






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到呀哈哈解读CVPR 2023端到端多目标跟踪的最新SOTA—MotionTrack,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【目标跟踪】技术交流群
论文作者 | Ce Zhang
自动驾驶之心 · 特约解读 | 呀哈哈
编辑 | 自动驾驶之心
论文链接:https://arxiv.org/abs/2306.17000

基于transformer的端到端算法可以同时检测和跟踪对象,在多目标跟踪任务中展现了巨大的潜力。然而,现有的方法主要聚焦于:单个传感器模式输入(通常是图像)、固定位置、高采样频率(通常为30Hz)以及单一对象类别(人类)的图像跟踪方法。在论文中,作者提出了一种新的端到端基于transformer的算法(MotionTrack),使用多模态传感器输入同时完成检测和跟踪多个类别的对象,以适应自动驾驶环境。该算法由transformer编码器和transformer解码器组成。编码器提取并融合来自激光雷达和图像的输入特征。解码器包含对象检测模块、基于transformer的数据关联模块和查询增强模块。数据关联模块使用修改后的注意力机制关联不同帧之间的对象,而不需要明确的运动预测和状态估计过程。查询增强模块结合历史跟踪特征来提高检测性能。作者在nuScenes数据集上测试和评估了MotionTrack算法及其变体,结果表明MotionTrack算法的性能明显优于其他基线模型,达到与概率3D卡尔曼滤波器相当的水平。论文建立了自动驾驶环境下的端到端transformer多目标检测与跟踪算法的基准。
1. 引言
感知是自动驾驶的基本和关键要素。常见的感知任务可分为三类:多目标检测(MOD)、多目标跟踪(MOT)和多目标预测(MOP)。一个可靠的MOT算法应该理解MOD的结果,并为MOP建立联系。
基于机器学习的跟踪算法最近变得流行,通过学习提高时间和空间特征来改进MOT性能。当前的基于机器学习的跟踪算法有两种范式:检测后跟踪和同步检测与跟踪。前者将检测和跟踪视为独立的顺序任务,而后者则同时联合处理检测和跟踪。两种范式都利用神经网络进行运动预测(MP)或数据关联(DA)。同步检测与跟踪通过相互特征共享具有重大优势。具体来说,来自跟踪的时间和空间特征可以提高检测性能,而来自检测的外观和位置特征可以增强跟踪中的DA。鉴于以上优点,作者为MotionTrack选择同步检测与跟踪范式。
目前相关的基于transformer的跟踪算法适用于以下情况:单个传感器模式输入(通常是图像),固定位置,高采样频率(通常为30 Hz),以及单一对象类别(人类)。但对于自动驾驶,跟踪算法可以使用多种传感器输入(例如图像和基于激光雷达的点云),在移动的自主车辆上运行,相对较低的采样频率(10 Hz)以及多个对象类别(行人、汽车、卡车等类别)。据作者所知,现有的transformer跟踪算法都无法有效处理这些复杂的情况。
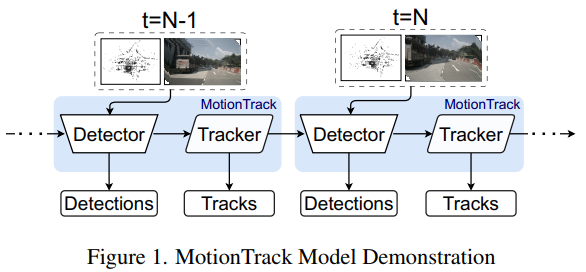
基于上述假设和问题,作者提出三个问题:(1) 是否可以将基于transformer的DA算法应用于自动驾驶环境下的同时MOD和MOT,如果可以,是否可以仅通过DA完成MOT而不需要显式的MP和状态估计过程?(2) 如何处理DA中的多种传感器输入?(3) 是否可以通过历史跟踪特征增强检测性能?为了回答这些问题,作者提出了一种新颖的端到端基于transformer的算法(MotionTrack),使用激光雷达和图像多模态传感器输入同时完成检测和跟踪(图1)。MotionTrack算法利用修改后的transformer实现DA,并使用另一个transformer将跟踪信息更新到潜在对象特征。所提出的算法通过nuScenes数据集进行了测试和评估,AMOTA结果比其他基线算法高出2-3倍,并与流行的跟踪解决方案(如概率3D卡尔曼滤波器)不相上下。论文的贡献包括:
设计具有多模态传感器输入的基于transformer的模块,用于在不进行MP和状态估计的情况下实现跟踪。
开发查询增强模块(QEM)来通过结合历史跟踪特征改进检测性能。
在自动驾驶环境中建立端到端transformer多目标检测与跟踪算法的基准。
据作者所知,这是自动驾驶环境下的首个端到端多模态transformer基础多目标检测与跟踪算法。作者强调论文的目标是调查可行性并建立基准,而不是通过nuScenes数据集实现跟踪任务的最先进结果;后者需要在作者的基准之上进行进一步改进。
2. 背景介绍
尽管物体在三维物理空间中运动,但MOT可以在3D或2D(如图像中)跟踪物体。MOT的输入可以是2D的(如图像)或3D的(如激光雷达点云),也可以两者都有。MOT可以采用用于MP、滤波和DA的传统方法,也可以采用神经网络来实现跟踪所需的目标。
2.1 2D MOT
2D MOT通常使用图像和对象状态作为输入。大多数2D算法利用图像中丰富的语义信息和密集的时域特征来实现MOT。但是,图像目标没有明确的位置和运动信息,这严重影响了2D MOT的性能。最流行的传统2D MOT方法之一是简单在线实时跟踪(SORT),它使用卡尔曼滤波器进行MP,使用匈牙利算法跨帧进行DA。SORT的后继DeepSORT 修改了DA算法,进一步引入了马氏距离分配器和基于神经网络的外观特征描述符来协助帧间的DA,从而提高了跟踪性能。尽管传统MOT算法可靠且易于部署,但需要大量的参数调优。此外,传统MOT无法处理遮挡等情况。
基于机器学习的MOT算法是为了解决传统跟踪中的上述问题而开发的。CenterTrack 设计了一个基于卷积神经网络(CNN)的MP模块,用于估计两帧之间的热力图位移,以实现DA。它在MOT数据集上获得了良好的性能,但ID切换和长期跟踪问题仍有待解决。除了CNN之外,transformer架构最近也变得流行,主要归功于其全局特征提取和时域特征聚合能力。全局特征提取同时处理所有潜在对象查询,而时域特征聚合将过去对象的特征转移到当前帧作为先验知识。当前流行的基于transformer的MOT算法有TrackFormer、MOTR、全局跟踪transformer(GTR) 和MeMOT 。TrackFormer和MOTR遵循同步检测与跟踪范式,将检测到的对象的嵌入与拟议的新生对象查询的嵌入进行拼接。GTR遵循检测后跟踪范式,利用自注意力和交叉注意力机制在所有输入帧之间关联对象。MeMOT由基于DETR的检测器和三个注意力机制组成,用于在关联求解器进行MOT之前,从以前的检测结果中聚合对象特征。所有这些基于transformer的算法都展示了有效的2D MOT。但是,这些算法都是为基于图像的单类跟踪应用设计的。
2.2 3D MOT
3D MOT算法通常应用于自动驾驶,它将图像、激光雷达的点云或激光雷达-图像融合数据作为输入。基于图像的3D MOT算法利用密集的外观特征进行DA。B3DMOT 使用3D卡尔曼滤波器和匈牙利算法进行跟踪。利用泊松多伯努利混合跟踪滤波器实现单相机输入的MOT,以TrackFormer和MOTR的方式使用transformer模型,通过将跟踪的对象连接到当前帧来实现MOD和MOT。进一步聚合时域特征以增强跟踪和检测。尽管有密集的外观特征,但基于图像的3D MOT算法的性能无法与基于激光雷达的方法相比,因为它缺乏明确的位置和距离特征。
目前,研究人员对激光雷达-图像融合感兴趣,因为图像特征提供了丰富的外观特征,而点云提供了准确的距离和位置特征。EagerMOT 是一种传统的3D跟踪器,它采用两阶段关联算法,第一阶段是标准的3D边界框匈牙利数据关联,第二阶段是相同的匈牙利分配器与2D边界框。JMODT是一种联合检测与跟踪算法,使用点云和图像作为输入,具有新颖的基于神经网络的对象关联和对象关联。CAMO-MOT结合运动和外观特征以防止误报。同时,他们设计了一个跟踪成本矩阵来防止跟踪遮挡,从而实现nuScenes数据集的当前最优算法。尽管有大量文献,但据作者所知,目前还不存在多模态、端到端的用于自动驾驶的transformer 3D MOT算法。
3. 方法介绍
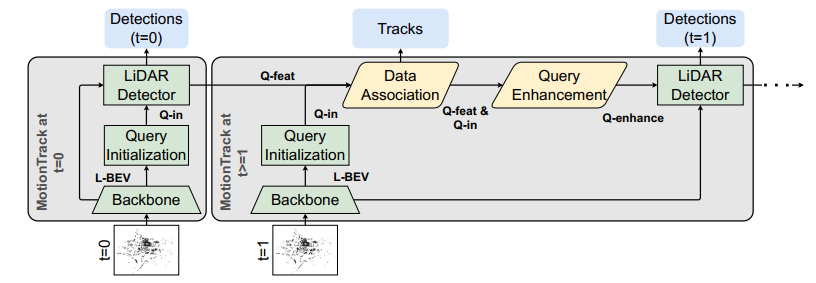
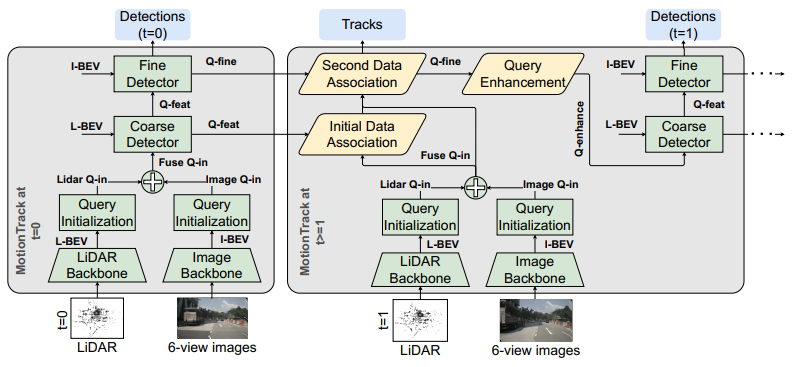
MotionTrack是一种同步检测与跟踪算法。对于MOD,作者采用TransFusion模型。对于MOT,作者设计了一个基于transformer的DA模块。此外,作者开发了一个QEM来继承历史时间信息以改进检测性能。MotionTrack算法包含两个不同传感器配置的设置:仅激光雷达输入(图2)和激光雷达-图像融合输入(图3)。两个设置都包含对象检测模块、DA模块和QEM。由于MOT问题的复杂性,作者定义了MotionTrack的几个术语如下表所示。
| 术语 | 解释 | 缩写 |
|---|---|---|
| 粗粒度(激光雷达)检测器 | transformer解码器层提取输入查询的特征进行对象检测。在仅激光雷达设置中称为激光雷达检测器,在激光雷达-图像设置中称为粗粒度检测器 | C-Det |
| 精细检测器 | transformer解码器层提取输入查询的特征进行对象检测,仅在激光雷达-图像设置中使用 | F-Det |
| 查询输入 | 根据热力图结果生成的查询,在初始帧用作粗粒度或激光雷达检测器的输入,在后续帧用作QEM的输入 | Q-in |
| 查询特征 | 来自粗粒度或激光雷达检测器的输出,也用作精细检测器和DA模块的输入 | Q-feat |
| 精细查询特征 | 来自精细检测器的输出,也用作额外DA模块的输入 | Q-fine |
| 增强查询 | 从QEM生成的增强查询,用作粗粒度或激光雷达检测器的输入 | Q-enhance |
| 激光雷达BEV | 激光雷达BEV特征 | L-BEV |
| 图像BEV | 图像BEV特征 | I-BEV |
3.1 MotionTrack检测器模块
MotionTrack的检测器是TransFusion ,它灵活地支持仅激光雷达和激光雷达-图像设置。
仅激光雷达设置支持两种实现:PointPillar (高性价比模型)、VoxelNet (高性能)。提取的特征转换为BEV特征(L-BEV)进行对象查询初始化。然后,作者基于L-BEV生成热力图以确定初始帧中Q-in的初始位置。在热力图生成之后,一个层的transformer解码器以L-BEV和Q-in为输入提取Q-feat。最后,Q-feat被馈送到预测头层进行对象检测。
与仅激光雷达设置相比,激光雷达-图像设置共享相同的激光雷达骨干,输出L-BEV和激光雷达的Q-in。在图像分支中,ResNet-50 骨干网络首先从6视角RGB图像中提取特征,并将其投影到BEV(I-BEV)。然后,作者生成图像的热力图,然后将图像的和激光雷达的Q-in融合在一起。激光雷达-图像设置的检测具有两个transformer解码层:一个是C-Det,它消耗L-BEV和Q-in;另一个是F-Det,它使用I-BEV和C-Det的输出(Q-feat)作为输入。最后,F-Det的输出馈送到预测头层。有关检测器模块的详细信息可以在中找到。
3.2 基于Transformer的关联模块
常见的MOT算法按顺序执行运动预测(MP)和数据关联(DA)。MOT的核心是DA,因为它使对象能够在不同帧之间联系起来,而MP的作用是支持DA过程。DA算法的结果是当前帧对象是跟踪对象还是新生对象,以及前一帧的对象是否消失,即死亡对象。在这里,作者通过transformer架构研究DA设计,而不进行显式MP。
Transformer DA灵感:自注意力和交叉注意力机制是transformer的核心。对于两种机制,注意力函数都是,其中Q、K和V被称为查询、键和值矩阵,这些矩阵是从输入中学习的。对于自注意力,Q、K和V矩阵是从相同输入(input-A)中学习的,而对于交叉注意力,Q是从不同输入中学习的,K和V矩阵是从相同输入中学习的。注意力函数的本质是基于查询和值矩阵获得的成本矩阵()来更新值矩阵。
成本矩阵启发作者这样的注意力机制可以用来计算轨迹和观测之间的亲和力。然而,实验结果表明,直接应用注意力机制效果不佳,因为softmax激活函数在训练过程中会导致梯度消失问题。因此,作者直接用对象观测特征和轨迹特征之间的点积来计算成本矩阵,这显示出了优异的关联性能。此外,作者发现注意力机制在将前一帧的对象特征更新到当前帧时表现良好,因为可以轻松学习过滤冗余特征并保留前一帧的必要特征。基于这些发现,MotionTrack的关联模块采用transformer架构来更新前一帧的对象特征,并使用点积计算进行DA。
MotionTrack包含适用于仅激光雷达和激光雷达-图像输入的两个DA模块配置。每个DA模块输出独立的轨迹估计结果。区别在于激光雷达-图像输入包含一个额外的DA模块。
DA模块:DA模块包含三个步骤:查询特征更新、目标特征更新和查询-目标式特征关联(图4)。

查询特征更新过程旨在从前帧建立和增强检测到的对象特征。它以前一帧检测到的Q-feat、Q-in和对象的航向角为输入,通过两个交叉注意力层(H-cross 和 Q-cross)更新检测到对象的特征。Q-cross的目的是更新检测到对象的外观特征。外观特征对于DA非常重要,因为关联是通过前后帧外观特征之间的相似度确定的。H-cross旨在继承对象的运动特征。由于单帧检测算法通常无法准确估计对象运动,如速度加速度等,航向角是要引入DA的最重要运动特征之一。
至于目标更新模块,其目的是refine当前帧的对象候选特征以进行DA。目标更新模块简单地将当前帧的Q-in作为输入,并通过两层多层感知机(MLP)进行准备DA,因为当前帧特征的更新是不必要的。由于前一帧检测到的对象可能在当前帧消失,作者将一个空向量(填充零)与Q-in连接,作者称之为“死亡查询特征”,表示消失的对象查询。
最后,前一帧更新后的查询特征通过点积过程与当前帧细化后的目标特征相关联。点积运算的输出是一个N x M+1矩阵,其中N是前一帧检测到的对象数量,M是当前帧中的对象查询数量。矩阵中的较高值(关联分数)表示更高的关联可能性。在训练阶段,作者将关联过程视为分类任务,并在对象关联模块估计结果和真值结果之间计算损失,使用交叉熵损失函数。在评估阶段,作者采用与训练阶段相同的方法,但在对象关联模块之后采用贪婪搜索方法,以防止重复关联。
额外的DA模块:针对激光雷达-图像融合检测器设计了额外的DA模块。架构设计与仅激光雷达的DA模块相同。区别在于查询特征更新模型使用前一帧的Q-fine、Q-feat和检测到的对象的航向角作为输入。此外,评估阶段需要进一步的决策步骤。当两个DA模块估计相同的轨迹结果时,最终关联由额外的关联模块确定。当两个关联模块之间存在冲突时,最终关联结果由最高关联分数确定。
3.3 查询增强模块
QEM的目标是将前一帧的Q-feat或Q-f2注入当前帧的Q-in中,以改进检测性能,整体架构如图5所示。在QEM中,前一帧的Q-feat或Q-fine以及当前帧的Q-in被传递到一个交叉注意力层,以聚合前一帧的特征到当前帧对应的查询中。通过这种方式,历史时间信息被聚合到当前帧中。此外,这种交叉注意力机制可以通过模型学习防止不必要甚至误导信息污染当前帧的特征。

4. 结论
论文提出了一种新的同步检测与跟踪基准算法MotionTrack,具有多模态传感器输入,适用于自动驾驶环境。MotionTrack证明基于transformer的算法适用于自动驾驶环境下的MOT。此外,MotionTrack证明自注意力和交叉注意力机制能够实现多个类别的对象关联。最后,作者提出了一个基于transformer的查询更新算法QEM,用于从历史帧细化潜在对象查询,以改善整体检测性能。MotionTrack的跟踪结果在nuScenes数据集上优于其他基准算法。作者相信MotionTrack可以用作未来基于深度学习的端到端跟踪算法在自动驾驶环境中的新基准。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)
















 2864
2864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









