapter采用密集稀疏连接,其中表示为群变换
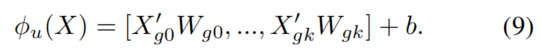
这里,是从中分离出来的特征,k是组的数量。是投影权值矩阵,是偏差项。
RepAdapter的稀疏结构使其比传统视觉适配器更轻。当组编号设置为2时,RepAdapter可以比最新的视觉适配器节省大约25%的参数。在实践中还发现这种稀疏结构可以提高性能,这防止了模型在训练样本有限的情况下过度拟合下游任务。
Pre-inserted placements
最近的进展表明,并行自适应在性能上通常优于顺序自适应。然而,由于内部模块的非线性,例如ViT中的FFN,此设置使得适配器无法重参化。在这种情况下,RepAdapter的部署也遵循顺序方式。但是,如何将RepAdapter有效地插入到视觉模型中仍然是一个悬而未决的问题。
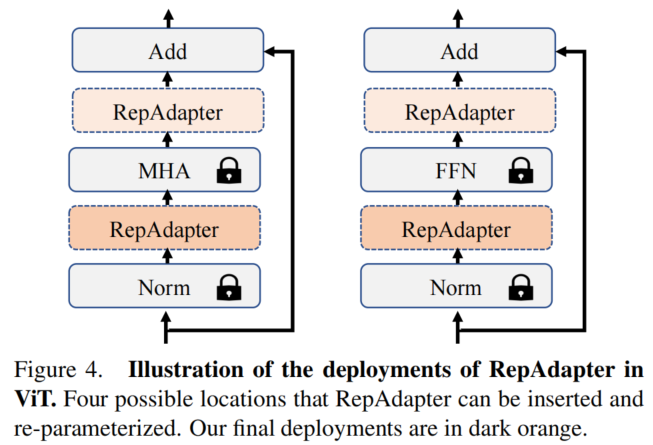
为此,作者研究了所有可能的顺序部署,如图4所示。根据经验发现在神经模块之前部署RepAdapter可以带来更好的性能,这对于重参化也是可行的。同时,还观察到,将RepAdapter应用于ViT中的MHA和FFN更为有益。因此,Transformer中RepAdapter的部署可以通过
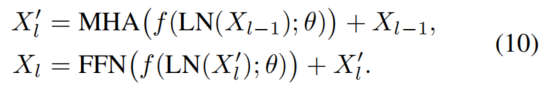
2、结构重新参数化
接下来展示了所提出的RepAdapter可以在训练后在结构上重新参数化到视觉模型中,因此在推断过程中不会产生额外的成本。
具体而言,首先通过以下方式重新公式化方程9中的群变换:
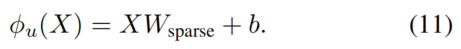
这里,是稀疏权重矩阵,其通过等式9中的零填充获得。然后,RepAdapter的公式θ可以简化为
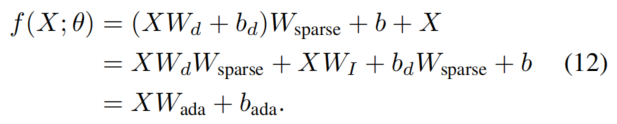
这里,是单位矩阵。为了简单起见,忽略了E.q 12中s的常量值。和分别是重参化的权重和偏差。通过这种方式,将RepAdapter的结构简化为线性投影层,可以通过矩阵乘法将其合并到近投影权重中。
基于等式12,进一步描述了RepAdapter for Vision Transformer的重参化。以FFN块为例,具有RepAdapter的FFN可以重新提交为
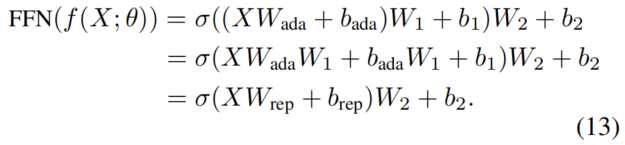
这里,是FFN的重参化投影权重,是重参化的偏置项。通过等式13,可以将RepAdapter完全合并到FFN块中。
类似地,使用RepAdapter重新参数化MHA块可以写成
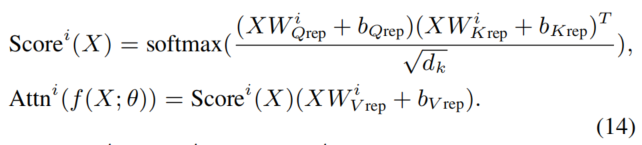
这里,、和是重参化的权重矩阵,、和是偏差。
通过以上推导,得出了顺序适配器重参化的两个条件。首先,自适应模块应该是线性的,否则不能在推理过程中将其简化为投影层。其次,在适配模块之前或之后必须有一个突出权重,适配器可以与之结合。基于这两个条件,其他自适应模块也可以在前馈结构中重参化。同时,这种重参化也可以扩展到正则卷积核。
3、实验
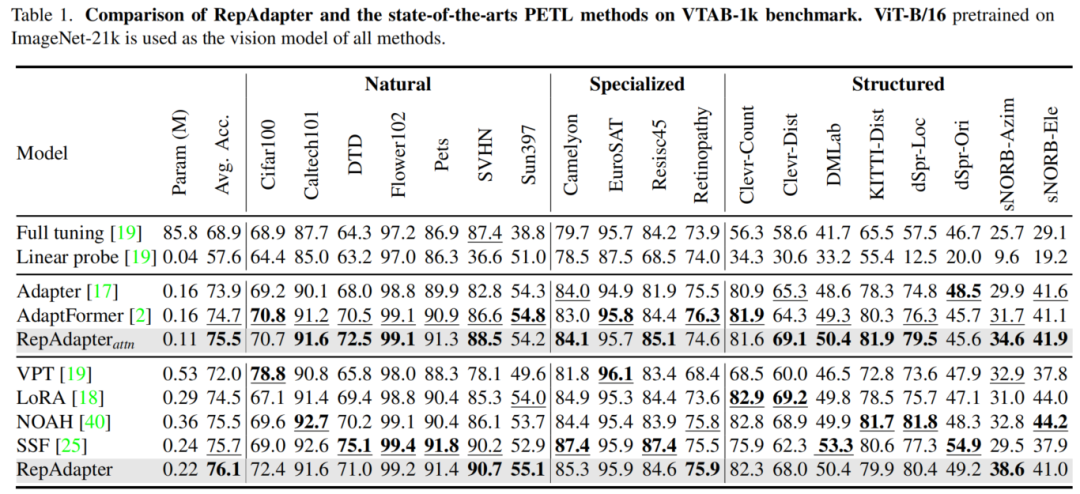
3.1、SOTA对比
3.2、消融实验

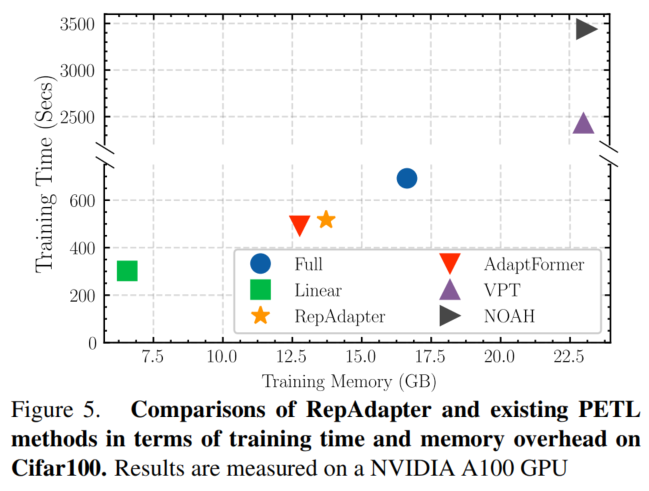
3.3、效率分析

3.4、泛化实验
1、少镜头学习和领域泛化
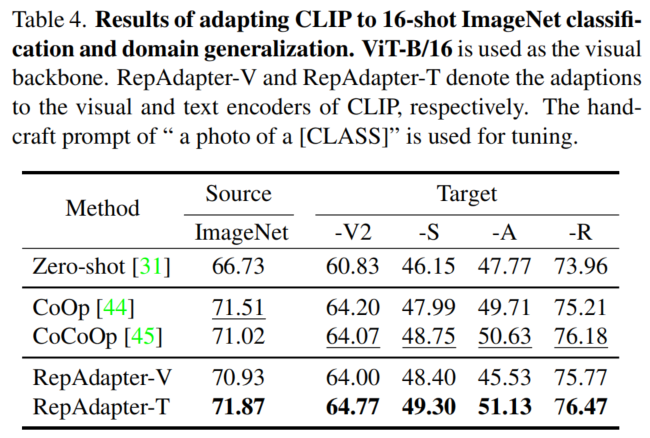
2、更多的网络架构的结果
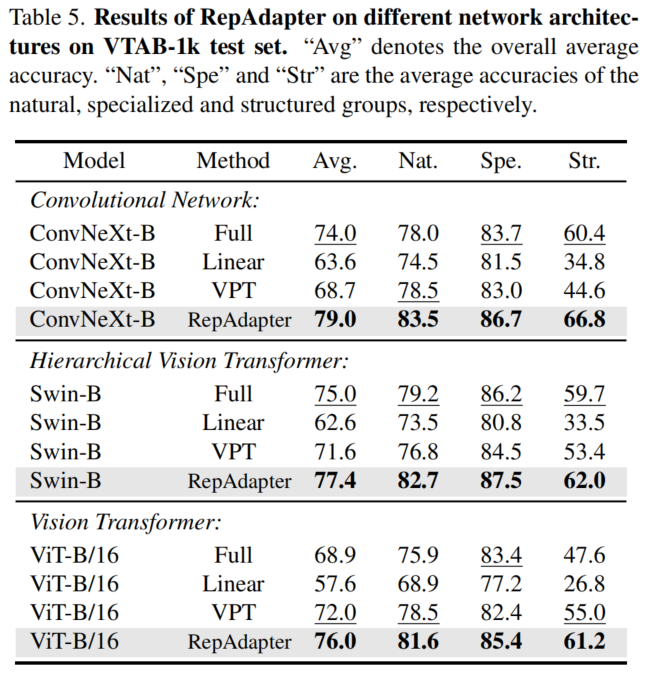
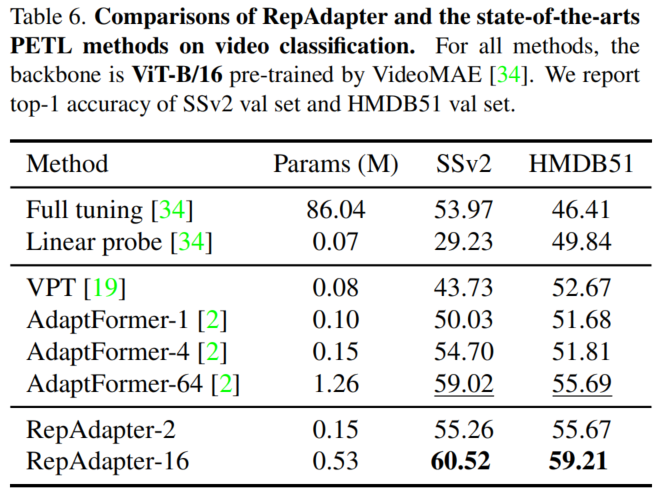
3、更多的视觉任务的结果
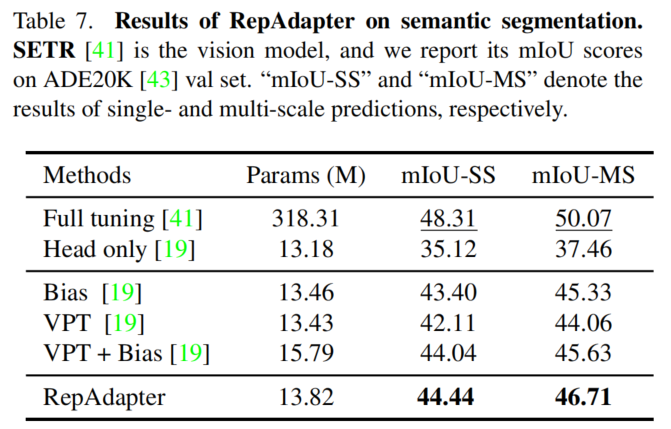
4、参考
[1].Towards Efficient Visual Adaption via Structural Re-parameterization.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









